ArrayList底层的实现原理
初始化后ArrayList添加元素的步骤
首先计算数组的容量,如果当前数组已使用长度+1后的大于当前的数组长度,则调用grow方法扩容(原来的1.5倍),确保新增的数据有地方存储之后,则添加元素到size的位置上。返回添加成功布尔值。
ArrayList list=new ArrayList(10)中的list扩容几次

数组与List之间的转换

用Arrays.asList转List后,如果修改了数组内容,list受影响吗List用toArray转数组后,如果修改了List内容,数组受影响吗?
用Arrays.asList转List后,如果修改了数组内容,list会受影响,因为在集合的构造器中,数组和List集合指向同一个地址。
List用toArray转数组后,如果修改了List内容,数组不受影响,因为底层他是数组的拷贝,跟原来的元素就没关系了。
链表
单向链表和双向链表的区别
单向链表只有一个方向,结点只有后继指针next。
双向链表有两个方向,结点有后继指针next和前驱指针prev。
链表操作数据的时间复杂度多少

ArrayList和LinkedList的区别是什么
1、底层数据结构:ArrayList是动态数组实现的,更节省空间,LinkedList是双向链表实现的,更占用内存。
2、操作数据的效率:
查找效率,LinkedList的时间复杂度是O(n),对于ArrayList,给定下标的时间复杂度是O(1),下标未知的时间复杂度是O(n)。
插入删除效率,对于LinkedList,在首尾的效率为O(1),其他位置是O(n),对于ArrayList,首部的效率为O(1),其他位置是O(n)。
3、线程安全:
ArrayList和LinkedList都不是线程安全的。
有两种方法使其线程安全:
第一种:在方法内部使用,局部变量则是线程安全的。
第二种:将其转换为线程安全的集合。
HashMap实现原理
HashMap的jdk1.7和jdk1.8的区别
jdk1.7的HashMap采用数组加链表的方式。jdk1.8的HashMap采用数组加链表加红黑树的方式。当数组长度大于64并且链表长度大于8时,链表转换为红黑树。
HashMap的put方法的具体流程
-
首先,
put方法接收两个参数:键(key)和值(value)。根据键的哈希值,确定要将键值对插入到HashMap的哪个桶(bucket)中。 -
如果要插入的桶为空,直接将键值对作为新的桶节点插入该位置即可。
-
如果要插入的桶不为空,即发生了哈希冲突,根据键的哈希值和equals方法进行比较来判断键是否已经存在于桶中。
-
如果存在相同的键,则更新对应键的值为新的值。
-
如果不存在相同的键,则将新的键值对作为桶的新节点插入到链表的头部或红黑树中。
-
插入完成后,如果数组长度大于64并且链表长度大于8时,链表转换为红黑树,以提高查询效率。
-
最后,如果插入操作导致HashMap的大小超过了负载因子(通常为0.75)乘以容量的阈值,就会触发扩容操作,重新调整HashMap的容量,以保持较低的哈希冲突率。
HashMap的扩容机制
-
当HashMap中存储的元素数量达到负载因子(load factor)乘以当前容量的阈值时,就会触发扩容操作。扩容时,HashMap会创建一个新的桶数组,其容量是旧数组的两倍。
-
接下来,HashMap会遍历原来的桶数组中的每个桶,并将桶中的元素重新分配到新的桶数组中的相应位置。重新分配的过程会根据键的哈希值重新计算桶的位置。
-
在重新分配元素的过程中,如果原来的桶中只有一个元素,那么该元素可以直接放入新的桶中。如果原来的桶中有多个元素,会涉及到链表或红黑树的重组操作,以保持元素在新的桶中的相对顺序。
-
扩容完成后,HashMap的容量就会更新为新的容量,并且新的桶数组会取代原来的桶数组成为HashMap的内部存储结构。




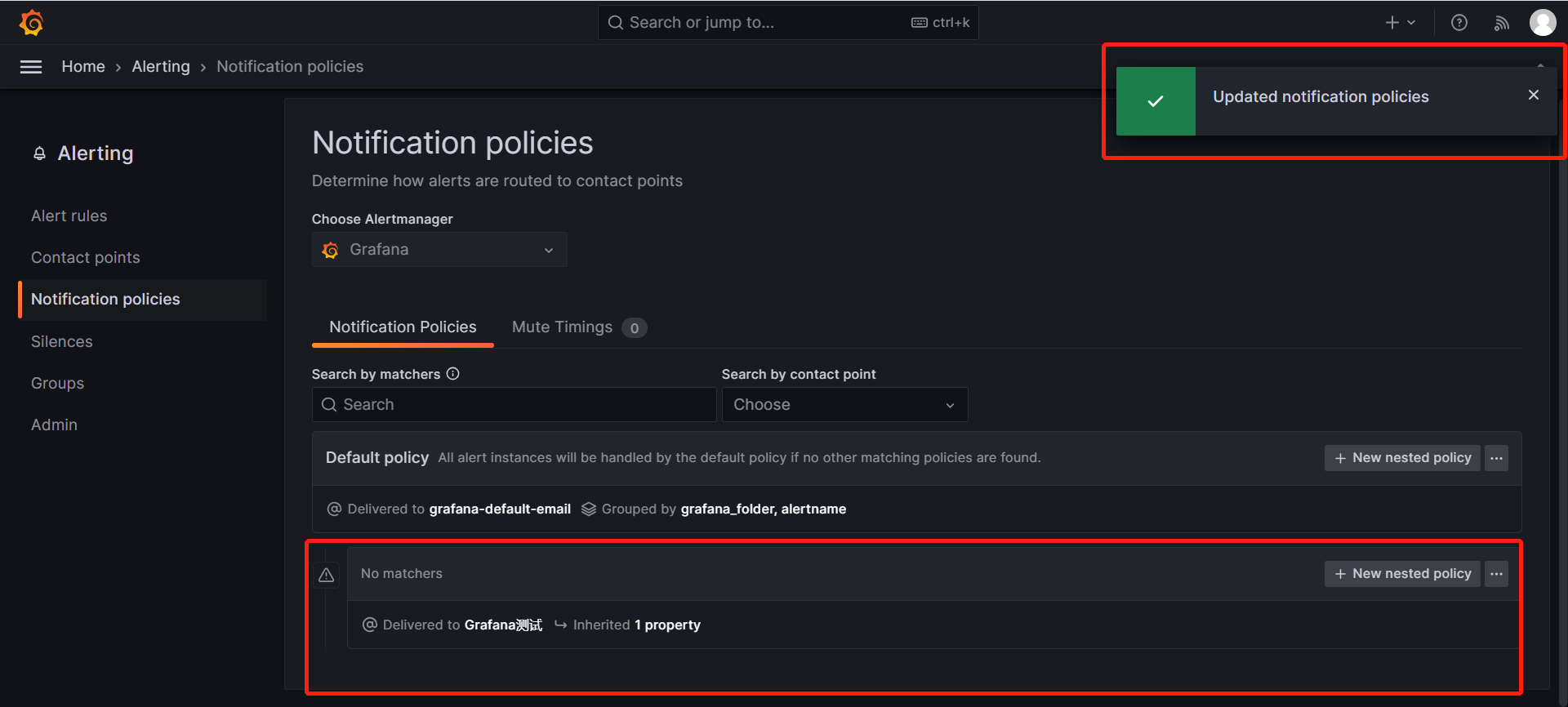
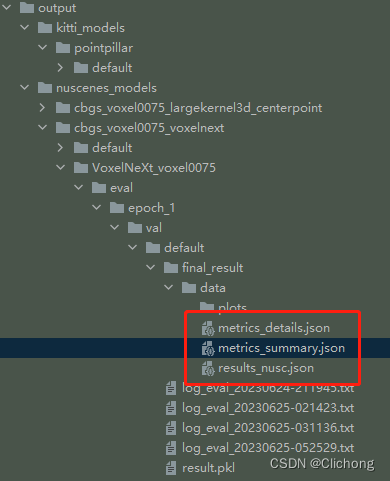
![[MMDetection]测试模型](https://img-blog.csdnimg.cn/4572b274a4b748e38ac3ab1f2ecf7732.png)