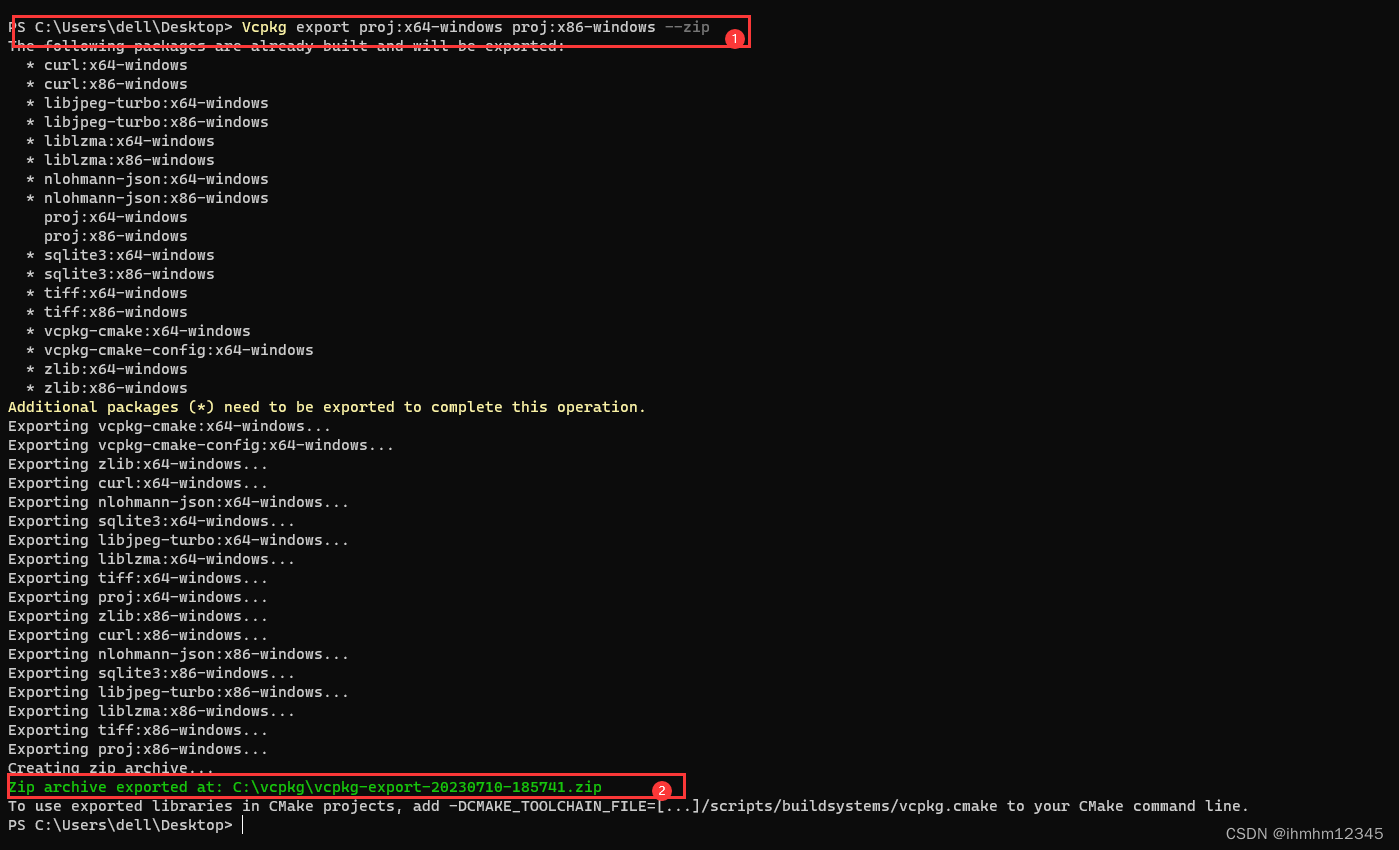
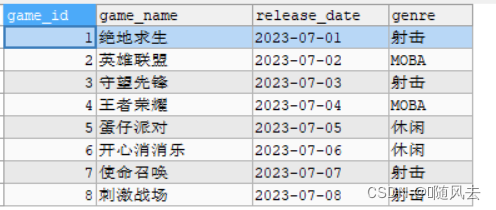
今天,我们进一步深入,并处理在图像处理中常用的形态学操作。形态学操作用于提取区域、边缘、形状等。
什么是形态学操作?
形态学操作是在二值图像上进行的。二值图像可能包含许多不完美之处。特别是由一些简单的阈值操作产生的二值图像(如果你对阈值不熟悉,现在不用担心)可能包含许多噪声和畸变。OpenCV库中提供了不同的形态学操作来处理这些噪声和缺陷。
形态学操作生成与原始图像相同形状的图像。形态学操作将结构元素应用于输入图像。结构元素可以是任何形状。在今天的所有形态学操作中,将比较输入图像的每个像素与相邻像素以生成输出图像。
对于不同的形态学操作,比较方式有所不同。我们将详细讨论这一点。
在深入讨论问题之前,这是我们将在本教程中使用的图片:

在这里,我们导入必要的包,将图像读取为数组,并将其转换为二值图像,正如前面提到的,形态学操作应用于二值图像:
import cv2
import matplotlib.pyplot as plt
#Reading the image to an array
image = cv2.imread('practice.jpg')
#converting it to a binary image
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)这是'gray'的样子:

我们将使用这个灰度图像来观察形态学操作的工作原理。
在深入示例之前,我想创建一个3x3的内核和一个6x3的内核:
kernel = cv2.getStructuringElement(cv2.MORPH_RECT, (3, 3))
kernel1 = cv2.getStructuringElement(cv2.MORPH_RECT, (6, 3))我们将在下面的形态学操作中使用这两个内核。如果需要,稍后我们将创建更多的内核。
内核可以是任何形状。你也可以尝试一些其他不同形状的内核,如1x4、4x4、5x5、7x18或更多。根据你的项目,内核的形状和大小可能会产生重大差异。
腐蚀
腐蚀做了它听起来的事情。它侵蚀图像的方式就像水侵蚀河岸一样。在腐蚀操作中,它将一个结构元素从输入图像的左到右、从上到下滑动。如果结构元素内的所有像素都大于0,则保留原始像素值。否则,将像素设置为0。
腐蚀用于去除被视为噪声的小斑点。
以下是腐蚀的语法:
eroded1 = cv2.erode(gray.copy(), kernel, iterations = 1)
cv2.imwrite('erode1.jpg', eroded1)腐蚀函数cv2.erode()使用图像、结构元素和迭代次数。这里的'iterations'参数是可选的。如果你不提供'iterations'值,它会自动执行一次迭代。
这是'erode1'的样子:

将其与原始图像进行比较。它已经被腐蚀掉了。此外,原始图像中的其他小元素也被去除了。
在任何OCR(光学字符识别)项目中,我们只想识别字母或数字。但图像中可能还有其他更小的字母和元素,可能会混淆你的算法。腐蚀可以消除这些噪声。
如果我们尝试2或3次迭代,它将被更加腐蚀:
eroded2 = cv2.erode(gray.copy(), kernel, iterations = 2)
cv2.imwrite('erode2.jpg', eroded2)
eroded3 = cv2.erode(gray.copy(), kernel, iterations = 3)
cv2.imwrite('erode3.jpg', eroded3)这是2次和3次迭代的结果:


你可以看到,随着迭代次数的增加,图像变得越来越腐蚀。因此,如果你需要提取粗体并且周围有很多噪声的字母,可以通过侵蚀图像来消除噪声。
膨胀
膨胀与腐蚀的作用恰恰相反。它增加前景,从而有助于连接断裂部分。在膨胀中,如果结构元素中的任何像素大于0,则将像素值设置为白色或255。这里我们使用1和3次迭代进行膨胀,以查看差异并了解其工作原理。
dilated1 = cv2.dilate(gray.copy(), kernel, iterations=1)
cv2.imwrite('dilate1.jpg', dilated1)
dilated3 = cv2.dilate(gray.copy(), kernel, iterations=3)
cv2.imwrite('dilate3.jpg', dilated3)这是膨胀1次迭代(第二个图像)和3次迭代(第三个图像)的图像。原始灰度图像在顶部。



如果我们将顶部的原始图像与经过一次膨胀的第二个图像进行比较,会有一些微小的差异,经过3次迭代后,差异变得更加显著。根据你的项目,你可以使用尽可能多的迭代次数。
开运算
开运算也是从图像中去除噪声的另一种方法。它在一次迭代中执行腐蚀后进行膨胀。这里有两个示例,我使用了之前准备好的内核和内核1:
opening1 = cv2.morphologyEx(gray, cv2.MORPH_OPEN, kernel)
cv2.imwrite('open1.jpg', opening1)
opening2 = cv2.morphologyEx(gray, cv2.MORPH_OPEN, kernel1) )
cv2.imwrite('open2.jpg', opening2)这里,我将原始图像放在顶部,然后是'opening1'操作的图像,底部是'opening2'操作的图像。



正如你所看到的,在使用3x3内核的中间图片中,左下角的小文本消失了,在使用大小为6x3的kernel1的底部图片中,添加了一个黑色阴影。
闭运算
闭运算与开运算相反。在闭运算中,首先进行膨胀,然后进行腐蚀。
让我们看一些示例:
closing1 = cv2.morphologyEx(gray.copy(), cv2.MORPH_CLOSE, kernel, iterations=1)
cv2.imwrite('close1.jpg', closing1)
closing3 = cv2.morphologyEx(gray.copy(), cv2.MORPH_CLOSE, (3, 3), iterations=3)
cv2.imwrite('close3.jpg', closing3)与之前一样,我将原始灰度图像放在顶部进行比较,然后是'closing1'和'closing2'的输出图像。



形态梯度
形态梯度对于检测对象的轮廓非常有用。它可用于边缘检测。基本上,它是膨胀操作和腐蚀操作之间的差异。
这是使用kernel和kernel1的两个示例:
grad1 = cv2.morphologyEx(gray.copy(), cv2.MORPH_GRADIENT, kernel)
cv2.imwrite('grad1.jpg', grad1)
grad2 = cv2.morphologyEx(gray.copy(), cv2.MORPH_GRADIENT, kernel1)
cv2.imwrite('grad3.jpg', grad2)这是'grad1'和'grad2'的输出图像:


正如你所看到的,不同形状的内核提供了两种不同类型的输出。
顶帽/白帽
顶帽操作是原始二值图像与开运算之间的差异。当你需要从黑色背景中找到亮区域时,它很有帮助。
对于这个操作,我们将使用不同的输入图像和其他操作:
这是输入图像:

这辆车的车牌比车身更亮。让我们看看如何提取出那个白色区域。和往常一样,我们应该将其转换为灰度图像,并定义两个不同的内核。
image = cv2.imread('car.jpg')
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
kernel = cv2.getStructuringElement(cv2.MORPH_RECT, (23, 5))
kernel1 = cv2.getStructuringElement(cv2.MORPH_RECT, (35, 8))我尝试了一些不同形状的内核,然后使用了这两个内核大小。请随意尝试一些其他内核大小并比较结果。
tophat1 = cv2.morphologyEx(gray.copy(), cv2.MORPH_TOPHAT, kernel1)
cv2.imwrite('tophat1.jpg', tophat1)这是输出图像:

看,它检测到了车牌从车身上的亮区域。
黑帽
黑帽操作与顶帽相反。
blackhat1 = cv2.morphologyEx(gray.copy(), cv2.MORPH_BLACKHAT, kernel)
cv2.imwrite('blackhat1.jpg', blackhat1)这是黑帽操作的输出:

如果你注意到,它聚焦于车牌上的字母。
经过顶帽操作后,检测到了车牌区域,经过黑帽操作后,突出显示了白色车牌上的黑色字母。
因此,如果我们想要检测车牌上的数字,我们将执行顶帽操作,然后是黑帽操作。
结论
本文试图通过示例解释一些众所周知的形态学操作。在将来的一些文章中,我将使用它们来解决一些实际问题。那将更有趣。
☆ END ☆
如果看到这里,说明你喜欢这篇文章,请转发、点赞。微信搜索「uncle_pn」,欢迎添加小编微信「 woshicver」,每日朋友圈更新一篇高质量博文。
↓扫描二维码添加小编↓