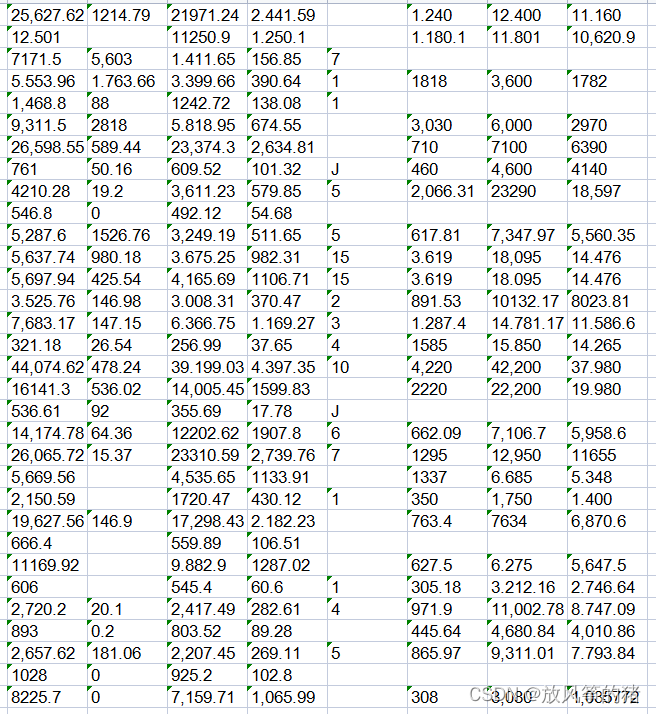
识别效果展示
原始表格
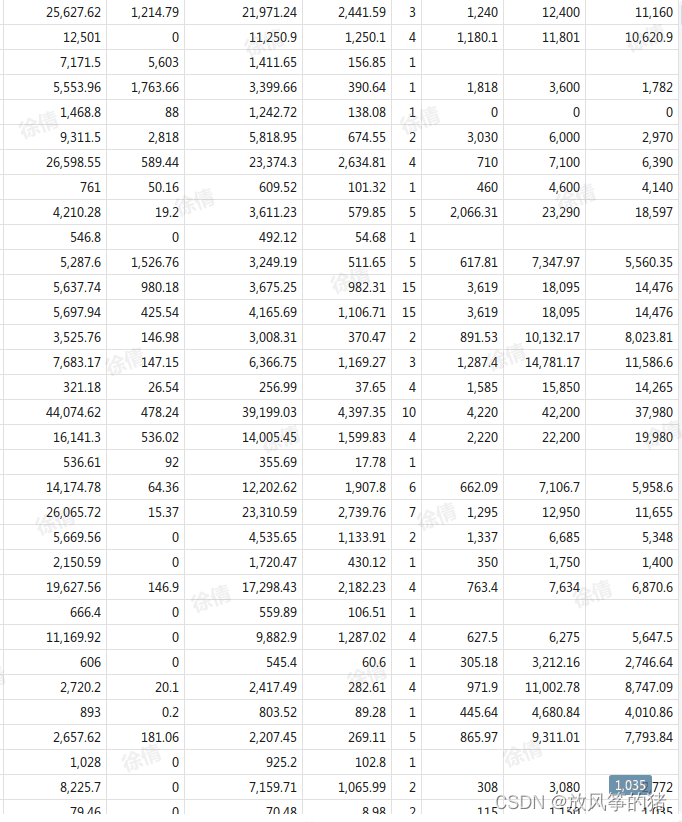
识别处理的表格,可以看到,效果是非常好的
获取KEY
百度智能云 (baidu.com)
产品——文字识别——通用场景
去领取

通用场景OCR——全部——0元领取
去创建
填应用名称——全选——最下面应用描述——立即创建——返回应用列表
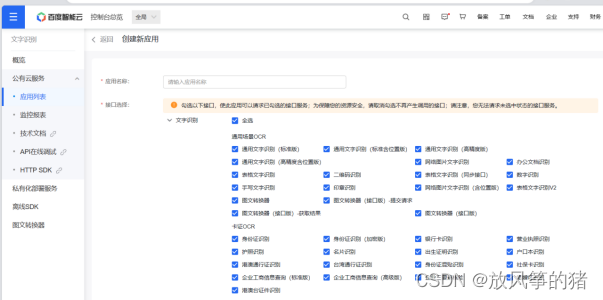
这两个key分别复制到main_GUI中的client_id和client_secret

第一步我们获取access_token
import requests
import json
import base64
import time
def get_access_token():
client_id = '你的apikey'
client_secret = '你的Secret Key'
# client_id 为官网获取的AK, client_secret 为官网获取的SK
host = 'https://aip.baidubce.com/oauth/2.0/token?grant_type=client_credentials&client_id={}&client_secret={}'.format(
client_id, client_secret)
response = requests.get(host).text
data = json.loads(response)
access_token = data['access_token']
return access_token
# 获取返回信息
第二步我们获取是否识别成功的json数据
如果成功识别成功会给你一个request_id,用这个来获取excel表,也可以选择获取json数据(注意图片一点要转为base64编码,支持PNG、JPG、JPEG、BMP、TIFF、PNM、WebP)
#在这里我把文件路径放在了函数里面,可以放在外面,也可以做一个循环,识别一个文件夹里面的所有图片。
def get_info(access_token):
request_url = "https://aip.baidubce.com/rest/2.0/solution/v1/form_ocr/request"
# 二进制方式打开图片文件
f = open('你需要识别的文件', 'rb')
img = base64.b64encode(f.read())#base64编码
params = {"image": img}
request_url = request_url + "?access_token=" + access_token
headers = {'content-type': 'application/x-www-form-urlencoded'}
response = requests.post(request_url, data=params, headers=headers)
# if response:
# print(response.json())
data_1 = response.json()
return data_1
第三步我们获取excel表。
如果你的result_type是excel,则会给你返回一个excel网页连接,如果是json,则会返回json数据
def get_excel(requests_id, access_token):
headers = {'content-type': 'application/x-www-form-urlencoded'}
pargams = {
'request_id': requests_id,
'result_type': 'excel'
}
url = 'https://aip.baidubce.com/rest/2.0/solution/v1/form_ocr/get_request_result'
url_all = url + "?access_token=" + access_token
res = requests.post(url_all, headers=headers, params=pargams)#访问链接获取excel下载页
info_1 = res.json()['result']['ret_msg']
excel_url=res.json()['result']['result_data']
excel_1=requests.get(excel_url).content
with open('识别结果.xls','wb+') as f:
f.write(excel_1)
print(info_1)
完整代码
下面是可以批量处理图片以及有一个GUI界面的代码
import os
import requests
import json
import base64
import time
import tkinter as tk
from tkinter import filedialog
from tkinter import ttk
# 获取access_token
def get_access_token():
client_id = '你的apikey'
client_secret = '你的apikey'
# client_id 为官网获取的AK, client_secret 为官网获取的SK
host = 'https://aip.baidubce.com/oauth/2.0/token?grant_type=client_credentials&client_id={}&client_secret={}'.format(
client_id, client_secret)
response = requests.get(host).text
data = json.loads(response)
access_token = data['access_token']
return access_token
# 获取识别结果
def get_info(access_token, image):
request_url = "https://aip.baidubce.com/rest/2.0/solution/v1/form_ocr/request"
# 二进制方式打开图片文件
img = base64.b64encode(image) # base64编码
params = {"image": img}
request_url = request_url + "?access_token=" + access_token
headers = {'content-type': 'application/x-www-form-urlencoded'}
response = requests.post(request_url, data=params, headers=headers)
data_1 = response.json()
return data_1
# 获取excel
def get_excel(requests_id, access_token, image_file, output_dir):
headers = {'content-type': 'application/x-www-form-urlencoded'}
pargams = {
'request_id': requests_id,
'result_type': 'excel'
}
url = 'https://aip.baidubce.com/rest/2.0/solution/v1/form_ocr/get_request_result'
url_all = url + "?access_token=" + access_token
res = requests.post(url_all, headers=headers, params=pargams) # 访问链接获取excel下载页
info_1 = res.json()['result']['ret_msg']
excel_url = res.json()['result']['result_data']
excel_1 = requests.get(excel_url).content
excel_name = '第{}.xlsx'.format(image_file.split('.')[0])
excel_path = os.path.join(output_dir, excel_name)
with open(excel_path, 'wb+') as f:
f.write(excel_1)
print('图片 {} 处理完成'.format(image_file))
print(info_1)
def process_images(input_dir, output_dir, progress_bar):
access_token = get_access_token()
image_files = os.listdir(input_dir) # 获取文件夹中的所有图片文件
total_images = len(image_files)
for i, image_file in enumerate(image_files):
image_path = os.path.join(input_dir, image_file)
with open(image_path, 'rb') as f:
image = f.read()
data_1 = get_info(access_token, image)
try:
requests_id = data_1['result'][0]['request_id']
if requests_id != '':
print('识别完成')
except:
print('识别错误')
print('正在获取excel')
time.sleep(10) # 延时十秒让网页图片转excel完毕,excel量多的话,转化会慢,可以延时长一点
get_excel(requests_id, access_token, image_file, output_dir)
progress = (i + 1) / total_images * 100
progress_bar['value'] = progress
progress_bar.update()
def select_input_dir():
input_dir = filedialog.askdirectory()
input_dir_entry.delete(0, tk.END)
input_dir_entry.insert(tk.END, input_dir)
def select_output_dir():
output_dir = filedialog.askdirectory()
output_dir_entry.delete(0, tk.END)
output_dir_entry.insert(tk.END, output_dir)
def start_processing():
input_dir = input_dir_entry.get()
output_dir = output_dir_entry.get()
progress_bar['value'] = 0
progress_bar.update()
process_images(input_dir, output_dir, progress_bar)
progress_bar['value'] = 100
progress_bar.update()
# 创建GUI窗口
window = tk.Tk()
window.title("图片处理")
window.geometry("400x250")
# 输入地址
input_dir_label = tk.Label(window, text="输入地址:")
input_dir_label.pack()
input_dir_entry = tk.Entry(window, width=40)
input_dir_entry.pack()
input_dir_button = tk.Button(window, text="选择文件夹", command=select_input_dir)
input_dir_button.pack()
# 输出地址
output_dir_label = tk.Label(window, text="输出地址:")
output_dir_label.pack()
output_dir_entry = tk.Entry(window, width=40)
output_dir_entry.pack()
output_dir_button = tk.Button(window, text="选择文件夹", command=select_output_dir)
output_dir_button.pack()
# 进度条
progress_bar = ttk.Progressbar(window, orient='horizontal', length=300, mode='determinate')
progress_bar.pack()
# 开始处理按钮
start_button = tk.Button(window, text="开始处理", command=start_processing)
start_button.pack()
# 运行GUI窗口
window.mainloop()参考:
(1条消息) Python调用百度云API识别表格识别_调用百度接口识别表格_白胖胖宋棒棒的博客-CSDN博客