文章目录
- 问题描述
- 示例 1
- 示例2
- 示例3
- 提示
- 思路分析
- 代码分析
- 完整代码
- 运行效果及示例代码
- 示例代码1
- 运行结果
- 示例代码2
- 运行结果
- 示例代码3
- 运行结果
- 完结
问题描述

给你一个字符串 s 和一个字符规律 p,请你来实现一个支持 ‘.’ 和 ‘’ 的正则表达式匹配。
‘.’ 匹配任意单个字符
'’ 匹配零个或多个前面的那一个元素
所谓匹配,是要涵盖 整个 字符串 s的,而不是部分字符串。

示例 1
输入:s = "aa", p = "a"
输出:false
解释:"a" 无法匹配 "aa" 整个字符串。
示例2
输入:s = "aa", p = "a*"
输出:true
解释:因为 '*' 代表可以匹配零个或多个前面的那一个元素, 在这里前面的元素就是 'a'。因此,字符串 "aa" 可被视为 'a' 重复了一次。
示例3
输入:s = "ab", p = ".*"
输出:true
解释:".*" 表示可匹配零个或多个('*')任意字符('.')。
提示
- 1 <= s.length <= 20
- 1 <= p.length <= 20
- s 只包含从 a-z 的小写字母。
- p 只包含从 a-z 的小写字母,以及字符 . 和 *。
- 保证每次出现字符 * 时,前面都匹配到有效的字符
思路分析

首先, 创建一个二维数组dp,其中dp[i][j]表示字符串s的前i个字符与模式p的前j个字符是否匹配。
初始化dp[0][0]为True,因为空字符串与空模式是匹配的。
接下来, 需要填充数组dp的其他值。我们使用两个嵌套的循环来遍历字符串s和模式p的每个字符。
对于每个位置(i, j),我们考虑几种情况:
- 如果模式
p的当前字符p[j-1]不是*,我们只需要判断字符串s的当前字符s[i-1]和模式p的当前字符p[j-1]是否匹配。如果相等,或者p[j-1]为.通配符,我们可以将dp[i][j]设置为dp[i-1][j-1],表示前缀字符串匹配。 - 如果模式
p的当前字符p[j-1]为*,我们需要考虑两种情况:*代表0个前面的字符。在这种情况下,我们将dp[i][j]设置为dp[i][j-2],表示模式p中的p[j-2]和p[j-1]被忽略。*代表多个前面的字符。我们需要检查字符串s的当前字符s[i-1]和模式p的前一个字符p[j-2]是否匹配。如果匹配,我们可以将dp[i][j]设置为dp[i-1][j],表示可以将当前字符*匹配到字符串s的前一个字符。
最终,返回dp[m][n]的值,其中m为字符串s的长度,n为模式p的长度。如果dp[m][n]为True,则表示整个字符串s与模式p匹配;否则,不匹配。
代码分析

def isMatch(self, s: str, p: str) -> bool:
m = len(s)
n = len(p)
dp = [[False] * (n + 1) for _ in range(m + 1)]
dp[0][0] = True
- 首先,我们定义了一个
isMatch函数,接受两个参数s和p,分别表示字符串和模式。 - 然后,我们获取字符串
s和模式p的长度,并创建大小为(m+1) x (n+1)的二维数组dp,并将所有元素初始化为False。 - 初始化
dp[0][0]为True,因为空字符串与空模式是匹配的。
for i in range(m + 1):
for j in range(1, n + 1):
if p[j - 1] != '*':
if i > 0 and (s[i - 1] == p[j - 1] or p[j - 1] == '.'):
dp[i][j] = dp[i - 1][j - 1]
else:
if j >= 2:
dp[i][j] = dp[i][j - 2]
if i > 0 and (s[i - 1] == p[j - 2] or p[j - 2] == '.'):
dp[i][j] |= dp[i - 1][j]
- 使用两层循环遍历字符串
s和模式p的每个字符。 - 对于每个位置
(i, j),我们分情况讨论:- 如果模式
p的当前字符p[j-1]不是*,且字符串s的当前字符s[i-1]与模式p的当前字符p[j-1]匹配(或者p[j-1]为.通配符),则将dp[i][j]设置为dp[i-1][j-1],表示前缀字符串匹配。 - 如果模式
p的当前字符p[j-1]为*,我们需要进一步分情况讨论:*代表0个前面的字符:设置dp[i][j]为dp[i][j-2],表示模式p中的p[j-2]和p[j-1]被忽略。*代表多个前面的字符:首先设置dp[i][j]为dp[i][j-2],然后判断字符串s的当前字符s[i-1]与模式p的前一个字符p[j-2]是否匹配。如果匹配,就将dp[i][j]更新为dp[i-1][j]的值。
- 如果模式
return dp[m][n]
- 最后,返回
dp[m][n]的值,即表示整个字符串s与模式p是否匹配。
完整代码

class Solution(object):
def isMatch(self, s, p):
"""
:type s: str
:type p: str
:rtype: bool
"""
# 获取字符串s和模式p的长度
m, n = len(s), len(p)
# 创建一个二维dp数组来存储匹配结果,默认为False
dp = [[False] * (n + 1) for _ in range(m + 1)]
# 初始化dp[0][0]为True,表示空字符串与空模式匹配
dp[0][0] = True
for i in range(m + 1):
for j in range(1, n + 1):
if p[j - 1] != '*':
# 当前字符不是'*'时,比较s的第i个字符和p的第j个字符是否匹配
if i > 0 and (s[i - 1] == p[j - 1] or p[j - 1] == '.'):
dp[i][j] = dp[i - 1][j - 1]
else:
# 当前字符是'*'时,分两种情况考虑
# 第一种情况:忽略p的前两个字符(即'*'前面的字符)
if j >= 2:
dp[i][j] = dp[i][j - 2]
# 第二种情况:如果s的第i个字符和p的前两个字符匹配,
# 或者p的前两个字符是'.',则可以考虑将s的第i个字符加入匹配模式中
if i >= 1 and j >= 2 and (s[i - 1] == p[j - 2] or p[j - 2] == '.'):
dp[i][j] = dp[i][j] or dp[i - 1][j]
# 返回匹配结果
return dp[m][n]
运行效果及示例代码
示例代码1
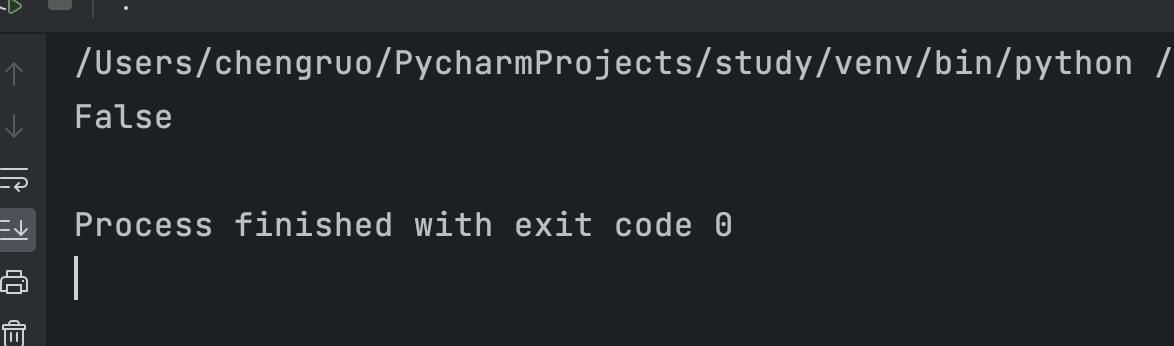
solution = Solution()
print(solution.isMatch("aa", "a"))
运行结果
示例代码2
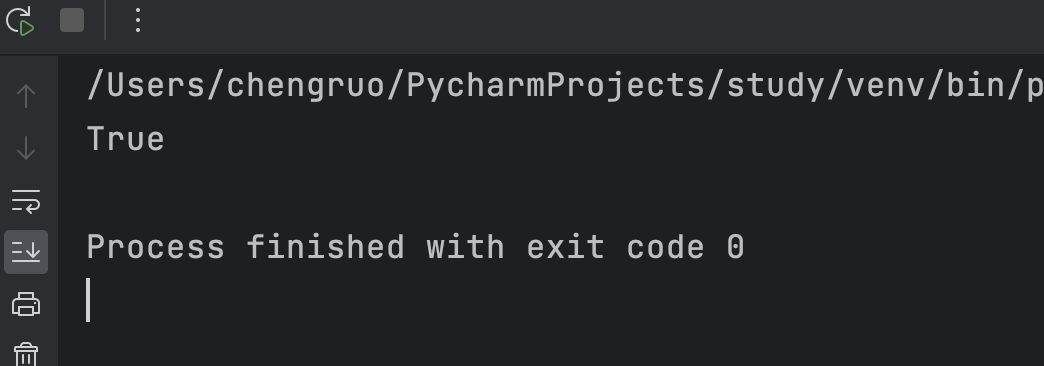
solution = Solution()
print(solution.isMatch("aa", "a*"))
运行结果
示例代码3
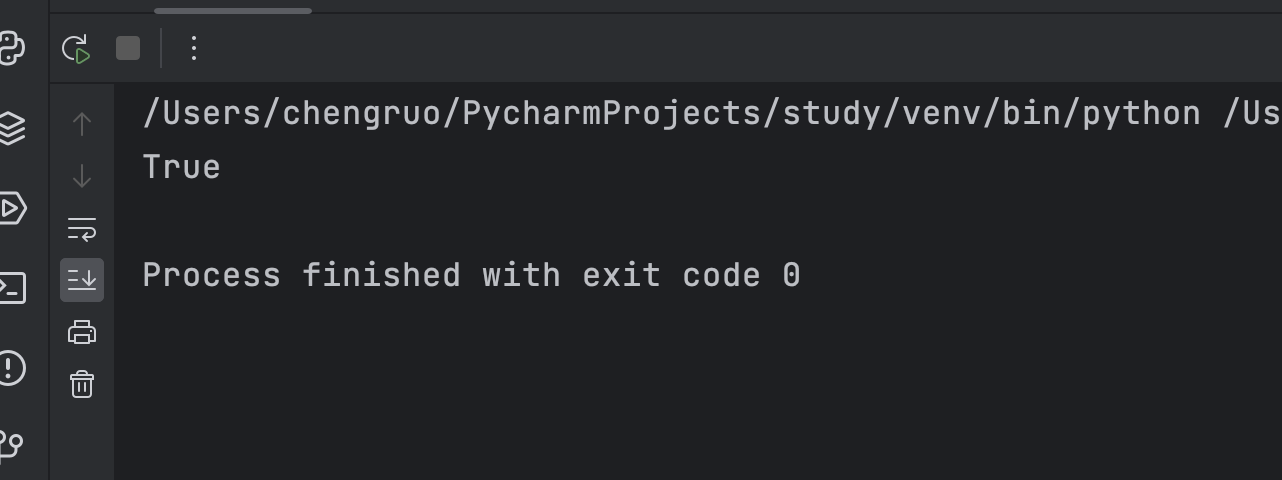
solution = Solution()
print(solution.isMatch("ab", ".*"))
运行结果
完结