业务场景:当前业务模块中,有个查询产品直通率接口,随着数据量的递增,百万级数据,并且需要并表的情况下,那么返回数据就会开始变慢,而在数据层方面,已经比较难去做进一步的sql优化,那么我们最终就尝试开启多线程,并行任务
当然这里也可以有其他方式,比如前面提到的一篇定时任务文章,可以根据业务的情况,定期的预先跑出查询结果的数据,对应的数据建立一张新表存储,这样每次就是直接取这个单表,效率也可以得到提升【业务功能篇17】Springboot +shedlock锁 实现定时任务_springboot定时任务加锁_studyday1的博客-CSDN博客
一、配置线程池
自定义线程池config类并实现AsyncConfigurer接口,重写public Executor getAsyncExecutor() {}构造方法,自定义线程池,若不重写会使用默认的线程池。 这里我定义的线程方法名并不是其接口方法,也可以识别,在我们需要进行多线程设置的方法加注解 @Async("自定义方法名")
- Runtime.getRuntime().availableProcessors() :获取电脑的处理器数量,一般电脑一个处理器有两个逻辑线程
- executor.setCorePoolSize(num * 2 + 1):核心线程数最好设置为电脑的逻辑线程总数 + 1,达到最大化利用处理器
- 类注解添加 @EnableAsync,表示该bean配置类开启了多线程任务
- @Bean在配置类中使用
1.当配置类中的方法存在这个注解时,这个注解会将方法的返回值放入ioc容器中去。
2.当@Bean标注的方法中有参数的时候,一般会和Qualifier(“beanId”)一起使用,会去ioc容器中寻找该类型的bean 作为参数注入进该方法中。
package com.config;
import lombok.extern.slf4j.Slf4j;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.context.annotation.Primary;
import org.springframework.scheduling.annotation.AsyncConfigurer;
import org.springframework.scheduling.annotation.EnableAsync;
import org.springframework.scheduling.concurrent.ThreadPoolTaskExecutor;
import java.util.concurrent.ThreadPoolExecutor;
/**
* 线程池配置
*
*/
@Slf4j
@Configuration
@EnableAsync
public class ThreadConfigurer implements AsyncConfigurer {
/**
* taskExecutor
*
* @return ThreadPoolTaskExecutor
*/
@Primary
@Bean
public ThreadPoolTaskExecutor taskExecutor() {
ThreadPoolTaskExecutor executor = new ThreadPoolTaskExecutor();
//获取电脑的处理器数量,一般电脑一个处理器有两个逻辑线程
int num = Runtime.getRuntime().availableProcessors();
// 核心线程数目 核心线程数最好设置为电脑的逻辑线程总数 + 1,达到最大化利用处理器
executor.setCorePoolSize(num * 2 + 1);
// 指定最大线程数
executor.setMaxPoolSize(200);
// 队列中最大的数目
executor.setQueueCapacity(100);
// 线程名称前缀
executor.setThreadNamePrefix("taskExecutor-");
// 拒绝策略:不在新线程中执行任务,而是由调用者所在的线程来执行
executor.setRejectedExecutionHandler(new ThreadPoolExecutor.CallerRunsPolicy());
// 当调度器shutdown被调用时等待当前被调度的任务完成
executor.setWaitForTasksToCompleteOnShutdown(true);
// 线程空闲后的最大存活时间
executor.setKeepAliveSeconds(60);
// 线程池初始化
executor.initialize();
return executor;
}
}
实现解析:
- Springboot中已经有集成的ThreadPoolTaskExecutor线程池可以供调用(注意区分Java自带的ThreadPoolExecutor),虽然2种线程池的提供的具体方法不一定一样,但是调度线程过程原理是通用,下面贴出ThreadPoolExecutor的调度线程过程作为创建ThreadPoolTaskExecutor的参考。
-
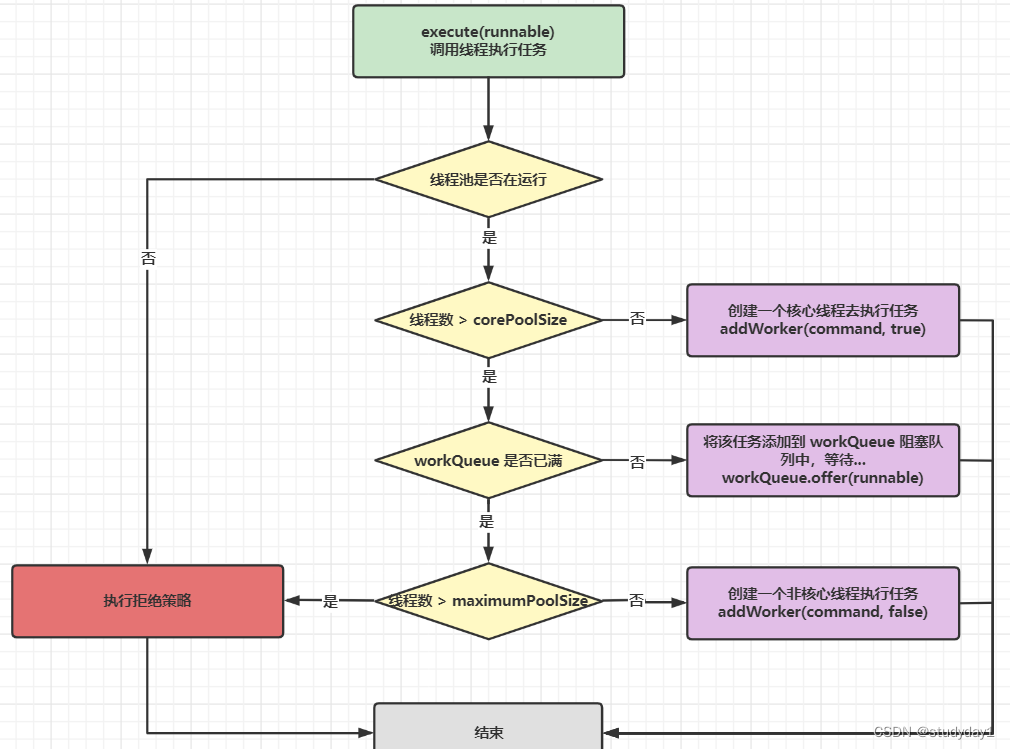
简单来说,在执行execute()方法时如果状态一直是RUNNING时,的执行过程如下:
如果workerCount < corePoolSize,则创建并启动一个线程来执行新提交的任务;
如果workerCount >= corePoolSize,且线程池内的阻塞队列未满,则将任务添加到该阻塞队列中;
如果workerCount >= corePoolSize && workerCount < maximumPoolSize,且线程池内的阻塞队列已满,则创建并启动一个线程来执行新提交的任务;
如果workerCount >= maximumPoolSize,并且线程池内的阻塞队列已满, 则根据拒绝策略来处理该任务, 默认的处理方式是直接抛异常,而我们设置的拒绝策略是交给调用者所在线程执行,不抛异常。
二、@Async配置需要进行多线程任务
-
@Async("taskExecutor") 表示异步 通过@Async注解表明该方法是异步方法,如果注解在类上,那表明这个类里面的所有方法都是异步的,这里注入了mapper,执行时间相对较长的接口,进行编码 - 若异步方法需要返回值,使用Future<String>、new AsyncResult<>()
- AsyncResult是异步方式,异步主要用于调用的代码需要长时间运行,才能返回结果的时候,可以不阻塞调用者。
- 使用@Async的返回,代码中通常new AsyncResult<返回类型>(返回值),方法中返回类型的Future。AsyncResult类实现了ListenableFuture接口,ListenableFuture实现了Future接口
注意要点:
- 在并发编程中,我们经常需要用非阻塞的模型,Java 默认多线程的三种实现中,继承 Thread 类和实现 Runnable 接口是异步并且主调函数是无法获取到返回值的。通过实现 Callback 接口,并用 Future 可以来接收多线程的执行结果
- Future 接收一个可能还没有完成的异步任务的结果,针对这个结果可以添加 Callable 以便任务执行成功或失败后作出相应的操作
- 采用 Future 修改的异步方法,在每次被异步调用以后会马上返回(无论一步方法体是否执行完成),Future 就会监听异步任务执行状态(成功、失败),等到执行完成以后,就能通过 Future.get() 方法获取到异步返回的结果
- 也就是说,如果批量调用采用 Future 修饰的异步方法,程序不会阻塞等待,然后再遍历 Future 列表,即可获取到所有的异步结果(Future 的内部机制是等所有的异步任务完成了才进行遍历), 这种请求耗时只会略大于耗时最长的一个 Future 修饰的方法
1、在方法上使用该 @Async 注解,申明该方法是一个异步任务。
2、在类上使用该 @Async 注解,申明该类中的所有方法都是异步任务。
3、使用此注解的方法的类对象,必须是spring管理下的bean对象。
4、要想使用异步任务,需要在主启动类或者@configure注解类上开启异步配置,即,配置上 @EnableAsync 注解。对于Spring注解 @Async,Spring是以配置文件的形式来开启 @Async,而SpringBoot则是以注解 @EnableAsync的方式开启。
5、异步方法使用注解 @Async 的返回值只能为 void 或者 Future。
6、@Async 失效处理:
异步方法使用static修饰。不要定义为static类型,这样异步调用不会生效。
方法必须是public方法。
标注@Async注解的方法和调用的方法一定不能在同一个类下,也就是说,方法一定要从另一个类中调用,也就是从类的外部调用,类的内部调用是无效的,因为@Transactional和@Async注解的实现都是基于Spring的AOP,而AOP的实现是基于动态代理模式实现的。那么注解失效的原因就很明显了,有可能因为调用方法的是对象本身而不是代理对象,因为没有经过Spring容器。
使用@Async注解的方法的所在类,一定要交给spring容器来管理。用@Component注解(或其他注解)。
7、若没有通过实现 AsyncConfigurer 接口来自定义线程池,则使用的是Spring默认的线程池 SimpleAsyncTaskExecutor。8、实现 AsyncConfigurer 接口,主要作用:
自定义线程池。
异常处理。
9、实现 AsyncConfigurer 接口并重写getAsyncExecutor()方法,@Async 默认使用的是重写方法中的线程池。当然也可以自定义方法名称XXX,然后在多线程任务调用时要加上对应名称,@Async("xxx"),才能找到该bean10、@Async("xxx"),可以使用指定线程池xxx。
11、若有两个实现类实现 AsyncConfigurer 接口,则启动报错。所以说还是比较局限。
12、@Async("xxx")指定使用了其他线程池,出现异常,还是使用的实现 AsyncConfigurer 接口的实现类中的异常处理方法(如果重写了)。也是比较局限(当其他业务不想使用此处理方式时)。
13、异步任务的事务问题:@Async注解的方法由于是异步执行的,在其进行数据库的操作,将无法控制事务管理。 解决办法:可以把@Transactional注解放到内部的需要进行事务的方法上。
FUTURE常用方法
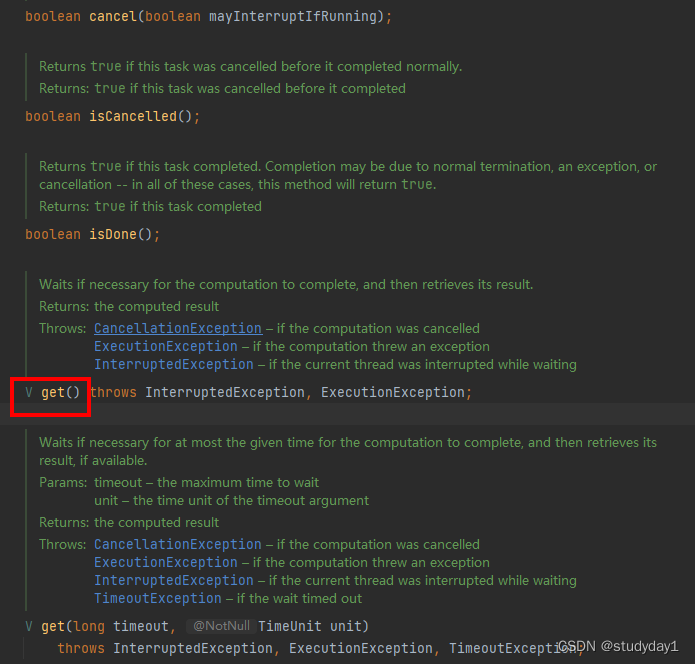
- isDone() 返回Boolean类型值,用来判断该异步任务是否执行完成,如果执行完成,则返回true,如果未执行完成,则返回false.
- cancel(boolean mayInterruptRunning) 返回boolean类型值,参数也是一个boolean类型的值,用来传入是否可以打断当前正在执行的任务。如果参数是true且当前任务没有执行完成 ,说明可以打断当前任务,那么就会返回true,如果当前任务还没有执行,那么不管参数是true还是false,返回值都是true,如果当前任务已经完成,那么不管参数是true还是false,那么返回值都是false,如果当前任务没有完成且参数是false,那么返回值也是false。总结下来就是:1.如果任务还没执行,那么如果想取消任务,就一定返回true,与参数无关。2.如果任务已经执行完成,那么任务一定是不能取消的,所以此时返回值都是false,与参数无关。3.如果任务正在执行中,那么此时是否取消任务就看参数是否允许打断(true/false)。
- isCancelled() 返回的是boolean类型,如果是上面总结的第三种情况,这才是真正意义上有机会被取消的任务,那么此时如果上面的方法返回的是true,那么说明任务取消成功了,则这个方法返回的也就是true。
- get() 返回的是在异步方法中最后return 的那个对象中的value的值。主要是通过里面的get()方法来获取异步任务的执行结果,这个方法是阻塞的,直到异步任务执行完成。
- get(long timeout,TimeUnit unit) 这个方法和get()的功能是一样的(在方法执行没有超时的情况下效果是一样的),只不过这里参数中设置了超时时间,因为get()在执行的时候是需要等待回调结果的,是阻塞在那里的,如果不设置超时时间,它就阻塞在那里直到有了任务执行完成。我们设置超时时间,就可以在当前任务执行太久的情况下中断当前任务,释放线程,这样就不会导致一直占用资源。参数一是时间的数值,参数二是参数一的单位,可以在TimeUnit这个枚举中选择单位。如果任务执行超时,则抛出TimeOut异常,返回的message就是null。
package com.thread.callable;
import com.qualitybigdata.model.BoardQueryParam;
import com.service.dao.mapper.BoardPassMapper;
import org.springframework.scheduling.annotation.Async;
import org.springframework.scheduling.annotation.AsyncResult;
import org.springframework.stereotype.Component;
import org.springframework.transaction.annotation.Transactional;
import java.util.List;
import java.util.Map;
import java.util.concurrent.Future;
import javax.annotation.Resource;
/**
* BoardPassThread
*
*/
@Component
public class BoardPassThread {
@Resource
private BoardPassMapper boardPassMapper;
/**
* getBoardData
*
* @param field field
* @param startDate startDate
* @param endDate endDate
* @param queryParam queryParam
* @return Future<List<Map<String,String>>>
*/
@Async("taskExecutor")
@Transactional
public Future<List<Map<String, String>>> getBoardData(String field, String startDate, String endDate,
BoardQueryParam queryParam) {
return new AsyncResult<>(field.equals("yearMon")
? boardPassMapper.getBoardDataByTime(startDate, endDate, queryParam)
: boardPassMapper.getBoardData(startDate, endDate, field, queryParam));
}
}
下面就把对应的业务代码分层贴上,业务需求是查询产品直通率的同时,获取当前条件年月对应的去年的数据 比如查询23年1-6月,同时也需要或者22年1-6月,这样数据量较大的情况下,接口返回较慢,所以我们采用多线程,按照时间分成两个子线程,一个查询当前年月,一个查询去年对应的年月数据,从而一定程度提升性能效率
controller层
package com.qualitybigdata.service;
import org.springframework.web.bind.annotation.*;
import com.qualitybigdata.delegate.BoardPassDelegate;
import org.springframework.validation.annotation.Validated;
import org.springframework.beans.factory.annotation.Autowired;
import com.qualitybigdata.model.BoardQueryParam;
import com.qualitybigdata.model.ResponseVo;
@RestController
@RequestMapping(value = "/boardPass/board", produces = {"application/json;charset=UTF-8"})
@Validated
public class BoardPassController {
@Autowired(required=false)
private BoardPassDelegate delegate;
@RequestMapping(
value = "",
produces = { "application/json" },
method = RequestMethod.POST)
public ResponseVo getBoardData( @RequestParam(value = "queryMethod", required = true) String queryMethod,
@RequestBody BoardQueryParam queryParam)
{
return delegate.getBoardData(queryMethod
, queryParam);
}
}
service 层 接口
package com.qualitybigdata.delegate;
import com.qualitybigdata.model.BoardQueryParam;
import com.qualitybigdata.model.ResponseVo;
public interface BoardPassDelegate {
ResponseVo getBoardData(String queryMethod,
BoardQueryParam queryParam) ;
}
service 层 接口实现类
package com.qualitybigdata.impl;
import com.qualitybigdata.delegate.BoardPassDelegate;
import com.qualitybigdata.model.BoardQueryParam;
import com.qualitybigdata.model.ResponseVo;
import com.thread.callable.BoardPassThread;
import com.utils.ResponseUtils;
import lombok.extern.slf4j.Slf4j;
import org.springframework.stereotype.Service;
import javax.annotation.Resource;
import java.util.Arrays;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import java.util.concurrent.BlockingQueue;
import java.util.concurrent.ExecutionException;
import java.util.concurrent.Future;
import java.util.concurrent.LinkedBlockingQueue;
/**
* 直通率数据实现类
*
*/
@Slf4j
@Service
public class BoardPassDelegateImpl implements BoardPassDelegate {
@Resource
BoardPassThread boardPassThread;
/**
* 获取数据
*
* @param queryMethod queryMethod
* @param queryParam queryParam
* @return ResponseVo
*/
@Override
public ResponseVo getBoardData(String queryMethod
, BoardQueryParam queryParam) {
// 验证查询参数是否符合规范
String valid = validBoardQueryParam(queryParam);
if (!valid.equals("")) {
return ResponseUtils.errorResponse(null, valid);
}
// 将查询参数转为查询字段
String field;
switch (queryMethod) {
case "0":
field = "yearMon";
break;
case "1":
field = "oper_group";
break;
case "2":
field = "factory_code";
break;
case "3":
field = "board_item";
break;
default:
return ResponseUtils.errorResponse(null, "非法的参数传入");
}
// 前端传来的值为111,222,333逗号分隔的字符串,需要转为list
if (queryParam.getBoardItem() != null) {
queryParam.setBoardItemList(Arrays.asList(queryParam.getBoardItem().trim().split(",")));
}
// 创建阻塞队列,多线程查询 阻塞指的是等到所有线程执行完毕,才会执行后面的代码 两个线程是同时执行
BlockingQueue<Future<List<Map<String, String>>>> queue = new LinkedBlockingQueue<>();
// 查询今年数据
queue.add(boardPassThread.getBoardData(field, queryParam.getStartDate(), queryParam.getEndDate(), queryParam));
// 查询去年数据
queryParam.setStartDate(getDate(queryParam.getStartDate()));
queryParam.setEndDate(getDate(queryParam.getEndDate()));
queue.add(boardPassThread.getBoardData(field, queryParam.getStartDate(), queryParam.getEndDate(), queryParam));
Map<String, List<Map<String, String>>> result = new HashMap<>(8);
try {
//queue.take取出队列的第一个元素,并将该元素从队列中移除
//get指的是等待线程执行完毕,获取线程的执行结果
result.put("currentYear", queue.take().get());
result.put("lastYear", queue.take().get());
} catch (InterruptedException | ExecutionException e) {
log.error(e.toString());
return ResponseUtils.errorResponse(null, "无法获取数据");
}
return ResponseUtils.successResponse(result, "");
}
/**
* getDate
*
* @param date date
* @return String
*/
private String getDate(String date) {
// 时间设置为去年
String[] dates = date.split("-");
Integer year = Integer.parseInt(dates[0]) - 1;
return year + "-" + dates[1];
}
/**
* validBoardQueryParam
*
* @param queryParam queryParam
* @return String
*/
private String validBoardQueryParam(BoardQueryParam queryParam) {
if (queryParam.getStartDate() == null || queryParam.getEndDate() == null) {
return "请输入起止时间区间";
} else {
// 例如查询区间为2022-1至2022-8,则sql处理为2022-1-1 <= date < 2022-9-1(需要对endDate的月份加1)
String[] dates = queryParam.getEndDate().split("-");
int month = Integer.parseInt(dates[1]) + 1 > 12 ? 1 : Integer.parseInt(dates[1]) + 1;
int year = Integer.parseInt(dates[1]) + 1 > 12 ? Integer.parseInt(dates[0]) + 1 : Integer.parseInt(dates[0]);
queryParam.setEndDate(year + "-" + month);
}
return "";
}
}
任务队列:
BlockingQueue<Future<List<Map<String, String>>>> queue = new LinkedBlockingQueue<>();
阻塞队列,用来存储线程池等待执行的任务,均为线程安全。这里我们需要把线程任务添加到这个队列当中,才能来执行多线程。它一般分为直接提交队列、有界任务队列、无界任务队列、优先任务队列几种,包含以下 7 种类型:
ArrayBlockingQueue:一个由数组结构组成的有界阻塞队列。
LinkedBlockingQueue:一个由链表结构组成的有界阻塞队列。
SynchronousQueue:一个不存储元素的阻塞队列,即直接提交给线程不保持它们。
PriorityBlockingQueue:一个支持优先级排序的无界阻塞队列。
DelayQueue:一个使用优先级队列实现的无界阻塞队列,只有在延迟期满时才能从中提取元素
LinkedTransferQueue:一个由链表结构组成的无界阻塞队列。与SynchronousQueue类似,还含有非阻塞方法。
LinkedBlockingDeque:一个由链表结构组成的双向阻塞队列。
有界的任务队列:有界的任务队列可以使用 ArrayBlockingQueue 实现
ThreadPoolExecutor threadPool = new ThreadPoolExecutor(1, 2, 1000, TimeUnit.MILLISECONDS, new ArrayBlockingQueue<Runnable>(10),Executors.defaultThreadFactory(),new ThreadPoolExecutor.AbortPolicy());
1- 使用 ArrayBlockingQueue 有界任务队列,若有新的任务需要执行时,线程池会创建新的线程,直到创建的线程数量达到 corePoolSize 时,则会将新的任务加入到等待队列中。若等待队列已满,即超过 ArrayBlockingQueue 初始化的容量,则继续创建线程,直到线程数量达到 maximumPoolSize 设置的最大线程数量,若大于 maximumPoolSize,则执行拒绝策略。在这种情况下,线程数量的上限与有界任务队列的状态有直接关系,如果有界队列初始容量较大或者没有达到超负荷的状态,线程数将一直维持在 corePoolSize 以下,反之当任务队列已满时,则会以 maximumPoolSize 为最大线程数上限
无界的任务队列:有界任务队列可以使用 LinkedBlockingQueue 实现
ThreadPoolExecutor threadPool = new ThreadPoolExecutor(1, 2, 1000, TimeUnit.MILLISECONDS, new LinkedBlockingQueue<Runnable>(),Executors.defaultThreadFactory(),new ThreadPoolExecutor.AbortPolicy());
1- 使用无界任务队列,线程池的任务队列可以无限制的添加新的任务,而线程池创建的最大线程数量就是你 corePoolSize 设置的数量,也就是说在这种情况下 maximumPoolSize 这个参数是无效的,哪怕你的任务队列中缓存了很多未执行的任务,当线程池的线程数达到 corePoolSize 后,就不会再增加了;若后续有新的任务加入,则直接进入队列等待,当使用这种任务队列模式时,一定要注意你任务提交与处理之间的协调与控制,不然会出现队列中的任务由于无法及时处理导致一直增长,直到最后资源耗尽的问题。
dao层 接口
- 多线程任务类中的方法,直接进行调用dao层的接口数据方法,处理响应时间比较慢的接口方法
package com.service.dao.mapper;
import com.qualitybigdata.model.BoardQueryParam;
import com.domain.model.QualityTpySum;
import com.baomidou.mybatisplus.core.mapper.BaseMapper;
import org.apache.ibatis.annotations.Mapper;
import org.apache.ibatis.annotations.Param;
import java.util.List;
import java.util.Map;
/**
* BoardPassMapper
*
*/
@Mapper
public interface BoardPassMapper extends BaseMapper<QualityTpySum> {
/**
* 按时间查询直通率
*
* @param startDate 开始时间
* @param endDate 结束时间
* @param queryParam 查询参数,可以设置开始时间、结束时间、编码、团队、工序和厂商
* @return 直通率列表
*/
List<Map<String, String>> getBoardDataByTime(@Param("startDate") String startDate, @Param("endDate") String endDate,
@Param("queryParam") BoardQueryParam queryParam);
/**
* 按工序、厂商或者编码查询直通率
*
* @param startDate 开始时间
* @param endDate 结束时间
* @param field 查询字段,按工序、厂商或者编码
* @param queryParam 查询参数,可以设置开始时间、结束时间、单板编码、团队、工序和厂商
* @return List
*/
List<Map<String, String>> getBoardData(@Param("startDate") String startDate, @Param("endDate") String endDate,
@Param("field") String field, @Param("queryParam") BoardQueryParam queryParam);
}
dao层 xml映射
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com..energytools.service.dao.mapper.BoardPassMapper">
<select id="getBoardDataByTime" resultType="map">
WITH tab1 AS (
SELECT
date_format( date_sql, '%Y-%m' ) AS yearMon,
1- (sum( DEFECT_QTY )/ sum( INPUT_QTY )) AS ACOL
FROM
DWR_QUALITY_TPY_SUM_F
FORCE INDEX ( date_sql_index )
<where>
<include refid="getBoardDataQuery"></include>
</where>
GROUP BY
date_format( date_sql, '%Y-%m' )
) SELECT
yearMon,
ifnull( round( exp( sum( ln( nullif( ACOL, 0 ))))* 100, 2 ), 100 ) AS BCOL
FROM
tab1
GROUP BY
yearMon
ORDER BY
yearMon
</select>
<select id="getBoardData" resultType="map">
WITH tab1 AS (
SELECT
${field},
1- (sum( DEFECT_QTY )/ sum( INPUT_QTY )) AS ACOL
FROM
DWR_QUALITY_TPY_SUM_F
FORCE INDEX ( date_sql_index )
<where>
${field} is not null
<include refid="getBoardDataQuery"></include>
</where>
GROUP BY
${field}
) SELECT
${field},
ifnull( round( exp( sum( ln( nullif( ACOL, 0 ))))* 100, 2 ), 100 ) AS BCOL
FROM
tab1
GROUP BY
${field}
ORDER BY
${field}
</select>
<sql id="getBoardDataQuery">
<if test="startDate != null">
AND date_sql >= date_format( CONCAT(#{startDate},'-1'), '%Y-%m-%d' )
</if>
<if test="endDate != null">
AND date_sql < date_format( CONCAT(#{endDate},'-1'), '%Y-%m-%d' )
</if>
<if test="queryParam.teamName != null">
AND ( lv1_organization_cn = #{queryParam.teamName}
OR lv2_organization_cn = #{queryParam.teamName} )
</if>
<if test="queryParam.boardItem != null">
AND board_item IN
<foreach collection="queryParam.boardItemList" index="index" item="item" separator="," close=")" open="(">
LTRIM(RTRIM(#{item}))
</foreach>
</if>
<if test="queryParam.operGroupList.size() != 0">
AND oper_group IN
<foreach collection="queryParam.operGroupList" index="index" item="item" separator="," close=")" open="(">
#{item}
</foreach>
</if>
<if test="queryParam.factoryCodeList.size() != 0">
AND factory_code IN
<foreach collection="queryParam.factoryCodeList" index="index" item="item" separator="," close=")" open="(">
#{item}
</foreach>
</if>
</sql>
<cache/>
</mapper>直通率数据表实体类
package com.domain.model;
import com.baomidou.mybatisplus.annotation.TableField;
import com.baomidou.mybatisplus.annotation.TableId;
import com.baomidou.mybatisplus.annotation.TableName;
import lombok.Data;
import lombok.NoArgsConstructor;
import lombok.experimental.Accessors;
import java.time.LocalDateTime;
/**
* TpySum
*
*/
@Data
@NoArgsConstructor
@Accessors(chain = true)
@TableName("dwr_quality_tpy_sum_f")
public class QualityTpySum {
@TableId(value = "id")
private Integer id;
@TableField("task_no")
private String taskNo;
@TableField("board_item")
private String boardItem;
@TableField("date_sql")
private LocalDateTime dateSql;
@TableField("factory_code")
private String factoryCode;
@TableField("source_oper")
private String sourceOper;
@TableField("proc_no")
private String procNo;
@TableField("oper_group")
private String operGroup;
@TableField("factory_area")
private String factoryArea;
@TableField("year")
private String year;
@TableField("calmonth")
private String calmonth;
@TableField("lv0_organization_cn")
private String lv0OrganizationCn;
@TableField("lv1_organization_cn")
private String lv1OrganizationCn;
@TableField("lv2_organization_cn")
private String lv2OrganizationCn;
@TableField("lv3_organization_cn")
private String lv3OrganizationCn;
@TableField("lv4_organization_cn")
private String lv4OrganizationCn;
@TableField("input_qty")
private String inputQty;
@TableField("gd_input_qty")
private String gdInputQty;
@TableField("test_fault_qty")
private String testFaultQty;
@TableField("defect_qty")
private String defectQty;
@TableField("pass_qty")
private String passQty;
}
SQL解析:
-
nullif()函数
NULLIF函数是接受2个参数的控制流函数之一。如果第一个参数等于第二个参数,则NULLIF函数返回NULL,否则返回第一个参数。
NULLIF函数的语法如下:
NULLIF(expression_1,expression_2);
如果expression_1 = expression_2为true,则NULLIF函数返回NULL,否则返回expression_1 。
请注意,NULLIF函数与以下使用CASE的表达式类似:
CASE WHEN expression_1 = expression_2
THEN NULL
ELSE
expression_1
END;EXP(SUM(LN(字段))函数完成累乘- 参考MySQL实现累加、累乘、累减、累除_mysql 累加_鲸鲸说数据的博客-CSDN博客
- 传入的参数在SQL中显示不同
#传入的参数在SQL中显示为字符串(当成一个字符串),会对自动传入的数据加一个双引号。
$传入的参数在SqL中直接显示为传入的值
- force index() 强制索引 表中对时间字段做了索引
如果表中的数据是百万级的,这样查询是比较慢的;虽然你有可能在时间字段上面加了索引,但是在where条件中又破坏了索引;导致索引失效;
可以使用mysql force index() 强制索引来优化查询语句
![[MMDetection]测试模型](https://img-blog.csdnimg.cn/4572b274a4b748e38ac3ab1f2ecf7732.png)