目录
1. Rollup 物化索引作用
1.1 改变索引
1.2 聚合数据
2. Rollup物化索引注意点
进入正文之前,欢迎订阅专题、对博文点赞、评论、收藏,关注IT贫道,获取高质量博客内容!
宝子们点赞、收藏不迷路!抓紧订阅专题!
1. Rollup 物化索引作用
在Doris里Rollup 作为一份聚合物化视图,其在查询中可以起到两个作用:改变索引和聚合数据。
1.1 改变索引
改变索引主要说的是可以调整前缀索引,因为建表时已经指定了列顺序,所以一个表只有一种前缀索引。这对于使用其他不能命中前缀索引的列作为条件进行的查询来说,效率上可能无法满足需求。因此,我们可以通过创建 ROLLUP 来人为的调整列顺序,以获得更好的查询效率。
Doris 的前缀索引,即 Doris 会把 Base/Rollup 表中的前 36 个字节(有 varchar 类型则可能导致前缀索引不满 36 个字节,varchar 会截断前缀索引,并且最多使用 varchar 的 20 个字节)在底层存储引擎单独生成一份排序的稀疏索引数据(数据也是排序的,用索引定位,然后在数据中做二分查找),然后在查询的时候会根据查询中的条件来匹配每个 Base/Rollup 的前缀索引,并且选择出匹配前缀索引最长的一个 Base/Rollup。

如上图,取查询中 where 以及 on 上下推到 ScanNode 的条件,从前缀索引的第一列开始匹配,检查条件中是否有这些列,有则累计匹配的长度,直到匹配不上或者36字节结束(varchar类型的列只能匹配20个字节,并且会匹配不足36个字节截断前缀索引),然后选择出匹配长度最长的一个 Base/Rollup,下面举例说明,创建了一张Base表以及四张rollup:
创建表 rollup_test1 ,表结构如下:
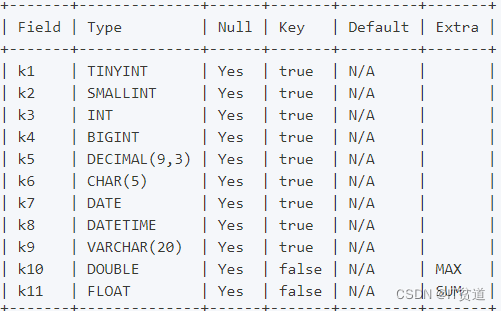
创建表SQL语句如下:
CREATE TABLE IF NOT EXISTS example_db.rollup_test1
(
`k1` TINYINT,
`k2` SMALLINT,
`k3` INT,
`k4` BIGINT,
`k5` DECIMAL(9,3),
`k6` CHAR(5),
`k7` DATE,
`k8` DATETIME,
`k9` VARCHAR(20),
`k10` DOUBLE MAX,
`k11` FLOAT SUM
)
AGGREGATE KEY(`k1`,`k2`,`k3`,`k4`,`k5`,`k6`,`k7`,`k8`,`k9`)
DISTRIBUTED BY HASH(`k1`) BUCKETS 1
PROPERTIES (
"replication_allocation" = "tag.location.default: 1"
);向以上表中插入如下数据(注意:不插入数据,后续创建的物化索引不能被命中):
insert into example_db.rollup_test1 values
(1,2,3,4,1.0,'a',"2023-03-01","2023-03-01 08:00:00","aaa",1.0,1.0),
(5,6,7,8,2.0,'b',"2023-03-02","2023-03-02 08:00:00","bbb",2.0,2.0);基于rollup_test1表创建四张rollup物化索引表,如下:
#创建 rollup_index1
mysql> ALTER TABLE example_db.rollup_test1 ADD ROLLUP rollup_index1(k9,k1,k2,k3,k4,k5,k6,k7,k8,k10,k11);
Query OK, 0 rows affected (0.05 sec)
#创建rollup_index2
mysql> ALTER TABLE example_db.rollup_test1 ADD ROLLUP rollup_index2(k9,k2,k1,k3,k4,k5,k6,k7,k8,k10,k11);
Query OK, 0 rows affected (0.02 sec)
#创建rollup_index3
mysql> ALTER TABLE example_db.rollup_test1 ADD ROLLUP rollup_index3(k4,k5,k6,k1,k2,k3,k7,k8,k9,k10,k11);
Query OK, 0 rows affected (0.03 sec)
#创建rollup_index4
mysql> ALTER TABLE example_db.rollup_test1 ADD ROLLUP rollup_index4(k4,k6,k5,k1,k2,k3,k7,k8,k9,k10,k11);
Query OK, 0 rows affected (0.02 sec)desc table all; 查看表rollup_test1 表物化索引信息:
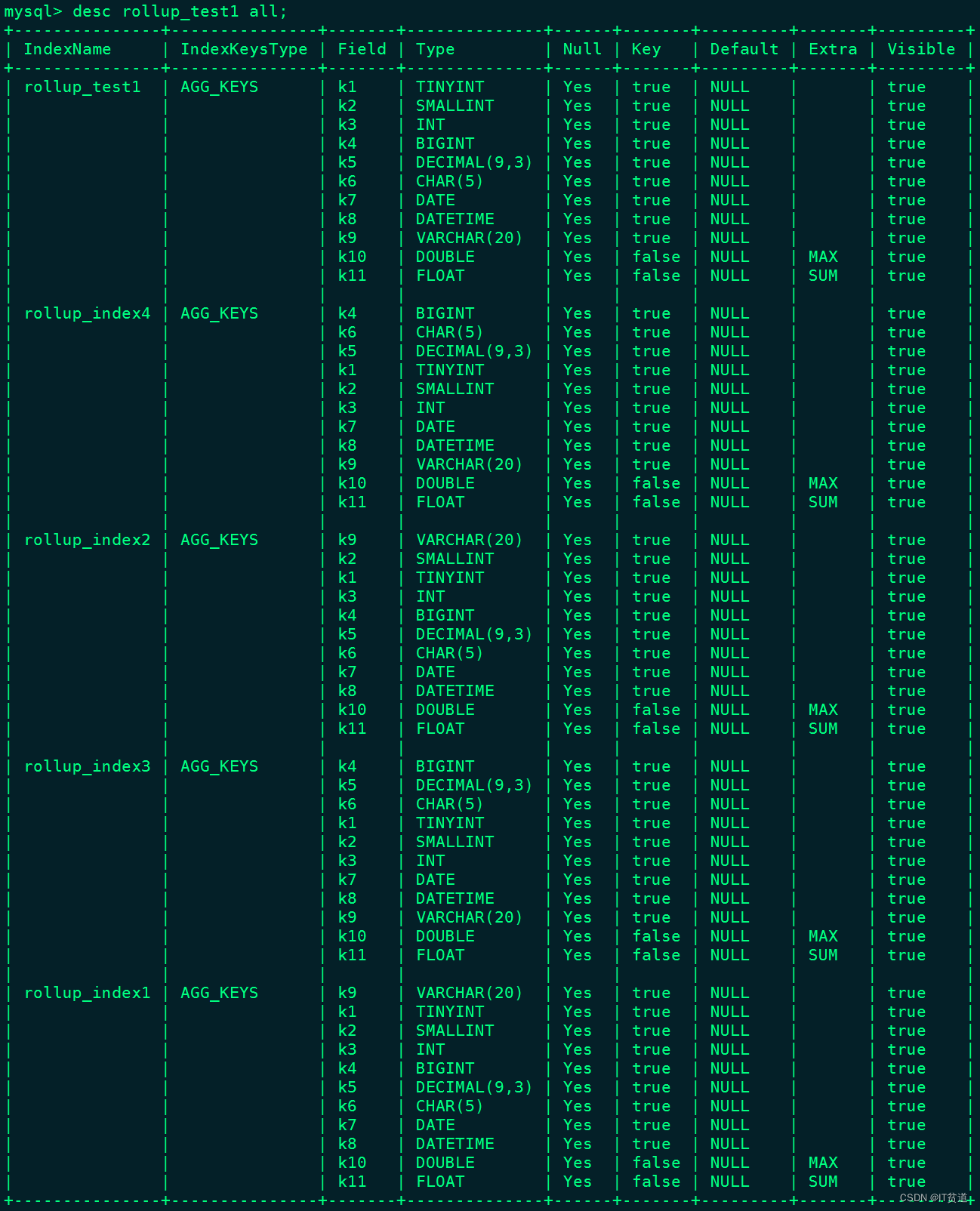
Doris中默认将一行数据的前36个字节作为这行数据的前缀索引,但是当遇到VARCHAR类型时,前缀索引会直接截断,以上Base表和rollup物化索引表的前缀索引分别为(TINYINT-1字节、SMALLINT-2字节、INT-4字节、BIGINT-8字节、DECIMAL-16字节、CHAR-1字节、DATETIME-8字节):
rollup_test1(Base表)(k1 ,k2, k3, k4, k5, k6, k7)
rollup_index1(k9)
rollup_index2(k9)
rollup_index3(k4, k5, k6, k1, k2, k3, k7)
rollup_index4(k4, k6, k5, k1, k2, k3, k7)
能用的上前缀索引的列上的条件需要是 = < > <= >= in between 这些,并且这些条件是并列的且关系使用 and 连接,对于or、!= 等这些不能命中,命中规则是匹配最长的前缀索引。
执行以下查询,查看对应的前缀索引命中情况:
# select * from rollup_test1 where k1 =1 AND k2>3;此语句有k1以及k2上的条件,只有rollup_test1第一列含有条件里的k1,所以匹配最长的前缀索引即rollup_test1,验证如下:
mysql> explain select * from rollup_test1 where k1 =1 AND k2>3;
...
TABLE: default_cluster:example_db.rollup_test1(rollup_test1)
...
# SELECT * FROM rollup_test1 WHERE k4 = 1 AND k5 > 3;此语句有k4以及k5的条件,匹配前缀最长索引,可以匹配到rollup_index3,验证如下:
mysql> explain SELECT * FROM rollup_test1 WHERE k4 = 1 AND k5 > 3;
...
TABLE: default_cluster:example_db.rollup_test1(rollup_index3)
...下面我们尝试匹配含有varchar列上的条件,执行如下SQL:
mysql> explain select * from rollup_test1 where k9 in ("xxx","yyy") and k1=10;
...
TABLE: default_cluster:example_db.rollup_test1(rollup_index1)
...有 k9 以及 k1 两个条件,rollup_index1 以及 rollup_index2 的第一列都含有 k9,按理说这里选择这两个 rollup 都可以命中前缀索引并且效果是一样的随机选择一个即可(因为这里 varchar 刚好20个字节,前缀索引不足36个字节被截断),但是当前策略这里还会继续匹配 k1,因为 rollup_index1 的第二列为 k1,所以选择了 rollup_index1,其实后面的 k1 条件并不会起到加速的作用。(如果对于前缀索引外的条件需要其可以起到加速查询的目的,可以通过建立 Bloom Filter 过滤器加速。一般对于字符串类型建立即可,因为 Doris 针对列存在 Block 级别对于整型、日期已经有 Min/Max 索引)。
最后,看一个多张Rollup都可以命中的查询:
mysql> explain SELECT * FROM rollup_test1 WHERE k4 < 1000 AND k5 = 80 AND k6 >= 10000;
...
TABLE: default_cluster:example_db.rollup_test1(rollup_index3)
...有 k4,k5,k6 三个条件,rollup_index3 以及 rollup_index4 的前3列分别含有这三列,所以两者匹配的前缀索引长度一致,选取两者都可以,当前默认的策略为选取了比较早创建的一张 rollup,这里为 rollup_index3。
修改以上查询,加入OR条件(不走任何索引),则这里的查询不能命中前缀索引。
mysql> explain SELECT * FROM rollup_test1 WHERE k4 < 1000 AND k5 = 80 OR k6 >= 10000;
...
TABLE: default_cluster:example_db.rollup_test1(rollup_test1)
...1.2 聚合数据
聚合数据仅用于聚合模型,即aggregate 和Unique(读时合并,Unique只是Aggregate模型的一个特例),在Duplicate模型中,由于Duplicate模型没有聚合的语境,所以该模型中的 ROLLUP,已经失去了“上卷”这一层含义,而仅仅是作为调整列顺序,以命中前缀索引的作用。
当然一般的聚合物化视图其聚合数据的功能是必不可少的,这类物化视图对于聚合类查询或报表类查询都有非常大的帮助,要命中聚合物化视图需要下面一些前提:
- 查询或者子查询中涉及的所有列都存在一张独立的 Rollup 中。
- 如果查询或者子查询中有 Join,则 Join 的类型需要是 Inner join。
以下是可以命中Rollup的一些聚合查询的种类:
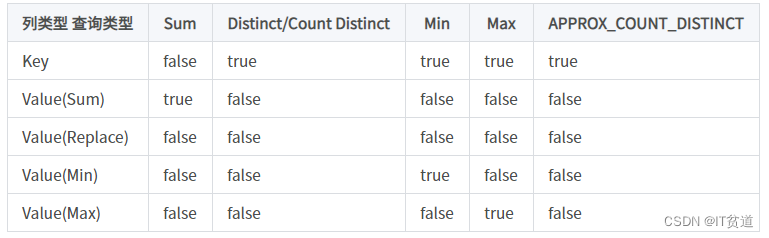
注意:APPROX_COUNT_DISTINCT 类似Count Distinct ,速度快,返回近似值。
如果符合上述条件,则针对聚合模型在判断命中 Rollup 的时候会有两个阶段:
- 首先通过条件匹配出命中前缀索引索引最长的 Rollup 表。
- 然后比较 Rollup 的行数,选择最小的一张 Rollup,这里不是真正去查询对应rollup表中行数少的,而是找到rollup上卷聚合程度最高的,意味着行数最少。
例如创建Base表rollup_test2以及Rollup:
#创建表 rollup_test2
CREATE TABLE IF NOT EXISTS example_db.rollup_test2
(
`k1` TINYINT,
`k2` SMALLINT,
`k3` INT,
`k4` BIGINT,
`k5` DECIMAL(9,3),
`k6` CHAR(5),
`k7` DATE,
`k8` DATETIME,
`k9` VARCHAR(20),
`k10` DOUBLE MAX,
`k11` FLOAT SUM
)
AGGREGATE KEY(`k1`,`k2`,`k3`,`k4`,`k5`,`k6`,`k7`,`k8`,`k9`)
DISTRIBUTED BY HASH(`k1`) BUCKETS 1
PROPERTIES (
"replication_allocation" = "tag.location.default: 1"
);
#给表rollup_test2 添加Rollup物化索引表,名称为rollup1
mysql> ALTER TABLE example_db.rollup_test2 ADD ROLLUP rollup1(k1,k2,k3,k4,k5,k10,k11);
Query OK, 0 rows affected (0.01 sec)
#给表rollup_test2 添加Rollup物化索引表,名称为rollup2
mysql> ALTER TABLE example_db.rollup_test2 ADD ROLLUP rollup2(k1,k2,k3,k10,k11);
Query OK, 0 rows affected (0.02 sec)
#向表rollup_test2 中插入如下数据
insert into example_db.rollup_test2 values
(1,2,3,4,1.0,'a',"2023-03-01","2023-03-01 08:00:00","aaa",1.0,1.0),
(5,6,7,8,2.0,'b',"2023-03-02","2023-03-02 08:00:00","bbb",2.0,2.0);
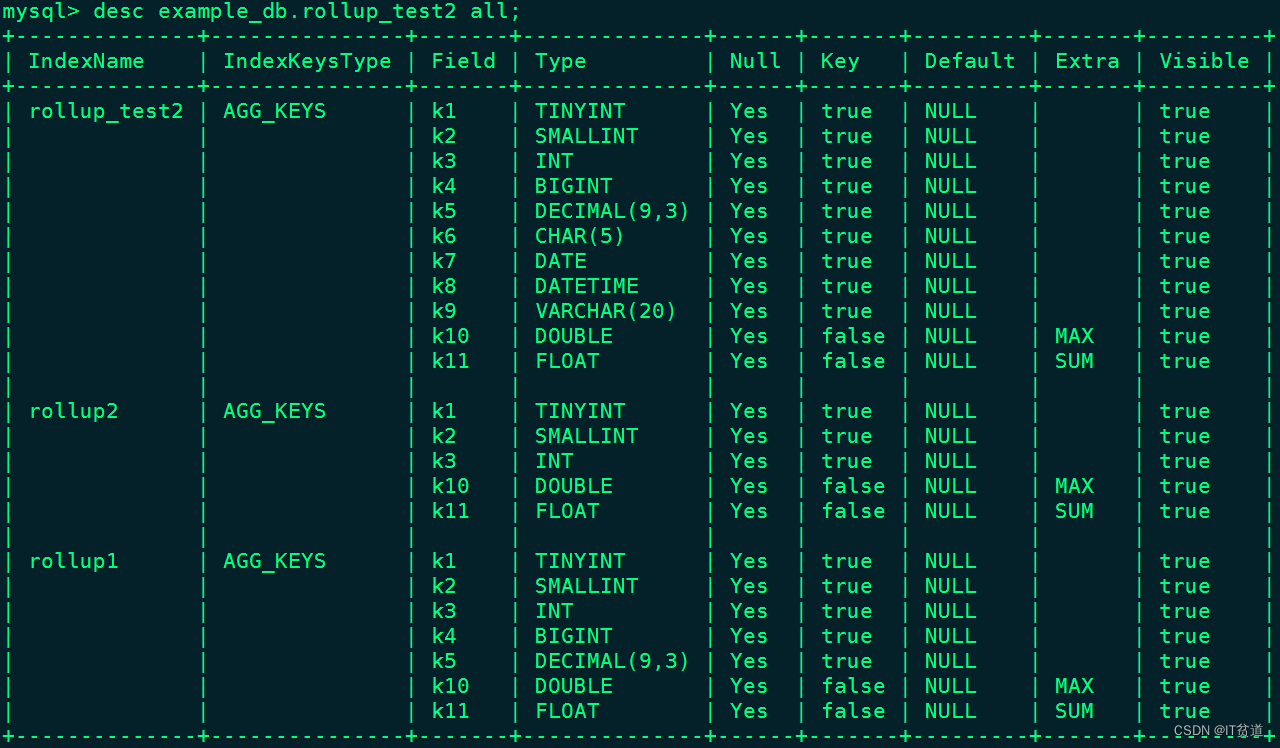
#创建完成后,查看表中的物化索引信息
mysql> desc example_db.rollup_test2 all;物化索引信息结果如下:
查看如下查询命中rollup情况:
mysql> explain SELECT SUM(k11) FROM rollup_test2 WHERE k1 = 10 AND k2 > 200 AND k3 in (1,2,3);
...
TABLE: default_cluster:example_db.rollup_test2(rollup2)
...以上命中rollup判断流程如下:首先判断查询是否可以命中聚合的 Rollup表,经过查上面的图是可以的,然后条件中含有 k1,k2,k3 三个条件,这三个条件 rollup_test2、rollup1、rollup2 的前三列都含有,所以前缀索引长度一致,然后比较行数显然 rollup2 的聚合程度最高行数最少所以选取 rollup2。
2. Rollup物化索引注意点
- ROLLUP最根本的作用是提高某些查询的查询效率(无论是通过聚合来减少数据量,还是修改列顺序以匹配前缀索引)。因此ROLLUP的含义已经超出了“上卷”的范围。这也是为什么我们在源代码中,将其命名为 Materialized Index(物化索引)的原因。
- ROLLUP是附属于Base表的,可以看做是Base表的一种辅助数据结构。用户可以在Base表的基础上,创建或删除ROLLUP,但是不能在查询中显式的指定查询某 ROLLUP。是否命中ROLLUP完全由Doris系统自动决定。
- ROLLUP的数据是独立物理存储的。因此,创建的ROLLUP越多,占用的磁盘空间也就越大。同时对导入速度也会有影响(导入的ETL阶段会自动产生所有 ROLLUP 的数据),但是不会降低查询效率(只会更好)。
- ROLLUP的数据更新与Base表是完全同步的。用户无需关心这个问题。
- ROLLUP中列的聚合方式,与Base表完全相同。在创建ROLLUP无需指定,也不能修改。
- 查询能否命中ROLLUP的一个必要条件(非充分条件)是,查询所涉及的所有列(包括 select list 和 where 中的查询条件列等)都存在于该ROLLUP的列中。否则,查询只能命中Base表。
- 某些类型的查询(如count(*))在任何条件下,都无法命中ROLLUP。
- 可以通过 EXPLAIN your_sql; 命令获得查询执行计划,在执行计划中,查看是否命中 ROLLUP。
可以通过DESC tbl_name ALL; 语句显示Base表和所有已创建完成的ROLLUP。