文章目录
- 前言
- webshell流量特征
- 内存马
- 蜜罐
- 应急响应
- Windows 事件ID
- 如何是误报还是攻击(如何判断是否攻击成功)
- 研判的思路
- 渗透测试思路
- 内网渗透相关
- 溯源反制
- 反序列化(Shiro、Weblogic、Log4j)
- CDN
- MySQL5.5版本以上和以下读写权限的区别
- PHP伪协议
- Apache、Nginx解析漏洞
- MySQL的UDF提权
- 无法连接服务器 3389 端口的几种情况
- SQLMap的os-shell
- Session、Cookie、Token
- HTTP、HTTPS
- 三次握手、四次挥手
- Nmap常用命令
- 手机号如何对攻击者进行画像
- MD5加盐
- oracle、mongodb、mssql和mysql注入的区别
前言
护网的定义是以国家组织组织事业单位、国企单位、名企单位等开展攻防两方的网络安全演习。进攻方一个月内采取不限方式对防守方展开进攻,不管任何手段只要攻破防守方的网络并且留下标记即成功,直接冲到防守方的办公大楼,然后物理攻破也算成功。护网是国家应对网络安全问题所做的重要布局之一。
护网随着中国对网络安全的重视,涉及单位不断扩大,越来越多都加入到“护网”中,网络安全对抗演练越来越贴近实际情况,各机构对待网络安全需求也从被动构建,升级为业务保障刚需。随着大数据、物联网、云计算的快速发展,愈演愈烈的网络攻击已经成为国家安全的新挑战。护网行动是由公安机关组织的“网络安全攻防演习”,每支队伍3-5人组成,明确目标系统,不限攻击路径,获取到目标系统的权限、数据即可得分,禁止对目标实施破坏性操作,对目标系统关键区域操作需得到指挥部批准。
webshell流量特征
1、蚁剑:
蚁剑静态特征:蚁剑中php使用assert、eval执行;asp只有eval执行;在jsp使用的是Java类加载(ClassLoader),同时会带有base64编码解码等字符特征。
蚁剑动态特征:我们使用一句话木马上传webshell,抓包后会发现每个请求体都存在以@ini_set("display_errors","0");@set_time_limit(0)开头。
且响应体的返回结果是base64编码发混淆字符,格式为:随机数 结果 随机数。
2、冰蝎:
冰蝎3.0流量特征:使用AES加密 + base64编码,取消了2.0的动态获取密钥,使用固定的连接密钥,
AES加密的密钥为webshell连接密码的MD5的前16位,默认连接密码是"rebeyond"(即密钥是md5('rebeyond')[0:16]=e45e329feb5d925b)。
进行请求时内置了十几个User-Agent头,每次请求时会随机选择其中的一个。
因此当发现一个ip的请求头中的user-agent在频繁变换,就可能是冰蝎。
3.0连接jsp的webshell的请求数据包中的content-type字段常见为application/octet-stream。
冰蝎4.0流量特征:
提供了传输协议自定义的功能,让用户对流量的加密和解密进行自定义,实现流量加解密协议的去中心化。
v4.0版本不再有连接密码的概念,自定义传输协议的算法就是连接密码。
Accept字段(弱特征),通常是Accept: application/json, text/javascript, /; q=0.01 意思是浏览器可接受任何文件,但最倾向application/json 和 text/javascript。
Content-Type字段(弱特征),通常是Content-type: Application/x-www-form-urlencoded
与冰蝎的前述版本相似,进行请求时内置了十几个User-Agent头,每次请求时会随机选择其中的一个。
连接的端口有一定的特征,冰蝎与webshell建立连接的同时,java也与目的主机建立tcp连接,每次连接使用本地端口在49700左右(就是比较大的端口),每连接一次,每建立一次新的连接,端口就依次增加。
使用长连接,避免了频繁的握手造成的资源开销。默认情况下,请求头和响应头里会带有 Connection:Keep-Alive
有固定的请求头和响应头,请求字节头:dFAXQV1LORcHRQtLRlwMAhwFTAg/M ,响应字节头:TxcWR1NNExZAD0ZaAWMIPAZjH1BFBFtHThcJSlUXWEd
默认时,冰蝎 webshell都有“e45e329feb5d925b” (rebeyond)一串密钥,与冰蝎3.0相同。
3、哥斯拉:
哥斯拉静态特征:
在默认脚本编码的情况下,jsp会出现xc、pass字符和Java反射(ClassLoader,getClass().getClassLoader()),base64加解码等特征。
哥斯拉动态特征:
User-Agent字段(弱特征),如果采用默认的情况,会暴露使用的jdk信息。不过哥斯拉支持自定义HTTP头部,这个默认特征是可以很容易去除的。
Accept字段(弱特征),默认是Accept:text/html, image/gif, image/jpeg, *; q=.2, /; q=.2。同上,这个也可修改,只能作为辅助检测的特征。
Cookie中有一个非常关键的特征,最后会有个分号。估计后续的版本会修复。
响应体的数据有一定特征,哥斯拉会把一个32位的md5字符串按照一半拆分,分别放在base64编码的数据的前后两部分。整个响应包的结构体征为:md5前十六位+base64+md5后十六位。
4、菜刀:
菜刀静态特征:
PHP: <?php @eval([$_post['test']]); ?>
ASP: <% eval request("test")%>
ASP.NET: <%@ Page Language="Javascript"%><% eval(Request.Item["test"],"unsafe");%>
菜刀动态特征:
payload在请求体中,采用url编码+base64编码,payload部分是明文传输。
payload中有eval或assert、base64_decode这样的字符。
payload中有默认固定的&z0=QGluaV9zZXQ...这样base64加密的攻击载荷,参数z0对应$_POST[z0]接收到的数据,且固定为QGluaV9zZXQ开头。
进行base64解码后可看到代码:@ini_set("display_errors","0");@set_time_limit(0);@set_magic_quotes_runtime(0);这段意思是首先关闭报错和magic_quotes,接下来去获取主机的信息。
内存马
1、介绍:内存马也被称为无文件码,利用中间件的进程执行某些恶意代码,不会有文件落地。
由客户端发起的Web请求后,中间件的各个独立的组件如Listener、Filter、Servlet等组件会在请求过程中做监听、判断、过滤等操作,
内存马就是利用请求过程在内存中修改已有的组件或动态注册一个新的组件,插入恶意的shellcode,达到持久化控制服务器的目的。
内存马可以通过访问存在漏洞的url加上命令执行参数,即可让服务器返回结果,也可通过webshell管理工具例如:蚁剑、冰蝎、哥斯拉等进行远程连接后攻击目标。
2、java内存马又主要分为下面这三大类:
1、servlet-api类:filter型、servlet型、listener型
2、spring类:拦截器、controller型
3、Java Instrumentation类:agent型
3、对于内存马的排查思路:
1、先查看检查服务器web日志,查看是否有可疑的web访问日志,比如说filter或者listener类型的内存马,
会有大量url请求路径相同参数不同的,或者页面不存在但是返回200的请求。
2、如在web日志中并未发现异常,可以排查是否为中间件漏洞导致代码执行注入内存马,排查中间件的error.log日志查看是否有可疑的报错,
根据注入时间和方法根据业务使用的组件排查是否可能存在java代码执行漏洞以及是否存在过webshell,排查框架漏洞,反序列化漏洞。
3、查看是否有类似哥斯拉、冰蝎特征的url请求,哥斯拉和冰蝎的内存马注入流量特征与普通webshell的流量特征基本吻合。
4、通过查找返回200的url路径对比web目录下是否真实存在文件,如不存在大概率为内存马。
4、内存马特征的识别(以filter内存马为例):
1、filter特殊名称:内存马的Filter名一般比较特别,随便一点的可能有shell,Mem这种关键词或者随机数随机字母。
当然这个特征并不是决定条件,因为讲究一点的攻击者也可以将filter伪装成web应用自带的名称。
2、filter优先级:为了确保内存马在各种环境下都可以访问,往往需要把filter匹配优先级调至最高,比如shiro反序列化漏洞。
3、web.xml中没有filter配置:内存马的Filter是动态注册的,所以在web.xml中肯定没有配置,如果发现了在web.xml中不存在的filter,那么这个filter就十分可疑了
4、特殊classloader加载:一般来说,正常的Filter都是由中间件的WebappClassLoader加载的。
而攻击者利用的getshell攻击链往往具有明显的特征,比如反序列化漏洞喜欢利用TemplatesImpl和bcel执行任意代码。
5、对应的classloader路径下没有class文件:所谓内存马就是代码驻留内存中,本地无对应的class文件。
所以我们只要检测Filter对应的ClassLoader目录下是否存在class文件。(这也是很多内存马检测脚步实现的原理)
6、Filter的doFilter方法中有恶意代码:可以把内存中所有的Filter的class dump出来,使用反编译工具分析看看,是否存在恶意代码,
比如调用了:java.lang.Runtime.getRuntime,defineClass,invoke
5、内存马检测工具:
1、脚本 tomcat-memshell-scanner.jsp:
优点:使用非常简单,将脚本放在能访问的web路径下,然后直接访问就可以获得结果。
支持Dump出来使用反编译工具分析是否存在恶意代码
支持直接Kill掉
缺点:只支持Tomcat相关的内存马
2、河马的内存马查杀工具
优点:适用多种中间件的内存马
缺点:易出Bug,不支持直接Dump或Kill
3、Arthas:
是Alibaba开源的Java诊断工具,不是专门用户内存马的检测,
但是由于java内存马相当于利用了jvm的底层特性,所以可以给我们对内存马的排查带来很多便利
蜜罐
1、介绍:蜜罐(Honeypot)是一种安全技术,旨在诱使攻击者进入一个看似真实但实际上是有意制造的弱点、易受攻击或有漏洞的系统或网络环境。
蜜罐的目的是吸引和捕获攻击者,以便收集他们的行为信息、攻击手段、利用漏洞的方式和其他有关攻击者的情报。
蜜罐通常是一个虚拟或物理系统,与真实系统类似,但被专门配置和监视,以检测、记录和分析攻击活动。
2、蜜罐怎么获取攻击者的社交信息的?
攻击者与蜜罐的交互:攻击者进入蜜罐后,他们与蜜罐进行交互,执行攻击行为或尝试获取信息。这些交互可以包括攻击指令、命令执行、数据传输、文件上传等。通过监控和记录这些交互,可以获取攻击者的行为信息和攻击手段。
日志和网络记录:蜜罐会详细记录攻击者与蜜罐之间的所有网络活动,包括网络连接、协议交互、数据包捕获等。这些记录可以提供有关攻击者的IP地址、使用的工具、攻击技术和行为模式等信息。
仿冒目标:蜜罐可能模拟一个真实的社交媒体、论坛或其他在线平台,吸引攻击者注册并参与讨论。在这个过程中,攻击者可能会填写一些个人信息,例如用户名、电子邮件地址、个人简介等。
蜜罐联动:蜜罐可以与其他安全系统和情报源进行联动,将攻击者的活动信息与其他信息进行关联和分析。例如,与入侵检测系统(IDS)、情报共享平台或威胁情报服务进行集成,以获取更全面的攻击者情报。
3、如果叫你部署一个蜜罐,你会开放哪些端口?
21端口:FTP文件传输协议端口,用来捕获黑客的FTP爆破行为
22端口:SSH端口 链接Linux主机SSH服务的端口,用来捕获黑客的SSH爆破行为
23端口:Telnet服务,命令执行服务,用来探测黑客对于telnet的爆破
80端口/443端口:WEB服务的端口,用来捕获黑客的WEB攻击行为特征
1521:oracle数据库开放端口,捕获黑客的oracle爆破行为,UDF命令执行等行为
3306:MYSQL端口,用来捕获黑客对于mysql数据库的爆破行为,UDF命令执行等行为
3389:Windows远程桌面端口,用来捕获黑客的爆破行为
应急响应
1、应急响应大致思路:(PDCERF 模型:准备-检测-抑制-根除-恢复-跟踪)
1、信息收集:首要任务是收集相关信息,包括事件影响范围、事件类型、攻击源头主机、攻击意图以及是否需要保障业务等,这些信息有助于下一步的阻断。
2、阻断攻击行为:根据已知信息采取相应的行动来阻断攻击行为并保护资产。
例如,如果攻击行为局限于某个站点且未造成重大损失,可以直接封锁攻击者的IP地址以确保业务的正常进行。
对于主机或域控服务器被攻陷的情况,需要及时将受感染设备断网处理。如果存在备份服务器,可以切换至备用设备以确保业务的正常运行。
3、数据保护:阻断攻击行为后,需要对数据进行保护。这包括保存流量记录、可疑进程的内存信息、受影响系统的镜像、恶意样本以及设备的日志等。这些数据有助于后续的溯源工作。
4、安全事件根除:结合工具和手动检查系统用户是否有新增用户、进程信息、计划任务、自启动项、注册表、端口状态等方面,检查是否存在可疑行为。
可以使用诸如火绒剑、ProcessHacker等工具进行分析。如发现可疑行为,直接关闭或删除相关进程或文件。
对于无法关闭或删除的顽固进程或文件,可以结合专杀工具如Rkhunter、火绒等进行处理。
5、恢复业务与加固系统:在根除安全事件后,需要恢复业务并加强安全措施。这包括更新软件版本、安装已知漏洞的补丁、关闭不必要的端口等。对于暂时无法解决的问题,可以根据业务需求暂时关闭某些服务。
6、输出报告与总结反思:最后,需要生成一份详细的报告,总结应急响应过程并进行反思。
报告应包括事件的背景、应急响应措施的描述、阻断行动的结果以及后续的改进建议。这有助于改进应急响应策略和提高组织的安全能力。
应急事件如何定位到具体设备?
MAC地址追踪:根据态势感知、防火墙的流量告警或日志等拿到被攻击的内网IP,然后查找交换机或路由器的ARP表里对应IP的MAC地址和接口,最终定位到具体设备
2、Webshell的应急响应:
1、先找到现象发生的位置,根据整个Web应用数据流逻辑找对应风险点,
被植入后门的“现象”一般是如下述几种情况:
1、HOSTS文件被篡改:访问正常域名,错误解析会跳转到非法网站。
2、网卡DNS配置被修改:指向恶意的DNS服务器也可造成错误解析。
3、终端发起DNS解析请求:局域网DNS劫持,也是跳转到非法网站。
4、域名对应IP被修改:在域名服务商那注册的账号泄露,导致域名对应IP被修改。
5、CDN服务器污染:CDN缓存未更新,还是缓存被挂黑链时的页面。
6、服务器被篡改:也是遇到“最多”的情况,需要找到在服务器上被篡改的位置。
这里以服务器被篡改为例,找到篡改的文件后,确定文件被修改时间,如果是web页面文件,
则可根据修改时间点以及文件名,搜索指定日志文件,找到访问记录,根据访问记录,我们可以定位源IP
(当然,这种情况是服务器前端没过云WAF或CDN,否则源IP非真实IP)
最好是第一次访问的源IP和它的时间点,可靠度最高
(因为攻击者上传webshell后,很可能会访问一次该文件判断是否写入成功)
如果无法定位源IP,则检查访问路径是否为敏感路径(如后台),根据源IP或敏感路径,过滤出相应访问日志,
根据过滤后的日志,尝试分析整个攻击过程的操作,看是否有可疑漏洞触发点访问。
当无法根据以上定位时,可以多关注事件发生附近时间点的POST请求,上传webshell绝大部分情况都是使用POST上传,可关注里面可疑路径的POST提交)
2、使用手工配合杀软(D盾)进行全盘扫描,彻底清除Webshell,移除所有可疑文件。
3、安全加固:及时更新和修补Web应用程序及相关组件的漏洞、配置适当的访问控制和权限管理、使用IDS、IPS、WAF等安全设备、使用HTTPS协议等
4、输出报告与总结反思
3、挖矿病毒应急响应相关:
1、特征为:挖矿服务器的CPU或GPU占用率居高不下;外连矿池地址矿池地址一般含有pool、xmr、eth、bth等字符;爆破行为等
2、挖矿病毒的确认:
1. 通信端口:挖矿木马可能会使用特定的端口进行通信。例如,Monero挖矿木马通常会使用TCP端口3333或5555进行通信
2. 通信流量:挖矿木马的通信流量可能会具有特定的特征,例如大量的高速数据传输和周期性的通信,在数据包中可以看到大量的计算资源使用信息和挖矿结果信息
3. 进程和文件系统:挖矿木马可能会创建特定的进程和文件来执行挖矿操作。例如,Monero挖矿木马通常会在操作系统上创建名为""xmrig""的进程,并在文件系统上创建名为""config.json""的配置文件
4. 系统资源:挖矿木马可能会占用系统资源,例如CPU和内存,并可能导致系统崩溃或变得缓慢。
5. 判断流量的数据:挖矿木马通常会在通信中发送一些特定的数据,例如挖矿难度、钱包地址、挖矿程序版本等,如果流量中存在这些数据,就可能存在挖矿木马
6. 看数据包的详细信息,看终端或者服务器是否有与矿池交互的信息,判断是否存在登录到矿池(method“:”login“)、从矿池接收任务(”method“:”job“)字段,在载荷内容中是否存在ok、success等字段"
3、挖矿病毒的应急响应流程:
1、了解攻击情况及范围:与受影响的服务器管理员或相关人员沟通,了解挖矿病毒的现状。获取事件发生的时间节点、网络架构和受影响范围。
2、临时抑制:如果能断网的业务进行断网处理,不能断网的业务可以关闭高危端口 比如445 3389,或者向上面写申请一个维护页面挂在该web网页
2、攻击痕迹挖掘:根据高CPU占用、异常进程、开放的端口、计划任务、启动项和可疑账户等线索,定位到挖矿病毒的样本。这些痕迹有助于确定挖矿病毒的来源和入侵路径。
3、样本分析:备份挖矿病毒样本,并使用云沙箱等工具对样本进行行为分析。这有助于了解病毒的特征、功能和传播方式,并为后续的排查和根除提供指导。
4、排查与根除:挖矿病毒通常会进行权限维持,因此需要彻底排查和根除恶意的计划任务、启动项、SSH公钥、进程和病毒文件。删除相关的病毒文件,并修复受影响系统的安全漏洞。
5、溯源:(根据攻击痕迹的清晰程度分为两种情况进行溯源)
攻击痕迹清晰:通过安全设备日志、系统日志等进行溯源分析。重点关注攻击的时间节点、攻击方式、病毒文件、攻击者身份和攻击复现。通过收集和分析这些信息,可以更好地了解攻击者的行为和目的。
攻击痕迹记录不全:进行漏洞挖掘工作,检查系统中可能存在的安全漏洞。同时,与相关人员进行交流,询问是否有其他可用的信息或线索。
6、提出修改建议和输出文档:根据应急响应的经验和挖矿病毒的特点,提出系统的修改建议和加固措施。将应急响应的流程、结果和建议整理成文档,以便参考和后续的改进工作。
4、挖矿病毒的应急处置:
1、Linux系统:
top命令查看进程,有异常的话netstat -anpt查看外连IP,通过微步确认可疑IP是否为矿池地址或恶意脚本地址;无异常的话确认库文件是否正常,使用busybox删除恶意库文件
查看/etc/crontab和/var/spool/cron目录,排查可疑的计划任务;也可以使用crontab -l命令查询。
查看/etc/rc.d目录和/etc/init.d目录,排查可疑开机启动项。
查看/etc/profile、/etc/bashrc、~/.bash_profile和~/.bashrc文件,排查可疑环境变量。
将前面排查出来的病毒相关文件全部清除。
Kill -9 [PID]结束挖矿进程,主机恢复正常
2、windows系统:
netstat -ano和tasklist | findstr 'PID'查看外连情况以及对应的进程
如果无法定位到可疑进程,可使用“Procexp.exe”工具查看,通过OptionConfig colors看到不同颜色的各个进程,重点关注紫色、深红色以及浅蓝色。
使用AutoRuns工具查看注册表、启动项、计划任务和服务是否异常。Autoruns 中应重点观察被标记为红色或黄色的项目,重点观看发布者 Not Verified(未签名)的项目,未签名文件要查看 Image Path项(即实际执行文件路径)
使用PCHunter工具将前面处置2.1-2.4排查出来的病毒相关文件全部清除,特别注意以下几个目录:
C:\users\用户\AppData\Local\Temp
C:\Windows\System32\
C:\Windows\SysWOW64\
C:\users\用户\AppData\Local\Temp
C:\Windows\system32\drivers\
C:\Users\用户\AppData\Local\Microsoft\
清除顺序一般为:删除恶意驱动文件恶意dll异常服务异常计划任务异常启动项异常SQLServer作业恶意进程母体病毒释放的残留文件。
Windows 事件ID
1、常见事件ID:
"win+R",在弹出的运行对话框中输入 “eventvwr.msc”,打开自带的事件查看器
1074,查看计算机的开机、关机、重启的时间以及原因和注释。
6005,表示日志服务已启动,用来判断正常开机进入系统。
6006,表示日志服务已停止,用来判断系统关机。
6009 表示非正常关机, 按ctrl、alt、delete键关机。
41,表示系统在未先正常关机的情况下重新启动。当出现意外断电关机、系统崩溃时,出现此事件ID。
4199,当发生TCP/IP地址冲突的时候,出现此事件ID,用来排查用户IP网络的问题。
35,36,37,记录时间客户端状态信息,35表示更改时间源,36表示时间同步失败,37表示时间同步正常
134,当出现时间同步源DNS解析失败时会出现此事件ID。
7045,服务创建成功
7030,服务创建失败
4624,表示成功登陆的用户,用来筛选该系统的用户登陆成功情况。
4625,表示登陆失败的用户,用来判断RDP爆破的情况。
4672,表示授予了特殊权限
2、Windows登录失败的事件ID不同版本有区别吗?
Windows登录失败的事件ID在不同版本的操作系统中可能会有一些区别。
事件ID 4625:这是Windows中通用的登录失败事件ID。它在不同的Windows版本中保持一致,表示登录尝试失败。
事件ID 4771:这是Windows Server 2008及更高版本中引入的事件ID,用于记录Kerberos预身份验证失败的情况。它指示在Kerberos身份验证期间发生了错误或失败。
事件ID 529和事件ID 680:这些事件ID在较早的Windows版本(如Windows XP和Windows Server 2003)中使用,用于表示登录失败的情况。事件ID 529用于本地账户的登录失败,而事件ID 680用于域账户的登录失败。
如何是误报还是攻击(如何判断是否攻击成功)
1、首先分析IP看是内网还是公网IP,若是内网IP就和内部人员沟通一下是否为正常访问情况,若是公网可以放沙箱检测一下
2、然后分析请求头各字段(如url、cookie、user-agent、referer等)和请求体中有无恶意payload,同时关注工具流量特征(如哥斯拉、冰蝎、SQLMap等)
3、然后看响应包,返回的内容是否正常,可以判断攻击是否成功(比如SQL联合注入,有没有返回数据库信息;又比如布尔盲注,看返回的页面长度是否正常)
4、同时结合日志进行分析,看请求路径、请求频率、响应码等(比如短时间出现大量请求返回404时就有可能是目录扫描之类的,根据请求数据包里的特征符、标识做判断)
5、还可以结合多台安全设备的告警情况,如果多台都告警,那么大概率是攻击,如果只有一台检测到了而其他设备没检测到,那么可能是误报
6、注意:真实攻击不可能只持续一次,它一定是长时间、周期性、多 IP 的进行攻击
研判的思路
1.首先对攻击的来源进行判断,是内对内,外对内还是内对外的情况。
2.依据设备的告警信息结合具体情况来分析攻击行为的类型,比如说告警 SQL 注入攻击,那我们就去查看一下请求数据包里面是否有单引号,SELECT 等敏感字符,返回数据包里面是否有 SQL 语法报错等信息,有的话就可以初步判断该攻击行为是 SQL 注入攻击。
3.然后就是根据攻击特征来分析攻击行为使用了什么技术或者说工具,比如说攻击的频率,数据包的信息等等。
比如说在使用 AWVS 或者 APPSCAN 等工具在扫描的时候,很有可能在请求数据包的 useragent 里面就有相关的信息。
同样结合告警信息和具体情况来判断攻击行为的危害程度,比如说检测到多条攻击成功告警和内对内及内对外攻击告警,这个时候就需要尽快的交给应急组了。
4.结合设备告警信息及具体情况分析攻击意图,比如说攻击者的目标是主站还是旁站,是主机还是域控,不同的攻击意图对于后续的处理也不同。
5.最后根据我们掌握的信息采取相应的处置方式,比如说告警信息是误报,说明设备需要策略优化,不需要处置。
告警信息是尝试攻击,暂时对资产没有影响,就需要后续持续关注,攻击成功时能够做到及时上报。
如果告警确认不是误报,并且攻击成功时,我们就需要迅速上报及时采取应急响应。
渗透测试思路
0、渗透测试步骤:信息收集->漏洞扫描->漏洞利用->权限提升->痕迹清理->总结报告以及修复方案
1、信息收集
a、服务器的相关信息(真实ip,系统类型,版本,开放端口,WAF等)
b、网站指纹识别(包括,cms,cdn,证书等),dns记录
c、whois信息,姓名,备案,邮箱,电话反查(邮箱丢社工库,社工准备等)
e、子域名收集,旁站,C段等
f、google hacking针对化搜索,pdf文件,中间件版本,弱口令扫描等
g、扫描网站目录结构,爆后台,网站banner,测试文件,备份等敏感文件泄漏等
h、传输协议,通用漏洞,exp,github源码等
2、漏洞扫描
a、浏览网站,看看网站规模,功能,特点等
b、端口,弱口令,目录等扫描,对响应的端口进行漏洞探测,比如 rsync,心脏出血,mysql,ftp,ssh弱口令等。
c、XSS,SQL注入,上传,命令注入,CSRF,cookie安全检测,敏感信息,通信数据传输,暴力破解,任意文件上传,
越权访问,未授权访问,目录遍历,文件 包含,重放攻击(短信轰炸)
d、漏扫工具扫一扫,AWVS、Nessus等
3、漏洞利用
利用msf、cs、nc一些工具拿下shell或者一些其他的权限
4、权限提升
a、Windows提权手段(土豆溢出、进程注入、令牌窃取、UAC绕过、DLL劫持、不安全的服务路径或权限)
b、Linux提权手段(脏牛、SUID提权、环境变量提权、定时任务提权)
c、第三方应用提权(MySQL的UDF提权、向日葵、Teamviewer、Rsync、Docker)
5、最后痕迹清理->总结报告以及修复方案
内网渗透相关
1、内网信息收集:主机信息收集(用户和组、系统补丁、安装的软件、计划任务、服务列表、进程列表)
网络信息收集(网卡信息、网络连接、路由表、ARP缓存、防火墙配置)
存活主机发现(ICMP协议、arp协议、Netbios协议)
密码收集(系统密码、WIFI密码、第三方程序如数据库、浏览器等)
2、权限提升:Windows提权手段(土豆溢出、进程注入、令牌窃取、UAC绕过、DLL劫持、不安全的服务路径或权限)
Linux提权手段(脏牛、SUID提权、环境变量提权、定时任务提权)
第三方应用提权(MySQL的UDF提权、向日葵、Teamviewer、Rsync、Docker)
3、权限维持:Windows(自启动、进程注入、克隆帐号&激活Guest)
Linux(自启动、ssh软链接、PAM后门)
4、代理&隧道:ICMP隧道、DNS隧道、HTTP隧道、Socks代理、端口转发)
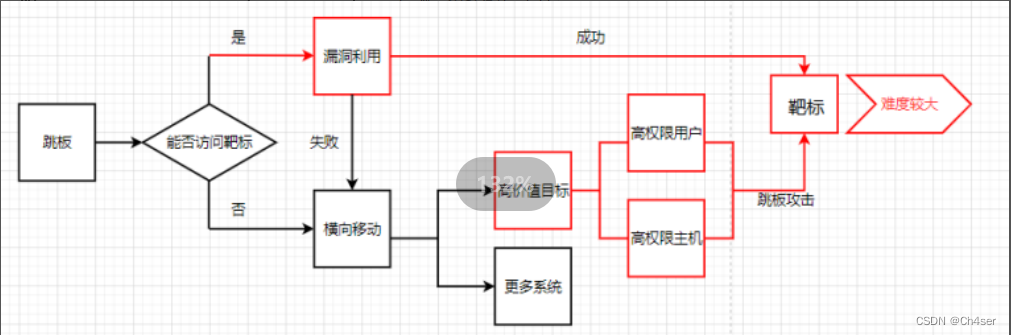
5、横向移动:见图
6、痕迹清理
溯源反制
1、攻击源捕获:
1.1、监测安全设备报警:通过扫描IP、威胁阻断、病毒木马、入侵事件等安全设备的报警信息,及时发现异常活动。
1.2、日志与流量分析:分析异常的通讯流量、攻击源与攻击目标等日志信息,找出攻击源的特征。
1.3、检测服务器资源异常:查找异常的文件、账号、进程、端口,启动项、计划任务和服务等服务器资源信息。
1.4、邮件钓鱼分析:获取恶意文件样本、钓鱼网站URL等,分析其中的信息。
1.5、利用蜜罐系统:通过设置诱骗系统来吸引攻击者,获取其ID、电脑信息、浏览器指纹、行为和意图的相关信息。
2、溯源反制:
2.1、IP定位技术:通过IP地址定位物理地址,包括代理IP,可以通过IP和端口扫描,反向渗透服务器进行分析,最终定位到攻击者的相关信息。
2.2、ID追踪术:通过搜索引擎、社交平台、技术论坛、社工库等进行ID追踪,匹配相关信息,例如从技术论坛追溯邮箱,然后通过邮箱追溯真实姓名,最终找到相关简历信息。
2.3、网站URL:通过域名Whois查询注册人的姓名、地址、电话和邮箱,进行域名隐私保护,通过攻击IP的历史解析记录/域名,对域名注册信息进行溯源分析。
2.4、恶意样本分析:提取恶意样本特征、用户名、ID、邮箱、C2服务器等信息进行同源分析,例如通过样本分析过程中发现攻击者的个人ID和QQ,从而成功定位到攻击者。
2.5、社交账号:利用JSONP跨域,获取攻击者的主机信息、浏览器信息、真实IP及社交信息等,前提是可以找到相关社交网站的jsonp接口泄露敏感信息,并且相关网站登录未注销。
3、攻击者画像:
3.1、攻击路径:确定攻击目的(拿到权限、窃取数据、获取利益、DDOS等)、使用网络代理(代理IP、跳板机、C2服务器等)、采用的攻击手法(鱼叉式邮件钓鱼、Web渗透、水坑攻击、近源渗透、社会工程等)。
3.2、攻击者身份画像:包括虚拟身份(ID、昵称、网名)、真实身份(姓名、物理位置)、联系方式(手机号、QQ/微信、邮箱)和组织情况(单位名称、职位信息)等。通过分析这些信息,可以描绘出攻击者的画像,有助于进一步追溯和反制攻击行为。
反序列化(Shiro、Weblogic、Log4j)
1、反序列化介绍:
序列化的目的是方便数据的传输和存储,在PHP中,序列化和反序列化一般用做缓存,比如session缓存,cookie等。
序列化:将对象转换为字符串以便存储传输的一种方式。
反序列化:将字符串转化为对象供程序使用。
当程序在进行反序列化时,会自动调用一些函数,例如__wakeup(),__destruct()等函数,
但是如果传入函数的参数可以被用户控制的话,用户可以输入一些恶意代码到函数中,从而导致反序列化漏洞。
_construct() 当一个对象被创建时调用
_destruct() 当一个对象被销毁时调用
_toString() 当一个对象被当作一个字符串使用
_sleep() 在对象再别序列化之前运行
_wakeup() 将在序列化之后调用
2、相关函数:
PHP:
serialize 将对象格式化成有序的字符串
unserialize 将字符串还原成原来的对象
Java:
序列化:一般通过jdk中的java.io.objectoutputstream的 writeObject() 方法实现
反序列化:一般通过jdk中的java.io.objectoutputstream的 readObject() 方法实现
3、Shiro反序列化(550、721)
3.1、Shiro-550原理:
Apache Shiro框架提供了记住密码的功能(RememberMe),用户登录成功后会生成经过加密并编码的cookie。在服务端对rememberMe的cookie值,先base64解码然后AES解密再反序列化,就导致了反序列化RCE漏洞。
那么,Payload产生的过程:命令=>序列化=>AES加密=>base64编码=>RememberMe Cookie值
在整个漏洞利用过程中,比较重要的是AES加密的密钥,如果没有修改默认的密钥那么就很容易就知道密钥了,Payload构造起来也是十分的简单。
3.2、Shiro-550流量特征:
返回包中会包含rememberMe=deleteMe字段
这种情况大多会发生在登录处,返回包里包含remeberMe=deleteMe字段,这个是在返回包中(Response)
如果返回的数据包中没有remeberMe=deleteMe字段的话,可以在数据包中的Cookie中添加remeberMe=deleteMe字段这样也会在返回包中有这个字段
3.3、Shiro-721原理:
shiro721用到的加密方式是AES-CBC,而且其中的ase加密的key基本猜不到了,是系统随机生成的。
而cookie解析过程跟cookie的解析过程一样,也就意味着如果能伪造恶意的rememberMe字段的值且目标含有可利用的攻击链的话,还是能够进行RCE的。
3.4、二者区别:
Shiro550使用已知默认密码,只要有足够的密码,不需要Remember Cookie
Shiro721的ase加密的key基本猜不到,系统随机生成,可使用登录后rememberMe去爆破正确的key值,
即利用有效的RememberMe Cookie作为Padding Oracle Attack的前缀,然后精心构造 RememberMe Cookie 值来实现反序列化漏洞攻击,难度高
4、WebLogic反序列化
4.1、weblogic反序列化在利用过程中,主要考虑四个部分:
Deliver_way :payload通过什么方式传入服务器
Payload:payload是什么格式,xml本身即为序列化对象,可直接反序列化。ysoserial生成的payload,为序列化文件
Write object():若非序列化数据,则首先经过writeobject()进行序列化
Readobject():反序列化数据
4.2、CVE-2017-10271漏洞产生的原因:
Weblogic的WLS Security组件对外提供webservice服务,
其中使用了XMLDecoder来解析用户传入的XML数据,在解析的过程中出现反序列化漏洞,导致可执行任意命令。
攻击者发送精心构造的xml数据甚至能通过反弹shell拿到权限。
4.3、为什么会触发?
xml本身就是序列化对象,通过xmldecoder进行反序列化解析 xmldecode.readObject
5、Log4j反序列化
CDN
1、CDN是什么:
CDN的全称是Content Delivery Network,即分发网络。CDN的关键技术主要有内容存储和分发技术。
CDN是构建在网络之上的容分发网络,依靠部署在各地的边缘服务内器,通过中心平台的负容载均衡、内容分发、调度等功能模块,使用户就近获取所需内容,降低网络拥塞,提高用户访问响应速度和命中率。
2、验证是否有CDN:
使用多地 ping 的服务,查看对应 IP 地址是否唯一,如果不唯一大概率就是存在 CDN
使用 nslookup 命令检测,查看返回域名解析对应 IP 地址是否唯一,如果不唯一很可能存在 CDN
3、绕过CDN得到真实IP:
子域名查询:因为有些主站是做了CDN服务而子站是没有做CDN服务
邮件服务查询:因为邮箱大部分都是内部人在访问、而且访问的量也不是很大,一般是没有做CDN。
国外地址请求:因为很多的企业没有在国外部署CDN,要是用国外的地址请求、就容易找到他的真实地址。
遗留文件、扫描全网:如PHPinfo信息当中会遗留出ip地址
黑暗引擎搜索:fofa、shodan、钟馗之眼等
奇淫技巧:fackcdn、w8fuckcdn、zmap、社工
4、验证IP是否真实:
使用端口扫描工具 nmap 扫描开了哪些端口,然后结合开放的端口直接访问找到的 IP,看看响应的页面是不是和访问域名返回的一样
MySQL5.5版本以上和以下读写权限的区别
1、常规读写权限:在MySQL 5.5版本以下,常规的读写权限控制是通过SELECT、INSERT、UPDATE和DELETE等语句进行控制的。而在MySQL 5.5版本以上,引入了更细粒度的权限控制,可以使用GRANT语句为用户分配更具体的权限,如SELECT、INSERT、UPDATE、DELETE、CREATE、DROP等。
2、数据库级别权限:MySQL 5.5版本以下,权限是以全局为单位进行授予的,即用户对整个MySQL实例拥有相同的权限。而在MySQL 5.5版本以上,引入了数据库级别的权限控制。可以为用户分配对特定数据库的权限,使其只能在指定数据库上执行相应的操作。
3、表级别权限:MySQL 5.5版本以下,权限是以数据库为单位进行授予的,即用户对整个数据库内的所有表都有相同的权限。而在MySQL 5.5版本以上,引入了更细粒度的权限控制,可以为用户分配对特定表的权限,使其只能在指定表上执行相应的操作。
4、列级别权限:MySQL 5.5版本以下,没有原生支持列级别的权限控制。而在MySQL 5.5版本以上,引入了列级别的权限控制。可以为用户分配对特定表的特定列的权限,使其只能对指定列进行读写操作。
PHP伪协议
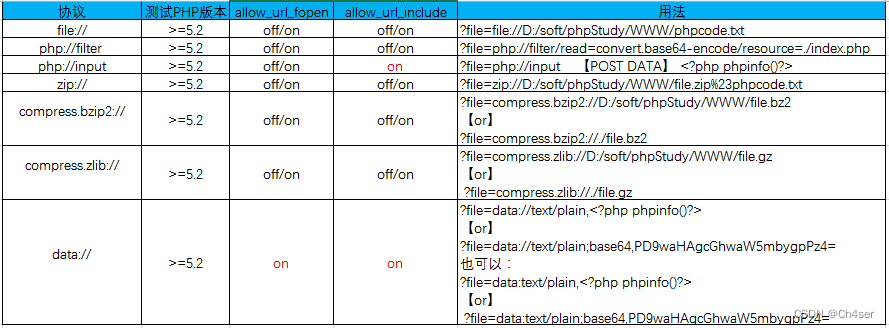
1、常用场景:文件包含
2、注意两个关键参数:
allow_url_fopen:默认值是ON,允许url里的封装协议访问文件
allow_url_include:默认值是OFF,不允许包含url里的封装协议包含文件
3、各协议利用条件和方法:如图
4、各协议详细介绍:
php://input:
用于执行php代码,将post请求的数据当作php代码执行。
当传入的参数作为文件名打开时,可以将参数设为php://input,同时post想设置的文件内容,php执行时会将post内容当作文件内容。
例如 ?file=php://input [后面的在POST DATA内] <?php phpinfo(); ?>(执行phpinfo)
php://filter
用于读取源码居多。
例如 ?file=php://filter/read=convert.base64-encode/resource=index.html(读取10.1.1.7中index.php文件以base64编码输出)
file://
用于访问服务端本地文件。
当指定相对路径时将基于当前的工作目录。
例如 ?file=./phpinfo.txt(访问当前目录下的phpinfo.txt)
?file=file://E:\phpStudy\PHPTutorial\WWW\phpinfo.txt
http://、https://
URL 形式,允许通过 HTTP 1.0 的 GET方法,以只读访问文件或资源,通常用于远程包含。
例如 ?file=http://192.168.1.100/phpinfo.txt(远程包含192.168.1.100上的phpinfo.txt)
phar://、zip://、bzip2://、zlib://
用于读取压缩文件,通常是配合文件上传进行使用。
可以访问压缩文件中的子文件,更重要的是不需要指定后缀名,可修改为任意后缀。
例如 http://127.0.0.1/include.php?file=zip://E:\phpStudy\PHPTutorial\WWW\phpinfo.jpg%23phpinfo.txt
data://
用于执行php代码。
例如 ?file=data://text/plain,<?php phpinfo();?>
?file=data://text/plain;base64,PD9waHAgcGhwaW5mbygpOz8%2b
Apache、Nginx解析漏洞
1、Nginx解析漏洞:
先上传一句话木马 webshell.jpg,然后构造 http://your-ip/uploadfiles/webshell.jpg/1.php 去访问它,发现其被当作 PHP 文件解析。
Nginx 把以 .php 结尾的文件交给 fastcgi 处理,但 fastcgi 处理的时候发现并没有这个文件,于是 fastcgi 会继续向上查找,然后找到了上级文件 .jpg,于是就把 .jpg 当作 PHP 文件处理,导致漏洞产生。
为什么 fastcgi 会向上查找?
这是因为 PHP 配置文件 php.ini 中 cgi.fix_pathinfo=1,这项配置用于修复路径,如果当前路径不存在则采用上层路径。
为什么 fastcgi 会把 jpg 文件当作 PHP 文件解析?
这是因为 php-fpm.conf 的配置项 security.limit_extensions 限制了 fastcgi 解析文件的类型。此项设置为空时,fastcgi 会将 jpg 等文件当做 PHP 代码解析
2、Apache解析漏洞:
Apache默认一个文件可以有多个用.分割的后缀,默认从右往左查找,无法识别则继续向左查找,直到碰到合法后缀才进行解析。比如 1.php.xxx.yyy。
MySQL的UDF提权
1、UDF介绍:MySQL UDF的设计初衷是为了方便用户自定义一些函数,方便查询一些复杂的数据。
2、提权原理:
黑客编写调用cmd或者shell的udf.dll文件,并且导入到一个指定的文件夹目录下,创建一个指向udf.dll的自定义函数,从而在数据库中的查询就等价于在cmd或者shell中执行命令。
不同的操作系统,不同的版本,提权时导出udf.dll存放的目录不一样,在MySQL 5.1版本及以后的环境下,udf提权时需要将udf.dll导出到mysql安装目录\lib\plugin\目录下。
3、工具:MDUT
无法连接服务器 3389 端口的几种情况
3389端口是远程桌面协议(Remote Desktop Protocol,简称RDP)的默认端口号
1、3389 端口处于关闭状态
2、默认端口号被修改
3、防火墙拦截
4、服务器处于内网环境
5、超过了服务器最大连接数
6、管理员设置了权限,指定用户才能通过 3389 端口进行远程桌面访问
SQLMap的os-shell
1、原理:
使用udf提权获取webshell,通过into outfile向服务器写入两个文件,一个是可以直接执行系统命令,一个是进行上传文件。
2、前提条件:
1、网站必须是dba权限
2、知道网站的绝对路径(可以通过网页报错信息、phpinfo、爆破等方式得到)
3、PHP关闭魔术引号转义,即 magic_quotes_gpc = off
4、参数 secure_file_priv=值为空,即任意路径都可以导入、导出文件(可以通过show global variables like '%secure%';查询)
Session、Cookie、Token
1、Cookie 是客户端存储的一小块数据,它会在客户端和服务器之间来回传递。
Cookie 会被存储在浏览器的文件系统里,并且在浏览器发送请求的时候会自动携带这些数据。
2、Session 是在服务器端存储的一小块数据,它可以用来跟踪用户的状态。Session 数据存储在服务器端,并且由服务器端来维护。
客户端访问服务器时,服务器会根据客户端的请求来确定客户端的身份,并且为客户端分配一个session ID
客户端每次请求时都会携带session ID ,服务器通过这个 session ID 来识别客户端并获取相应的 session 数据
3、Token 是一种在客户端和服务器端之间传递身份验证凭据的方法,它通常是一个字符串,可以用来表示用户的身份或者权限。
Token 可以用来代替传统的 Session 和 Cookie,因为它可以在不同的系统之间共享,而且不容易被窃取
HTTP、HTTPS
1、HTTP是一种基于文本的协议,用于在Web浏览器和Web服务器之间传输数据。它使用TCP/IP协议来传输数据,并使用默认端口号80。
HTTP协议在传输过程中不对数据进行加密,因此在传输敏感信息时存在安全风险。
2、HTTPS是HTTP的安全版本,它通过使用TLS(Transport Layer Security)或SSL(Secure Sockets Layer)协议对数据进行加密和身份验证。
这种加密可以防止恶意用户窃取或篡改数据。HTTPS使用默认端口号443。
3、二者比较:
安全性:HTTP在数据传输过程中不加密数据,而HTTPS使用加密机制对数据进行安全保护。因此,HTTPS更适合传输敏感信息,如信用卡号码、登录凭证等。
数据完整性:HTTPS通过使用数字证书对数据进行身份验证和完整性检查,确保数据在传输过程中未被篡改。
默认端口:HTTP使用端口号80,而HTTPS使用端口号443。
证书:HTTPS使用数字证书来验证Web服务器的身份,确保客户端与服务器之间的通信是安全的。
性能:由于加密和解密过程会增加处理开销,HTTPS通常比HTTP稍微慢一些。然而,随着计算机硬件和网络技术的发展,这种差异正在逐渐减小。
总的来说,HTTPS相比于HTTP提供了更高的安全性和数据完整性,适用于需要保护隐私和安全的网站和应用程序。
三次握手、四次挥手
1、三次握手的工作原理如下:
客户端向服务器发送一个SYN(同步)数据包,表示请求建立连接。
服务器收到SYN数据包后,向客户端发送一个SYN-ACK(同步-确认)数据包,表示同意建立连接。
客户端收到SYN-ACK数据包后,向服务器发送一个ACK(确认)数据包,表示连接已建立
2、四次挥手的工作原理如下:
客户端向服务器发送一个FIN(结束)数据包,表示要关闭连接。
服务器收到FIN数据包后,向客户端发送一个ACK数据包,表示收到了关闭请求。
服务器向客户端发送一个FIN数据包,表示服务器也要关闭连接。
客户端收到FIN数据包后,向服务器发送一个ACK数据包,表示收到了关闭请求,连接已经关闭
Nmap常用命令
nmap -sT 192.168.96.4 //TCP连接扫描,不安全,慢
nmap -sS 192.168.96.4 //SYN扫描,使用最频繁,安全,快
nmap -Pn 192.168.96.4 //目标机禁用ping,绕过ping扫描
nmap -sU 192.168.96.4 //UDP扫描,慢,可得到有价值的服务器程序
nmap -sI 僵尸ip 目标ip //使用僵尸机对目标机发送数据包
nmap -sA 192.168.96.4 //检测哪些端口被屏蔽
nmap 192.168.96.4 -p <portnumber> //对指定端口扫描
手机号如何对攻击者进行画像
1、电话号码分析:通过电话号码的前缀或国际区号,你可以大致确定攻击者所在的地理位置。这可以帮助你了解攻击者的大致所在地和可能的时区。
2、逆向查询:使用逆向查询服务,如反查电话号码的在线工具或商业服务,可以获取有关该电话号码的一些基本信息。这可能包括电话号码的所有者姓名、地址或其他注册信息。请注意,这种服务的可用性和准确性因国家和地区而异。
3、社交媒体分析:使用攻击者的电话号码搜索社交媒体平台,可能会找到与该号码相关的公开信息。这些信息可能包括与该电话号码关联的社交媒体账户、公开的个人资料、发布的内容等。这可以提供有关攻击者的兴趣、活动和社交圈的线索。
4、开源情报(OSINT)收集:使用开源情报收集技术,你可以搜索与电话号码相关的在线数据,例如论坛帖子、新闻报道、网站注册等。这些信息可能提供更多关于攻击者的线索,例如其参与的活动、技术兴趣等。
5、其他信息关联:如果你已经拥有攻击者的其他信息,例如用户名、电子邮件地址或IP地址,你可以尝试将这些信息与电话号码关联起来,以获得更全面的画像。通过关联不同的数据点,你可以获得更多关于攻击者身份和背景的信息。
MD5加盐
1、MD5加盐是指在使用MD5哈希算法对密码进行加密时,将一个随机生成的字符串(称为盐)与密码进行组合,然后进行哈希计算。
2、具体步骤如下:
生成盐值:随机生成一个字符串作为盐值。盐值应该是随机且足够复杂,以增加密码哈希的强度。
将盐值与密码组合:将生成的盐值与用户的密码进行拼接。
进行哈希计算:使用MD5哈希算法对盐值与密码的组合进行哈希运算,生成哈希值。
存储盐值与哈希值:将盐值和生成的哈希值一起存储在数据库或其他存储中,以备后续验证用户密码时使用。
3、在验证用户密码时,重复上述步骤,将用户输入的密码与存储的盐值进行拼接,再进行MD5哈希运算。然后,将得到的哈希值与存储的哈希值进行比较。如果两个哈希值相同,则密码验证通过。
4、MD5加盐的目的是增加密码哈希的复杂性和安全性。通过引入随机盐值,即使相同的密码在不同用户之间相同,它们的哈希结果也会因为不同的盐而不同。这增加了破解密码的难度,即使攻击者拥有预先计算的彩虹表,也需要为每个可能的盐值进行计算和存储。
5、需要注意的是,MD5算法本身存在一些弱点,并且不再被推荐用于密码存储。更强大的哈希算法,如SHA-256或bcrypt,更常见地用于密码存储和哈希操作。此外,每个用户应具有唯一的随机盐值,以增加密码哈希的强度。
oracle、mongodb、mssql和mysql注入的区别
Oracle、MongoDB、Microsoft SQL Server (MSSQL) 和 MySQL 是不同类型的数据库管理系统(DBMS),它们在处理 SQL 注入漏洞方面有一些区别。以下是它们之间的一些常见区别:
1、语法差异:不同的数据库系统具有不同的 SQL 语法和查询语句结构。这意味着在进行 SQL 注入时,注入攻击的语法和方法可能会有所不同。攻击者需要根据目标数据库的语法规则和特性来调整注入攻击的语句。
2、数据库对象和函数:每个数据库系统都有自己独特的数据库对象和函数。在注入攻击中,攻击者可能会尝试利用数据库特定的函数或对象来执行恶意操作。攻击者需要了解目标数据库的对象和函数,并根据其特性来构造恶意注入语句。
3、字符串处理:不同的数据库系统对字符串的处理方式也有所不同。例如,一些数据库在字符串比较时区分大小写,而其他数据库则不区分。这可能会影响攻击者构造的恶意注入语句中字符串值的格式和比较方式。
4、防护措施和安全特性:不同的数据库系统提供了不同的防护措施和安全特性来减轻 SQL 注入风险。例如,一些数据库系统提供预编译语句或参数化查询,以减少注入攻击的风险。在进行 SQL 注入时,攻击者可能需要绕过特定数据库的安全特性和防护措施。
5、数据库权限和访问控制:不同的数据库系统具有不同的权限模型和访问控制机制。攻击者可能需要考虑目标数据库的权限设置,并尝试获取足够的权限来执行恶意操作或绕过访问限制。
需要注意的是,无论目标数据库是哪个,SQL 注入漏洞都是一种严重的安全风险。无论使用哪种数据库系统,都应该采取适当的防御措施,如参数化查询、输入验证、最小特权原则等,以减少 SQL 注入攻击的风险。此外,及时应用安全补丁和保持数据库系统的最新版本也是重要的安全实践。