文章目录
- One Transformer Fits All Distributions in Multi-Modal Diffusion at Scale
- 摘要
- 本文方法
- 实验结果
One Transformer Fits All Distributions in Multi-Modal Diffusion at Scale
摘要
本文提出了一个统一的扩散框架(UniDiffuser)来拟合一个模型中与一组多模态数据相关的所有分布。
我们的关键观点是——边缘分布、条件分布和联合分布的学习扩散模型可以统一为预测扰动数据中的噪声,其中扰动水平(即时间步长)对于不同的模态可能是不同的。
受统一视图的启发,UniDiffuser同时学习所有分布,对原始扩散模型进行最小的修改-扰动所有模态的数据,而不是单一模态,输入不同模态的单个时间步长,预测所有模态的噪声,而不是单一模态.
UniDiffuser是由扩散模型的转换器参数化的,以处理不同模态的输入类型。
UniDiffuser在大规模成对的图像-文本数据上实现,可以通过设置适当的时间步来执行图像、文本、文本到图像、图像到文本和图像-文本对的生成,而不需要额外的开销。
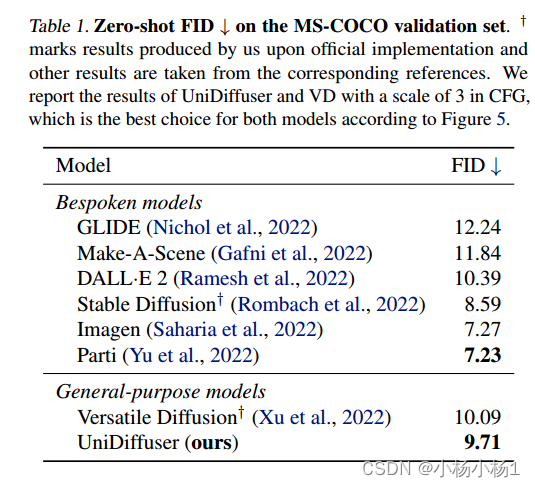
特别是,UniDiffuser能够在所有任务中产生感知上真实的样本,其定量结果(例如FID和CLIP分数)不仅优于现有的通用模型,而且在代表性任务(例如文本到图像生成)中也可与定制模型(例如,Stable Diffusion和DALL·e2)相媲美。
代码地址

本文方法
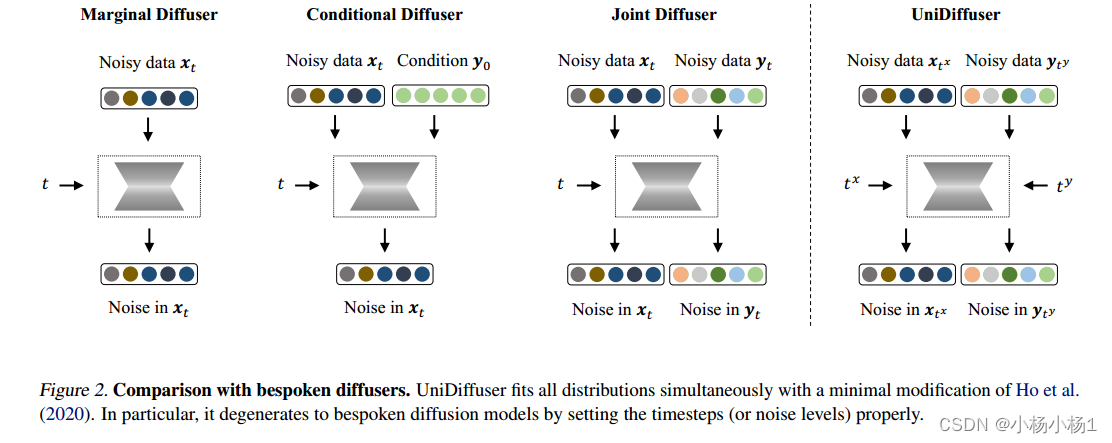
与定制扩散器的比较。UniDiffuser在Ho等人的最小修改下同时拟合所有分布(2020)。特别是,通过适当地设置时间步长(或噪声水平),它退化为预定的扩散模型
形式上,假设我们有两个从分布q(x0, y0)中采样的数据模态。我们的目标是设计一个基于扩散的模型,能够捕获由q(x0, y0)决定的所有相关分布,即边际分布q(x0)和q(y0),条件分布q(x0|y0)和q(y0|x0),以及联合分布q(x0, y0)。
使用扩散模型学习分布等同于估计噪声上的条件期望。对边际分布q(x0)进行建模相当于估计注入到xt的噪声的条件期望,即E[λ x |xt]。同样,在对条件分布q(x0|y0)和联合分布q(x0, y0)进行建模时要估计的关键量分别是E[λ x |xt, y0]和E[λ x, λ |xt, yt]。

联合图像和文本
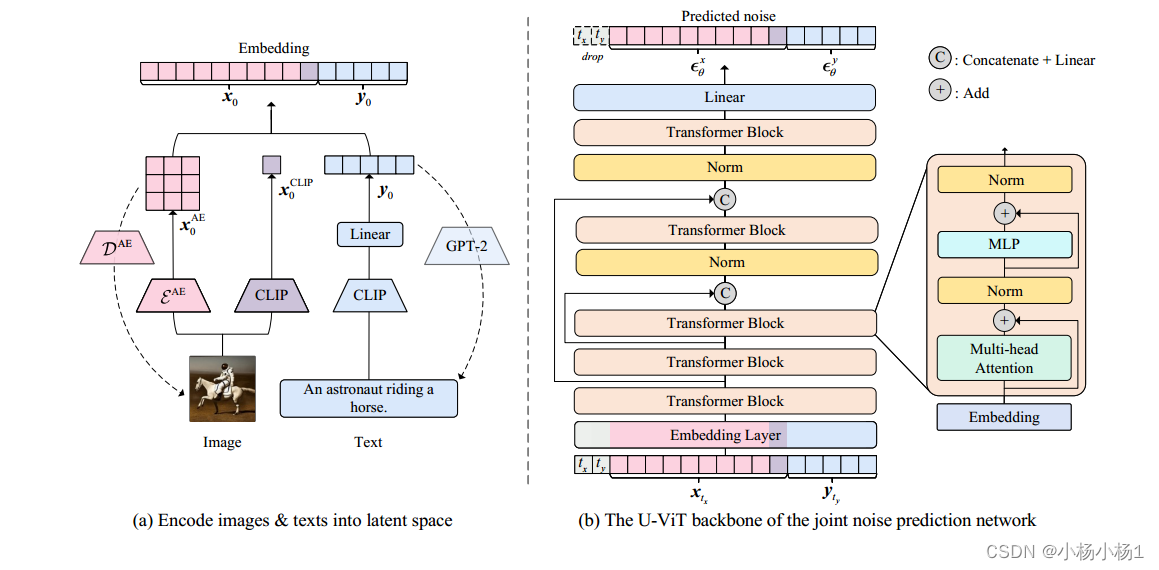
UniDiffuser对图像-文本数据的实现。(a)首先,对图像和文本进行隐空间编码。(b)其次,我们以图2所示的方式训练由变压器参数化的UniDiffuser 。
实验结果