目录
- 前言
- 一、paddleNLP介绍、特性
- 1-1、介绍
- 1-2、特性介绍
- 二、paddleNLP安装
- 三、PaddleNLP一键使用
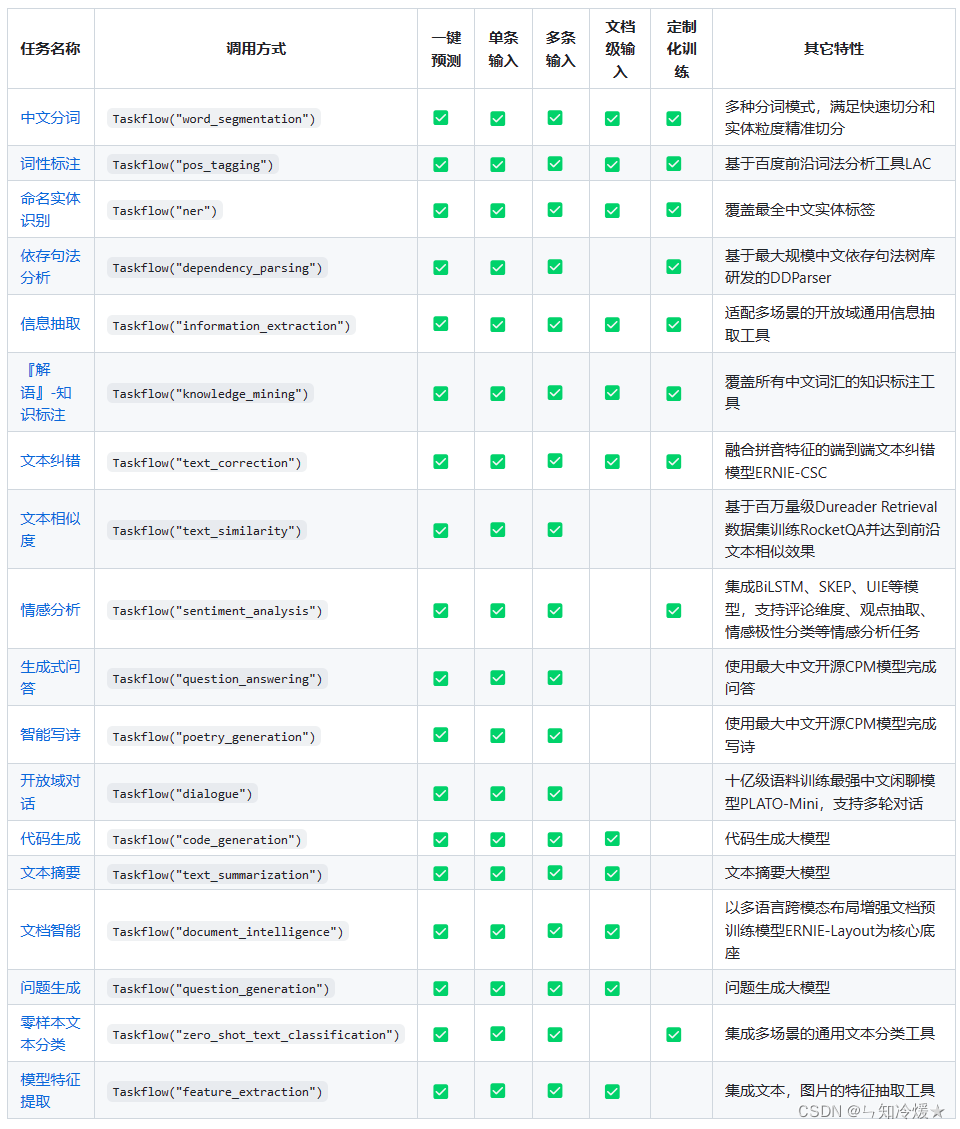
- 3-1、中文分词
- 3-2、词性标注
- 3-3、命名实体识别
- 3-4、依存句法分析(DDParser)
- 3-5、解语知识标注
- 3-6、文本纠错(ERNIE-CSC)
- 3-7、文本相似度(SimBERT)
- 3-8、情感分析(BiLSTM、SKEP、UIE)
- 3-9、生成式回答(CPM)
- 3-10、智能写诗(CPM)
- 3-11、开放领域回答(PLATO-Mini)
- 3-12、代码生成
- 3-13、文本摘要
- 3-14、文档智能
- 3-15、问题生成
- 3-16、零样本文本分类(UTC)
- 3-17、模型特征提取
- 总结
前言
PaddleNLP是一个基于PaddlePaddle深度学习平台的自然语言处理(NLP)工具库。它提供了一系列用于文本处理、文本分类、情感分析、机器翻译、文本生成等任务的预训练模型、模型组件和工具函数。一、paddleNLP介绍、特性
1-1、介绍

PaddleNLP是一个基于PaddlePaddle深度学习平台的自然语言处理(NLP)工具库。它提供了一系列用于文本处理、文本分类、情感分析、机器翻译、文本生成等任务的预训练模型、模型组件和工具函数。
以下是PaddleNLP的一些主要功能和特点:
- 预训练模型:PaddleNLP提供了多个预训练模型,包括BERT、ERNIE、RoBERTa、GPT等,这些模型在各种NLP任务中取得了优异的性能表现。用户可以通过PaddleNLP加载这些预训练模型,进行特征提取、文本分类、序列标注等任务。
- 模型组件:PaddleNLP提供了各种常用的NLP模型组件,例如词向量(Word Embedding)、注意力机制(Attention Mechanism)、编码器(Encoder)等,用户可以使用这些组件构建自定义的NLP模型。
- 数据处理工具:PaddleNLP提供了用于数据处理和数据集加载的工具函数,包括文本分词、数据预处理、数据批处理等功能,简化了NLP任务中数据的准备过程。
- 任务示例:PaddleNLP提供了丰富的任务示例代码,覆盖了文本分类、序列标注、文本生成等多个任务。这些示例代码可以帮助用户快速上手并理解如何使用PaddleNLP解决具体的NLP问题。
- 多语言支持:PaddleNLP支持多种语言,包括中文和英文,可以应用于不同语种的NLP任务。
- 与PaddlePaddle无缝集成:PaddleNLP基于PaddlePaddle深度学习平台构建,可以与PaddlePaddle的其他组件和功能进行无缝集成,充分发挥PaddlePaddle的优势。
总之,PaddleNLP是一个功能强大且易于使用的NLP工具库,为用户提供了丰富的预训练模型、模型组件和工具函数,帮助用户解决各种文本处理和NLP任务。无论是初学者还是有经验的研究人员和工程师,都可以从PaddleNLP中受益并加快NLP项目的开发速度。
1-2、特性介绍
PaddleNLP提供开箱即用的产业级NLP预置任务能力,无需训练,一键预测。
- 最全的中文任务:覆盖自然语言理解与自然语言生成两大核心应用;
- 极致的产业级效果:在多个中文场景上提供产业级的精度与预测性能;
- 统一的应用范式:通过paddlenlp.Taskflow调用,简捷易用。
二、paddleNLP安装
安装:
# 需要安装如下几种包
pip install python==3.8.10 -i https://mirror.baidu.com/pypi/simple
pip install paddlepaddle==2.4.2 -i https://mirror.baidu.com/pypi/simple
pip install paddlenlp==2.3.4 -i https://mirror.baidu.com/pypi/simple
# 智能文档任务需要调用
pip install opencv-python -i https://mirror.baidu.com/pypi/simple
pip install paddleocr -i https://mirror.baidu.com/pypi/simple
pip install --upgrade opencv-python
pip install --upgrade paddlenlp
pip install --upgrade paddleocr
验证:
import paddle
paddle.utils.run_check()
# 如果没有报错,则安装成功
其他问题:
# 在后续使用过程中,我遇到了scipy和sk-learn的一个兼容问题,我这里都卸载后重新安装了一下
pip uninstall scipy scikit-learn
pip install scipy scikit-learn -i https://mirror.baidu.com/pypi/simple
三、PaddleNLP一键使用
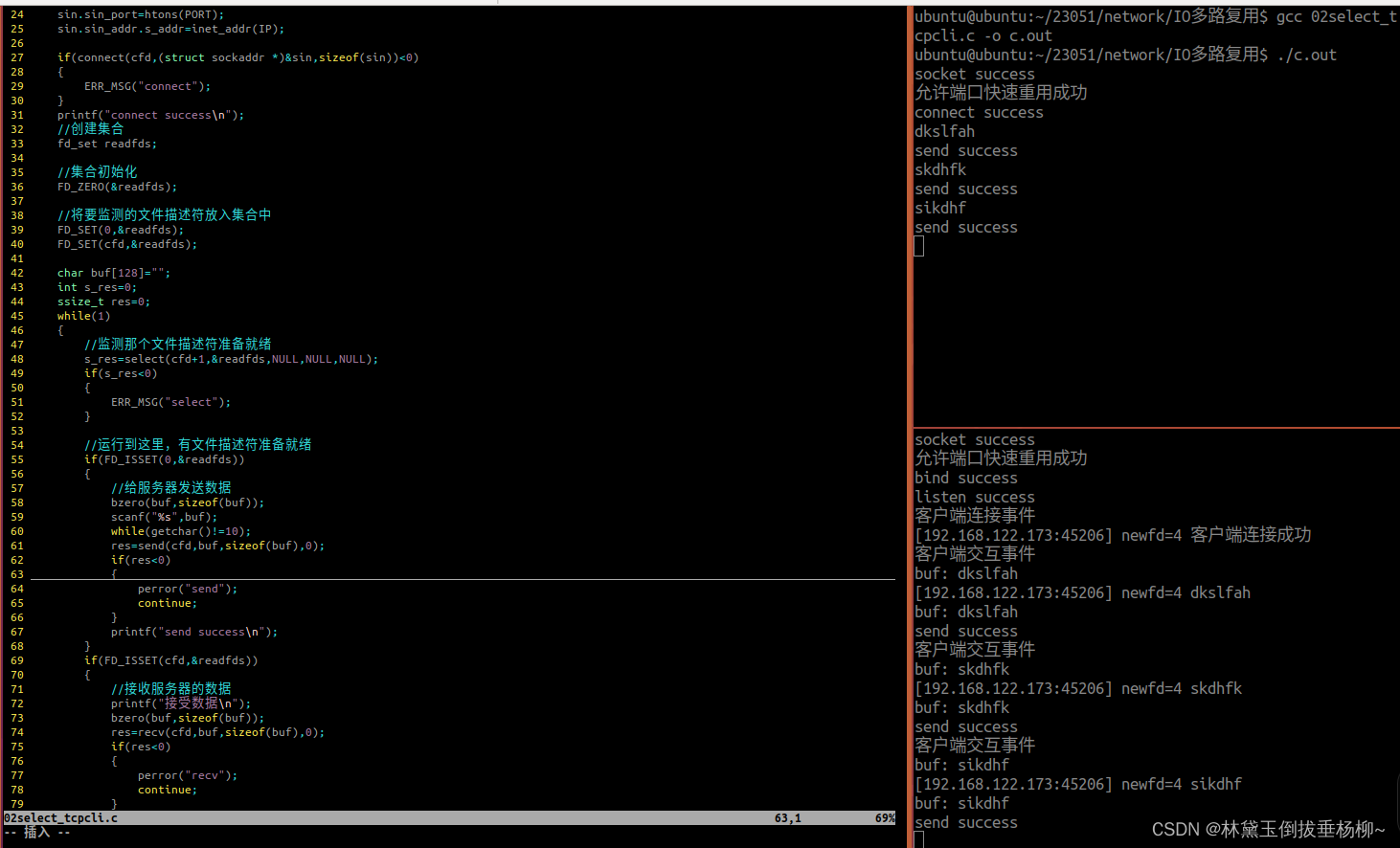
3-1、中文分词
中文分词(BiGRU+CRF、jieba、WordTag)
参数:
- mode:指定分词模式,快速、精确、默认(两者之间)。
- batch_size: 批处理大小,结合机器情况调整,默认为1。
- user_dict: 自定义词典文件路径,默认为None。
- task_path: 自定义任务路径,默认为None。
案例如下:
from paddlenlp import Taskflow
# 默认模式————实体粒度分词,在精度和速度上的权衡,基于百度LAC
seg = Taskflow("word_segmentation")
seg("近日国家卫健委发布第九版新型冠状病毒肺炎诊疗方案")
# ['近日', '国家卫健委', '发布', '第九版', '新型', '冠状病毒肺炎', '诊疗', '方案']
# 快速模式————最快:实现文本快速切分,基于jieba中文分词工具
seg_fast = Taskflow("word_segmentation", mode="fast")
seg_fast("近日国家卫健委发布第九版新型冠状病毒肺炎诊疗方案")
# ['近日', '国家', '卫健委', '发布', '第九版', '新型', '冠状病毒', '肺炎', '诊疗', '方案']
# 精确模式————最准:实体粒度切分准确度最高,基于百度解语
# 精确模式基于预训练模型,更适合实体粒度分词需求,适用于知识图谱构建、企业搜索Query分析等场景中
seg_accurate = Taskflow("word_segmentation", mode="accurate")
seg_accurate("近日国家卫健委发布第九版新型冠状病毒肺炎诊疗方案")
# ['近日', '国家卫健委', '发布', '第九版', '新型冠状病毒肺炎', '诊疗', '方案']
# 批量样本输入时,平均速度更快,以下NLP任务,同样适用。
seg(["第十四届全运会在西安举办", "三亚是一个美丽的城市"])
# [['第十四届', '全运会', '在', '西安', '举办'], ['三亚', '是', '一个', '美丽', '的', '城市']]
自定义词典:词典文件每一行由一个或多个自定义item组成。词典文件user_dict.txt示例:
平原上的火焰
上 映
3-2、词性标注
词性标注
参数:
- batch_size:批处理大小,请结合机器情况进行调整,默认为1。
- user_dict:用户自定义词典文件,默认为None。
- task_path:自定义任务路径,默认为None。
案例如下:基于百度词法分析工具LAC
>>> from paddlenlp import Taskflow
# 单条预测
>>> tag = Taskflow("pos_tagging")
>>> tag("第十四届全运会在西安举办")
# [('第十四届', 'm'), ('全运会', 'nz'), ('在', 'p'), ('西安', 'LOC'), ('举办', 'v')]
# 批量样本输入,平均速度更快
>>> tag(["第十四届全运会在西安举办", "三亚是一个美丽的城市"])
# [[('第十四届', 'm'), ('全运会', 'nz'), ('在', 'p'), ('西安', 'LOC'), ('举办', 'v')], [('三亚', 'LOC'), ('是', 'v'), ('一个', 'm'), ('美丽', 'a'), ('的', 'u'), ('城市', 'n')]]
标签以及对应含义如下:
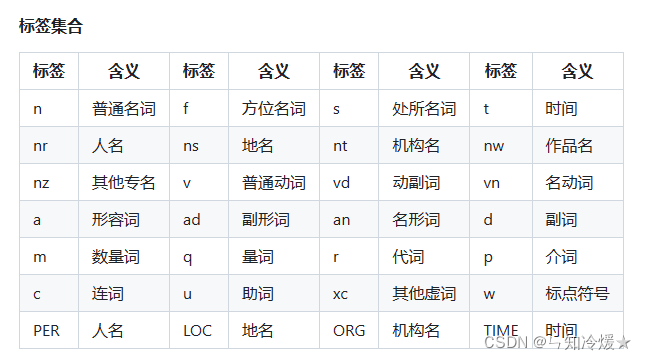
3-3、命名实体识别
命名实体识别:
可配置参数说明
- batch_size:批处理大小,请结合机器情况进行调整,默认为1。
- user_dict:用户自定义词典文件,默认为None。
- task_path:自定义任务路径,默认为None。
- entity_only:只返回实体/概念词及其对应标签。
案例分析:
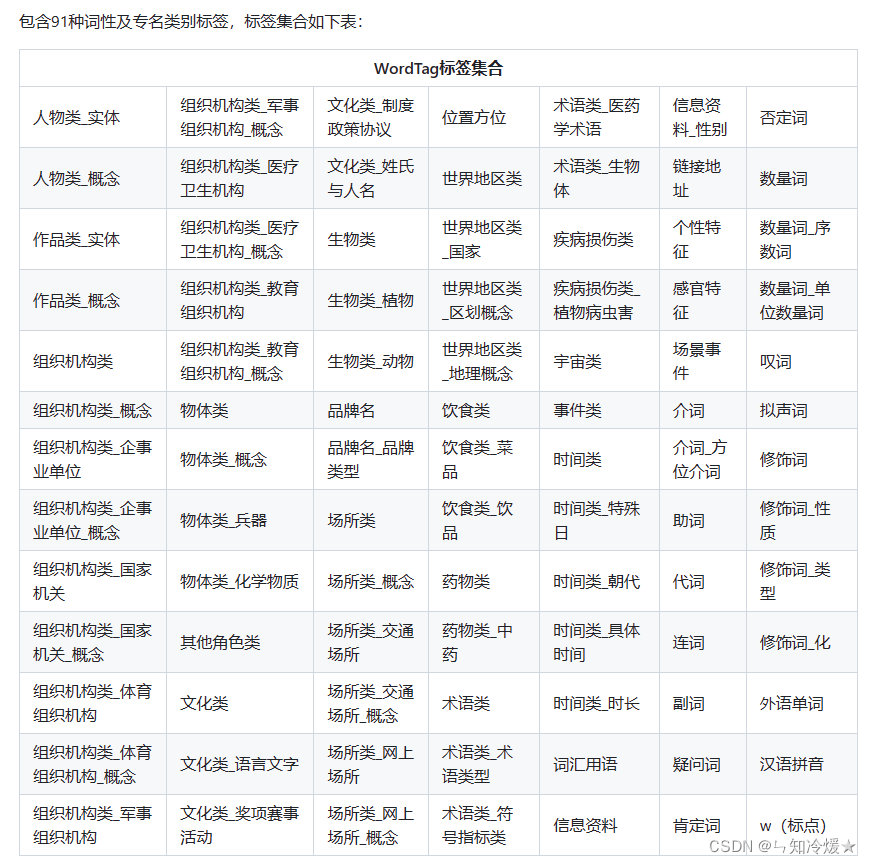
# 精确模式(默认),基于百度解语,内置91种词性及专名类别标签
>>> from paddlenlp import Taskflow
>>> ner = Taskflow("ner")
>>> ner("《孤女》是2010年九州出版社出版的小说,作者是余兼羽")
# [('《', 'w'), ('孤女', '作品类_实体'), ('》', 'w'), ('是', '肯定词'), ('2010年', '时间类'), ('九州出版社', '组织机构类'), ('出版', '场景事件'), ('的', '助词'), ('小说', '作品类_概念'), (',', 'w'), ('作者', '人物类_概念'), ('是', '肯定词'), ('余兼羽', '人物类_实体')]
>>> ner = Taskflow("ner", entity_only=True) # 只返回实体/概念词
>>> ner("《孤女》是2010年九州出版社出版的小说,作者是余兼羽")
# [('孤女', '作品类_实体'), ('2010年', '时间类'), ('九州出版社', '组织机构类'), ('出版', '场景事件'), ('小说', '作品类_概念'), ('作者', '人物类_概念'), ('余兼羽', '人物类_实体')]
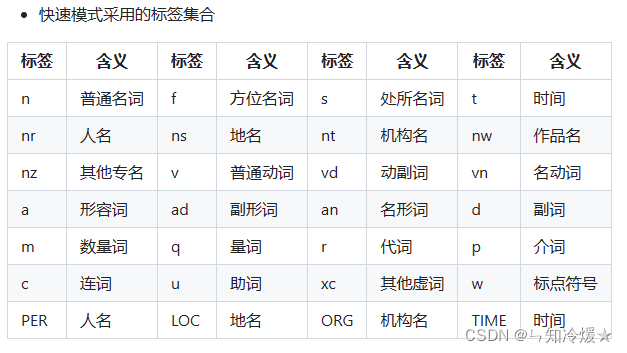
# 快速模式,基于百度LAC,内置24种词性和专名类别标签
>>> from paddlenlp import Taskflow
>>> ner = Taskflow("ner", mode="fast")
>>> ner("三亚是一个美丽的城市")
# [('三亚', 'LOC'), ('是', 'v'), ('一个', 'm'), ('美丽', 'a'), ('的', 'u'), ('城市', 'n')]
精确模式标签集合:
快速模式标签集合:快速模式有点和词性标注类似了。
3-4、依存句法分析(DDParser)
依存句法分析:基于最大规模中文依存句法树库研发的DDParser,使用命名实体识别抽取实体,来进行依存分析。
可配置参数说明:
- batch_size:批处理大小,请结合机器情况进行调整,默认为1。
- model:选择任务使用的模型,可选有ddparser,ddparser-ernie-1.0和ddparser-ernie-gram-zh。
- tree:确保输出结果是正确的依存句法树,默认为True。
- prob:是否输出每个弧对应的概率值,默认为False。
- use_pos:是否返回词性标签,默认为False。
- use_cuda:是否使用GPU进行切词,默认为False。
- return_visual:是否返回句法树的可视化结果,默认为False。
- task_path:自定义任务路径,默认为None。
案例分析:抽取的实体为’时间’, ‘选手’, ‘赛事名称’。
>>> from pprint import pprint
>>> from paddlenlp import Taskflow
>>> schema = ['时间', '选手', '赛事名称'] # Define the schema for entity extraction
>>> ie = Taskflow('information_extraction', schema=schema)
>>> pprint(ie("2月8日上午北京冬奥会自由式滑雪女子大跳台决赛中中国选手谷爱凌以188.25分获得金牌!")) # Better print results using pprint
输出:
[{‘时间’: [{‘end’: 6,
‘probability’: 0.9857378532924486,
‘start’: 0,
‘text’: ‘2月8日上午’}],
‘赛事名称’: [{‘end’: 23,
‘probability’: 0.8503089953268272,
‘start’: 6,
‘text’: ‘北京冬奥会自由式滑雪女子大跳台决赛’}],
‘选手’: [{‘end’: 31,
‘probability’: 0.8981548639781138,
‘start’: 28,
‘text’: ‘谷爱凌’}]}]
在上例中我们已经实例化了一个Taskflow对象,这里可以通过set_schema方法重置抽取目标。
调用示例:
>>> schema = ['肿瘤的大小', '肿瘤的个数', '肝癌级别', '脉管内癌栓分级']
>>> ie.set_schema(schema)
>>> pprint(ie("(右肝肿瘤)肝细胞性肝癌(II-III级,梁索型和假腺管型),肿瘤包膜不完整,紧邻肝被膜,侵及周围肝组织,未见脉管内癌栓(MVI分级:M0级)及卫星子灶形成。(肿物1个,大小4.2×4.0×2.8cm)。"))
输出如下:
[{‘肝癌级别’: [{‘end’: 20,
‘probability’: 0.9243267447402701,
‘start’: 13,
‘text’: ‘II-III级’}],
‘肿瘤的个数’: [{‘end’: 84,
‘probability’: 0.7538413804059623,
‘start’: 82,
‘text’: ‘1个’}],
‘肿瘤的大小’: [{‘end’: 100,
‘probability’: 0.8341128043459491,
‘start’: 87,
‘text’: ‘4.2×4.0×2.8cm’}],
‘脉管内癌栓分级’: [{‘end’: 70,
‘probability’: 0.9083292325934664,
‘start’: 67,
‘text’: ‘M0级’}]}]
3-5、解语知识标注
3-6、文本纠错(ERNIE-CSC)
文本纠错
参数说明:
- batch_size:批处理大小,请结合机器情况进行调整,默认为1。
- task_path:自定义任务路径,默认为None。
案例如下:
>>> from paddlenlp import Taskflow
>>> corrector = Taskflow("text_correction")
# 单条输入
>>> corrector('遇到逆竟时,我们必须勇于面对,而且要愈挫愈勇。')
# [{'source': '遇到逆竟时,我们必须勇于面对,而且要愈挫愈勇。', 'target': '遇到逆境时,我们必须勇于面对,而且要愈挫愈勇。', 'errors': [{'position': 3, 'correction': {'竟': '境'}}]}]
# 批量预测
>>> corrector(['遇到逆竟时,我们必须勇于面对,而且要愈挫愈勇。', '人生就是如此,经过磨练才能让自己更加拙壮,才能使自己更加乐观。'])
# [{'source': '遇到逆竟时,我们必须勇于面对,而且要愈挫愈勇。', 'target': '遇到逆境时,我们必须勇于面对,而且要愈挫愈勇。', 'errors': [{'position': 3, 'correction': {'竟': '境'}}]}, {'source': '人生就是如此,经过磨练才能让自己更加拙壮,才能使自己更加乐观。', 'target': '人生就是如此,经过磨练才能让自己更加茁壮,才能使自己更加乐观。', 'errors': [{'position': 18, 'correction': {'拙': '茁'}}]}]
3-7、文本相似度(SimBERT)
文本相似度
参数说明:
- batch_size:批处理大小,请结合机器情况进行调整,默认为1。
- max_seq_len:最大序列长度,默认为384。
- task_path:自定义任务路径,默认为None。
案例如下:
>>> from paddlenlp import Taskflow
>>> similarity = Taskflow("text_similarity")
>>> similarity([["春天适合种什么花?", "春天适合种什么菜?"]])
# [{'text1': '春天适合种什么花?', 'text2': '春天适合种什么菜?', 'similarity': 0.83402544}]
3-8、情感分析(BiLSTM、SKEP、UIE)
情感分析
参数说明:
- batch_size:批处理大小,请结合机器情况进行调整,默认为1。
- model:选择任务使用的模型,可选有bilstm,skep_ernie_1.0_large_ch,uie-senta-base,uie-senta-- medium,uie-senta-mini,uie-senta-micro,uie-senta-nano。
- task_path:自定义任务路径,默认为None。
案例如下:
>>> from paddlenlp import Taskflow
# 默认使用bilstm模型进行预测,速度快
>>> senta = Taskflow("sentiment_analysis")
>>> senta("这个产品用起来真的很流畅,我非常喜欢")
[{'text': '这个产品用起来真的很流畅,我非常喜欢', 'label': 'positive', 'score': 0.9938690066337585}]
# 使用SKEP情感分析预训练模型进行预测,精度高
>>> senta = Taskflow("sentiment_analysis", model="skep_ernie_1.0_large_ch")
>>> senta("作为老的四星酒店,房间依然很整洁,相当不错。机场接机服务很好,可以在车上办理入住手续,节省时间。")
[{'text': '作为老的四星酒店,房间依然很整洁,相当不错。机场接机服务很好,可以在车上办理入住手续,节省时间。', 'label': 'positive', 'score': 0.984320878982544}]
# 使用UIE模型进行情感分析,具有较强的样本迁移能力
# 1. 语句级情感分析
>>> schema = ['情感倾向[正向,负向]']
>>> senta = Taskflow("sentiment_analysis", model="uie-senta-base", schema=schema)
>>> senta('蛋糕味道不错,店家服务也很好')
[{'情感倾向[正向,负向]': [{'text': '正向', 'probability': 0.996646058824652}]}]
# 2. 评价维度级情感分析
>>> # Aspect Term Extraction
>>> # schema = ["评价维度"]
>>> # Aspect - Opinion Extraction
>>> # schema = [{"评价维度":["观点词"]}]
>>> # Aspect - Sentiment Extraction
>>> # schema = [{"评价维度":["情感倾向[正向,负向,未提及]"]}]
>>> # Aspect - Sentiment - Opinion Extraction
>>> schema = [{"评价维度":["观点词", "情感倾向[正向,负向,未提及]"]}]
>>> senta = Taskflow("sentiment_analysis", model="uie-senta-base", schema=schema)
>>> senta('蛋糕味道不错,店家服务也很热情')
[{'评价维度': [{'text': '服务', 'start': 9, 'end': 11, 'probability': 0.9709093024793489, 'relations': { '观点词': [{'text': '热情', 'start': 13, 'end': 15, 'probability': 0.9897222206316556}], '情感倾向[正向,负向,未提及]': [{'text': '正向', 'probability': 0.9999327669598301}]}}, {'text': '味道', 'start': 2, 'end': 4, 'probability': 0.9105472387838915, 'relations': {'观点词': [{'text': '不错', 'start': 4, 'end': 6, 'probability': 0.9946981266891619}], '情感倾向[正向,负向,未提及]': [{'text': '正向', 'probability': 0.9998829392709467}]}}]}]
3-9、生成式回答(CPM)
生成式回答
参数说明:
- batch_size:批处理大小,请结合机器情况进行调整,默认为1。
案例如下:
>>> from paddlenlp import Taskflow
>>> qa = Taskflow("question_answering")
# 单条输入
>>> qa("中国的国土面积有多大?")
[{'text': '中国的国土面积有多大?', 'answer': '960万平方公里。'}]
# 多条输入
>>> qa(["中国国土面积有多大?", "中国的首都在哪里?"])
[{'text': '中国国土面积有多大?', 'answer': '960万平方公里。'}, {'text': '中国的首都在哪里?', 'answer': '北京。'}]
3-10、智能写诗(CPM)
案例如下:
>>> from paddlenlp import Taskflow
>>> poetry = Taskflow("poetry_generation")
# 单条输入
>>> poetry("林密不见人")
[{'text': '林密不见人', 'answer': ',但闻人语响。'}]
# 多条输入
>>> poetry(["林密不见人", "举头邀明月"])
[{'text': '林密不见人', 'answer': ',但闻人语响。'}, {'text': '举头邀明月', 'answer': ',低头思故乡。'}]
3-11、开放领域回答(PLATO-Mini)
开放领域回答: 十亿级语料训练最强中文闲聊模型PLATO-Mini,支持多轮对话
参数说明:
- batch_size:批处理大小,请结合机器情况进行调整,默认为1。
- max_seq_len:最大序列长度,默认为512。
案例如下
非交互模式:
>>> from paddlenlp import Taskflow
>>> dialogue = Taskflow("dialogue")
>>> dialogue(["吃饭了吗"])
['刚吃完饭,你在干什么呢?']
>>> dialogue(["你好", "吃饭了吗"], ["你是谁?"])
['吃过了,你呢', '我是李明啊']
交互模式:
>>> from paddlenlp import Taskflow
>>> dialogue = Taskflow("dialogue")
# 输入`exit`可退出交互模式
# max_turn:任务能记忆的对话轮数,当max_turn为1时,模型只能记住当前对话,无法获知之前的对话内容。
>>> dialogue.interactive_mode(max_turn=3)
'''
[Human]:你好
[Bot]:你好,很高兴认识你,我想问你一下,你喜欢运动吗?
[Human]:喜欢
[Bot]:那你喜欢什么运动啊?
[Human]:篮球,你喜欢篮球吗
[Bot]:当然了,我很喜欢打篮球的
'''
3-12、代码生成
3-13、文本摘要
文本摘要: 十亿级语料训练最强中文闲聊模型PLATO-Mini,支持多轮对话
参数说明:
- model:可选模型,默认为IDEA-CCNL/Randeng-Pegasus-523M-Summary-Chinese。
- batch_size:批处理大小,请结合机器情况进行调整,默认为1。
案例如下: 通过Pegasus模型来生成摘要、支持单条、批量预测。
>>> from paddlenlp import Taskflow
>>> summarizer = Taskflow("text_summarization")
# 单条输入
>>> summarizer('2022年,中国房地产进入转型阵痛期,传统“高杠杆、快周转”的模式难以为继,万科甚至直接喊话,中国房地产进入“黑铁时代”')
# 输出:['万科喊话中国房地产进入“黑铁时代”']
# 多条输入
>>> summarizer([
'据悉,2022年教育部将围绕“巩固提高、深化落实、创新突破”三个关键词展开工作。要进一步强化学校教育主阵地作用,继续把落实“双减”作为学校工作的重中之重,重点从提高作业设计水平、提高课后服务水平、提高课堂教学水平、提高均衡发展水平四个方面持续巩固提高学校“双减”工作水平。',
'党参有降血脂,降血压的作用,可以彻底消除血液中的垃圾,从而对冠心病以及心血管疾病的患者都有一定的稳定预防工作作用,因此平时口服党参能远离三高的危害。另外党参除了益气养血,降低中枢神经作用,调整消化系统功能,健脾补肺的功能。'
])
#输出:['教育部:将从四个方面持续巩固提高学校“双减”工作水平', '党参能降低三高的危害']
3-14、文档智能
文档智能: 以多语言跨模态布局增强文档预训练模型ERNIE-Layout为核心底座,注意:从我目前的实验结果来看,仅支持单页图片。如果遇到有关于环境配置的问题,请查看参考链接第四个。
参数说明:
- batch_size:批处理大小,请结合机器情况进行调整,默认为1。
- lang:选择PaddleOCR的语言,ch可在中英混合的图片中使用,en在英文图片上的效果更好,默认为ch。
- topn: 如果模型识别出多个结果,将返回前n个概率值最高的结果,默认为1。
案例如下:
>>> from pprint import pprint
>>> from paddlenlp import Taskflow
>>> docprompt = Taskflow("document_intelligence")
# 可以是图片,也可以直接是网页链接
>>> pprint(docprompt([{"doc": "./resume.png", "prompt": ["五百丁本次想要担任的是什么职位?", "五百丁是在哪里上的大学?", "大学学的是什么专业?"]}]))
输出:
[{‘prompt’: ‘五百丁本次想要担任的是什么职位?’,
‘result’: [{‘end’: 7, ‘prob’: 1.0, ‘start’: 4, ‘value’: ‘客户经理’}]},
{‘prompt’: ‘五百丁是在哪里上的大学?’,
‘result’: [{‘end’: 37, ‘prob’: 1.0, ‘start’: 31, ‘value’: ‘广州五百丁学院’}]},
{‘prompt’: ‘大学学的是什么专业?’,
‘result’: [{‘end’: 44, ‘prob’: 0.82, ‘start’: 38, ‘value’: ‘金融学(本科)’}]}]
3-15、问题生成
问题生成:基于百度自研中文预训练模型UNIMO-Text和大规模多领域问题生成数据集
参数说明:
- model:可选模型,默认为unimo-text-1.0-dureader_qg,支持的模型有[“unimo-text-1.0”, “unimo-text-1.0-dureader_qg”, “unimo-text-1.0-- - question-generation”, “unimo-text-1.0-question-generation-dureader_qg”]。
- device:运行设备,默认为"gpu"。
- template:模版,可选项有[0, 1, 2, 3],1表示使用默认模版,0表示不使用模版。
- batch_size:批处理大小,请结合机器情况进行调整,默认为1。
- output_scores:是否要输出解码得分,默认为False。
i- s_select_from_num_return_sequences:是否对多个返回序列挑选最优项输出,当为True时,若num_return_sequences不为1则自动根据解码得分选择得分最高的序列最为最终结果,否则返回num_return_sequences个序列,默认为True。 - max_length:生成代码的最大长度,默认为50。
- min_length:生成代码的最小长度,默认为3。
- decode_strategy:解码策略,支持beam_search和sampling,默认为beam_search。
- temperature:解码参数temperature,默认为1.0。
- top_k:解码参数top_k,默认为0。
- top_p:解码参数top_p,默认为1.0。
- num_beams:解码参数num_beams,表示beam_search解码的beam size,默认为6。
- num_beam_groups:解码参数num_beam_groups,默认为1。
- diversity_rate:解码参数diversity_rate,默认为0.0。
- length_penalty:解码长度控制值,默认为1.2。
- num_return_sequences:解码返回序列数,默认为1。
- repetition_penalty:解码重复惩罚值,默认为1。
- use_fast:表示是否开启基于FastGeneration的高性能预测,注意FastGeneration的高性能预测仅支持gpu,默认为False。
- use_fp16_decoding: 表示在开启高性能预测的时候是否使用fp16来完成预测过程,若不使用则使用fp32,默认为False。
案例如下:
>>> from paddlenlp import Taskflow
# 默认模型为 unimo-text-1.0-dureader_qg
>>> question_generator = Taskflow("question_generation")
# 单条输入
>>> question_generator([
{"context": "奇峰黄山千米以上的山峰有77座,整座黄山就是一座花岗岩的峰林,自古有36大峰,36小峰,最高峰莲花峰、最险峰天都峰和观日出的最佳点光明顶构成黄山的三大主峰。", "answer": "莲花峰"}
])
'''
['黄山最高峰是什么']
'''
# 多条输入
>>> question_generator([
{"context": "奇峰黄山千米以上的山峰有77座,整座黄山就是一座花岗岩的峰林,自古有36大峰,36小峰,最高峰莲花峰、最险峰天都峰和观日出的最佳点光明顶构成黄山的三大主峰。", "answer": "莲花峰"},
{"context": "弗朗索瓦·韦达外文名:franciscusvieta国籍:法国出生地:普瓦图出生日期:1540年逝世日期:1603年12月13日职业:数学家主要成就:为近代数学的发展奠定了基础。", "answer": "法国"}
])
'''
['黄山最高峰是什么', '弗朗索瓦是哪里人']
'''
3-16、零样本文本分类(UTC)
适配多场景的零样本通用文本分类工具:通用文本分类主要思想是利用单一模型支持通用分类、评论情感分析、语义相似度计算、蕴含推理、多项式阅读理解等众多“泛分类”任务。用户可以自定义任意标签组合,在不限定领域、不设定 prompt 的情况下进行文本分类。
参数说明:
- batch_size:批处理大小,请结合机器情况进行调整,默认为1。
- task_path:自定义任务路径,默认为None。
- schema:定义任务标签候选集合。
- model:选择任务使用的模型,默认为utc-base, 支持utc-xbase, utc-base, utc-medium, utc-micro, utc-mini, utc-nano, utc-pico。
- max_seq_len:最长输入长度,包括所有标签的长度,默认为512。
- pred_threshold:模型对标签预测的概率在0~1之间,返回结果去掉小于这个阈值的结果,默认为0.5。
- precision:选择模型精度,默认为fp32,可选有fp16和fp32。fp16推理速度更快。如果选择fp16,请先确保机器正确安装NVIDIA相关驱动和基础软件,确保CUDA>=11.2,cuDNN>=8.1.1,初次使用需按照提示安装相关依赖。其次,需要确保GPU设备的CUDA计算能力(CUDA Compute Capability)大于7.0,典型的设备包括V100、T4、A10、A100、GTX 20系列和30系列显卡等。更多关于CUDA Compute - Capability和精度支持情况请参考NVIDIA文档:GPU硬件与支持精度对照表。
案例如下: 这里以语义相似度为例。
>>> from paddlenlp import Taskflow
>>> cls = Taskflow("zero_shot_text_classification", schema=["不同", "相同"])
>>> cls([["怎么查看合同", "从哪里可以看到合同"]])
[{'predictions': [{'label': '相同', 'score': 0.9951385264364382}], 'text_a': '怎么查看合同', 'text_b': '从哪里可以看到合同'}]
>>> cls([["为什么一直没有电话来确认借款信息", "为何我还款了,今天却接到客服电话通知"]])
[{'predictions': [{'label': '不同', 'score': 0.9991497973466908}], 'text_a': '为什么一直没有电话来确认借款信息', 'text_b': '为何我还款了,今天却接到客服电话通知'}]
3-17、模型特征提取
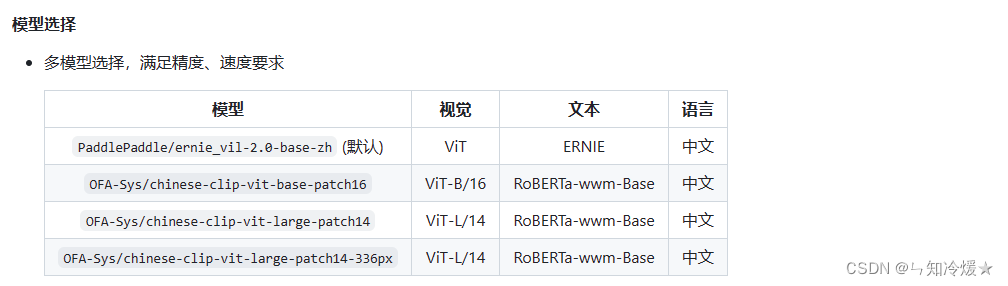
模型特征提取:基于百度自研中文图文跨模态预训练模型ERNIE-ViL 2.0
参数说明:
- batch_size:批处理大小,请结合机器情况进行调整,默认为1。
- _static_mode:静态图模式,默认开启。
- model:选择任务使用的模型,默认为PaddlePaddle/ernie_vil-2.0-base-zh。
>>> from paddlenlp import Taskflow
>>> from PIL import Image
>>> import paddle.nn.functional as F
>>> vision_language= Taskflow("feature_extraction")
# 单条输入
>>> image_embeds = vision_language(Image.open("demo/000000039769.jpg"))
>>> image_embeds["features"]
Tensor(shape=[1, 768], dtype=float32, place=Place(gpu:0), stop_gradient=True,
[[-0.59475428, -0.69795364, 0.22144008, 0.88066685, -0.58184201,
# 单条输入
>>> text_embeds = vision_language("猫的照片")
>>> text_embeds['features']
Tensor(shape=[1, 768], dtype=float32, place=Place(gpu:0), stop_gradient=True,
[[ 0.04250504, -0.41429776, 0.26163983, 0.29910022, 0.39019185,
-0.41884750, -0.19893740, 0.44328332, 0.08186490, 0.10953025,
......
# 多条输入
>>> image_embeds = vision_language([Image.open("demo/000000039769.jpg")])
>>> image_embeds["features"]
Tensor(shape=[1, 768], dtype=float32, place=Place(gpu:0), stop_gradient=True,
[[-0.59475428, -0.69795364, 0.22144008, 0.88066685, -0.58184201,
......
# 多条输入
>>> text_embeds = vision_language(["猫的照片","狗的照片"])
>>> text_embeds["features"]
Tensor(shape=[2, 768], dtype=float32, place=Place(gpu:0), stop_gradient=True,
[[ 0.04250504, -0.41429776, 0.26163983, ..., 0.26221892,
0.34387422, 0.18779707],
[ 0.06672225, -0.41456309, 0.13787819, ..., 0.21791610,
0.36693242, 0.34208685]])
>>> image_features = image_embeds["features"]
>>> text_features = text_embeds["features"]
>>> image_features /= image_features.norm(axis=-1, keepdim=True)
>>> text_features /= text_features.norm(axis=-1, keepdim=True)
>>> logits_per_image = 100 * image_features @ text_features.t()
>>> probs = F.softmax(logits_per_image, axis=-1)
>>> probs
Tensor(shape=[1, 2], dtype=float32, place=Place(gpu:0), stop_gradient=True,
[[0.99833173, 0.00166824]])
参考文章:
官方GitHub.
GitHub_相关功能介绍.
PaddleNLP常见问题汇总(持续更新).
拓展阅读:Paddle开源项目——PaddleNLP文档智能技术重磅升级,动手搭建端到端文档抽取问答模型_副本.
端到端开放文档抽取问答系统.
从0到1实现全流程本地部署Paddle项目——视频人像分割(一).
部署:一行命令启动,十分钟内完成部署,Paddle Serving开放模型即服务功能.
总结
樱花🌸公主佩戴着花环,跳舞在春风里,将绚烂的花瓣洒满整个季节。



![从零开始构建一个电影知识图谱,实现KBQA智能问答[下篇]:Apache jena SPARQL endpoint及推理、KBQA问答Demo超详细教学](https://img-blog.csdnimg.cn/033577b0fa5e47349e33c2ebbaeb92b9.png#pic_center)