本文章续接上篇文章
目录
1.数据抽取
1.1 抽取一行数据
1.2 抽取多行数据
1.3 抽取指定列数据
1.4 抽取指定行、列数据
1.5 按指定条件抽取数据
2、数据的增加、删除和修改
2.1 数据增加
2.2 修改数据
2.3 删除数据
1.数据抽取
数据分析过程中,并不是所有的数据都是我们想要的,此时可以抽取部分数据,主要使用DataFrame对象的loc属性和iloc属性。
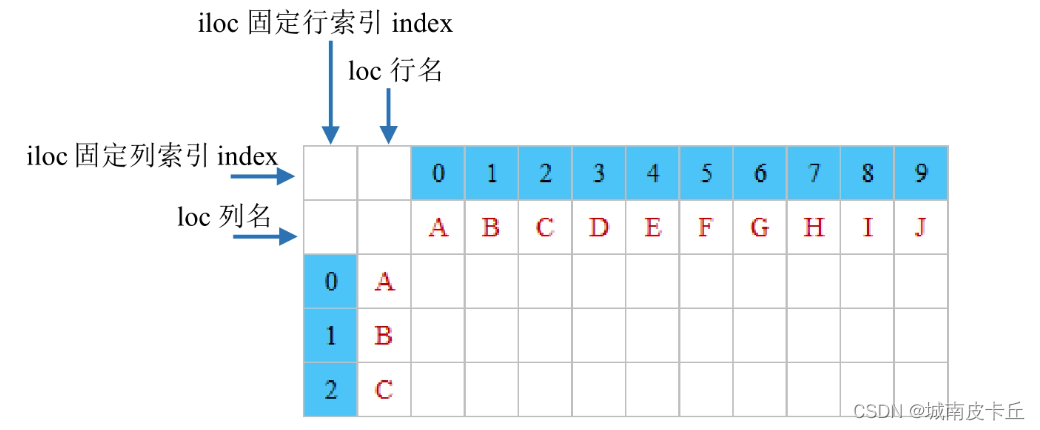
对象的loc属性和iloc属性都可以抽取数据,区别如下
- loc属性:以列名(columns)和行名(index)作为参数,当只有一个参数时,默认是行名,即抽取整行数据,包括所有列,如df.loc['A']
- iloc属性:以行和列位置索引(即0,1,2,…)作为参数,0表示第1行,1表示第2行,以此类推。当只有一个参数时,默认是行索引,即抽取整行数据,包括所有列。如抽取第1行数据,df.iloc[0]
1.1 抽取一行数据
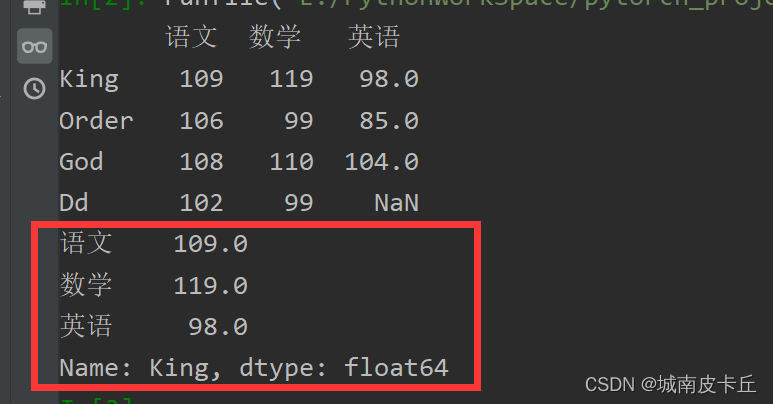
抽取一行数据主要使用loc属性。例如,抽取一行名为“King”的考试成绩数据(包括所有列),程序代码如下:
data=[[109,119,98],[106,99,85],[108,110,104],[102,99]]
name=['King','Order','God','Dd']
columns=['语文','数学',"英语"]
df=pd.DataFrame(data=data,index=name,columns=columns)
print(df)
print(df.loc['King'])
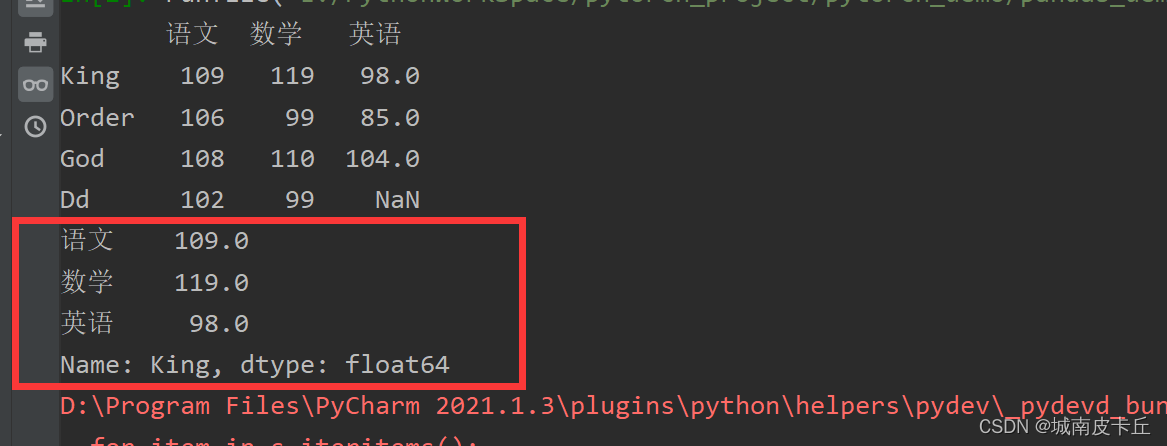
使用iloc属性抽取第1行数据,指定行索引即可,如df.iloc[0],输出结果同上图一样。
data=[[109,119,98],[106,99,85],[108,110,104],[102,99]]
name=['King','Order','God','Dd']
columns=['语文','数学',"英语"]
df=pd.DataFrame(data=data,index=name,columns=columns)
print(df)
print(df.iloc[0])
1.2 抽取多行数据
通过loc属性和iloc属性指定行名和行索引即可实现抽取任意多行数据。例如,抽取行名为“King”和“God”(即第1行和第3行数据)的考试成绩数据,可以使用loc属性,也可以使用iloc属性,其输出结果都是一样的,主要代码如下:
data=[[109,119,98],[106,99,85],[108,110,104],[102,99]]
name=['King','Order','God','Dd']
columns=['语文','数学',"英语"]
df=pd.DataFrame(data=data,index=name,columns=columns)
print(df)
print("--------------------")
print(df.iloc[[0,2]])
print("--------------")
print(df.loc[['King','God']])
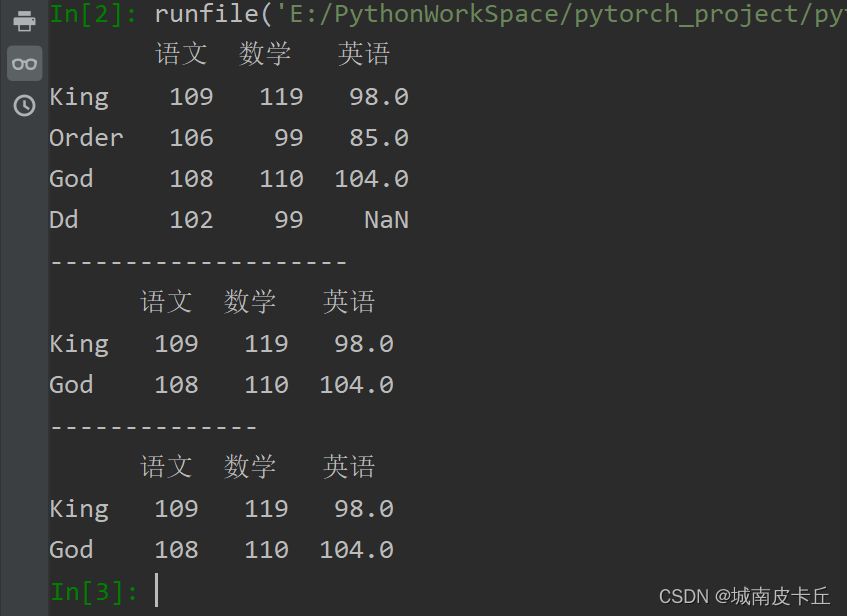
在loc属性和iloc属性中合理地使用冒号(:),即可抽取连续任意多行数据
print(df.iloc[0:2])#抽取第一行到第二行
print("--------------")
print(df.loc['King':'God'])#抽取King到God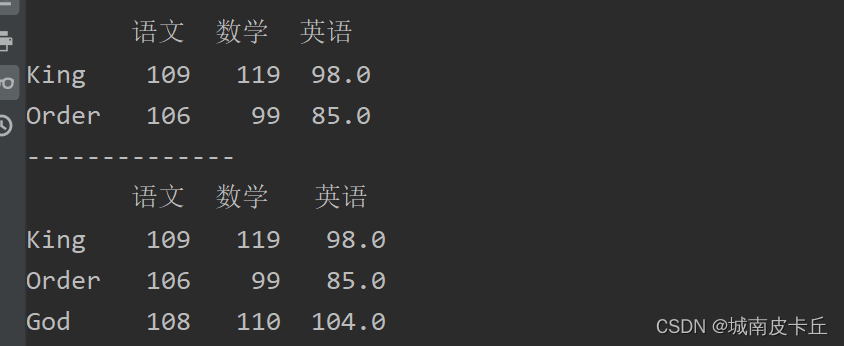
print(df.loc[:'God':])#抽取第一行到God
print("-------------------")
print(df.iloc[1::])#抽取第二行到最后一行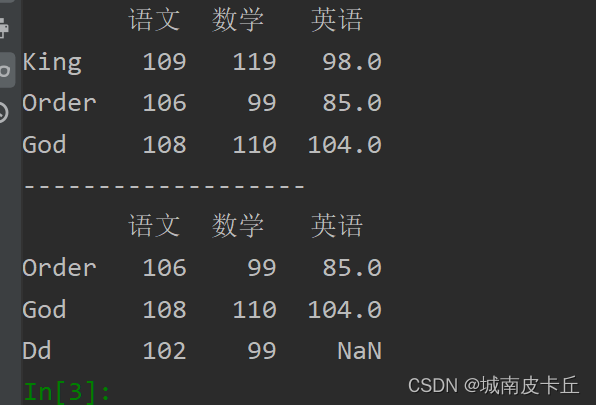
1.3 抽取指定列数据
抽取指定列数据,可以直接使用列名,也可以使用loc属性和iloc属性。
(1)使用列名
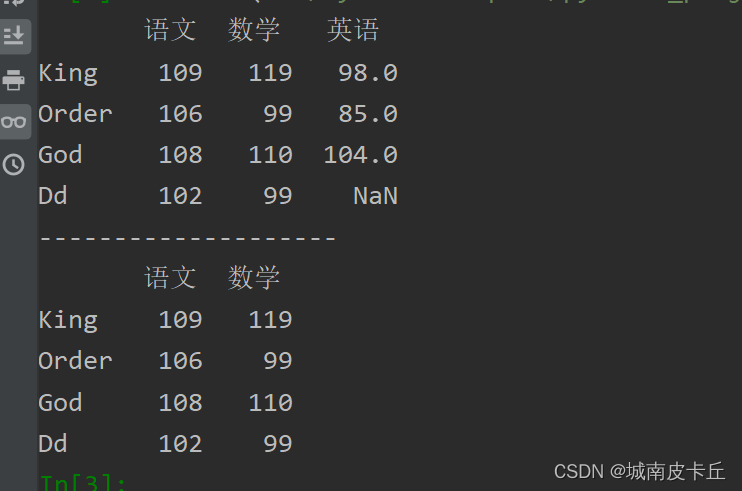
例如,抽取列名为“语文”和“数学”的考试成绩数据,程序代码如下:
data=[[109,119,98],[106,99,85],[108,110,104],[102,99]]
name=['King','Order','God','Dd']
columns=['语文','数学',"英语"]
df=pd.DataFrame(data=data,index=name,columns=columns)
print(df)
print("--------------------")
print(df[['语文','数学']])
(2)使用loc属性和iloc属性
前面介绍loc属性和iloc属性均有两个参数:第一个参数代表行;第二个参数代表列。那么这里抽取指定列数据时,行参数不能省略。
下面使用loc属性和iloc属性抽取指定列数据,主要代码如下:
data=[[109,119,98],[106,99,85],[108,110,104],[102,99]]
name=['King','Order','God','Dd']
columns=['语文','数学',"英语"]
df=pd.DataFrame(data=data,index=name,columns=columns)
print(df)
print("--------------------")
print(df.loc[:,['语文','数学']])#抽取语文和数学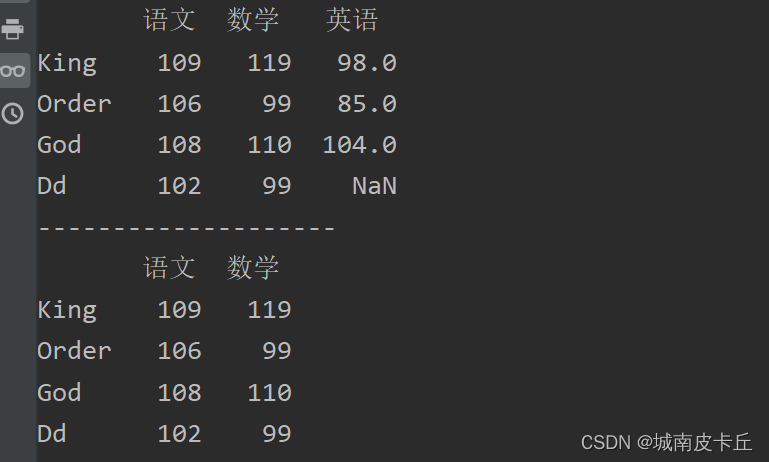
data=[[109,119,98],[106,99,85],[108,110,104],[102,99]]
name=['King','Order','God','Dd']
columns=['语文','数学',"英语"]
df=pd.DataFrame(data=data,index=name,columns=columns)
print(df)
print("--------------------")
print(df.loc[:,'语文':])#抽取从语文到最后一列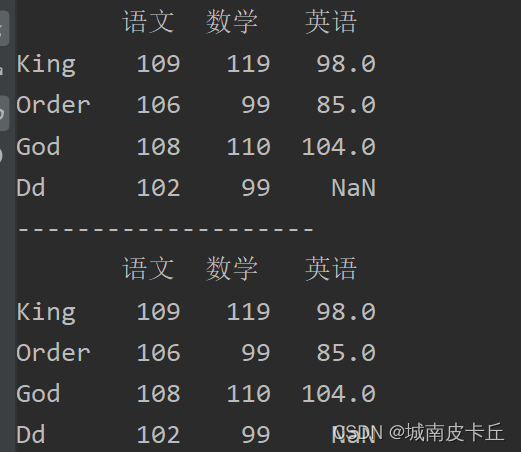
data=[[109,119,98],[106,99,85],[108,110,104],[102,99]]
name=['King','Order','God','Dd']
columns=['语文','数学',"英语"]
df=pd.DataFrame(data=data,index=name,columns=columns)
print(df)
print("--------------------")
print(df.iloc[:,[0,1]])#抽取第一列和第二列
print("--------------------")
print(df.iloc[:,:2])#连续抽取从第1列开始到第3列,但不包括第3列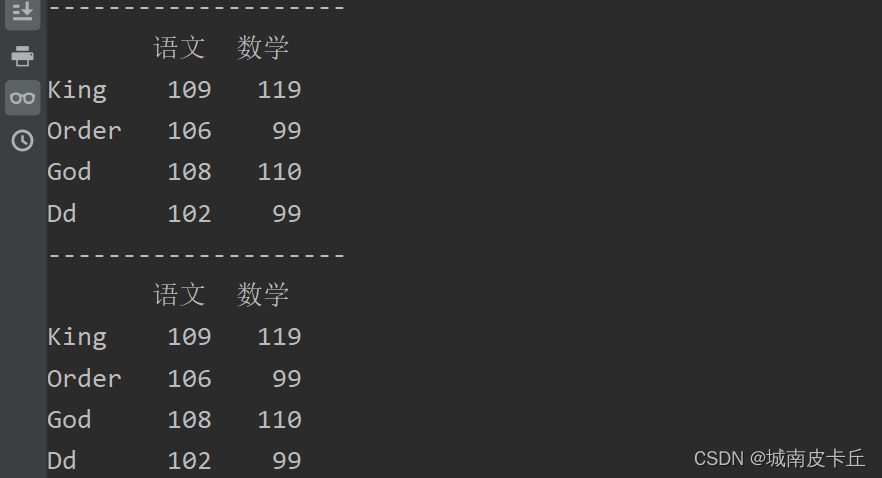
1.4 抽取指定行、列数据
抽取指定行、列数据主要使用loc属性和iloc属性,这两个方法的两个参数都指定就可以实现指定行、列数据的抽取。
使用loc属性和iloc属性抽取指定行、列数据,程序代码如下:
data=[[109,119,98],[106,99,85],[108,110,104],[102,99]]
name=['King','Order','God','Dd']
columns=['语文','数学',"英语"]
df=pd.DataFrame(data=data,index=name,columns=columns)
print(df)
print("--------------------")
print(df.loc['King','数学'])#抽取King的数学成绩
print("--------------------")
print(df.loc['King',['数学']])#抽取King的数学成绩
print("--------------------")
print(df.loc[['King'],['数学']])#抽取King的数学成绩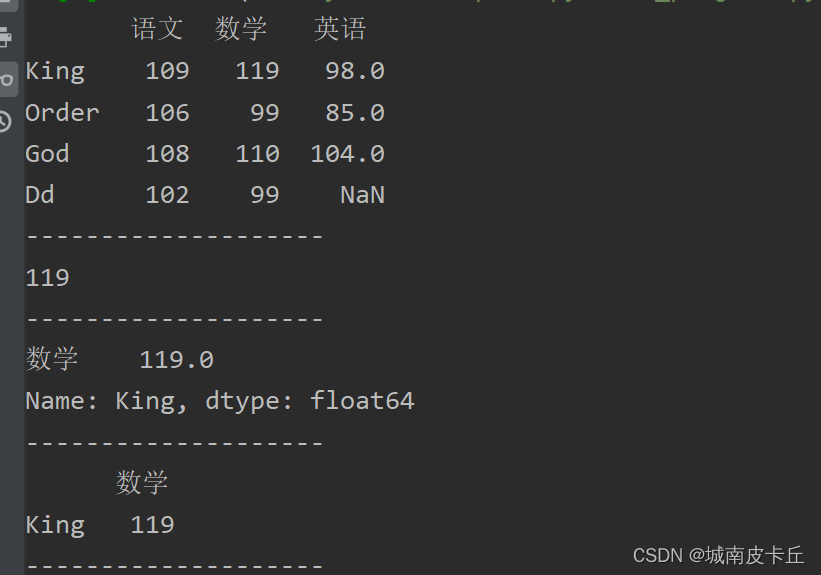
注意,在上述结果中,第一个输出结果是一个数,不是数据,是由于“df.loc['King','数学']”没有使用方括号[],导致输出的数据不是DataFrame类型。
data=[[109,119,98],[106,99,85],[108,110,104],[102,99]]
name=['King','Order','God','Dd']
columns=['语文','数学',"英语"]
df=pd.DataFrame(data=data,index=name,columns=columns)
print(df)
print("--------------------")
print(df.loc[['Order'],['语文','英语']])#抽取Order的语文和英语成绩
print("--------------------")
print(df.loc[['Order','Dd'],['语文','英语']])#抽取Order、Dd的语文和英语成绩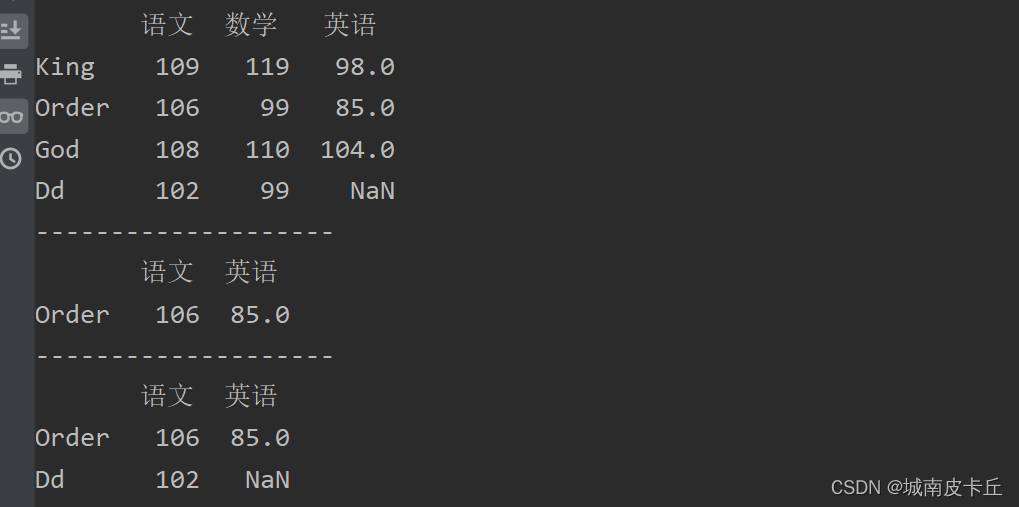
print(df.iloc[[1],[2]])#抽取第二行第三列
print("##################")
print(df.iloc[1,2])#抽取第二行第三列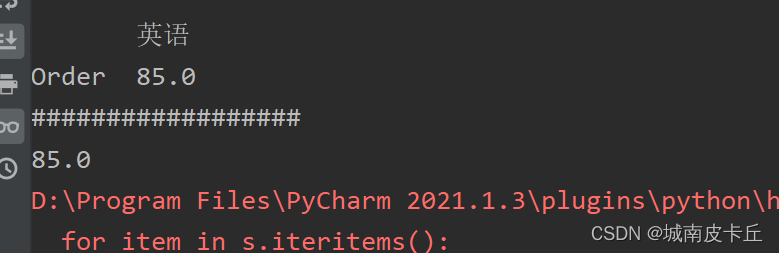
data=[[109,119,98],[106,99,85],[108,110,104],[102,99]]
name=['King','Order','God','Dd']
columns=['语文','数学',"英语"]
df=pd.DataFrame(data=data,index=name,columns=columns)
print(df)
print("--------------------------")
print(df.iloc[1:,[2]])#抽取第二行到最后一行的第三列
print("##################")
print(df.iloc[1:,[0,2]])#抽取第二行到最后一行的第一、三列
print("-------------")
print(df.iloc[:,2])#所有行第3列语文 数学 英语
King 109 119 98.0
Order 106 99 85.0
God 108 110 104.0
Dd 102 99 NaN
--------------------------
英语
Order 85.0
God 104.0
Dd NaN
##################
语文 英语
Order 106 85.0
God 108 104.0
Dd 102 NaN
-------------
King 98.0
Order 85.0
God 104.0
Dd NaN
Name: 英语, dtype: float64
1.5 按指定条件抽取数据
DataFrame对象实现数据查询有以下3种方式。
例如,抽取语文成绩大于105,数学成绩大于80的数据,程序代码如下:
data=[[109,119,98],[106,99,85],[108,110,104],[102,99]]
name=['King','Order','God','Dd']
columns=['语文','数学',"英语"]
df=pd.DataFrame(data=data,index=name,columns=columns)
print(df)
print("========================")
print(df.loc[(df['语文']>105)&(df['数学']>80)])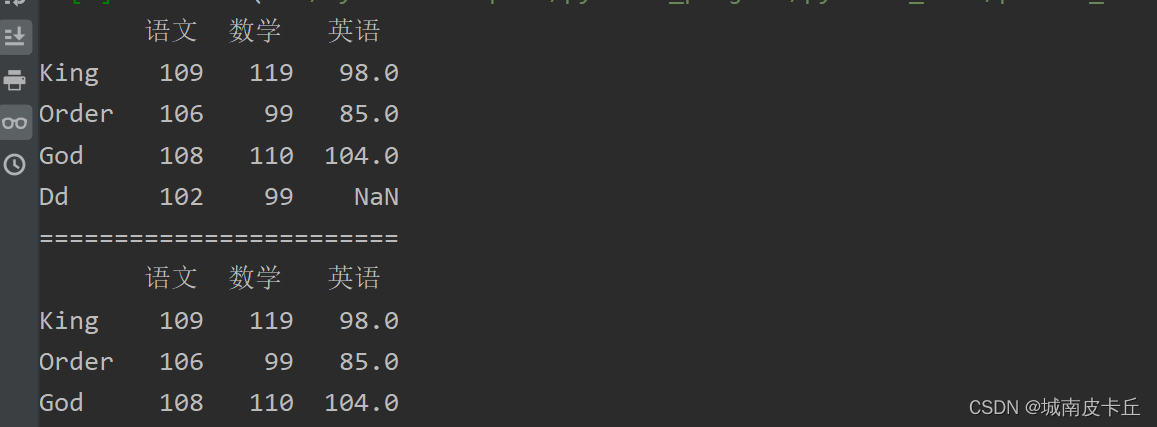
2、数据的增加、删除和修改
2.1 数据增加
DataFrame对象增加数据主要包括列数据增加和行数据增加。首先看一下原始数据
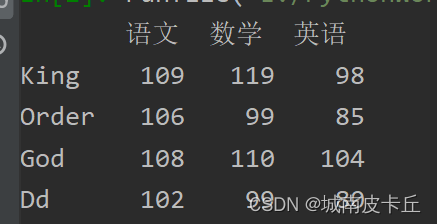
(1)按列增加数据
按列增加数据,可以通过以下3种方式实现:
1、直接为DataFrame对象赋值
例如,增加一列“物理”成绩,程序代码如下:
data=[[109,119,98],[106,99,85],[108,110,104],[102,99,80]]
name=['King','Order','God','Dd']
columns=['语文','数学',"英语"]
df=pd.DataFrame(data=data,index=name,columns=columns)
print(df)
df['物理']=[90,89,87,99]
print(df)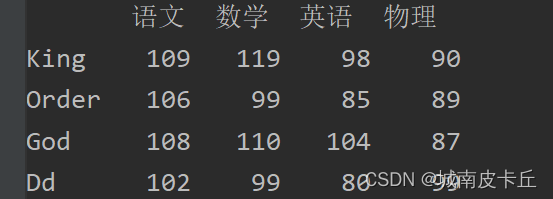
2、使用loc属性在DataFrame对象的最后增加一列
使用loc属性在DataFrame对象的最后增加一列。例如,增加“物理”一列,主要代码如下:
data=[[109,119,98],[106,99,85],[108,110,104],[102,99,80]]
name=['King','Order','God','Dd']
columns=['语文','数学',"英语"]
df=pd.DataFrame(data=data,index=name,columns=columns)
print(df)
print("-------------")
# df['物理']=[90,89,87,99]
df.loc[:,'物理']=[90,89,87,99]
print(df)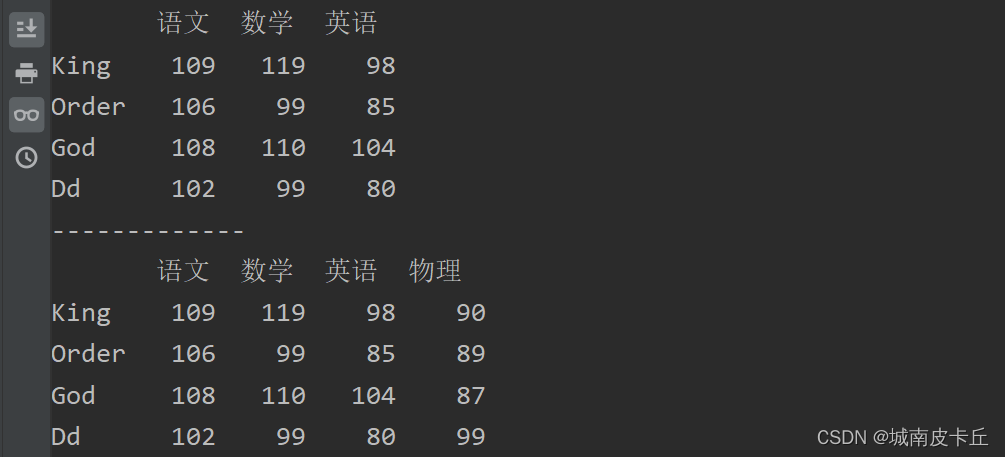
3、在指定位置插入一列
在指定位置插入一列,主要使用insert()方法。例如,在第1列后面插入“物理”,其值为wl的数值,主要代码如下:
wl=[90,89,87,99]
df.insert(1,'物理',wl)
print(df)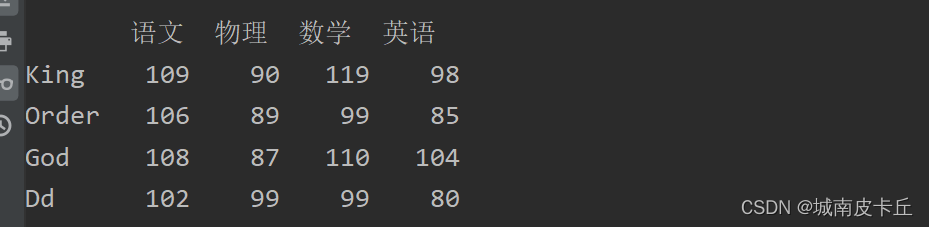
(2)按行增加数据
按行增加数据,可以通过以下两种方式实现。
1.增加一行数据
增加一行数据主要使用loc属性实现。例如,在成绩表中增加一行数据,即“wyy”同学的成绩,主要代码如下:
df.loc['wyy']=[100,109,98]
print(df)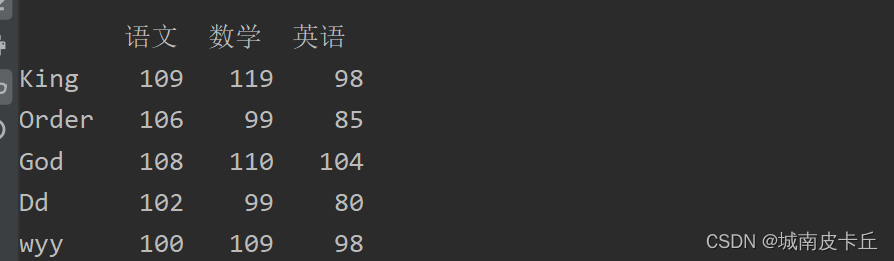
2.增加多行数据
增加多行数据主要使用字典结合append()方法实现。例如,在原有数据中增加“wyy”“wxx”“alan”同学的考试成绩,主要代码如下:
df_insert=pd.DataFrame(
{
'语文':[100,109,101],
'数学':[103,113,93],
'英语':[92,97,99]
},
index=['wyy','wxx','alan']
)
df=df.append(df_insert)
print(df)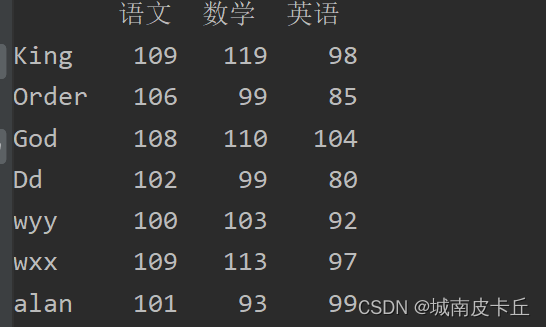
2.2 修改数据
修改数据包括行、列标题和数据的修改,首先看一下原始数据。
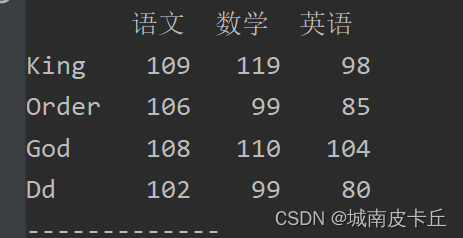
(1)修改列标题
修改列标题主要使用DataFrame对象的cloumns属性,直接赋值即可。
例如,将“数学”修改为“数学(上)”,主要代码如下:
df.columns=['语文','数学(上)','英语']
print(df)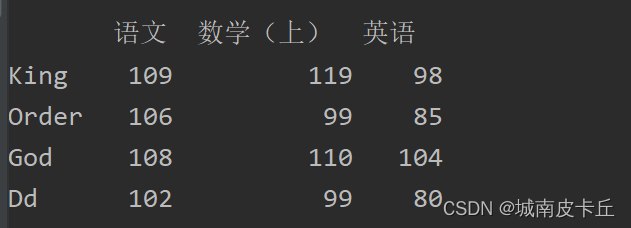
上述代码中,即使只修改“数学”为“数学(上)”,但是也要将所有列的标题全部写上;否则将报错。
有例如,修改多个学科的列名。将“语文”修改为“语文(上)”、“数学”修改为“数学(上)”、“英语”修改为“英语(上)”,主要代码如下:
df.rename(columns={'语文':'语文(上)','数学':'数学(上)','英语':'英语(上)'},inplace=True)
print(df)
上述代码中,参数inplace为True,表示直接修改df;否则,不修改df,只返回修改后的数据。
(2)修改行标题
修改行标题主要使用DataFrame对象的index属性,直接赋值即可。
例如,将行标题统一修改为数字编号。
df.index=list('1234')
print(df)
使用DataFrame对象的rename()方法也可以修改行标题。例如,将行标题统一修改为数字编号,主要代码如下:
df.rename({'King':1,'Order':2,'God':3,'Dd':4},axis=0,inplace=True)
print(df)
(3)修改数据
修改数据主要使用DataFrame对象的loc属性和iloc属性。
1.修改整行数据。例如,例如,修改“King”同学的各科成绩,主要代码如下:
df.loc['King']=[100,100,100]
print(df)
print("-------------------")
df.loc['King']=df.loc['King']#各科成绩均加10分
print(df)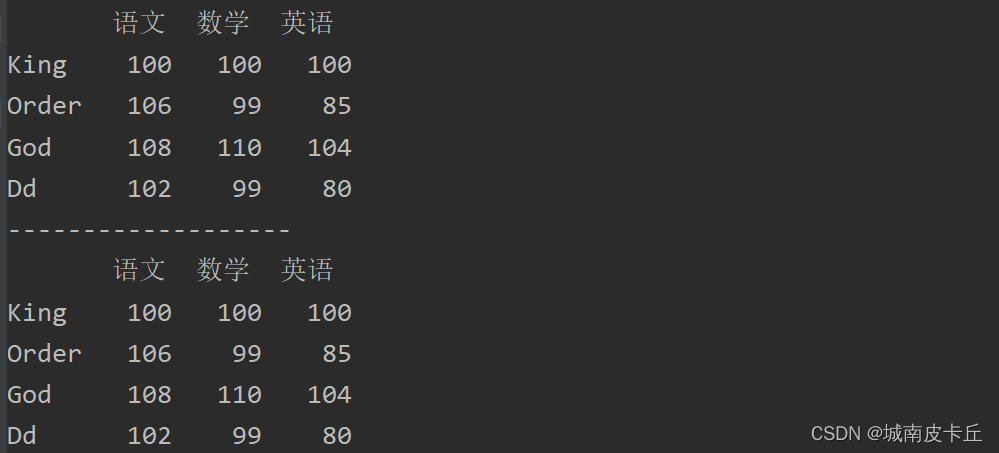
2.修改整列数据
例如,例如,修改所有同学的“语文”成绩,主要代码如下:
df.loc[:,'语文']=[109,103,108,98]
print(df)
3.修改某一数据
例如,修改“King”同学的“语文”成绩,主要代码如下:
df.loc['King','语文']=90
print(df)
4.使用iloc属性修改数据
通过iloc属性指定行、列位置实现修改数据,主要代码如下:
df.iloc[0,0]=115#修改第一行第一列数据
df.iloc[:,0]=[117,107,103,99]#修改第一列数据
df.iloc[0,:]=[100,100,100]#修改第一行数据
2.3 删除数据
删除数据主要使用DataFrame对象的drop()方法。语法如下
DataFrame.drop(labels=None, axis=0, index=None, columns=None, level=None, inplace=False, errors='raise')
- labels:表示行标签或列标签。
- axis:axis = 0,表示按行删除;axis = 1,表示按列删除。默认值为0,即按行删除。
- index:删除行,默认值为None。
- columns:删除列,默认值为None。
- level:针对有两级索引的数据。level = 0,表示按第1级索引删除整行;level = 1表示按第2级索引删除整行,默认值为None。
- inplace:可选参数,对原数组做出修改并返回一个新数组。默认值为False,如果值为True,那么原数组直接就被替换。
- errors:参数值为ignore或raise,默认值为raise,如果值为ignore(忽略),则取消错误。
(1) 除指定的学生成绩数据,主要代码如下:
#删除列名为'数学'的列
df.drop(['数学'],axis=1,inplace=True)
df.drop(columns='数学',inplace=True)
df.drop(labels='数学',axis=1,inplace=True)
df.drop(['God','Dd'],inplace=True)#删除多行
df.drop(index='King',inplace=True)#删除index为'King'的行
df.drop(labels='Order',axis=0,inplace=True)#删除标签为'Order'的行(2)删除特定条件的行
删除满足特定条件的行,首先找到满足该条件的行索引,然后再使用drop()方法将其删除。
例如。删除“数学”成绩中等于110的行、“语文”成绩小于110的行,主要代码如下:
df.drop(index=df[df['数学'].isin([110])].index[0],inplace=True)
df.drop(index=df[df['语文']<110].index[0],inplace=True)