paper:An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
摘要
- 把transformer直接应用于图像块序列,也可以在图像分类任务上表现很好。
- 通过在大数据集上预训练,然后迁移到中等规模和小规模数据集上,ViT可以取得和SOTA的卷积网络同样出色(甚至更好)的结果,同时需要更少的训练资源。
介绍
1、将标准transformer直接应用于图像,只做最小可能修改
将一幅图像分割成多个图像块,然后将这些图像块的embedding序列作为输入,送到transformer。这里的图像块类似于NLP中的token。
2、在中等规模数据集(如ImageNet)上训练ViT,模型结果会比resnet结构的模型低一点。
和CNN相比,transformer缺乏一些归纳偏置(inductive bias),比如平移不变性和局部性。但是在大规模数据集上,直接从数据中学习,更加有效。
方法
网络结构
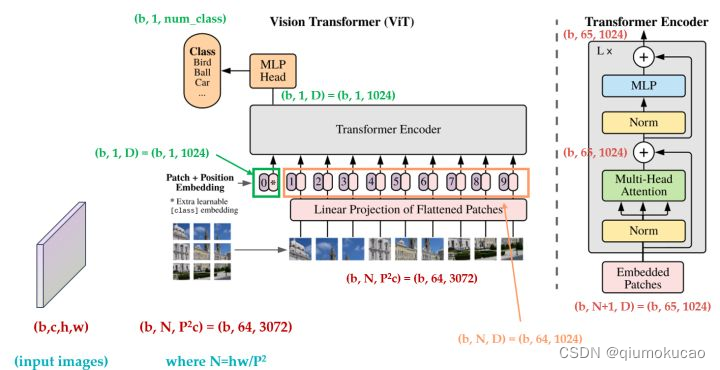
图片来源:https://zhuanlan.zhihu.com/p/342261872
输入图像维度为$$H×W×C$$,分割成N个$$P×P$$大小的图像块,N为$$HW/P^2$$,图像块通过线性映射得到D维的向量,D在transformer的所有层中保持不变。
不同层的操作计算过程如下:

公式1是将图像块映射成embedding,这里加了一个可学习的class token $$x_{class}$$(类似BERT),与其他图像块嵌入向量一起输入到 Transformer 编码器中,其在网络最后的输出,作为整个图像的表示y,就是公式4中的结果。Transformer 编码器中的具体过程这里不作展开,可参考https://tech.xiaomi.com/#/pc/article-detail?id=16932。
公式2是multiheaded self-attention的计算过程,公式3是MLP的计算过程。
实际实现过程中,图像块映射成embedding可以通过卷积实现:
# 其中fh,fw是patch的高和宽,让卷积核的大小和stride与patch大小相等
self.patch_embedding = nn.Conv2d(in_channels, dim, kernel_size=(fh, fw), stride=(fh, fw))另外,网络最后接MLP head的时候,可以只使用class token对应的结果(如公式4中描述),也可以对所有结果进行pooling,然后接MLP head。参考https://github.com/lucidrains/vit-pytorch.git中实现:
def forward(self, img):
x = self.to_patch_embedding(img) #图像转成embedding
b, n, _ = x.shape
cls_tokens = repeat(self.cls_token, '1 1 d -> b 1 d', b = b)
x = torch.cat((cls_tokens, x), dim=1) #引入cls_tokens
x += self.pos_embedding[:, :(n + 1)] #加入位置embedding
x = self.dropout(x)
x = self.transformer(x)
# 根据设置选择cls_tokens对应的输出或者进行pooling
x = x.mean(dim = 1) if self.pool == 'mean' else x[:, 0]
x = self.to_latent(x)
return self.mlp_head(x)Hybrid Architecture
可以将ViT应用于CNN的特征之上,区别就是这里把CNN的特征映射为embedding,其余部分跟ViT的处理过程一样
模型微调(fine-tune)
在大规模数据集上进行预训练,然后在下游任务中进行微调。微调时,把预训练的预测头去掉,添加一个$$D×K$$的全连接层,K为预测类别数。
微调时可以采用更大的输入分辨率,保持patch size不变,这样输入到transformer的序列长度会变长,事实上ViT可以处理任意长的序列,不过预训练的position embedding就失去意义了,这时作者对position embedding进行了2D插值处理。
实验结果
数据集
ImageNet:1.3M images,1k classes
ImageNet-21k:14M images,21k classes
JFT:303M high-resolution images,18k classes
模型参数

Layers:Encoder Block 数量
Hidden Size D:隐藏层特征大小,其在各 Encoder Block 保持一致
MLP Size:MLP 特征大小,通常设为 4D
Heads:MSA 中的 heads 数量
Patch Size:模型输入的 Patch size,ViT 中共有两个设置:14x14 和 16x16,该参数仅影响计算量,patch size越小,序列长度越长,计算量越大。
实验结果
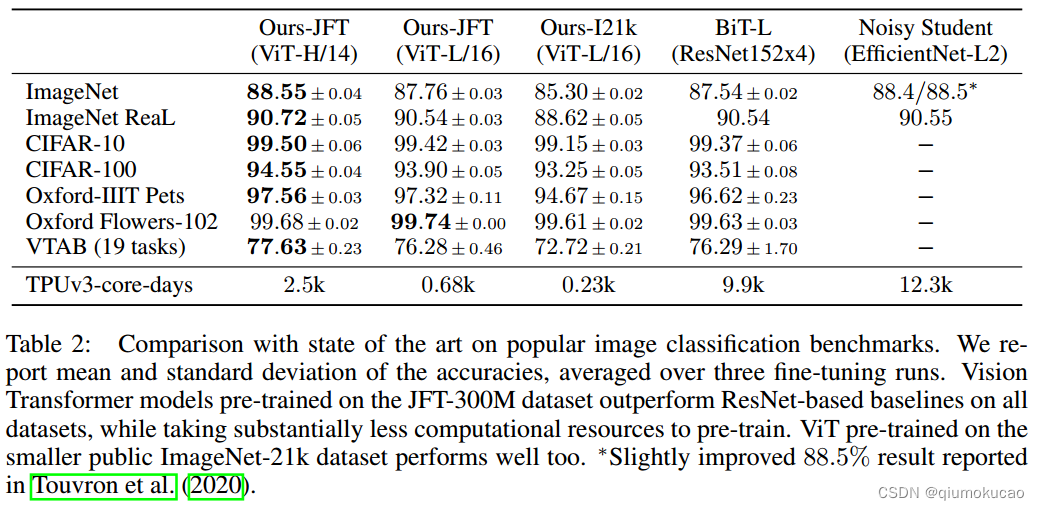
JFT+TPU的钞能力!