您好,如果喜欢我的文章,可以关注我的公众号「量子前端」,将不定期关注推送前端好文~
虚拟DOM
我们都知道虚拟DOM带来的好处,多次更新数据层的数据,最后异步处理只进行一次页面重绘,而这中间的奥秘就是虚拟DOM。在传统的Web应用中,我们往往会把数据的变化实时地更新到用户界面中,就这样,每一次改动都引发了页面的重渲染,虚拟DOM的目的就是将这过程中所有的改动都聚集在一起,计算出所有的变化,统一更新一次DOM。
如果有这样的一段模板代码:
<div class="title">
<span>你好</span>
<ul>
<li>吃饭</li>
<li>睡觉</li>
</ul>
</div>
在React中会变转换成虚拟DOM,其实就是一个JS对象:
const vDom = {
type: 'div',
props: { class: 'title' },
children: [
{
type: 'span',
children: '你好'
},
{
type: 'ul',
children: [
{ type: 'li', children: '吃饭' },
{ type: 'li', children: '睡觉' }
]
}
]
}
当我们需要创建或更新视图层时,React会先通过模板创建出这样的虚拟DOM对象,最后再将该对象转换为真实DOM(唯一一次视图更新),当然,在实际React虚拟DOM中是不止这些基本类型的,React会通过React.createElement的方式将整个模板转换成虚拟DOM对象,案例最终生成的虚拟DOM对象如下结构:

-
typeof:元素类型,可以是原生元素(span/ul/div)、文本或React组件(ReactComponent);
-
key:每个元素的唯一标识,用于Diff算法比较页面元素更新前后差异,下一节会讲到;
-
ref:访问原生DOM节点,在React中用于特殊情况手动操作DOM;
- props:元素传参,如类名、innerHTML,也可以是一个新的元素(嵌套元素),或者是React组件;
- owner:当前正在构建的节点所属于哪个React组件;
- self:指定位于哪个组件实例(非生产环境);
- _source:元素代码来自于哪个文件以及代码行数,相当于sourcemap(非生产环境);
因此传说中的虚拟DOM本身其实并不稀奇,只是一个JS对象,里面嵌套了许多JS对象,就像是一个树节点,因此在React中,组件模板必须只能有一个根元素,这样就是一个唯一父节点向下向内扩展的数据结构,如果有多个根节点就会变得情况非常复杂,不利于框架本身维护。
如果页面结构复杂再去通过React.createElement的方式去转换虚拟DOM对象,对于开发者而言会变得非常复杂且消耗很多的心智,因此React官方推出了JSX语法,JSX就是JS的扩展,让JavaScript语言获得了模板化,你只需要像这样去写模板,React会通过JSX Babel插件来转换为React.createElement,因此JSX也是其语法糖形式。
const Index = () => {
return (
<div>
你好
<p>欢迎</p>
<Children>这是子组件</Children>
</div>
)
}
上面的React JSX模板会被Babel解析成React.createElement版本的形式:
const Index = () => {
return (
React.createElement(
'div',
null,
'你好',
React.createElement('p', null, '欢迎'),
React.createElement('Children', null. '这是子组件')
)
)
}
可以感受到,通过JSX语法来代替React.createElement写法大大降低了开发者框架层面带来的负担,可以专注于业务本身。同时提一嘴,为什么React中的组件必须要大写呢?由于要通过Babel进行转换,需要一个条件来判断该节点为原生标签还是React组件,而React也是通过首字母大写来判定节点为元素还是React组件。
Diff算法
React多次更新只进行一次重绘的奥妙——虚拟DOM,那么React是如何进行更新前后的对比,最后进行唯一一次的更新的呢?React会维护两个虚拟DOM树,那么是如何来对比、判断,做出最优的解法呢?这就用到了Diff算法。
在React中,最值得夸赞的就是虚拟DOM和Diff算法的结合,Diff算法并非首创,在Vue中也有Diff算法的概念,React引入Diff算法的基础上做了质的优化,如果在计算一棵树到另一棵树有哪些节点发生变化时,传统Diff算法会通过循环+递归的形式去依次对比,并且该过程不可逆,时间复杂度达到了O(n^3),简单理解,如果有一千个节点,就需要计算十亿次。
而React的Diff算法的时间复杂度只有O(n),如果有一千个节点,只需要计算一千次,这是非常巨大的优化,而这优化的过程主要通过了三种策略,分别对应:Tree Diff、Component Diff、Element Diff。
-
Web UI 中 DOM 节点跨层级的移动操作特别少,可以忽略不计;
-
拥有相同类的两个组件将会生成相似的树形结构,拥有不同类的两个组件将会生成不同的树形结构;
-
对于同一层级的一组子节点,它们可以通过唯一 id 进行区分;
按顺序讲解下,首先是Tree Diff:同级比较,既然DOM节点跨层级的移动少到可以忽略不计,React通过了update Depth对虚拟DOM进行层级控制,在同一层如果发现某个子节点不在了,会完全删除并中断向下的比较,这样只遍历一次即可,举个例子:
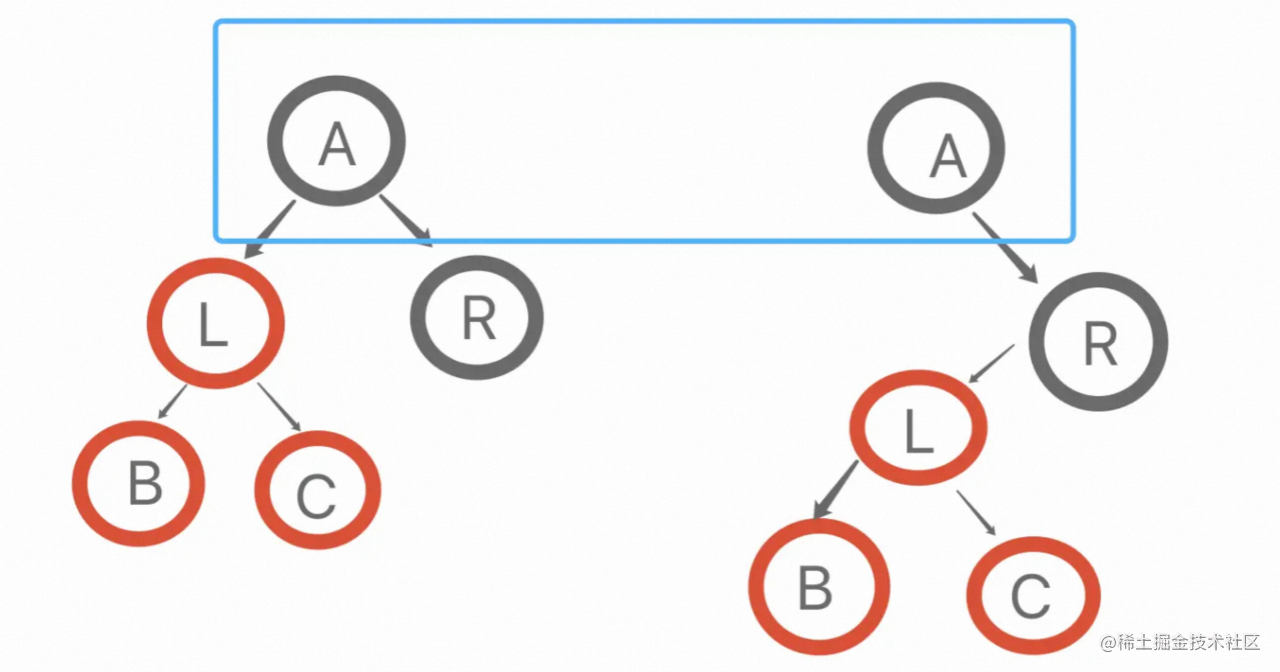
如上图所示,在Diff时会一层一层的比较,也就是蓝框的地方,到第二层的时候会发现R节点还在并且属性和节点类型都一致,但是L节点消失了,此时React会直接删除L节点,重新创建。
其次是Component Diff,组件比较,对于React目前策略一共有两种:
-
相同类型的组件;
-
不同类型的组件;
对于同类型组件,进行常规的虚拟DOM判断即可,但是会有特殊情况,例如当组件A变化到组件B的时候,虚拟DOM没有发生任何变化,所以用户可以通过shouldComponentUpdate来决定是否需要更新和计算。
对于不同类型组件而言,例如组件名不同、组件类型不同(class -> function),React会统一认定为dirty component(脏组件),会直接删除该组件进行重新创建,不做Diff比较。
举个例子:
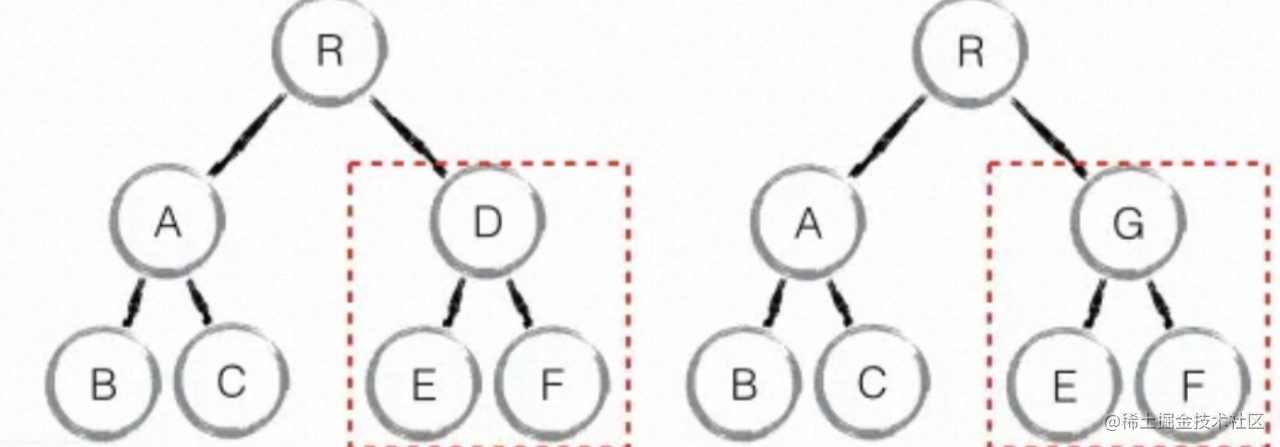
当比较D -> G时,虽然两个组件的结构非常相似,但是React判定D为dirty component,就会直接删除D,重新构建G,两个组件不同,结构类似的情况也是非常少的。
最后就是节点对比(Element Diff),对于同一层级的节点进行唯一Key的比较,当所有的节点在同一层级时包含三种操作:插入(INSERT_MARKUP)、移动(MOVE_EXISTING)、删除(REMOVE_NODE)。
-
INSERT_MARKUP:当新的节点不在老的层级中,直接插入到新的层级中。如:C不在A、B中,直接插入; -
MOVE_EXISTING:在老的层级中有的节点并且在新层级中也有,属性相同、可以复用的情况,采取移动的方式复用以前的DOM节点。如:老层级为A、B、C、D,新层级为A、D、C、B,节点相同,只是位置发生了变化,这种情况只需要复用+移动即可, -
REMOVE_NODE:老层级中有的节点,新层级中没有的节点,直接删除,或者新旧节点属性发生变化,无法复用,也会执行删除。如:老层级为A、B、C、D,新层级为A、B、C。直接删除D节点。
举例两个实际场景:
场景一:相同节点,移动复用。
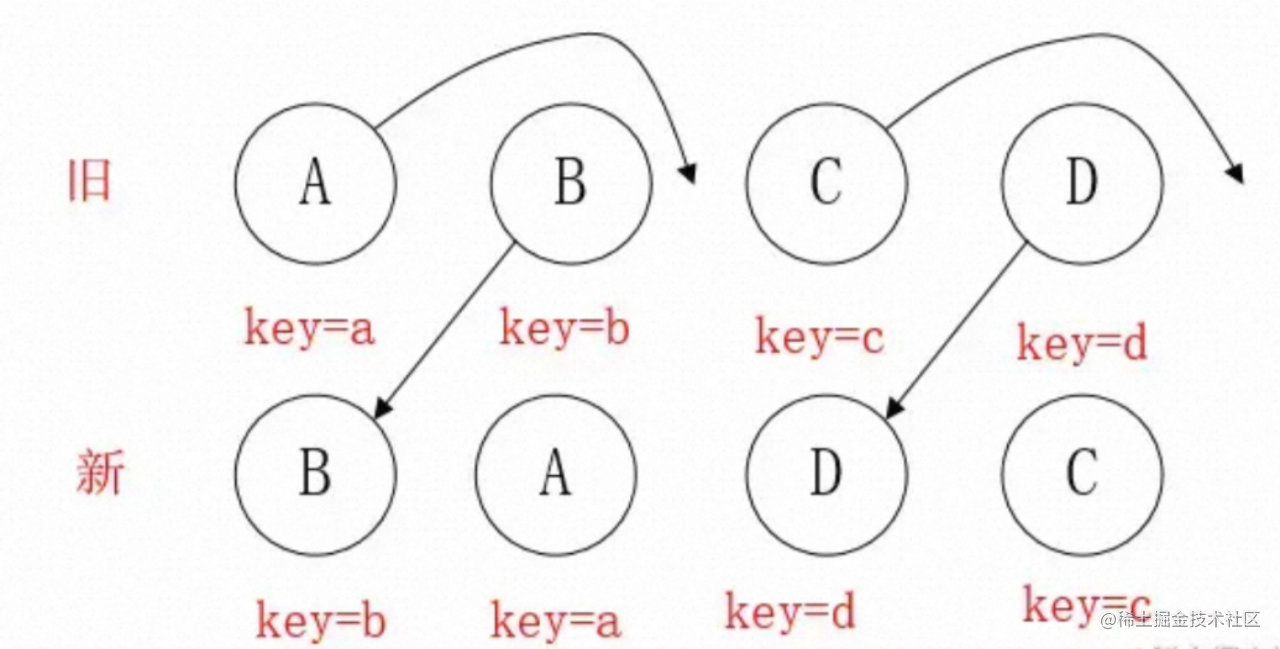
-
React开始遍历新层级,遇到B节点,判断在旧层级中是否出现,发现了B节点,判断是否要移动B;
-
判断一个节点是否移动的条件为
index<lastIndex,index为旧层级的下标,lastIndex为新层级中的下标或者移动后的下标,取Math.max(index, lastIndex),对于B,index=1、lastIndex=0,因此不满足移动条件; -
此时到了A的比较,
index为0,lastIndex为1,满足index<lastIndex的条件,移动A节点,lastIndex为1; -
相同的方式到了D节点,
index为3,lastIndex为1,不满足index<lastIndex的条件,不移动,并且lastIndex更新到3; -
最后到了C节点,
index为2,lastIndex为3,满足条件,移动C,lastIndex还是3,此时该层级Element Diff结束;
场景二:有新节点加入、删除节点:
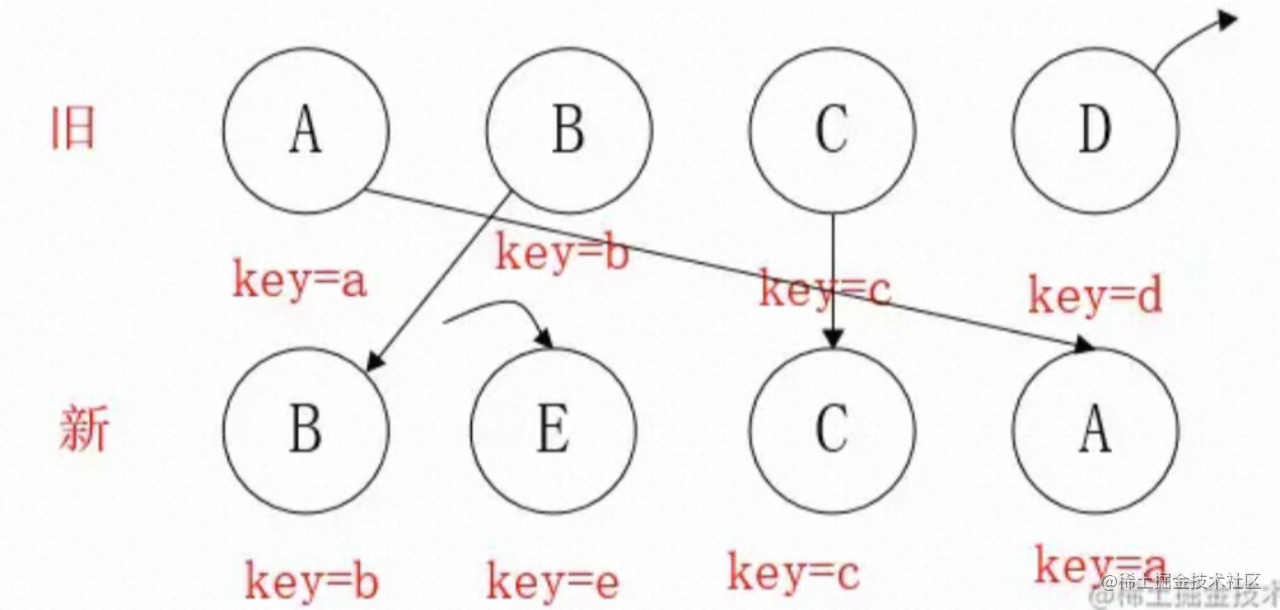
-
B与上述例子一样,不移动,
lastIndex为1; -
发现没有E节点,直接创建,此时
lastIndex还是1; -
到C节点,
index=2,lastIndex=1,不满足index < lastIndex的条件,不移动C,lastIndex更新到2; -
到A节点,
index=0,lastIndex=2,index < lastIndex,移动A节点; -
不存在D节点,删除D节点;
再来看一下这种特殊情况:
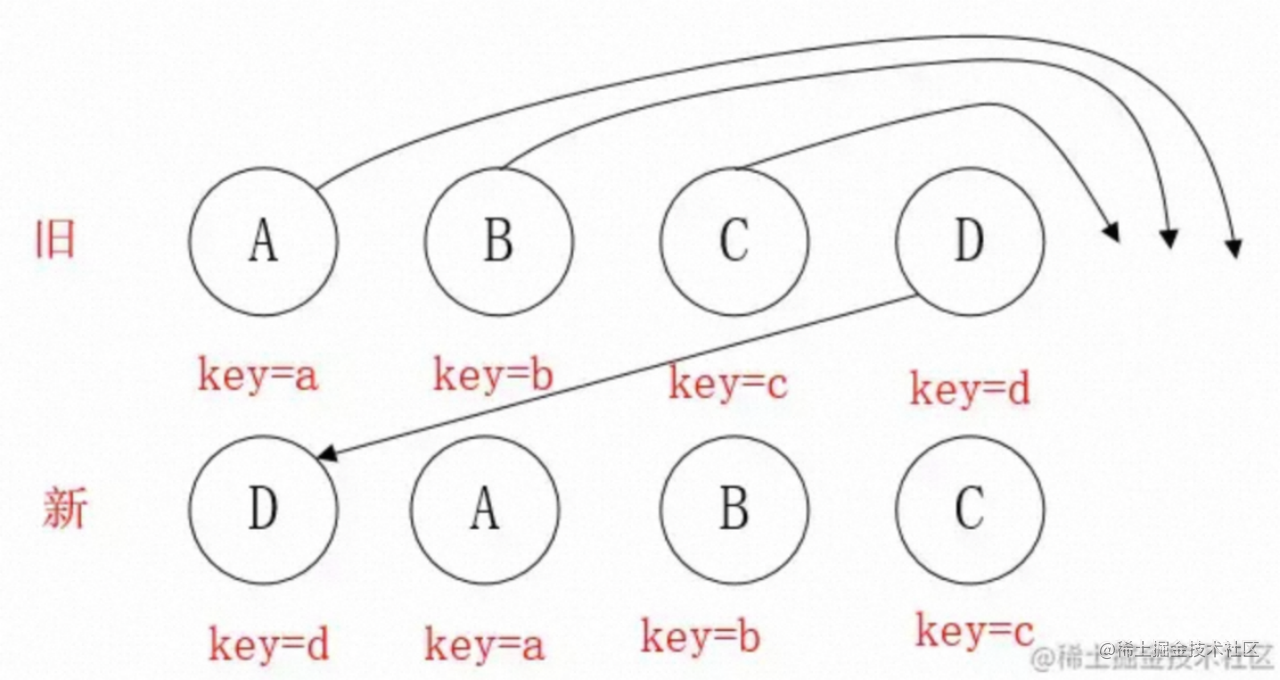
走到D节点,index=3,lastIndex=0,移动D节点,这样lastIndex为3,后续节点都满足移动条件,会影响性能,因此开发中要减少尾部节点移动到首部的操作。
Key
还有一个热门话题,为什么遍历时不要用index作为节点的key?举个例子:
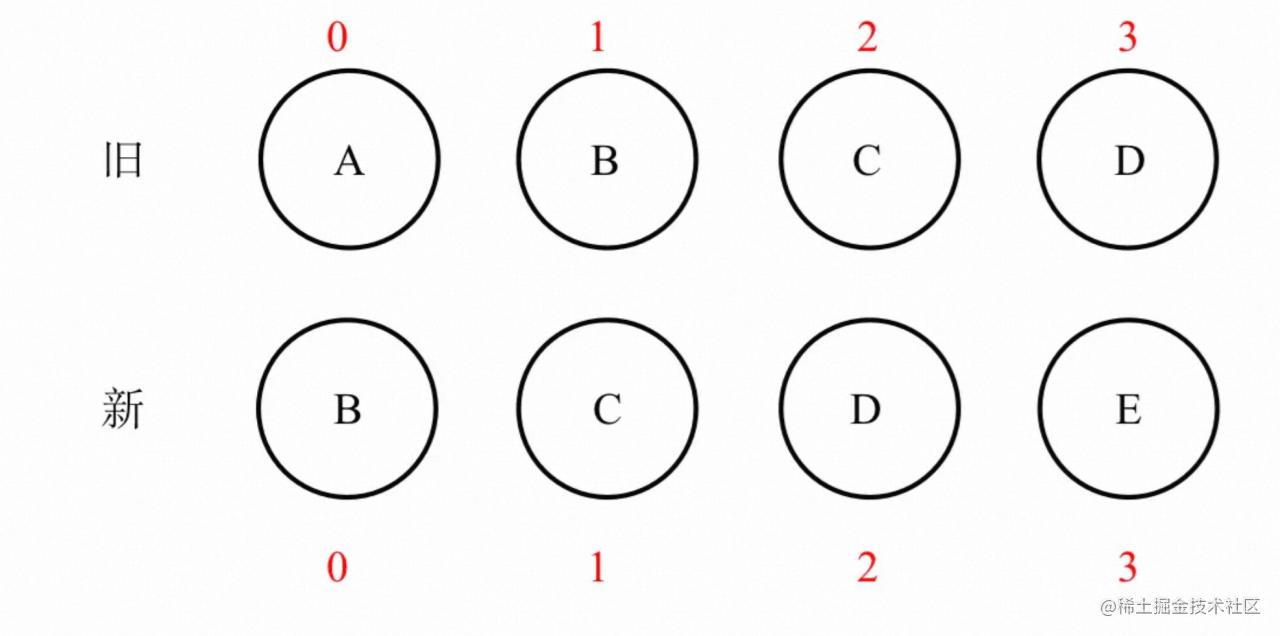
当循环时,假设有一个长度为100的数组,如果在index为10的时候破坏了后续数组的排列,比如插入或删除了一个节点,长度变成了99或101,这样后续的节点index全部发生了变化,就像这段代码一样:
const Index = () => {
const [list, setList] = useState(new Array(100).map((item, index) => index));
const change = () => {
setList((old) => {
old.splice(10, 1, 'new');
return [...old];
})
}
return (
<>
{
list.map((_, index) => {
return <div key={index}>{index}</div>
})
}
</>
<button onClick={change}>改变</button>
)
}
对于避免这样大量的性能消耗,你应该将key改为每个遍历节点本身的值,换句话说,上一轮渲染和下一轮渲染中,因为改变某个节点而被依赖改变的节点给定一个唯一标识,避免它被依赖重建。
实际上都是没有变化过的节点,因此key在某一次遍历中或是对于整个数组所有数据变化(分页)时是可用的,其余情况都应该用唯一标识来作为key。如果数组的长度为一万,性能损耗不堪设想。
结尾
如果读完这篇文章让你对于React原理有了更深一步的理解,欢迎留言讨论、点赞收藏。
如果喜欢我的文章,可以关注我的公众号「量子前端」,将不定期关注推送前端好文~