1. 定义
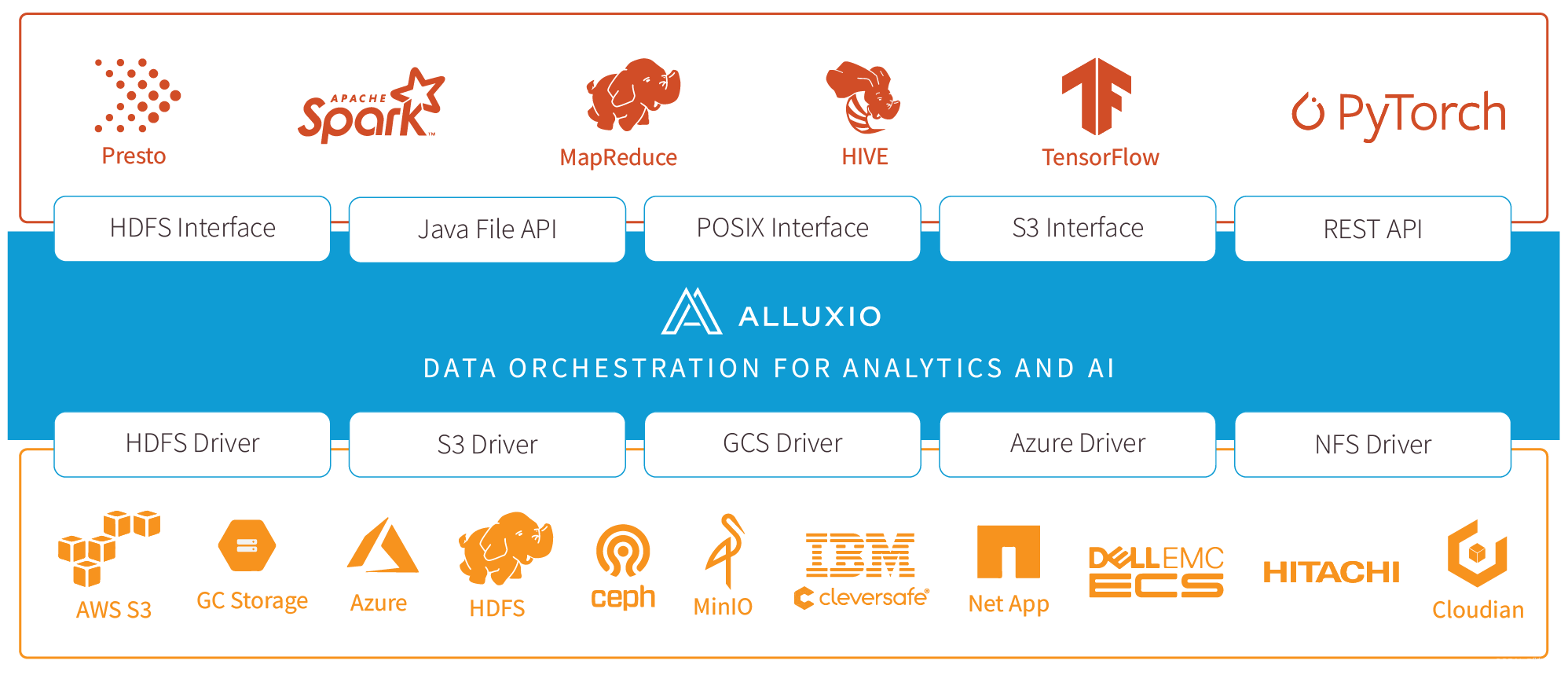
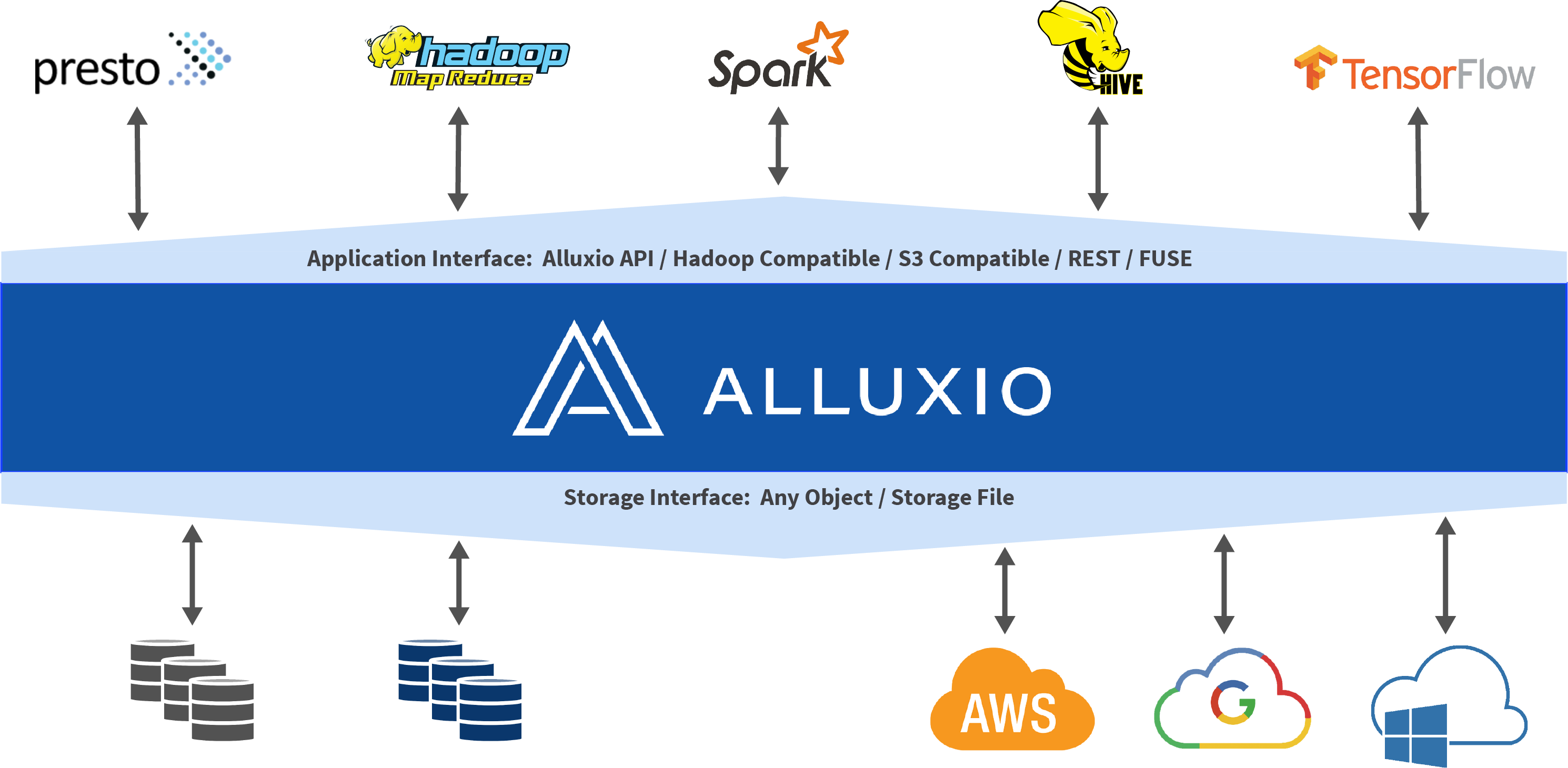
Alluxio(之前名为 Tachyon)是世界上第一个以内存为中心的虚拟的分布式存储系统。 它统一了数据访问的方式,为上层计算框架和底层存储系统构建了桥梁。应用只需要连接Alluxio即可访问存储在底层任意存储系统中的数据。此外,Alluxio的以内存为中心的架构使得数据的访问速度能比现有常规方案快几个数量级。
在大数据生态系统中,Alluxio 介于计算框架(如 Apache Spark,Apache MapReduce,Apache Flink)和现有的存储系统(如 Amazon S3,OpenStack Swift,GlusterFS,HDFS, Ceph,OSS)之间。Alluxio 为大数据软件栈带来了显著的性能提升。 用户可以以独立集群方式(如Amazon EC2)运行Alluxio,也可以从Apache Mesos或Apache YARN上启动Alluxio。
 2.优势
2.优势
- 内存速度 I/O:Alluxio 能够用作分布式共享缓存服务,这样与 Alluxio 通信的计算应用程序可以透明地缓存频繁访问的数据(尤其是从远程位置),以提供内存级 I/O 吞吐率。此外,Alluxio的层次化存储机制能够充分利用内存、固态硬盘或者磁盘,降低具有弹性扩张特性的数据驱动型应用的成本开销。
- 简化云存储和对象存储接入:与传统文件系统相比,云存储系统和对象存储系统使用不同的语义,这些语义对性能的影响也不同于传统文件系统。在云存储和对象存储系统上进行常见的文件系统操作(如列出目录和重命名)通常会导致显著的性能开销。当访问云存储中的数据时,应用程序没有节点级数据本地性或跨应用程序缓存。将 Alluxio 与云存储或对象存储一起部署可以缓解这些问题,因为这样将从 Alluxio 中检索读取数据,而不是从底层云存储或对象存储中检索读取。
- 简化数据管理:Alluxio 提供对多数据源的单点访问。除了连接不同类型的数据源之外,Alluxio 还允许用户同时连接同一存储系统的不同版本,如多个版本的 HDFS,并且无需复杂的系统配置和管理。
- 应用程序部署简易:Alluxio 管理应用程序和文件或对象存储之间的通信,将应用程序的数据访问请求转换为底层存储接口的请求。Alluxio 与 Hadoop 生态系统兼容,现有的数据分析应用程序,如 Spark 和 MapReduce 程序,无需更改任何代码就能在 Alluxio 上运行。
- 统一数据访问接口:Alluxio 能够屏蔽底层持久化存储系统在API、客户端及版本方面的差异,从而使整个系统易于扩展和管理。(能够将多个数据源中的数据挂载到Alluxio中;多个数据源使用统一的命名空间;用户使用统一的路径访问)
- 提升远程存储读写性能:以Hadoop为代表的存储计算紧耦合的传统架构具有优良的计算本地性。通过在邻近所需数据的节点上来部署运行计算任务,可以尽量减少通过网络传输数据,从而有效地提升性能。然而,维持这种紧耦合结构所需要付出的成本代价正逐渐让性能优势带来的意义变得微乎其微。Alluxio通过在当前主流的存储计算分离解耦的架构中,提供与紧耦合架构相似甚至更优的性能,来解决解耦后性能降低的难题。推荐把Alluxio与集群的计算框架并置部署(co-locate),从而能够提供靠近计算的跨存储缓存来实现高效本地性。
与传统的架构方案相比,Alluxio架构带来两个关键区别
(1)Alluxio存储中不需要保存底层存储中的所有数据,它只需要保存工作集(WorkingSet)。即使全体数据的规模非常大,Alluxio也不需要大量存储空间来存储所有数据,而是可以在有限的存储空间中只缓存作业所需要的数据。
(2)Alluxio存储采用了一种弹性的缓存机制来管理、使用存储资源。访问热度越高的数据(如被很多作业读取的数据表),会产生越多的副本,而请求很少甚至没有复用的数据则会被逐渐替换出Alluxio存储层(其在远端存储系统中的副本不会被清除)。而以HDFS为代表的存储系统通常是采用一个固定的副本数目(如3副本),很难根据具体的数据访问热度动态调节存储资源的使用。
- 数据快速复用与共性:Alluxio可以帮助实现跨计算、作业间的数据快速复用和共享。对于用户应用程序和大数据计算框架来说,Alluxio存储通常与计算框架并置。这种部署方式使Alluxio可以提供快速存储,促进作业之间的数据共享,无论它们是否在同一计算平台上运行。
与本地操作系统协议栈下不同层面模块的比较
3.架构
3.1 架构总览
Alluxio作为大数据和机器学习生态系统中的新增数据访问层,可位于任何持久化存储系统(如Amazon S3、Microsoft Azure 对象存储、Apache HDFS或OpenStack Swift)和计算框架(如Apache Spark、Presto或Hadoop MapReduce)之间,但是Alluxio本身并非持久化存储系统。使用Alluxio作为数据访问层可带来诸多优势:
- 对于用户应用和计算框架而言,Alluxio提供的快速存储可以让任务(无论是否在同一计算引擎上运行)进行数据共享,并且在同时将数据缓存在本地计算集群。因此,当数据在本地时,Alluxio可以提供内存级别的数据访问速度;当数据在Alluxio中时,Alluxio将提供计算集群网络带宽级别的数据访问速度。数据只需在第一次被访问时从底层存储系统中读取一次即可。因此,即使底层存储的访问速度较慢,也可以通过Alluxio显著加速数据访问。为了获得最佳性能,建议将 Alluxio与集群的计算框架部署在一起。
- 就底层存储系统而言,Alluxio将大数据应用和不同的存储系统连接起来,因此扩充了能够利用数据的可用工作负载集。由于Alluxio和底层存储系统的集成对于应用程序是透明的,因此任何底层存储都可以通过Alluxio支持数据访问的应用和框架。此外,当同时挂载多个底层存储系统时,Alluxio可以作为任意数量的不同数据源的统一层。
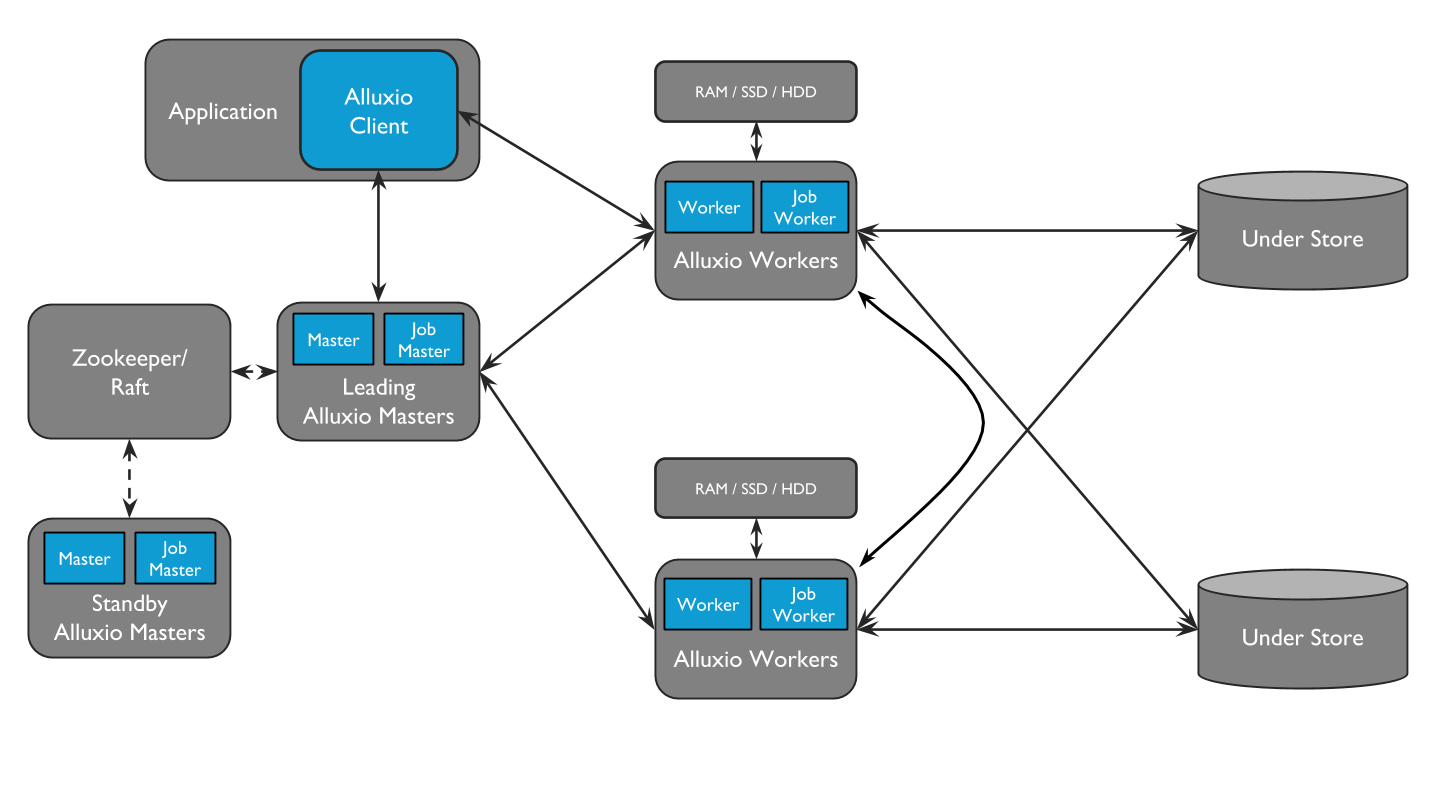
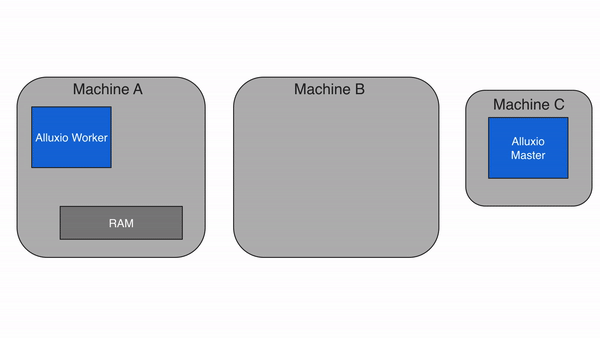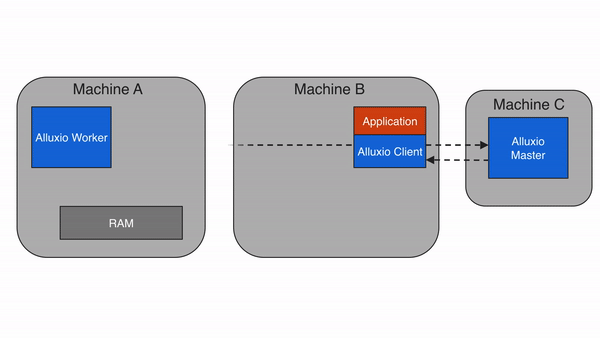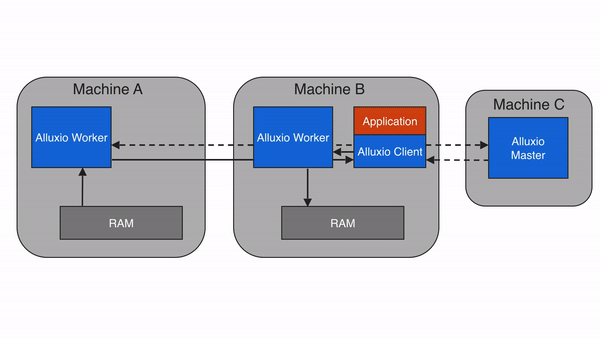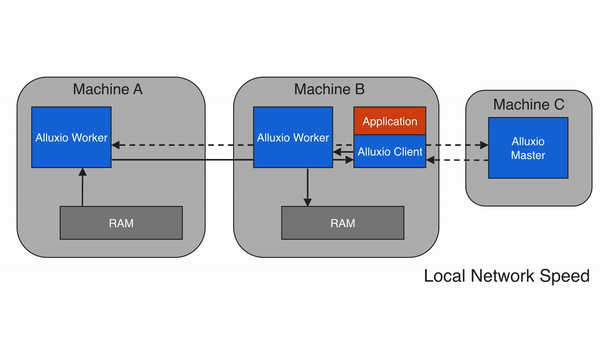
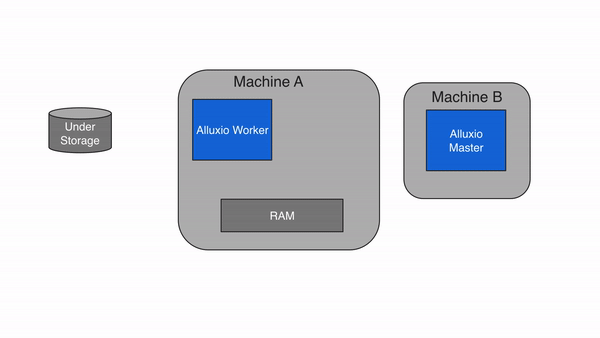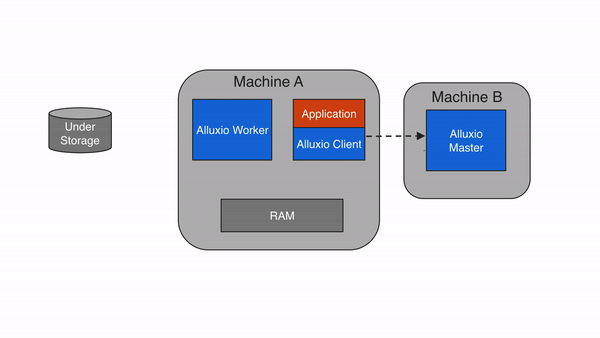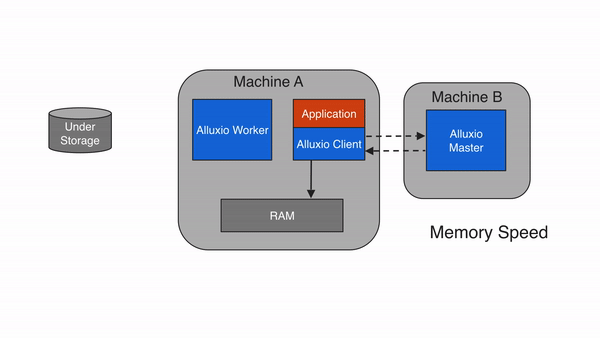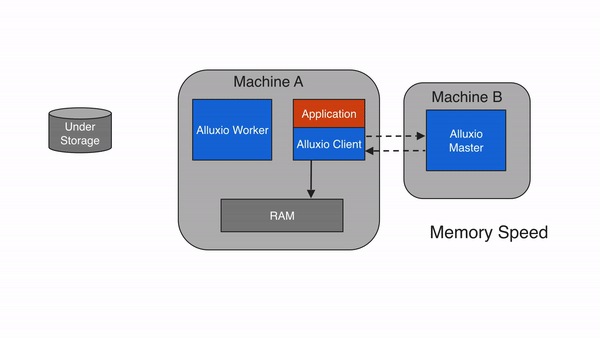
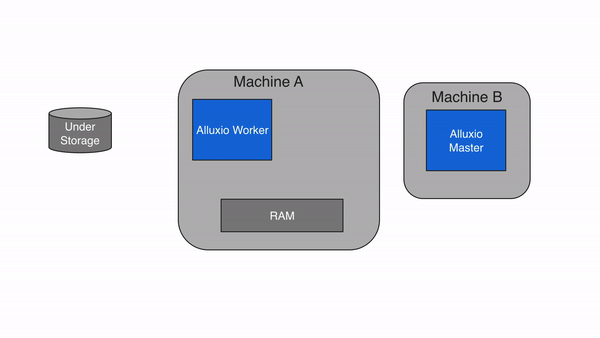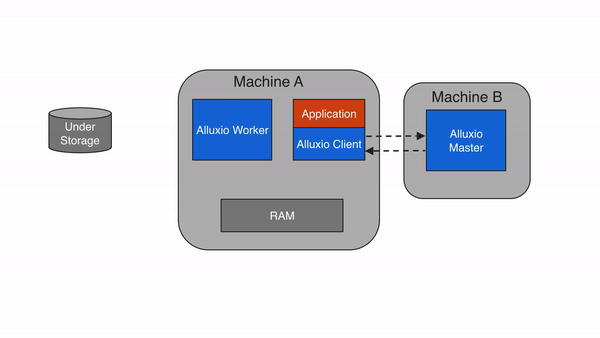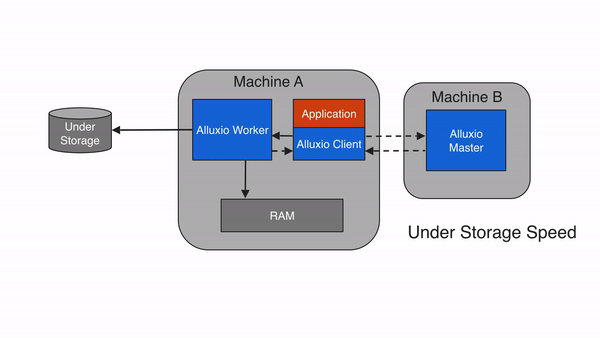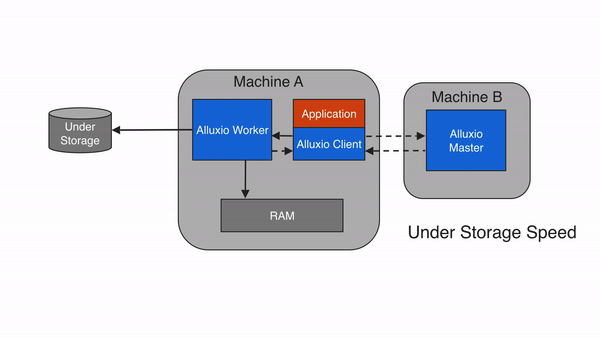
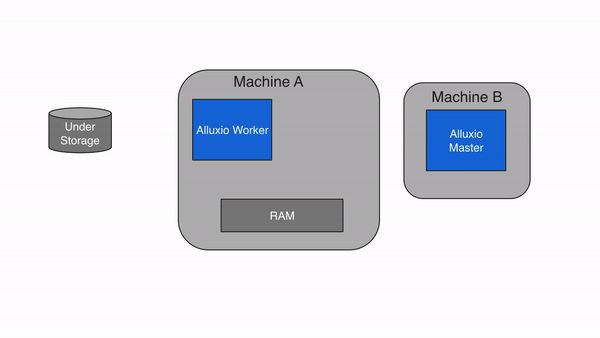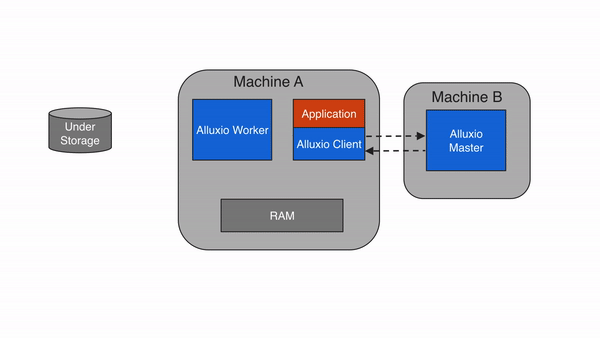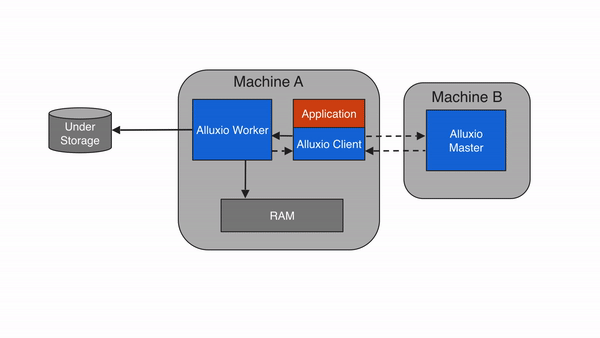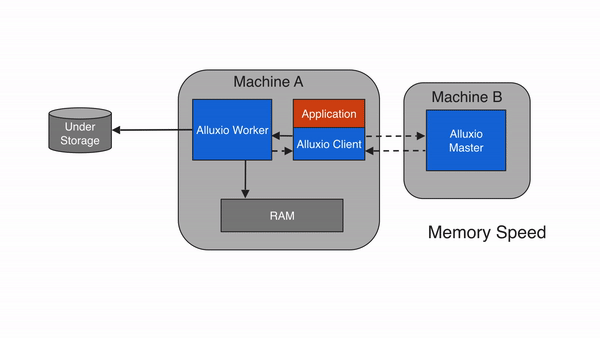
Alluxio包含三种组件:master、worker和client。一个集群通常包含一个leading master,多个standby master,一个primary job master、多个standby job master,多个worker和多个job workers 。master进程和worker进程通常由系统管理员维护和管理,构成了Alluxio server(服务端)。而应用程序(如Spark或MapReduce作业、Alluxio命令行或FUSE层)通过client(客户端)与Alluxio server进行交互。
Alluxio Job Masters和Job Worker可以归为一个单独的功能,称为Job Service。Alluxio Job Service是一个轻量级的任务调度框架,负责将许多不同类型的操作分配给Job Worker。这些任务包括:
- 将数据从UFS(under file system)加载到Alluxio
- 将数据持久化到UFS
- 在Alluxio中复制文件
- 在UFS间或Alluxio节点间移动或拷贝数据
Job service的设计使得所有与Job相关的进程不一定需要与其他Alluxio集群位于同一位置。但是,为了使得RPC和数据传输延迟较低,我们还是建议将job worker与对应的Alluxio worker并置。
3.2 Masters
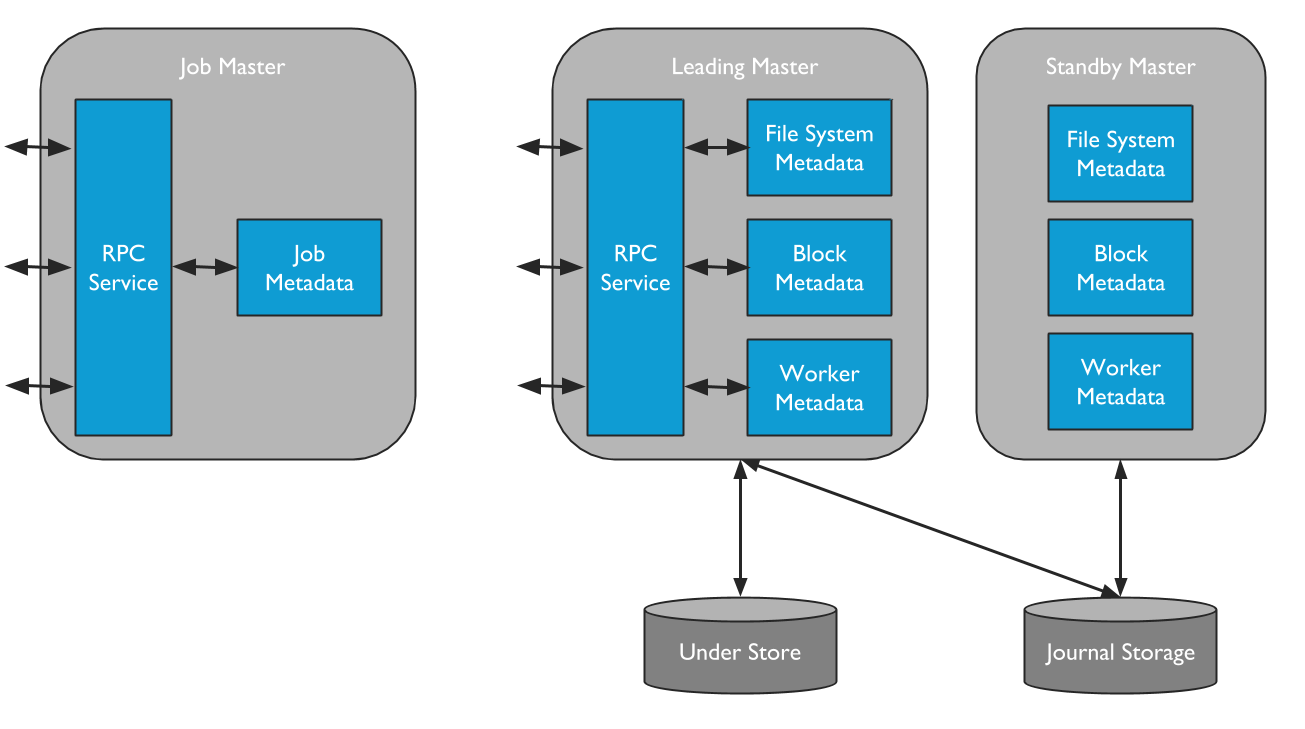
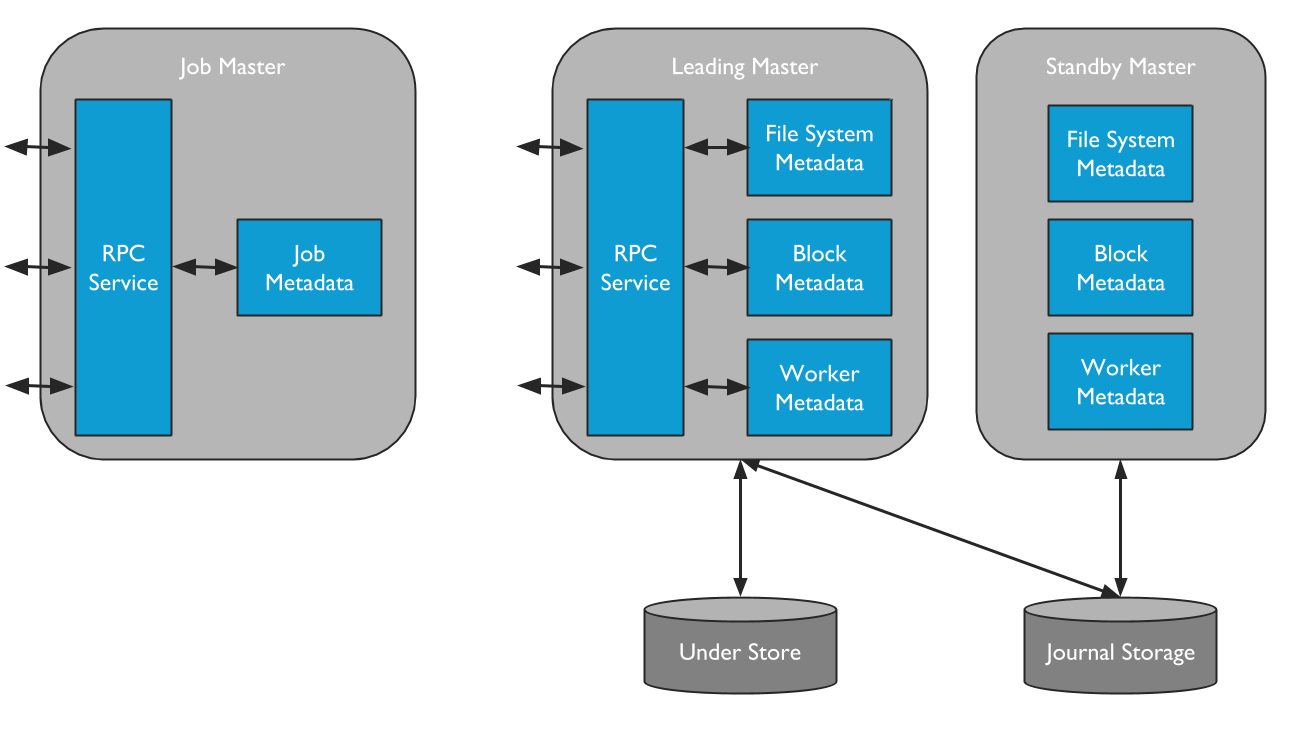
Alluxio包含两种不同类型的master进程。一种是Alluxio Master,Alluxio Master服务所有用户请求并记录文件系统元数据修改情况。另一种是Alluxio Job Master,这是一种用来调度将在Alluxio Job Workers上执行的各种文件系统操作的轻量级调度程序。
为了提供容错能力,可以以一个leading master和多个备用master的方式来部署Alluxio Master。当leading master宕机时,某个standby master会被选举成为新的leading master。
Leading Master
Alluxio集群中只有一个leading master,负责管理整个集群的全局元数据,包括文件系统元数据(如索引节点树)、数据块(block)元数据(如block位置)以及worker容量元数据(空闲和已用空间)。leading master只会查询底层存储中的元数据。应用数据永远不会通过master来路由传输。Alluxio client通过与leading master交互来读取或修改元数据。此外,所有worker都会定期向leading master发送心跳信息,从而维持其在集群中的工作状态。leading master通常不会主动发起与其他组件的通信,只会被动响应通过RPC服务发来的请求。此外,leading master还负责将日志写入分布式持久化存储,保证集群重启后能够恢复master状态信息。这组记录被称为日志(Journal)。
Standby Masters
standby master在不同的服务器上启动,确保在高可用(HA)模式下运行Alluxio时能提供容错。standby master读取leading master的日志,从而保证其master状态副本是最新的。standby master还编写日志检查点, 以便将来能更快地恢复到最新状态。但是,standby master不处理来自其他Alluxio组件的任何请求。当leading master出现故障后,standby master会重新选举新的leading master。
Secondary master(用于UFS 日志)
当使用UFS日志运行非HA模式的单个Alluxio master时,可以在与leading master相同的服务器上启动secondary master来编写日志检查点。请注意,secondary master并非用于提供高可用,而是为了减轻leading master的负载,使其能够快速恢复到最新状态。与standby master不同的是,secondary master永远无法升级为leading master。
Job Masters
Alluxio Job Master是负责在Alluxio中异步调度大量较为重量级文件系统操作的独立进程。通过将执行这些操作的需求从在同一进程中的leading Alluxio Master上独立出去,Leading Alluxio Master会消耗更少的资源,并且能够在更短的时间内服务更多的client。此外,这也为将来增加更复杂的操作提供了可扩展的框架。
Alluxio Job Master接受执行上述操作的请求,并在将要具体执行操作的(作为Alluxio 文件系统client的)Alluxio Job Workers间进行任务调度。
3.3 Workers
Alluxio Workers
Alluxio worker负责管理分配给Alluxio的用户可配置本地资源(RAMDisk、SSD、HDD 等)。Alluxio worker以block为单位存储数据,并通过在其本地资源中读取或创建新的block来服务client读取或写入数据的请求。worker只负责管理block, 从文件到block的实际映射都由master管理。
Worker在底层存储上执行数据操作, 由此带来两大重要的益处:
- 从底层存储读取的数据可以存储在worker中,并可以立即提供给其他client使用。
- client可以是轻量级的,不依赖于底层存储连接器。
由于RAM通常提供的存储容量有限,因此在Alluxio worker空间已满的情况下,需要释放worker中的block。Worker可通过配置释放策略(eviction policies)来决定在Alluxio空间中将保留哪些数据。
Alluxio Job Workers
Alluxio Job Workers是Alluxio文件系统的client, 负责运行Alluxio Job Master分配的任务。Job Worker接收在指定的文件系统位置上运行负载、持久化、复制、移动或拷贝操作的指令。
Alluxio job worker无需与普通worker并置,但建议将两者部署在同一个物理节点上。
3.4 Client
Alluxio client为用户提供了一个可与Alluxio server交互的网关。client发起与leading master节点的通信,来执行元数据操作,并从worker读取和写入存储在Alluxio中的数据。Alluxio支持Java中的原生文件系统API,并支持包括REST、Go和Python在内的多种客户端语言。此外,Alluxio支持与HDFS API以及Amazon S3 API兼容的API。
注意,Alluxio client不直接访问底层存储,而是通过Alluxio worker传输数据。
3.5 数据流:读操作
本节和下一节将介绍在典型配置下的Alluxio在常规读和写场景的行为:Alluxio与计算框架和应用程序并置部署,而底层存储一般是远端存储集群或云存储。
Alluxio位于存储和计算框架之间,可以作为数据读取的缓存层。本小节介绍Alluxio的不同缓存场景及其对性能的影响。
本地缓存命中
当应用程序需要读取的数据已经被缓存在本地Alluxio worker上时,即为本地缓存命中。应用程序通过Alluxio client请求数据访问后,Alluxio client会向 Alluxio master检索储存该数据的Alluxio worker位置。如果本地Alluxio worker存有该数据,Alluxio client将使用”短路读”绕过Alluxio worker,直接通过本地文件系统读取文件。短路读可避免通过TCP socket传输数据,并能提供内存级别的数据访问速度。短路读是从Alluxio读取数据最快的方式。
在默认情况下,短路读需要获得相应的本地文件系统操作权限。当Alluxio worker和client是在容器化的环境中运行时,可能会由于不正确的资源信息统计而无法实现短路读。在基于文件系统的短路读不可行的情况下,Alluxio可以基于domain socket的方式实现短路读,这时,Alluxio worker将通过预先指定的domain socket路径将数据传输到client。此外,除内存外,Alluxio还可以管理其他存储介质(如SSD、HDD),因此本地访问速度可能因本地存储介质而异。
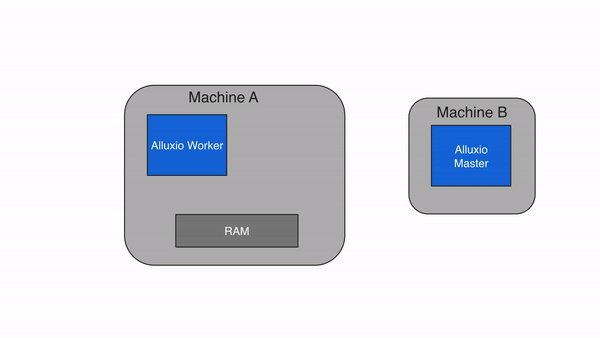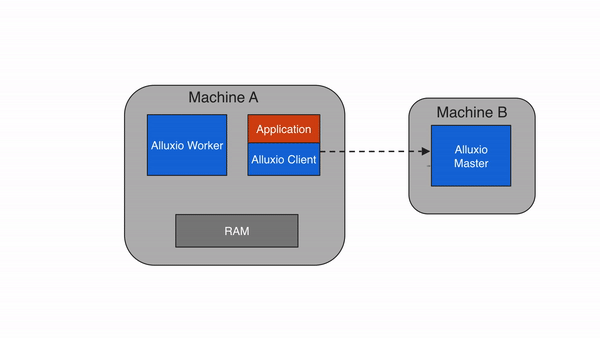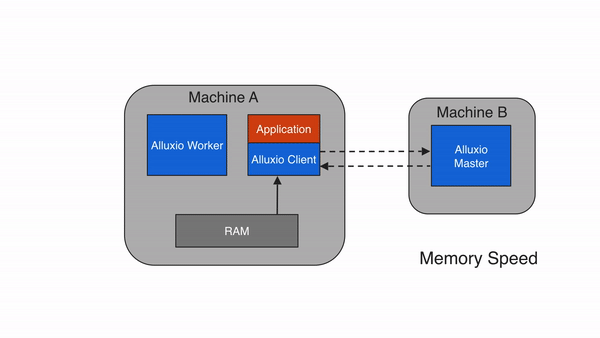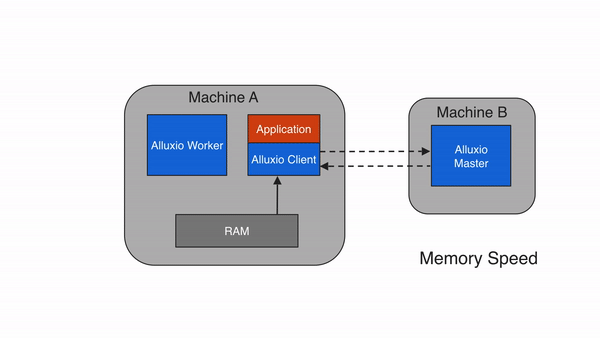
远程缓存命中
当Alluxio client请求的数据不在本地Alluxio worker上,但在集群中的某个远端Alluxio worker上时,Alluxio client将从远端worker读取数据。当client完成数据读取后,会指示本地worker(如果存在的话),在本地写入一个副本,以便将来再有相同数据的访问请求时,可以从本地内存中读取。远程缓存命中情况下的数据读取速度可以达到本地网络传输速度。由于Alluxio worker之间的网络速度通常比Alluxio worker与底层存储之间的速度快,因此Alluxio会优先从远端worker存储中读取数据。
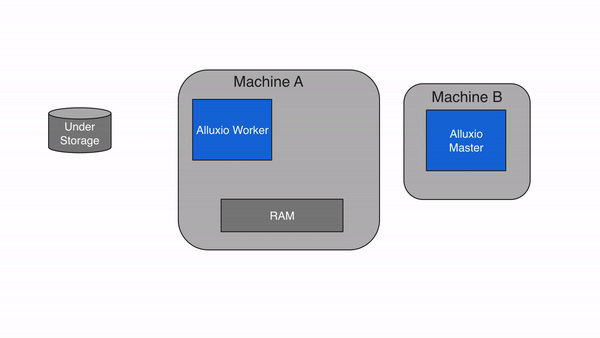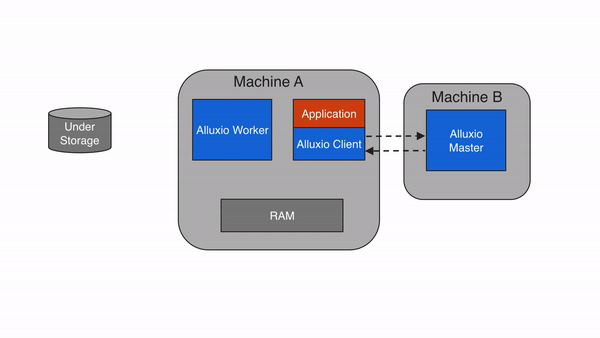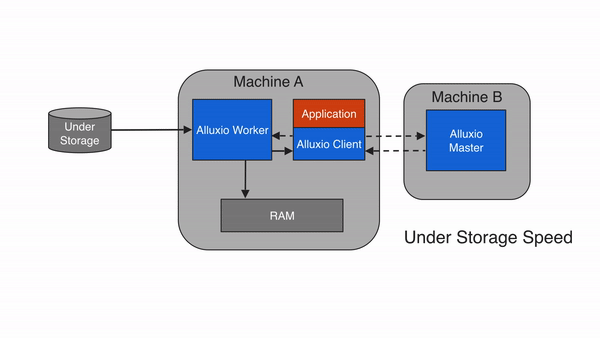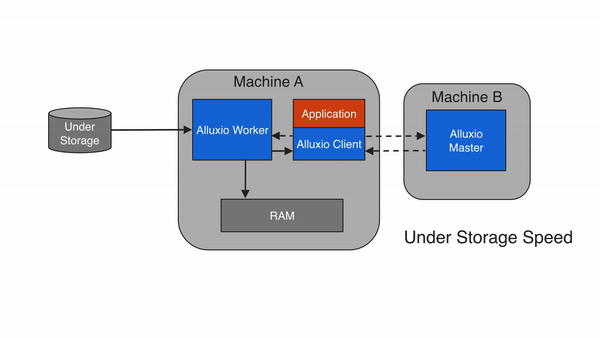
缓存未命中
如果请求的数据不在Alluxio空间中,即发生请求未命中缓存的情况,应用程序将必须从底层存储中读取数据。Alluxio client会将读取请求委托给一个Alluxio worker(优先选择本地worker),从底层存储中读取和缓存数据。缓存未命中时,由于应用程序必须从底层存储系统中读取数据,因此一般会导致较大的延迟。缓存未命中通常发生在第一次读取数据时。
当Alluxio client仅读取block的一部分或者非顺序读取时,Alluxio client将指示Alluxio worker异步缓存整个block。这也称为异步缓存。异步缓存不会阻塞client,但如果Alluxio和存储系统之间的网络带宽成为瓶颈,则仍然可能会影响性能。我们可以通过设置 alluxio.worker.network.async.cache.manager.threads.max来调节异步缓存的影响。默认值为 8。
绕过缓存
用户可以通过将client中的配置项alluxio.user.file.readtype.default设置为NO_CACHE来关闭Alluxio中的缓存功能。
3.6 数据流:写操作
用户可以通过选择不同的写入类型来配置不同的写入方式。用户可以通过Alluxio API或在client中配置alluxio.user.file.writetype.default 来设置写入类型。本节将介绍不同写入类型的行为以及其对应用程序的性能影响。
仅写Alluxio缓存(MUST_CACHE)
如果使用写入类型MUST_CACHE,Alluxio client仅将数据写入本地Alluxio worker,不会将数据写入底层存储系统。在写入期间,如果”短路写”可用,Alluxio client将直接将数据写入本地RAM盘上的文件中,绕过Alluxio worker,从而避免网络传输。由于数据没有持久化地写入底层存储,如果机器崩溃或需要通过释放缓存数据来进行较新的写入,则数据可能会丢失。因此,只有当可以容忍数据丢失的场景时(如写入临时数据),才考虑使用MUST_CACHE 类型的写入。
同步写缓存与持久化存储 (CACHE_THROUGH)
如果使用CACHE_THROUGH的写入类型,数据将被同步写入Alluxio worker和底层存储系统。Alluxio client将写入委托给本地worker,而worker将同时写入本地内存和底层存储。由于写入底层存储的速度通常比写入本地存储慢得多,因此client写入速度将与底层存储的写入速度相当。当需要保证数据持久性时,建议使用 CACHE_THROUGH 写入类型。该类型还会写入本地副本,本地存储的数据可供将来(读取)使用。
异步写回持久化存储(ASYNC_THROUGH)
Alluxio还提供了一种ASYNC_THROUGH写入类型。如果使用ASYNC_THROUGH,数据将被先同步写入Alluxio worker,再在后台持久化写入底层存储系统。 ASYNC_THROUGH可以以接近MUST_CACHE的内存速度提供数据写入,并能够完成数据持久化。从Alluxio 2.0开始,ASYNC_THROUGH已成为默认写入类型。
为了提供容错能力,还有一个重要配置项alluxio.user.file.replication.durable会和ASYNC_THROUGH一起使用。该配置项设置了在数据写入完成后但未被持久化到底层存储之前新数据在Alluxio中的目标复制级别,默认值为1。Alluxio将在后台持久化过程完成之前维持文件的目标复制级别,并在持久化完成之后收回Alluxio中的空间,因此数据只会被写入UFS一次。
如果使用ASYNC_THROUGH写入副本,并且在持久化数据之前出现包含副本的所有worker都崩溃的情况,则会导致数据丢失。
仅写持久化存储(THROUGH)
如果使用THROUGH,数据会同步写入底层存储,而不缓存到Alluxio worker。这种写入类型确保写入完成后数据将被持久化,但写入速度会受限于底层存储吞吐量。
数据一致性
无论写入类型如何,这些写入操作都会首先经由Alluxio master并在修改Alluxio文件系统之后再向client或应用程序返回成功,所以Alluxio 空间中的文件/目录始终是高度一致的。因此,只要相应的写入操作成功完成,不同的Alluxio client看到的数据将始终是最新的。
但是,对于需考虑UFS中数据状态的用户或应用程序而言,不同写入类型可能会导致差异:
- MUST_CACHE 不向UFS写入数据,因此Alluxio空间的数据永远不会与UFS一致。
- CACHE_THROUGH 在向应用程序返回成功之前将数据同步写入Alluxio和UFS。
- 如果写入UFS也是强一致的(例如,HDFS),且UFS中没有其他未经由Alluxio的更新,则Alluxio空间的数据将始终与UFS保持一致;
- 如果写入UFS是最终一致的(例如S3),则文件可能已成功写入Alluxio,但会稍晚才显示在UFS中。在这种情况下,由于Alluxio client总是会咨询强一致的Alluxio master,因此Alluxio client仍然会看到一致的文件系统;因此,尽管不同的Alluxio client始终在Alluxio空间中看到数据一致的状态,但在数据最终传输到UFS之前可能会存在数据不一致的阶段。
- ASYNC_THROUGH 将数据写入Alluxio并返回给应用程序,而Alluxio会将数据异步传输到UFS。从用户的角度来看,该文件可以成功写入Alluxio,但稍晚才会持久化到UFS中。
- THROUGH 直接将数据写入UFS,不在Alluxio中缓存数据,但是,Alluxio知道文件的存在及其状态。因此元数据仍然是一致的。
4. 核心功能
4.1 缓存
4.1.1 Alluxio存储概述
本文档的目的是向用户介绍Alluxio存储和 在Alluxio存储空间中可以执行的操作背后的概念。 与元数据相关的操作 例如同步和名称空间。
Alluxio在帮助统一跨各种平台用户数据的同时还有助于为用户提升总体I / O吞吐量。 Alluxio是通过把存储分为两个不同的类别来实现这一目标的。
- UFS(底层文件存储,也称为底层存储) -该存储空间代表不受Alluxio管理的空间。 UFS存储可能来自外部文件系统,包括如HDFS或S3。 Alluxio可能连接到一个或多个UFS并在一个命名空间中统一呈现这类底层存储。 -通常,UFS存储旨在相当长一段时间持久存储大量数据。
- Alluxio存储
- Alluxio做为一个分布式缓存来管理Alluxio workers本地存储,包括内存。这个在用户应用程序与各种底层存储之间的快速数据层带来的是显著提高的I / O性能。
- Alluxio存储主要用于存储热数据,暂态数据,而不是长期持久数据存储。
- 每个Alluxio节点要管理的存储量和类型由用户配置决定。
- 即使数据当前不在Alluxio存储中,通过Alluxio连接的UFS中的文件仍然 对Alluxio客户可见。当客户端尝试读取仅可从UFS获得的文件时数据将被复制到Alluxio存储中。
Alluxio存储通过将数据存储在计算节点内存中来提高性能。 Alluxio存储中的数据可以被复制来形成”热”数据,更易于I/O并行操作和使用。
Alluxio中的数据副本独立于UFS中可能已存在的副本。 Alluxio存储中的数据副本数是由集群活动动态决定的。 由于Alluxio依赖底层文件存储来存储大部分数据, Alluxio不需要保存未使用的数据副本。
Alluxio还支持让系统存储软件可感知的分层存储,使类似L1/L2 CPU缓存一样的数据存储优化成为可能。
4.1.2 配置Alluxio存储
单层存储
配置Alluxio存储的最简单方法是使用默认的单层模式。
请注意,此部分是讲本地存储,诸如mount之类的术语指在本地存储文件系统上挂载,不要与Alluxio的外部底层存储的mount概念混淆。
在启动时,Alluxio将在每个worker节点上发放一个ramdisk并占用一定比例的系统的总内存。 此ramdisk将用作分配给每个Alluxio worker的唯一存储介质。
通过Alluxio配置中的alluxio-site.properties来配置Alluxio存储。
对默认值的常见修改是明确设置ramdisk的大小。 例如,设置每个worker的ramdisk大小为16GB:
alluxio.worker.ramdisk.size=16GB
另一个常见更改是指定多个存储介质,例如ramdisk和SSD。 需要 更新alluxio.worker.tieredstore.level0.dirs.path以指定想用的每个存储介质 为一个相应的存储目录。 例如,要使用ramdisk(挂载在/mnt/ramdisk上)和两个 SSD(挂载在/mnt/ssd1和/mnt/ssd2):
alluxio.worker.tieredstore.level0.dirs.path=/mnt/ramdisk,/mnt/ssd1,/mnt/ssd2
alluxio.worker.tieredstore.level0.dirs.mediumtype=MEM,SSD,SSD
请注意,介质类型的顺序必须与路径的顺序相符。 MEM和SSD是Alluxio中的两种预配置存储类型。 alluxio.master.tieredstore.global.mediumtype是包含所有可用的介质类型的配置参数,默认情况下设置为MEM,SSD,HDD。 如果用户有额外存储介质类型可以通过修改这个配置来增加。
提供的路径应指向挂载适当存储介质的本地文件系统中的路径。 为了实现短路操作,对于这些路径,应允许客户端用户在这些路径上进行读取,写入和执行。 例如,对于与启动Alluxio服务的用户组同组用户应给予770权限。
更新存储介质后,需要指出每个存储目录分配了多少存储空间。 例如,如果要在ramdisk上使用16 GB,在每个SSD上使用100 GB:
alluxio.worker.tieredstore.level0.dirs.quota=16GB,100GB,100GB
注意存储空间配置的顺序一定与存储目录的配置相符。
Alluxio在通过Mount或SudoMount选项启动时,配置并挂载ramdisk。 这个ramdisk大小是由alluxio.worker.ramdisk.size确定的。 默认情况下,tier 0设置为MEM并且管理整个ramdisk。 此时alluxio.worker.tieredstore.level0.dirs.quota的值同alluxio.worker.ramdisk.size一样。 如果tier0要使用除默认的ramdisk以外的设备,应该显式地设置alluxio.worker.tieredstore.level0.dirs.quota选项。
多层存储
通常建议异构存储介质也使用单个存储层。 在特定环境中,工作负载将受益于基于I/O速度存储介质明确排序。 Alluxio假定根据按I/O性能从高到低来对多层存储进行排序。 例如,用户经常指定以下层:
- MEM(内存)
- SSD(固态存储)
- HDD(硬盘存储)
写数据
用户写新的数据块时,默认情况下会将其写入顶层存储。如果顶层没有足够的可用空间, 则会尝试下一层存储。如果在所有层上均未找到存储空间,因Alluxio的设计是易失性存储,Alluxio会释放空间来存储新写入的数据块。 根据块注释策略,空间释放操作会从worker中释放数据块。 块注释策略。 如果空间释放操作无法释放新空间,则写数据将失败。
注意:新的释放空间模型是同步模式并会代表要求为其要写入的数据块释放新空白存储空间的客户端来执行释放空间操作。 在块注释策略的帮助下,同步模式释放空间不会引起性能下降,因为总有已排序的数据块列表可用。 然而,可以将alluxio.worker.tieredstore.free.ahead.bytes(默认值:0)配置为每次释放超过释放空间请求所需字节数来保证有多余的已释放空间满足写数据需求。
读取数据
如果数据已经存在于Alluxio中,则客户端将简单地从已存储的数据块读取数据。 如果将Alluxio配置为多层,则不一定是从顶层读取数据块, 因为数据可能已经透明地挪到更低的存储层。
用ReadType.CACHE_PROMOTE读取数据将在从worker读取数据前尝试首先将数据块挪到 顶层存储。也可以将其用作为一种数据管理策略 明确地将热数据移动到更高层存储读取。
配置分层存储
可以使用以下方式在Alluxio中启用分层存储 配置参数。 为Alluxio指定额外存储层,使用以下配置参数:
alluxio.worker.tieredstore.levels
alluxio.worker.tieredstore.level{x}.alias
alluxio.worker.tieredstore.level{x}.dirs.quota
alluxio.worker.tieredstore.level{x}.dirs.path
alluxio.worker.tieredstore.level{x}.dirs.mediumtype
例如,如果计划将Alluxio配置为具有两层存储,内存和硬盘存储, 可以使用类似于以下的配置:
# configure 2 tiers in Alluxio
alluxio.worker.tieredstore.levels=2
# the first (top) tier to be a memory tier
alluxio.worker.tieredstore.level0.alias=MEM
# defined `/mnt/ramdisk` to be the file path to the first tier
alluxio.worker.tieredstore.level0.dirs.path=/mnt/ramdisk
# defined MEM to be the medium type of the ramdisk directory
alluxio.worker.tieredstore.level0.dirs.mediumtype=MEM
# set the quota for the ramdisk to be `100GB`
alluxio.worker.tieredstore.level0.dirs.quota=100GB
# configure the second tier to be a hard disk tier
alluxio.worker.tieredstore.level1.alias=HDD
# configured 3 separate file paths for the second tier
alluxio.worker.tieredstore.level1.dirs.path=/mnt/hdd1,/mnt/hdd2,/mnt/hdd3
# defined HDD to be the medium type of the second tier
alluxio.worker.tieredstore.level1.dirs.mediumtype=HDD,HDD,HDD
# define the quota for each of the 3 file paths of the second tier
alluxio.worker.tieredstore.level1.dirs.quota=2TB,5TB,500GB
可配置层数没有限制 但是每个层都必须使用唯一的别名进行标识。 典型的配置将具有三层,分别是内存,SSD和HDD。 要在HDD层中使用多个硬盘存储,需要在配置alluxio.worker.tieredstore.level{x}.dirs.path时指定多个路径。
块注释策略
Alluxio从v2.3开始使用块注释策略来维护存储中数据块的严格顺序。 注释策略定义了跨层块的顺序,并在以下操作过程中进行用来参考: 释放空间。
与写操作同步发生的释放空间操作将尝试根据块注释策略强制顺序删除块并释放其空间给写操作。注释顺序的最后一个块是第一个释放空间候选对象,无论它位于哪个层上。
开箱即用的注释策略实施包括:
- LRUAnnotator:根据最近最少使用的顺序对块进行注释和释放。 这是Alluxio的默认注释策略。
- LRFUAnnotator:根据配置权重的最近最少使用和最不频繁使用的顺序对块进行注释。
- 如果权重完全偏设为最近最少使用,则行为将 与LRUAnnotator相同。
- 适用的配置属性包括alluxio.worker.block.annotator.lrfu.step.factor alluxio.worker.block.annotator.lrfu.attenuation.factor。
workers选择使用的注释策略由Alluxio属性 alluxio.worker.block.annotator.class决定。 该属性应在配置中指定完全验证的策略名称。当前可用的选项有:
- alluxio.worker.block.annotator.LRUAnnotator
- alluxio.worker.block.annotator.LRFUAnnotator
释放空间模拟
旧的释放空间策略和Alluxio提供的实施现在已去掉了,并用适当的注释策略替换。 配置旧的Alluxio释放空间策略将导致worker启动失败,并报错java.lang.ClassNotFoundException。 同样,旧的基于水位标记配置已失效。因此,以下配置选项是无效的:
-alluxio.worker.tieredstore.levelX.watermark.low.ratio -alluxio.worker.tieredstore.levelX.watermark.high.ratio
然而,Alluxio支持基于自定义释放空间实施算法数据块注释的仿真模式。该仿真模式假定已配置的释放空间策略创建一个基于某种顺序释放空间的计划,并通过定期提取这种自定义顺序来支持块注释活动。
旧的释放空间配置应进行如下更改。 (由于旧的释放空间实施已删除,如未能更改基于旧实施的以下配置就会导致class加载错误。)
-LRUEvictor-> LRUAnnotator -GreedyEvictor-> LRUAnnotator -PartialLRUEvictor-> LRUAnnotator -LRFUEvictor-> LRFUAnnotator
分层存储管理
因为块分配/释放不再强制新的写入必须写到特定存储层,新数据块可能最终被写到任何已配置的存储层中。这样允许写入超过Alluxio存储容量的数据。但是,这就需要Alluxio动态管理块放置。 为了确保层配置为从最快到最慢的假设,Alluxio会基于块注释策略在各层存储之间移动数据块。
每个单独层管理任务都遵循以下配置:
- alluxio.worker.management.task.thread.count:管理任务所用线程数。 (默认值:CPU核数)
- alluxio.worker.management.block.transfer.concurrency.limit:可以同时执行多少个块传输。 (默认:CPU核数/2)
块对齐(动态块放置)
Alluxio将动态地跨层移动数据块,以使块组成与配置的块注释策略一致。
为辅助块对齐,Alluxio会监视I/O模式并会跨层重组数据块,以确保 较高层的最低块比下面层的最高块具有更高的次序。
这是通过”对齐”这个管理任务来实现的。此管理任务在检测到层之间 顺序已乱时,会通过在层之间交换块位置来有效地将各层与已配置的注释策略对齐以消除乱序。 有关如何控制这些新的后台任务对用户I/O的影响。
用于控制层对齐:
- alluxio.worker.management.tier.align.enabled:是否启用层对齐任务。 (默认: true)
- alluxio.worker.management.tier.align.range:单个任务运行中对齐多少个块。 (默认值:100)
- alluxio.worker.management.tier.align.reserved.bytes:配置多层时,默认情况下在所有目录上保留的空间大小。 (默认:1GB) 用于内部块移动。
- alluxio.worker.management.tier.swap.restore.enabled:控制一个特殊任务,该任务用于在内部保留空间用尽时unblock层对齐。 (默认:true) 由于Alluxio支持可变的块大小,因此保留空间可能会用尽,因此,当块大小不匹配时在块对齐期间在层之间块交换会导致一个目录保留空间的减少。
块升级
当较高层具有可用空间时,低层的块将向上层移动,以便更好地利用较快的磁盘介质,因为假定较高的层配置了较快的磁盘介质。
用于控制动态层升级:
- alluxio.worker.management.tier.promote.enabled:是否启用层升级任务。 (默认: true)
- alluxio.worker.management.tier.promote.range:单个任务运行中升级块数。 (默认值:100)
- alluxio.worker.management.tier.promote.quota.percent:每一层可以用于升级最大百分比。 一旦其已用空间超过此值,向此层升级将停止。 (0表示永不升级,100表示总是升级。)
管理任务推后
层管理任务(对齐/升级)会考虑用户I/O并在worker/disk重载情况下推后运行。 这是为了确保内部管理任务不会对用户I/O性能产生负面影响。
可以在alluxio.worker.management.backoff.strategy属性中设置两种可用的推后类型,分别是Any和DIRECTORY。
-ANY; 当有任何用户I/O时,worker管理任务将推后。 此模式将确保较低管理任务开销,以便提高即时用户I/O性能。 但是,管理任务要取得进展就需要在worker上花更长的时间。
-DIRECTORY; 管理任务将从有持续用户I/O的目录中推后。 此模式下管理任务更易取得进展。 但是,由于管理任务活动的增加,可能会降低即时用户I/O吞吐量。
影响这两种推后策略的另一个属性是alluxio.worker.management.load.detection.cool.down.time,控制多长时间的用户I/O计为在目标directory/worker上的一个负载。
4.1.3 Alluxio中数据生命周期管理
用户需要理解以下概念,以正确利用可用资源:
- free:释放数据是指从Alluxio缓存中删除数据,而不是从底层UFS中删除数据。 释放操作后,数据仍然可供用户使用,但对Alluxio释放文件后尝试访问该文件 的客户端来讲性能可能会降低。
- load:加载数据意味着将其从UFS复制到Alluxio缓存中。如果Alluxio使用 基于内存的存储,加载后用户可能会看到I/O性能的提高。
- persist:持久数据是指将Alluxio存储中可能被修改过或未被修改过的数据写回UFS。 通过将数据写回到UFS,可以保证如果Alluxio节点发生故障数据还是可恢复的。
- TTL(Time to Live):TTL属性设置文件和目录的生存时间,以 在数据超过其生存时间时将它们从Alluxio空间中删除。还可以配置 TTL来删除存储在UFS中的相应数据。
从Alluxio存储中释放数据
为了在Alluxio中手动释放数据,可以使用./bin/alluxio文件系统命令 行界面。
$ ./bin/alluxio fs free ${PATH_TO_UNUSED_DATA}
这将从Alluxio存储中删除位于给定路径的数据。如果数据是持久存储到UFS的则仍然可以访问该数据。
注意,用户通常不需要手动从Alluxio释放数据,因为 配置的注释策略将负责删除未使用或旧数据。
将数据加载到Alluxio存储中
如果数据已经在UFS中,使用 alluxio fs load
$ ./bin/alluxio fs load ${PATH_TO_FILE}
要从本地文件系统加载数据,使用命令 alluxio fs copyFromLocal。 这只会将文件加载到Alluxio存储中,而不会将数据持久保存到UFS中。 将写入类型设置为MUST_CACHE写入类型将不会将数据持久保存到UFS, 而设置为CACHE和CACHE_THROUGH将会持久化保存。不建议手动加载数据,因为,当首次使用文件时Alluxio会自动将数据加载到Alluxio缓存中。
在Alluxio中持久化保留数据
命令alluxio fs persist 允许用户将数据从Alluxio缓存推送到UFS。
$ ./bin/alluxio fs persist ${PATH_TO_FILE}
如果您加载到Alluxio的数据不是来自已配置的UFS,则上述命令很有用。 在大多数情况下,用户不必担心手动来持久化保留数据。
设置生存时间(TTL)
Alluxio支持命名空间中每个文件和目录的”生存时间(TTL)”设置。此 功能可用于有效地管理Alluxio缓存,尤其是在严格 保证数据访问模式的环境中。例如,如果对上一周提取数据进行分析, 则TTL功能可用于明确刷新旧数据,从而为新文件释放缓存空间。
Alluxio具有与每个文件或目录关联的TTL属性。这些属性将保存为 日志的一部分,所以集群重新后也能持久保持。活跃master节点负责 当Alluxio提供服务时将元数据保存在内存中。在内部,master运行一个后台 线程,该线程定期检查文件是否已达到其TTL到期时间。
注意,后台线程按配置的间隔运行,默认设置为一个小时。 在检查后立即达到其TTL期限的数据不会马上删除, 而是等到一个小时后下一个检查间隔才会被删除。
如将间隔设置为10分钟,在alluxio-site.properties添加以下配置:
alluxio.master.ttl.checker.interval=10m
4.1.4 在Alluxio中管理数据复制
被动复制
与许多分布式文件系统一样,Alluxio中的每个文件都包含一个或多个分布在集群中存储的存储块。默认情况下,Alluxio可以根据工作负载和存储容量自动调整不同块的复制级别。例如,当更多的客户以类型CACHE或CACHE_PROMOTE请求来读取此块时Alluxio可能会创建此特定块更多副本。当较少使用现有副本时,Alluxio可能会删除一些不常用现有副本 来为经常访问的数据征回空间(块注释策略)。 在同一文件中不同的块可能根据访问频率不同而具有不同数量副本。
默认情况下,此复制或征回决定以及相应的数据传输 对访问存储在Alluxio中数据的用户和应用程序完全透明。
主动复制
除了动态复制调整之外,Alluxio还提供API和命令行 界面供用户明确设置文件的复制级别目标范围。 尤其是,用户可以在Alluxio中为文件配置以下两个属性:
- alluxio.user.file.replication.min是此文件的最小副本数。 默认值为0,即在默认情况下,Alluxio可能会在文件变冷后从Alluxio管理空间完全删除该文件。 通过将此属性设置为正整数,Alluxio 将定期检查此文件中所有块的复制级别。当某些块 的复制数不足时,Alluxio不会删除这些块中的任何一个,而是主动创建更多 副本以恢复其复制级别。
- alluxio.user.file.replication.max是最大副本数。一旦文件该属性 设置为正整数,Alluxio将检查复制级别并删除多余的 副本。将此属性设置为-1为不设上限(默认情况),设置为0以防止 在Alluxio中存储此文件的任何数据。注意,alluxio.user.file.replication.max的值 必须不少于alluxio.user.file.replication.min。
例如,用户可以最初使用至少两个副本将本地文件/path/to/file复制到Alluxio:
$ ./bin/alluxio fs -Dalluxio.user.file.replication.min=2 \
copyFromLocal /path/to/file /file
接下来,设置/file的复制级别区间为3到5。需要注意的是,在后台进程中完成新的复制级别范围设定后此命令将马上返回,实现复制目标是异步完成的。
$ ./bin/alluxio fs setReplication --min 3 --max 5 /file
设置alluxio.user.file.replication.max为无上限。
$ ./bin/alluxio fs setReplication --max -1 /file
重复递归复制目录/dir下所有文件复制级别(包括其子目录)使用-R:
$ ./bin/alluxio fs setReplication --min 3 --max -5 -R /dir
要检查的文件的目标复制水平,运行
$ ./bin/alluxio fs stat /foo
并在输出中查找replicationMin和replicationMax字段。
4.1.5 检查Alluxio缓存容量和使用情况
Alluxio shell命令fsadmin report提供可用空间的简短摘要 以及其他有用的信息。输出示例如下:
$ ./bin/alluxio fsadmin report
Alluxio shell还允许用户检查Alluxio缓存中多少空间可用和在用。
获得Alluxio缓存总使用字节数运行:
$ ./bin/alluxio fs getUsedBytes
获得Alluxio缓存以字节为单位的总容量
$ ./bin/alluxio fs getCapacityBytes
Alluxio master web界面为用户提供了集群的可视化总览包括已用多少存储空间。可以在http:/{MASTER_IP}:${alluxio.master.web.port}/中找到。
4.2 UFS命名空间
4.2.1 介绍
Alluxio通过使用透明的命名机制和挂载API来实现有效的跨不同底层存储系统的数据管理。
统一命名空间
Alluxio提供的主要好处之一是为应用程序提供统一命名空间。 通过统一命名空间的抽象,应用程序可以通过统一命名空间和接口来访问多个独立的存储系统。 与其与每个独立的存储系统进行通信,应用程序可以只连接到Alluxio并委托Alluxio来与不同的底层存储通信。
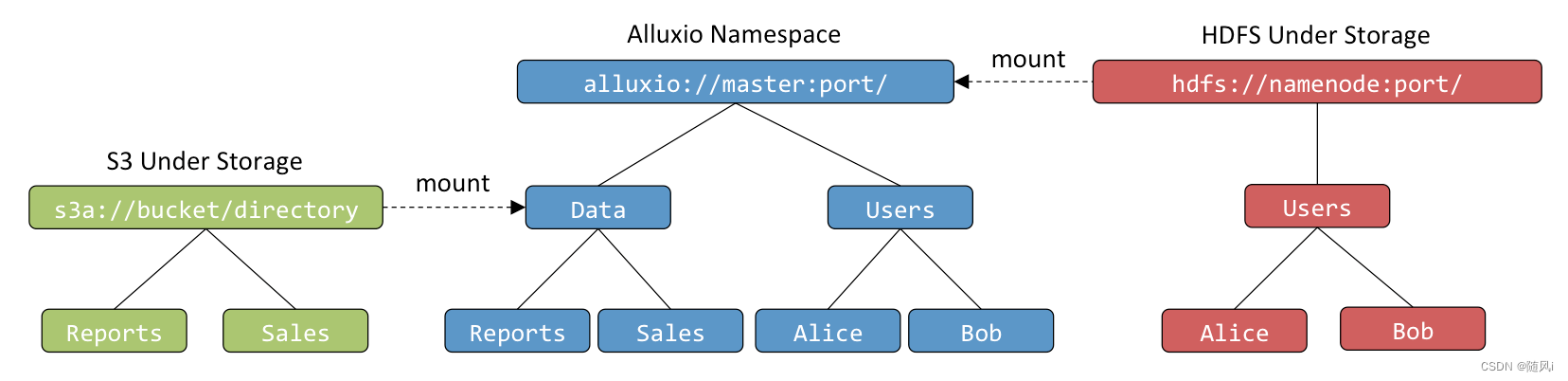
master配置属性alluxio.master.mount.table.root.ufs指定的目录挂载到Alluxio命名空间根目录,该目录代表Alluxio 的”primary storage”。在此基础上,用户可以通过挂载API添加和删除数据源。
void mount(AlluxioURI alluxioPath, AlluxioURI ufsPath);
void mount(AlluxioURI alluxioPath, AlluxioURI ufsPath, MountOptions options);
void unmount(AlluxioURI path);
void unmount(AlluxioURI path, UnmountOptions options);
例如,可以通过以下方式将一个新的S3存储桶挂载到Data目录中
mount(new AlluxioURI("alluxio://host:port/Data"), new AlluxioURI("s3://bucket/directory"));
UFS命名空间
除了Alluxio提供的统一命名空间之外,每个已挂载的基础文件系统 在Alluxio命名空间中有自己的命名空间; 称为UFS命名空间。 如果在没有通过Alluxio的情况下更改了UFS名称空间中的文件, UFS命名空间和Alluxio命名空间可能不同步的情况。 发生这种情况时,需要执行UFS元数据同步操作才能重新使两个名称空间同步。
4.2.2 透明命名机制
透明命名机制保证了Alluxio和底层存储系统命名空间身份一致性。
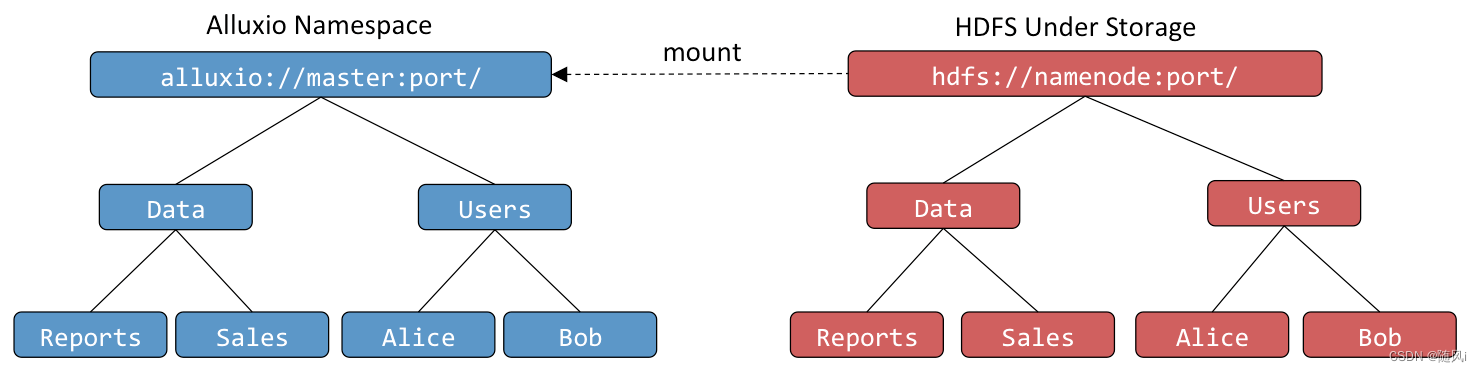
当用户在Alluxio命名空间创建对象时,可以选择这些对象是否要在底层存储系统中持久化。对于需要持久化的对象, Alluxio会保存底层存储系统存储这些对象的路径。例如,一个用户在根目录下创建了一个Users目录及Alice和Bob两个子目录,底层存储系统也会保存相同的目录结构和命名。类似地,当用户在 Alluxio命名空间中对一个持久化的对象进行重命名或者删除操作时,底层存储系统中也会对其执行相同的重命名或删除操作。
Alluxio能够透明发现底层存储系统中并非通过Alluxio创建的内容。例如,底层存储系统中包含一个Data文件夹, 其中包含Reports和Sales文件,都不是通过Alluxio创建的,当它们第一次被访问时,如用户请求打开文 件,Alluxio会自动加载这些对象的元数据。然而在该过程中Alluxio不会加载文件内容数据,若要将其内容加载到Alluxio, 可以用FileInStream来读数据,或者通过Alluxio Shell中的load命令。
4.2.3 挂载底层存储系统
定义Alluxio命名空间和UFS命名空间之间的关联是通过将底层存储系统挂载到Alluxio文件系统命名空间的机制完成的。 在Alluxio中挂载底层存储与在Linux文件系统中挂载一个卷类似。 mount命令将UFS挂载到Alluxio命名空间中文件系统树。
根挂载点
Alluxio命名空间的根挂载点是在masters上’conf/alluxio-site.properties’中配置的。 下一行是一个配置样例,一个HDFS路径挂载到 Alluxio命名空间根目录。
alluxio.master.mount.table.root.ufs=hdfs://HDFS_HOSTNAME:8020
使用配置前缀来配置根挂载点的挂载选项:
alluxio.master.mount.table.root.option.<some alluxio property>
例如,以下配置为根挂载点添加AWS凭证。
alluxio.master.mount.table.root.option.s3a.accessKeyId=<AWS_ACCESS_KEY_ID>
alluxio.master.mount.table.root.option.s3a.secretKey=<AWS_SECRET_ACCESS_KEY>
以下配置显示了如何为根挂载点设置其他参数。
alluxio.master.mount.table.root.option.alluxio.security.underfs.hdfs.kerberos.client.principal=client
alluxio.master.mount.table.root.option.alluxio.security.underfs.hdfs.kerberos.client.keytab.file=keytab
alluxio.master.mount.table.root.option.alluxio.security.underfs.hdfs.impersonation.enabled=true
alluxio.master.mount.table.root.option.alluxio.underfs.version=2.7
嵌套挂载点
除了根挂载点之外,其他底层文件系统也可以挂载到Alluxio命名空间中。 这些额外的挂载点可以通过mount命令在运行时添加到Alluxio。 --option选项允许用户传递挂载操作的附加参数,如凭证。
# the following command mounts an hdfs path to the Alluxio path `/mnt/hdfs`
$ ./bin/alluxio fs mount /mnt/hdfs hdfs://host1:9000/data/
# the following command mounts an s3 path to the Alluxio path `/mnt/s3` with additional options specifying the credentials
$ ./bin/alluxio fs mount \
--option s3a.accessKeyId=<accessKeyId> --option s3a.secretKey=<secretKey> \
/mnt/s3 s3://data-bucket/
注意,挂载点也允许嵌套。 例如,如果将UFS挂载到 alluxio:///path1,可以在alluxio:///path1/path2处挂载另一个UFS。
使用特定版本挂载UFS
Alluxio支持挂载特定不同版本HDFS。 因此,用户可以将不同版本的HDFS挂载到同一个Alluxio命名空间中。
4.2.4 Alluxio和UFS命名空间之间的关系
Alluxio提供了一个统一的命名空间,充当一个或多个底层文件存储系统的数据缓存层。 本节讨论Alluxio如何与底层文件系统交互来发现和通过Alluxio呈现这些文件。
通过Alluxio访问UFS文件的与直接通过UFS访问文件的相同。 如果UFS根目录是s3://bucket/data,则列出alluxio:///下内容应该与列出s3://bucket/data相同。 在alluxio:///file上运行cat的结果应与在s3://bucket/data/file上运行cat的结果相同。
Alluxio按需从UFS加载元数据。 在上面的示例中,Alluxio在启动时并没有有关s3://bucket/data/file的信息。 直到当用户试图列出alluxio:///或尝试使用cat alluxio:///file时,才发现该文件。 这样好处是可以防止在安装新的UFS时进行不必要的文件发现工作。
默认情况下, Alluxio预期所有对底层文件系统修改都是通过Alluxio 来进行的。 这样Alluxio只需扫描每个UFS目录一次,从而在UFS元数据操作很慢情况下显著提高性能。 当出现在Alluxio之外对UFS进行更改的情况下, 就需要用元数据同步功能用于同步两个命名空间。
UFS元数据同步
UFS元数据同步功能新增自版本1.7.0。
当Alluxio扫描UFS目录并加载其子目录元数据时, 它将创建元数据的副本,以便将来无需再从UFS加载。 元数据的缓存副本将根据 alluxio.user.file.metadata.sync.interval客户端属性配置的间隔段刷新。 此属性适用于客户端操作。 例如,如果客户执行一个命令基于间隔设置为一分钟的配置, 如果最后一次刷新是在一分钟之前,则相关元数据将据UFS刷新。 设值为0表示针对每个操作都会进行实时元数据同步, 而默认值-1表示在初始加载后不会再重新同步元数据。
低间隔值使Alluxio客户端可以快速发现对UFS的外部修改, 但由于导致调用UFS的次数增加,因此是以降低性能为代价的。
元数据同步会保留每个UFS文件的指纹记录,以便Alluxio可以在文件更改时做出相应更新。 指纹记录包括诸如文件大小和上次修改时间之类的信息。 如果在UFS中修改了文件,Alluxio将通过指纹检测到该修改,释放现有文件 元数据,然后重新加载更新文件的元数据。 如果在UFS中添加或删除了文件,Alluxio还将更新对其命名空间中的元数据做出相应刷新。
用于管理UFS同步的方法
定期元数据同步
如果UFS按计划的间隔更新,可以在更新后手动触发sync命令。 运行以下命令将同步间隔设置为0:
$ ./bin/alluxio fs ls -R -Dalluxio.user.file.metadata.sync.interval=0 /path/to/sync
集中配置
对于使用来自频繁更新的UFS数据的集群作业, 每个客户端指定一个同步间隔很不方便。 如果在master配置中设置了同步间隔,所有请求都将以默认的同步间隔来处理。
在master点上的alluxio-site.properties中设置:
alluxio.user.file.metadata.sync.interval=1m
注意,需要重新启动master节点以便启用新配置。
其他加载新UFS文件的方法
建议使用前面讨论的UFS同步的方法来同步UFS中的更改。 这是是其他一些加载文件的方法:
*alluxio.user.file.metadata.load.type:此客户端属性可以设置为 ALWAYS,ONCE或NEVER。此属性类似alluxio.user.file.metadata.sync.interval, 但有注意事项: 1.它只会发现新文件,不会重新加载修改或删除的文件。 1.它仅适用于exists,list和getStatus RPC。
`ALWAYS`配置意味者总会检查UFS中是否有新文件,`ONCE`将使用默认值 仅扫描每个目录一次,而`NEVER`配置下Alluxio根本不会 扫描新文件。
*alluxio fs ls -f /path:ls的-f选项相当于设置 alluxio.user.file.metadata.load.type为ALWAYS。它将发现新文件,但 不检测修改或删除的UFS文件。 要检测修改或删除的UFS文件的唯一方法是通过传递 -Dalluxio.user.file.metadata.sync.interval=0选项给ls。
4.2.5 示例
以下示例假设Alluxio源代码在${ALLUXIO_HOME}文件夹下,并且有一个本地运行的Alluxio进程。
透明命名
先在本地文件系统中创建一个将作为底层存储挂载的临时目录:
$ cd /tmp
$ mkdir alluxio-demo
$ touch alluxio-demo/hello
将创建的目录挂载到Alluxio命名空间中,并确认挂载后的目录在Alluxio中存在:
$ cd ${ALLUXIO_HOME}
$ ./bin/alluxio fs mount /demo file:///tmp/alluxio-demo
Mounted file:///tmp/alluxio-demo at /demo
$ ./bin/alluxio fs ls -R /
... # note that the output should show /demo but not /demo/hello
验证对于不是通过Alluxio创建的内容,当第一次被访问时,其元数据被加载进入了Alluxio中:
$ ./bin/alluxio fs ls /demo/hello
... # should contain /demo/hello
在挂载目录下创建一个文件,并确认在底层文件系统中该文件也被以同样名字创建了:
$ ./bin/alluxio fs touch /demo/hello2
/demo/hello2 has been created
$ ls /tmp/alluxio-demo
hello hello2
在Alluxio中重命名一个文件,并验证在底层文件系统中该文件也被重命名了:
$ ./bin/alluxio fs mv /demo/hello2 /demo/world
Renamed /demo/hello2 to /demo/world
$ ls /tmp/alluxio-demo
hello world
在Alluxio中删除一个文件,然后确认该文件是否在底层文件系统中也被删除了:
$ ./bin/alluxio fs rm /demo/world
/demo/world has been removed
$ ls /tmp/alluxio-demo
hello
卸载该挂载目录,并确认该目录已经在Alluxio命名空间中被删除,但该目录依然保存在底层文件系统中。
$ ./bin/alluxio fs unmount /demo
Unmounted /demo
$ ./bin/alluxio fs ls -R /
... # should not contain /demo
$ ls /tmp/alluxio-demo
hello
HDFS元数据主动同步
在2.0版中,引入了一项新功能,用于在UFS为HDFS时保持Alluxio空间与UFS之间的同步。 该功能称为主动同步,可监听HDFS事件并以master上后台任务方式定期在UFS和Alluxio命名空间之间同步元数据。 由于主动同步功能取决于HDFS事件,因此仅当UFS HDFS版本高于2.6.1时,此功能才可用。 你可能需要在配置文件中更改alluxio.underfs.version的值。
要在一个目录上启用主动同步,运行以下Alluxio命令。
$ ./bin/alluxio fs startSync /syncdir
可以通过更改alluxio.master.ufs.active.sync.interval选项来控制主动同步间隔,默认值为30秒。
要在一个目录上停止使用主动同步,运行以下Alluxio命令。
$ ./bin/alluxio fs stopSync /syncdir
注意:发布startSync时,就预定了对同步点进行完整扫描。 如果以Alluxio超级用户身份运行,stopSync将中断所有尚未结束的完整扫描。 如果以其他用户身份运行,stopSync将等待完整扫描完成后再执行。
可以使用以下命令检查哪些目录当前处于主动同步状态。
$ ./bin/alluxio fs getSyncPathList
主动同步的静默期
主动同步会尝试避免在目标目录被频繁使用时进行同步。 它会试图在UFS活动期寻找一个静默期,再开始UFS和Alluxio空间之间同步,以避免UFS繁忙时使其过载。 有两个配置选项来控制此特性。
alluxio.master.ufs.active.sync.max.activities是UFS目录中的最大活动数。 活动数的计算是基于目录中事件数的指数移动平均值的启发式方法。 例如,如果目录在过去三个时间间隔中有100、10、1个事件。 它的活动为100/10 * 10 + 10/10 + 1 = 3 alluxio.master.ufs.active.sync.max.age是在同步UFS和Alluxio空间之前将等待的最大间隔数。
系统保证如果目录”静默”或长时间未同步(超过最大期限),我们将开始同步该目录。
例如,以下设置
alluxio.master.ufs.active.sync.interval=30sec
alluxio.master.ufs.active.sync.max.activities=100
alluxio.master.ufs.active.sync.max.age=5
表示系统每隔30秒就会计算一次此目录的事件数, 并计算其活动。 如果活动数少于100,则将其视为一个静默期,并开始同步 该目录。 如果活动数大于100,并且在最近5个时间间隔内未同步,或者 5 * 30 = 150秒,它将开始同步目录。 如果活动数大于100并且至少已在最近5个间隔中同步过一次,将不会执行主动同步。
统一命名空间
此示例将安装多个不同类型的底层存储,以展示统一文件系统命名空间的抽象作用。 本示例将使用属于不同AWS账户和一个HDSF服务的两个S3存储桶。
使用相对应凭证<accessKeyId1>和<secretKey1>将第一个S3存储桶挂载到Alluxio中:
$ ./bin/alluxio fs mkdir /mnt
$ ./bin/alluxio fs mount \
--option s3a.accessKeyId=<accessKeyId1> \
--option s3a.secretKey=<secretKey1> \
/mnt/s3bucket1 s3://data-bucket1/
使用相对应凭证’’和’ ’将第二个S3存储桶挂载到Alluxio:
$ ./bin/alluxio fs mount \
--option s3a.accessKeyId=<accessKeyId2> \
--option s3a.secretKey=<secretKey2> \
/mnt/s3bucket2 s3://data-bucket2/
将HDFS存储挂载到Alluxio:
$ ./bin/alluxio fs mount /mnt/hdfs hdfs://<NAMENODE>:<PORT>/
所有这三个目录都包含在Alluxio的一个命名空间中:
$ ./bin/alluxio fs ls -R /
... # should contain /mnt/s3bucket1, /mnt/s3bucket2, /mnt/hdfs
5. Alluxio参数配置及调优
参考配置项解释:配置项列表 - Alluxio v2.9.0 Documentation
参数调优看这篇博文即可:Alluxio性能调优-腾讯云开发者社区-腾讯云
6. Alluxio Shell
Alluxio命令行接口为用户提供了基本的文件系统操作,可以使用以下命令来得到所有子命令:
$ ./bin/alluxio fs
Usage: alluxio fs [generic options]
[cat <path>]
[checkConsistency [-r] <Alluxio path>]
...
对于用Alluxio URI(如ls, mkdir)作为参数的fs子命令来说,参数应该要么是完整的Alluxio URI alluxio://<master-hostname>:<master-port>/<path>,要么是省略了头部信息的/<path>,以使用conf/alluxio-site.properties中设置的默认的主机名和端口。
通配符输入
大多数需要路径参数的命令可以使用通配符以便简化使用,例如:
$ ./bin/alluxio fs rm '/data/2014*'
该示例命令会将data文件夹下以2014为文件名前缀的所有文件删除。
注意有些shell会尝试自动补全输入路径,从而引起奇怪的错误(注意:以下例子中的数字可能不是21,这取决于你的本地文件系统中匹配文件的个数):
rm takes 1 arguments, not 21
作为一种绕开这个问题的方式,你可以禁用自动补全功能(跟具体shell有关,例如set -f),或者使用转义通配符,例如:
$ ./bin/alluxio fs cat /\\*
注意是两个转义符号,这是因为该shell脚本最终会调用一个java程序运行,该java程序将获取到转义输入参数(cat /\*)。
操作列表
| 操作 | 语法 | 描述 |
| cat | cat "path" | 将Alluxio中的一个文件内容打印在控制台中 |
| checkConsistency | checkConsistency "path" | 检查Alluxio与底层存储系统的元数据一致性 |
| checksum | checksum "path" | 计算一个文件的md5校验码 |
| chgrp | chgrp "group" "path" | 修改Alluxio中的文件或文件夹的所属组 |
| chmod | chmod "permission" "path" | 修改Alluxio中文件或文件夹的访问权限 |
| chown | chown "owner" "path" | 修改Alluxio中文件或文件夹的所有者 |
| copyFromLocal | copyFromLocal "source path" "remote path" | 将"source path"指定的本地文件系统中的文件拷贝到Alluxio中"remote path"指定的路径 如果"remote path"已经存在该命令会失败 |
| copyToLocal | copyToLocal "remote path" "local path" | 将"remote path"指定的Alluxio中的文件复制到本地文件系统中 |
| count | count "path" | 输出"path"中所有名称匹配一个给定前缀的文件及文件夹的总数 |
| cp | cp "src" "dst" | 在Alluxio文件系统中复制一个文件或目录 |
| du | du "path" | 输出一个指定的文件或文件夹的大小 |
| fileInfo | fileInfo "path" | 输出指定的文件的数据块信息 |
| free | free "path" | 将Alluxio中的文件或文件夹移除,如果该文件或文件夹存在于底层存储中,那么仍然可以在那访问 |
| getCapacityBytes | getCapacityBytes | 获取Alluxio文件系统的容量 |
| getfacl | getfacl "path" | |
| getUsedBytes | getUsedBytes | 获取Alluxio文件系统已使用的字节数 |
| help | help "cmd" | 打印给定命令的帮助信息,如果没有给定命令,打印所有支持的命令的帮助信息 |
| leader | leader | 打印当前Alluxio leader master节点主机名 |
| load | load "path" | 将底层文件系统的文件或者目录加载到Alluxio中 |
| loadMetadata | loadMetadata "path" | 将底层文件系统的文件或者目录的元数据加载到Alluxio中 |
| location | location "path" | 输出包含某个文件数据的主机 |
| ls | ls "path" | 列出给定路径下的所有直接文件和目录的信息,例如大小 |
| masterInfo | masterInfo | 打印Alluxio master容错相关的信息,例如leader的地址、所有master的地址列表以及配置的Zookeeper地址 |
| mkdir | mkdir "path1" ... "pathn" | 在给定路径下创建文件夹,以及需要的父文件夹,多个路径用空格或者tab分隔,如果其中的任何一个路径已经存在,该命令失败 |
| mount | mount "path" "uri" | 将底层文件系统的"uri"路径挂载到Alluxio命名空间中的"path"路径下,"path"路径事先不能存在并由该命令生成。 没有任何数据或者元数据从底层文件系统加载。当挂载完成后,对该挂载路径下的操作会同时作用于底层文件系统的挂载点。 |
| mv | mv "source" "destination" | 将"source"指定的文件或文件夹移动到"destination"指定的新路径,如果"destination"已经存在该命令失败。 |
| persist | persist "path1" ... "pathn" | 将仅存在于Alluxio中的文件或文件夹持久化到底层文件系统中 |
| pin | pin "path" | 将给定文件锁定到内容中以防止剔除。如果是目录,递归作用于其子文件以及里面新创建的文件 |
| report | report "path" | 向master报告一个文件已经丢失 |
| rm | rm "path" | 删除一个文件,如果输入路径是一个目录该命令失败 |
| setfacl | setfacl "newACL" "path" | |
| setTtl | setTtl "path" "time" | 设置一个文件的TTL时间,单位毫秒,注意,默认动作为 DELETE,会将文件从Alluxio命名空间和底层存储中删除 |
| stat | stat "path" | 显示文件和目录指定路径的信息 |
| tail | tail "path" | 将指定文件的最后1KB内容输出到控制台 |
| test | test "path" | 测试路径的属性,如果属性正确,返回0,否则返回1 |
| touch | touch "path" | 在指定路径创建一个空文件 |
| unmount | unmount "path" | 卸载挂载在Alluxio中"path"指定路径上的底层文件路径,Alluxio中该挂载点的所有对象都会被删除,但底层文件系统会将其保留。 |
| unpin | unpin "path" | 将一个文件解除锁定从而可以对其剔除,如果是目录则递归作用 |
| unsetTtl | unsetTtl "path" | 删除文件的ttl值 |
使用详情参考:User Command Line Interface - Alluxio v2.9.3 (stable) Documentation


![[SDOI2008] 仪仗队 题解](https://img-blog.csdnimg.cn/img_convert/24c97ec3cfde87981e216b1cdddd7d2a.png)