Different Input Resolutions and Arbitrary Output Resolution: A Meta Learning-Based Deep Framework for Infrared and Visible Image Fusion
(不同的输入分辨率和任意输出分辨率: 基于元学习的红外和可见光图像融合深度框架)
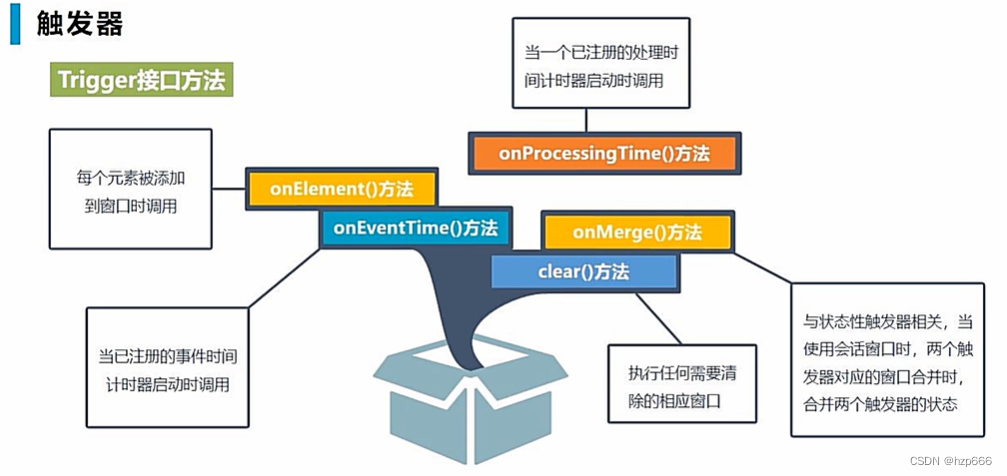
在本文中,我们提出了一个基于元学习的深度框架,用于红外和可见图像的融合。与大多数现有方法不同,所提出的框架可以接受不同分辨率的源图像,并仅使用单个学习模型即可生成任意分辨率的融合图像。在提出的框架中,首先通过卷积网络提取每个源图像的特征,并根据实际要求通过具有任意适当因子的元高档模块进行放大。然后,开发了基于双重注意机制的特征融合模块,以组合来自不同源图像的特征。最后,设计了一个可以在提议的框架中迭代采用的残差补偿模块,以增强我们的方法在详细提取方面的能力。此外,损失函数通过同时融合和超分辨率以多任务学习的方式公式化,旨在提高特征学习的效果。并且,提出了一种由感知对比度增强方法启发的新的对比度损失,以进一步提高融合图像的对比度。
介绍
应用图像超分辨率技术来帮助解决融合问题。一种常规方法是在融合之前执行超分辨率,但是这种两相分离方式有明显的缺点。为了解决这个问题,已经提出了一些使用集成模型同时进行融合和超分辨率的方法。但是,在这些方法中,不同源图像的空间分辨率仍然需要相同,即第一个问题没有解决。此外,这些方法只能通过几个整数比例因子 (例如 × 2,× 3,× 4) 来提高融合图像的分辨率,并且分别学习不同比例因子的超分辨率模型 (即,针对每个比例因子训练一个特定的模型),这大大降低了它们在实际应用中的有用性。因此,仍然存在两个亟待解决的问题: 1) 源图像需要具有相同的空间分辨率; 2) 只有几个整数比例因子可用于超分辨率。
本文提出了一种基于元学习的深度框架,用于红外和可见图像的融合。所提出的方法最显着的特点是,它可以同时处理不同分辨率的源图像 (假定源图像在空间上对齐,这是图像融合研究中的一般假设),并仅使用单个学习模型即可生成任意分辨率的融合图像。这主要是通过采用meta-upscale模块来实现的,该模块可以通过将比例因子作为输入来动态预测高档滤波器的权重。此外,该方法可以同时获得两个源图像的超分辨率结果。图1显示了所提出的基于元学习的红外和可见光图像融合方法的框架。
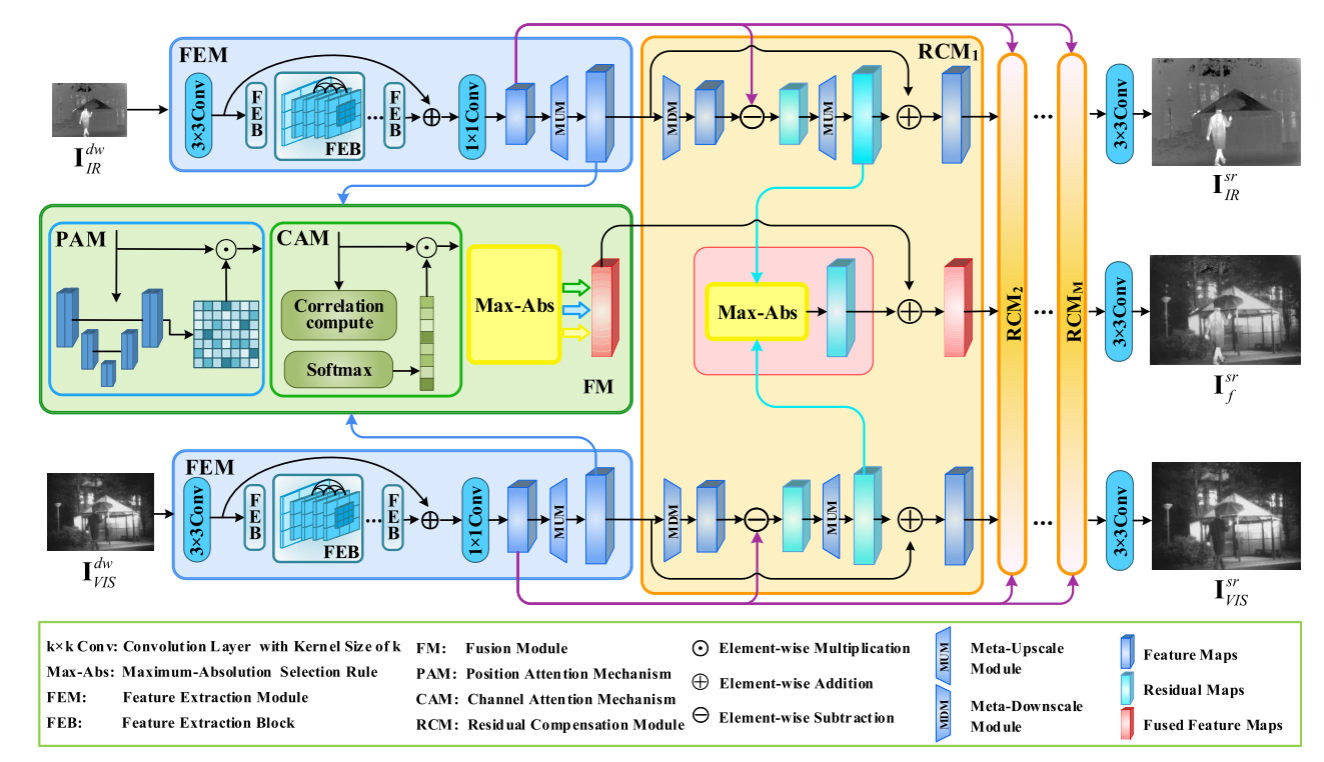
它主要由两个旨在从源图像中提取特征的特征提取模块 (FEMs),一个旨在融合显着特征的融合模块 (FM) 以及一系列用于弥补细节损失的残差补偿模块 (RCMs) 组成。在FEM中,首先通过卷积网络提取每个源图像的特征,然后通过具有适当因子 (值可以是任意的) 的meta-upscale模块 (MUM) 进行放大,该因子根据特定的要求设置融合问题。FM通过双重注意机制将放大的特征合并以生成融合的特征。然后,RCMs在特征图的上采样过程中进一步提取和补偿损失信息,并且可以在我们的融合框架中迭代多次使用。从图1可以看出,该框架可以以多任务学习的方式 (即一个融合分支和两个超分辨率分支) 同时实现融合和超分辨率,从而在特征学习方面具有更强大的能力,这有助于提高融合结果的质量。
贡献
1)我们提出了一种基于元学习的红外和可见光图像融合深度框架。与大多数现有的图像融合方法不同,所提出的框架可以接受不同分辨率的源图像,并且仅使用一个学习的模型就可以生成任意分辨率的融合图像,这在实际使用中具有重要意义。
2)我们开发了基于双重注意机制的特征融合模块,其中同时考虑了位置注意和通道注意,以融合来自不同源图像的特征。
3)我们提出了一个残差补偿模块,可以在建议的融合框架中迭代采用该模块,以增强我们的方法在细节提取方面的能力。
4)我们通过同时融合和超分辨率以多任务学习的方式来制定损失函数,这有助于学习更有效的特征并提高最终融合结果的质量。此外,在这项工作中提出了一种新的基于感知色彩校正理论的对比度损失。
相关工作
Infrared and Visible Image Fusion
(常规的方法:略)
Ma等人最近提出了一种基于双鉴别器GAN模型的多分辨率红外和可见光图像融合方法,同时假设可见光图像的分辨率是红外图像的4 × 4倍。解决上述问题的一种直接方法是在使用超分辨率方法融合之前统一源图像的分辨率。然而,这种两项分离方式有其固有的缺点,例如在超分辨率和融合任务中重复的特征提取过程可能会导致更多的计算成本,并且融合结果的质量严重依赖于所采用的超分辨率方法的效果。在实际应用中,始终首选统一的处理框架。此外,在大多数现有的融合方法中,输出融合图像的空间分辨率保持与源图像的空间分辨率相同,当需要更高分辨率的融合图像时,这在实践中产生了另一个限制。
Simultaneous Image Fusion and Super-Resolution
为了获得具有更高空间分辨率的融合图像,提出了一些同时融合图像和超分辨率的方法。Yin等人通过假设放大的低分辨率源图像的高频分量和重建结果共享相同的稀疏编码系数,开发了一种基于稀疏表示的同时图像融合和超分辨率方法。基于低秩稀疏表示理论,Xie等人提出了一种同时图像融合和超分辨率的残差补偿方法。Iqbal等人提出从高分辨率图像中学习一组多尺度词典,以构建高分辨率融合的结果。Li等人根据融合后的图像应包含源图像的基本几何形状,提出了一种用于图像融合和超分辨率的变分微分模型。
但是,所有这些方法仍然要求输入源图像具有相同的分辨率,并且只能将融合图像的分辨率提高几个整数比例因子。此外,还分别学习了不同比例因子的应用模型,即当比例因子发生变化时,应重新训练模型。这些缺点极大地限制了这些方法在现实场景中使用的潜力。
Meta Leaning-Based Super-Resolution
元学习旨在让神经网络学习,可以动态预测滤波器的权重。受益于这一优势,Jo等人引入了一种完全不同的视频超分辨率框架,其中基于元学习构建了端到端深度神经网络,用于生成动态上采样滤波器和残留图像。为了删除显式运动补偿,这些滤波器和残差图像是本地动态生成的,并且使用这些生成的上采样滤波器,构建了HR帧。在单图像超分辨率中,Hu等人提出了一种元学习方法来预测滤波器的权重,以重建超分辨率图像。与传统的超分辨率方法相比,该方法可以构造具有任意比例因子的超分辨率图像。Soh等人提出了一种zero-shot超分辨率的元转移学习方法。此方法可以利用外部和内部信息,并且只需要一次梯度更新。受元学习和超分辨率研究的启发,我们开发了一种新颖的深度学习框架,用于红外可见图像融合。采用中引入的meta-upscale模块来实现融合框架可以接受不同分辨率的源图像并仅使用单个训练模型即可生成任意分辨率的融合图像的目标。据我们所知,这是试图在该领域实现上述目标的第一项工作。
meta-SR超分辨率的文章
方法
特征提取模块 (FEM) 由特征提取网络和meta-upscale模块组成。特征提取网络用于从每个源图像中提取特征,并应用meta-upscale模块将获得的特征图upscale到融合图像的目标分辨率。
Feature Extraction Module
1) Feature Extraction Network:
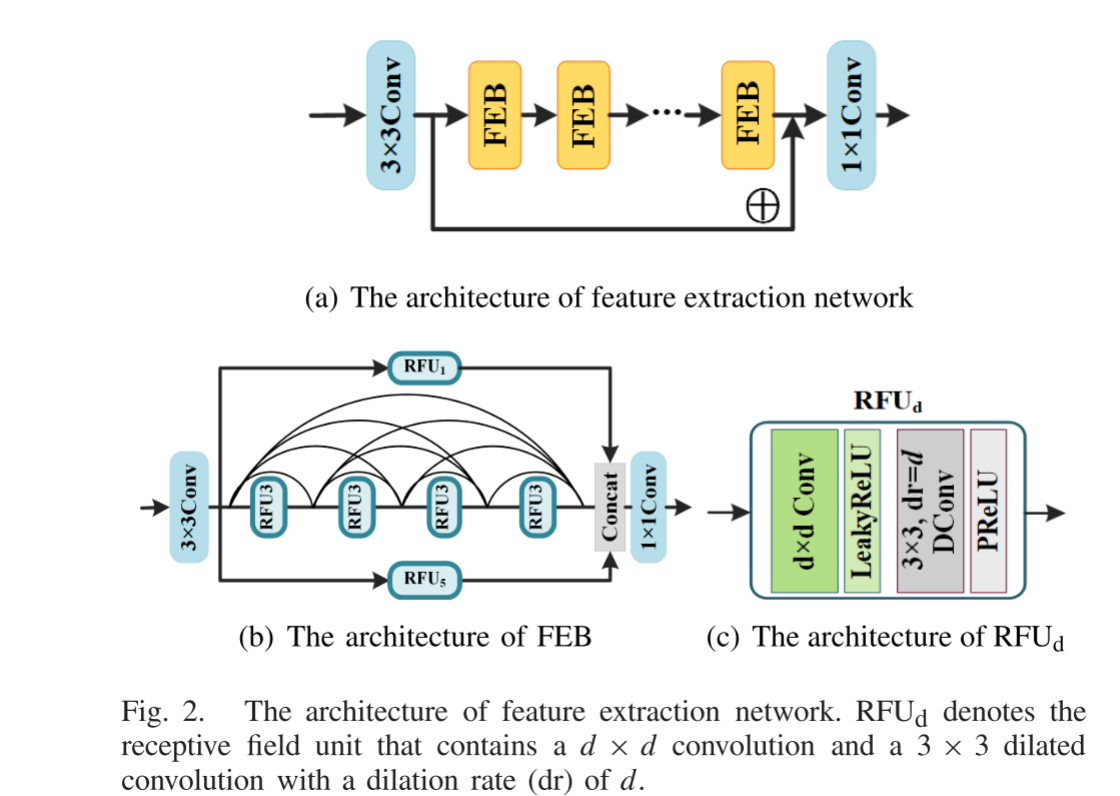
如图2(a) 所示,我们的特征提取网络包含3 × 3卷积层,一系列特征提取块 FEB) (见图2(b)) 和1 × 1卷积层。每个FEB由三个分支组成,这些分支是基于具有不同感受野的感受野单元 (rfu) (见图2©) 设计的。受已有文献中的感受野块 (RFB) 的启发,RFUd (d = 1,3,5) 包含d × d卷积和3 × 3空洞/膨胀卷积(dilated Convolution),其膨胀速率为d,其中,扩张的卷积被用来模拟pRFs在人类视觉皮层中的偏心率的影响。第一分支和第三分支中d的值分别为1和5。第二分支由四个RFU3组成,采用密集跳过连接方式,进一步提高了特征提取的能力。将这三个分支的输出串联起来,并最终将1 × 1卷积用作瓶颈层。为了避免池化和strided卷积造成的信息丢失,我们的FEB中不涉及下采样层 (例如pooling,strided卷积),因此输出特征图的空间大小与输入保持相同。
在我们的特征提取网络中,前3 × 3卷积层和最后1 × 1卷积层分别包含64个和8个滤波器。每个FEB中的最后1 × 1卷积层包含64个滤波器。其余卷积层中的每个包含32个滤波器。此外,为了避免零梯度,每个卷积层后面都有一个负0.2范围的LeakyReLU层,因为它不会引入需要学习的额外参数,而每个膨胀的卷积层后面都有一个PReLU层,用于更专门的激活。
卷积,反卷积,空洞卷积
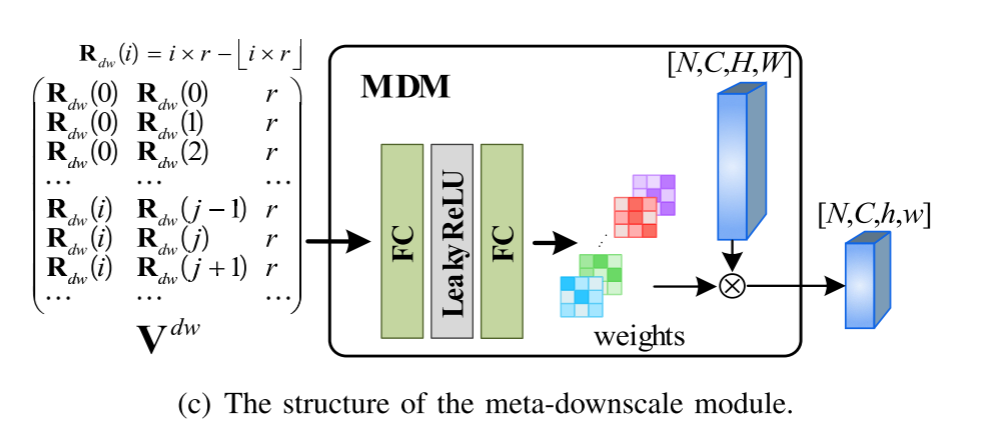
2) Meta-Upscale:

为了实现该方法可以接受不同分辨率的源图像并仅使用单个模型即可生成任意分辨率的融合图像的目标,采用元学习超分辨率工作中提出的Meta-Upscale模块 (MUM) 作为上采样层。具体而言,MUM包括三个步骤,包括位置对应,权重预测和特征映射。图3 (a) 显示了低分辨率图像与其相应的具有比例因子r的高分辨率版本之间的像素的位置对应关系。关键就是权重图是自己学习到的。

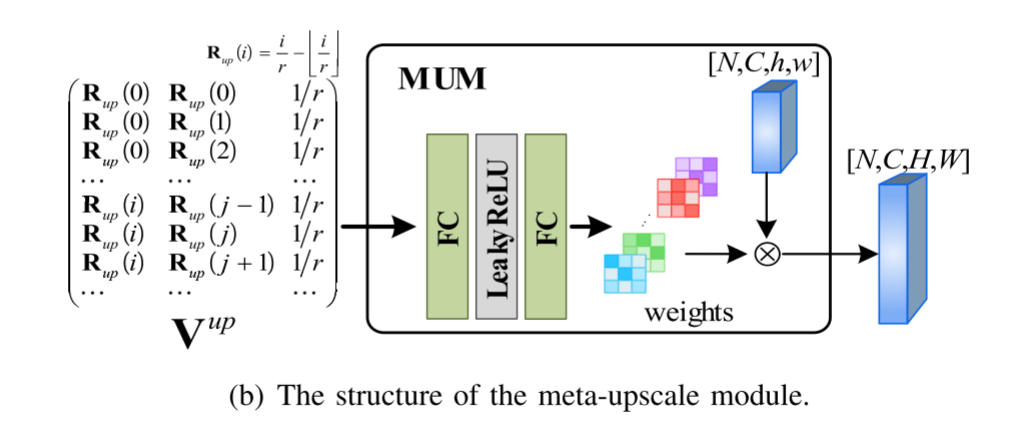

当比例因子改变时,可以独立于先前提取的特征相应地调整权重。因此,MUM可以任意增加特征图的分辨率,而无需重复训练整个模型。
Fusion Module
1) Dual Attention Mechanism:
(全局平均池化(Global Average Pooling (GAP)))
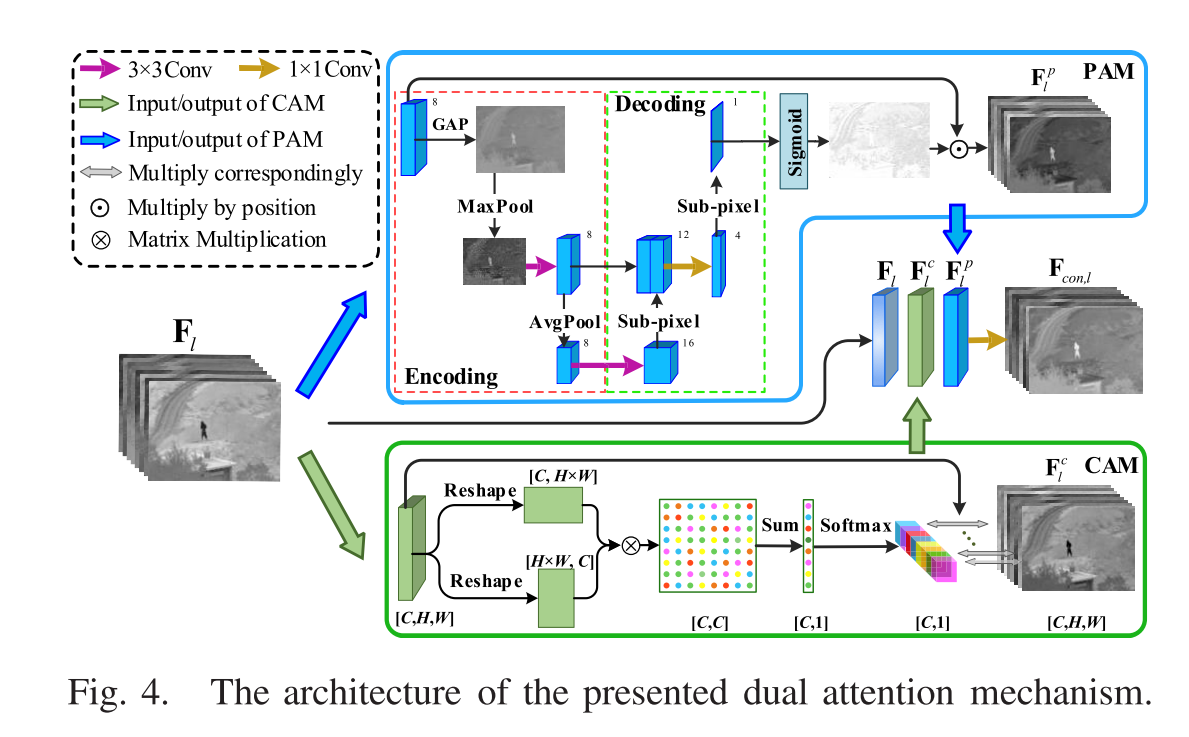
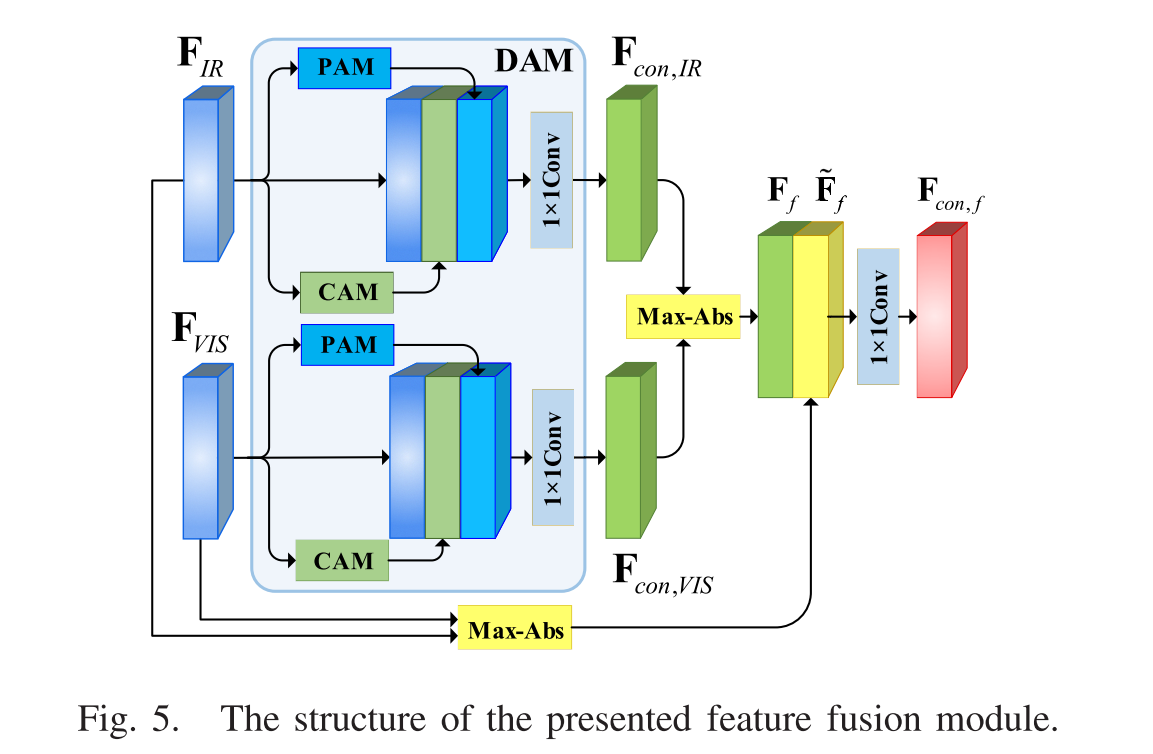
在基于深度学习的图像融合方法中,特征图的融合对提高融合图像的质量起着重要作用。传统的特征融合规则主要包括最大选择、加权平均和特征级联。但是,在大多数方法中,这些规则通常是在原始特征上执行的,而没有考虑不同位置和不同通道的特征之间的相关性和差异。Jian等人通过应用通道注意机制来缓解此问题,但是它忽略了不同空间位置处特征的相互关系。此外,这个通道注意被简单地设计为对所有输入通道的像素级softmax操作。在这项工作中,开发了双重注意机构 (DAM) 来解决上述问题,如图4所示,它由两个部件组成: 位置注意机构 (PAM) 和通道注意机构 (CAM)。
a) Position attention mechanism:
对于提取的特征图,如果将更多的注意力分配给与显着对象或轮廓相对应的系数,则将有利于保留显着源信息。为此,我们开发了一种类似于PAM的U-Net架构来预测不同空间位置的特征的权重,如图4所示。PAM架构主要包含两个阶段: 编码和解码。(略)
位置注意力和通道注意力机制
b) Channel attention mechanism:
在红外和可见光图像融合中,每个特征图 (即通道) 都可以视为源图像中重要目标的响应。对于目标,其在不同渠道中的响应总是不同的,并且应该相互关联。为了强调目标,最好为特征图分配更大的权重,并具有更强的响应。基于此考虑,我们开发了一种新颖的通道注意机制 (CAM),以通过利用不同通道之间的相互依赖性来生成每个通道的权重。
2) Fusion Strategy:
Residual Compensation Module
在我们的融合和超分辨率框架中,我们需要通过MUM将每个特征图的大小增加到目标大小。但是,此过程可能会导致源图像中精细细节的丢失。受反投影网络的启发,我们开发了一种简单而有效的剩余补偿机制来弥补丢失的细节。为此,我们通过模仿MUM来创建meta-downscale模块 (MDM),如图3© 所示。就像MUM一样,MDM还通过将比例因子作为输入来动态预测降尺度滤波器的权重,从而可以任意减小特征图的大小,而无需重复训练。MUM和MDM共同用于设计剩余补偿模块 (RCM)。
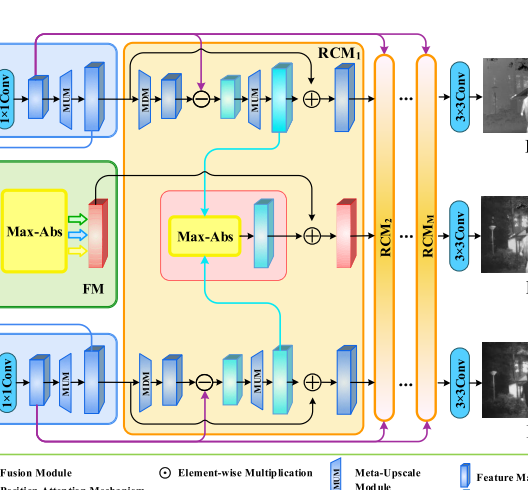
图1中的紫色线条进行相减,然后红外和可见光进行Max-Abs,最后与融合的结果相加,这本质上就是一个补偿的过程。


![[附源码]JAVA毕业设计西安市城市绿地管理系统(系统+LW)](https://img-blog.csdnimg.cn/d90481ddc9be461d8612b8df7035fd0b.png)





![[附源码]Python计算机毕业设计SSM基于售楼系统(程序+LW)](https://img-blog.csdnimg.cn/9e68047509f1454bb95da2b8cfbf51d2.png)

