👂 爱要坦荡荡 - 萧潇 - 单曲 - 网易云音乐
👂 武侯祠 - 闫东炜 - 单曲 - 网易云音乐
👂 You Are My Sunshine - Angelika Vee - 单曲 - 网易云音乐
(๑•̀ㅂ•́)و✧ O(∩_∩)O (ง •_•)ง (~﹃~)~zZ ---- 看乐评真是人生一大乐事 ----
目录
🌼4.1 顺序栈
(1)初始化
(2)入栈
(3)出栈
(4)取栈顶元素
🌼4.2 链栈
(1)初始化
(2)入栈
(3)出栈
(4)取栈顶元素
🌼4.3 顺序队列
1. 顺序队列
2. 循环队列
3. 循环队列基本操作
🌼4.4 链队列
🚩题目一 P1739 表达式括号匹配
🚩题目二 Rails
🚩题目三 Matrix Chain Multiplication
🚩题目四 Printer Queue
🚩题目五 Concurrency Simulator
🌼总结
🌼4.1 顺序栈
顺序栈需要2个指针,base指向栈顶,top指向栈底
定义(动态分配)
typedef struct SqStack
{
ElemType *base; //栈底指针
Elemtype *top; //栈顶指针
}SqStack;最大分配空间
//预先分配空间
#define Maxsize 100 //宏定义
const int Maxsize = 100; //常量定义(静态分配)
typedef struct SqStack
{
ElemType data[Maxsize]; //定长数组
int top; //栈顶下标
}SqStack;下面以动态分配空间和int类型为例进行讲解
(1)初始化
第一次用语雀画出来的,挺慢的,以后用熟练了应该可以
初始化一个空栈,动态分配Maxsize大小的空间,S.top和S.base指向该空间基地址
bool InitStack(SqStack &s) //构造一个空栈S
{
S.base = new int[Maxsize]; //为顺序栈分配最大容量Maxsize的空间
if(!S.base) //空间分配失败
return false;
S.top = S.base; //top初始为基地址base, 当前空栈
return true;
}(2)入栈
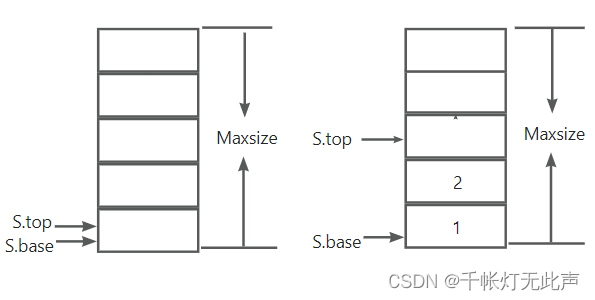
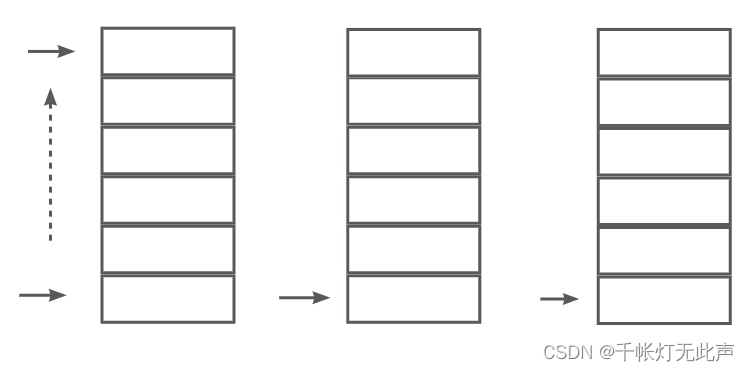
入栈前判断栈是否满了,已满则入栈失败;否则元素放入栈顶,栈顶指针向上移动一个位置(top++) 依次输入1,2,如图所示👆
bool Push(SqStack &S, int e) //入栈
{
if(S.top - S.base == Maxsize) //栈满
return false;
//等价于*S.top = e; S.top++;
*S.top++ = e; //新元素e入栈,栈顶指针+1
return true;
}(3)出栈
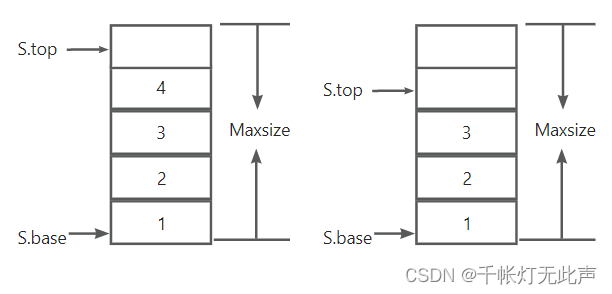
先判断栈为空,空则出栈失败
否则栈顶元素暂存到变量,栈顶指针向下移动一个空间(top--)
栈顶元素位置实际上是S.top - 1
注意,顺序存储中,删除一个元素时,没有销毁该空间。所以4还在原来的位置,不过下次元素进栈时,它只是被覆盖了(相当于出栈,因为栈的元素是S.base ~ S.top - 1)
bool Pop(SqStack &S, int &e)
{
if(S.base == S.top) //栈空
return false;
//等价于--S.top; e = *S.top;
e = *--S.top; //栈顶指针-1后,栈顶元素赋值给e
return true;
}(4)取栈顶元素
将栈顶元素复制一份,栈顶指针未移动,栈内元素个数未变
而出栈,栈顶指针向下移动一个位置,栈内不再包含该元素
int GetTop(SqStack S) //取栈顶元素, 栈顶指针不变
{
if(S.top != S.base) //栈不为空,防止访问不存在的内存区域
return *(S.top - 1); //返回栈顶元素的值
else
return -1;
}🌼4.2 链栈
顺序栈分配的空间是连续的,需要2个指针,base指向栈底,top指向栈顶。
链栈分配的空间不连续,只需要1个栈顶指针。
typedef struct Snode
{
ElemType data; //数据域
struct Snode *next; //指向下一节点的指针
}Snode, *LinkStack; //结构体类型链栈的节点定义类似单链表,但只能在栈顶操作
(1)初始化
初始化空栈,链栈不需要头节点,栈顶指针置空
bool InitStack(LinkStack &S) //构造一个空栈S
{
S = NULL;
return true;
}(2)入栈
新节点压入栈顶,类似摞盘子,将新节点摞到栈顶之上,新节点成为新的栈顶
首先,生成新节点,元素e存入该节点数据域,p指针指向该节点
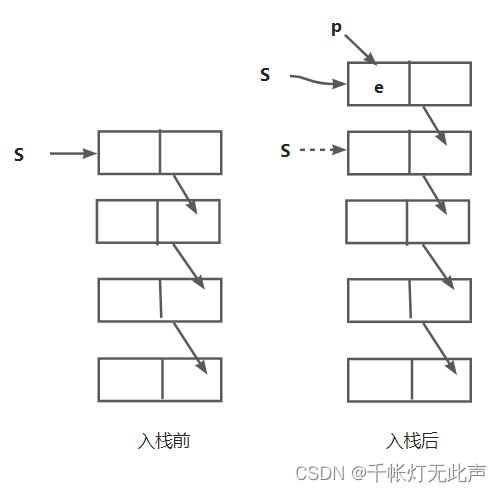
p = new Snode; //生成新节点,p指针指向该节点
p->data = e; //元素e放在新节点数据域新节点插入第1个节点前,然后栈顶指针指向新节点
"p->next = S",将S的地址赋给p的指针域,即新节点p的next指针指向S
"S = p",修改新的栈顶指针为p
bool Push(LinkStack &S, int e) //入栈,栈顶插入e
{
LinkStack p;
p = new Snode; //生成新节点
p->data = e; //e存入新节点的数据域
p->next = S; //新节点p的next指针指向S
S = p; //修改新栈顶指针为p
return true;
}(3)出栈
栈顶元素删除;栈顶指针指向下一节点;释放该节点空间
"p = S",S的地址(原来栈顶地址)赋值给p
"S = S->next",S后继节点地址(下一节点)赋给S
"delete p",释放p指向的节点空间(即原来栈顶的空间)
bool Pop(LinkStack &S, int &e) //出栈,删除栈顶元素,e保存值
{
LinkStack p; //声明节点
if(S == NULL) //栈空
return false;
e = S->data; //出栈前栈顶元素
p = S; //出栈前栈顶地址
S = S->next; //栈顶指针指向下一节点
delete p; //释放原栈顶空间
return true;
}(4)取栈顶元素
区别于出栈,栈顶指针不改变
int GetTop(LinkStack S) //取栈顶元素 不修改栈顶指针
{
if(S != NULL)
return S->data; //返回栈顶的值
else
return -1;
}顺序栈和链栈,基本操作都是常数时间,时间复杂度差不多。
空间复杂度而言:
顺序栈预先分配固定长度空间,容易空间浪费或溢出
链栈每次分配一个节点,除非没有内存,否则不会溢出,但是每个节点需要指针域,结构性开销增加
所以....
若元素个数变化大,采取链栈。否则采用顺序栈(顺序栈应用更为广泛)
🌼4.3 顺序队列
1. 顺序队列
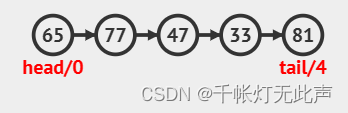
动态分配
typedef struct SqQueue
{
ElemType *base; //空间基地址
int front, rear; //队头和队尾
}SqQueue; //typedef将结构体等价于SqQueue#define Maxsize 100 //预先分配空间👆顺序结构都是如此,需要预先分配空间,因此采取宏定义
静态分配
typedef struct SqQueue
{
ElemType data[Maxsize]; //定产数组
int front, rear; //对头队尾
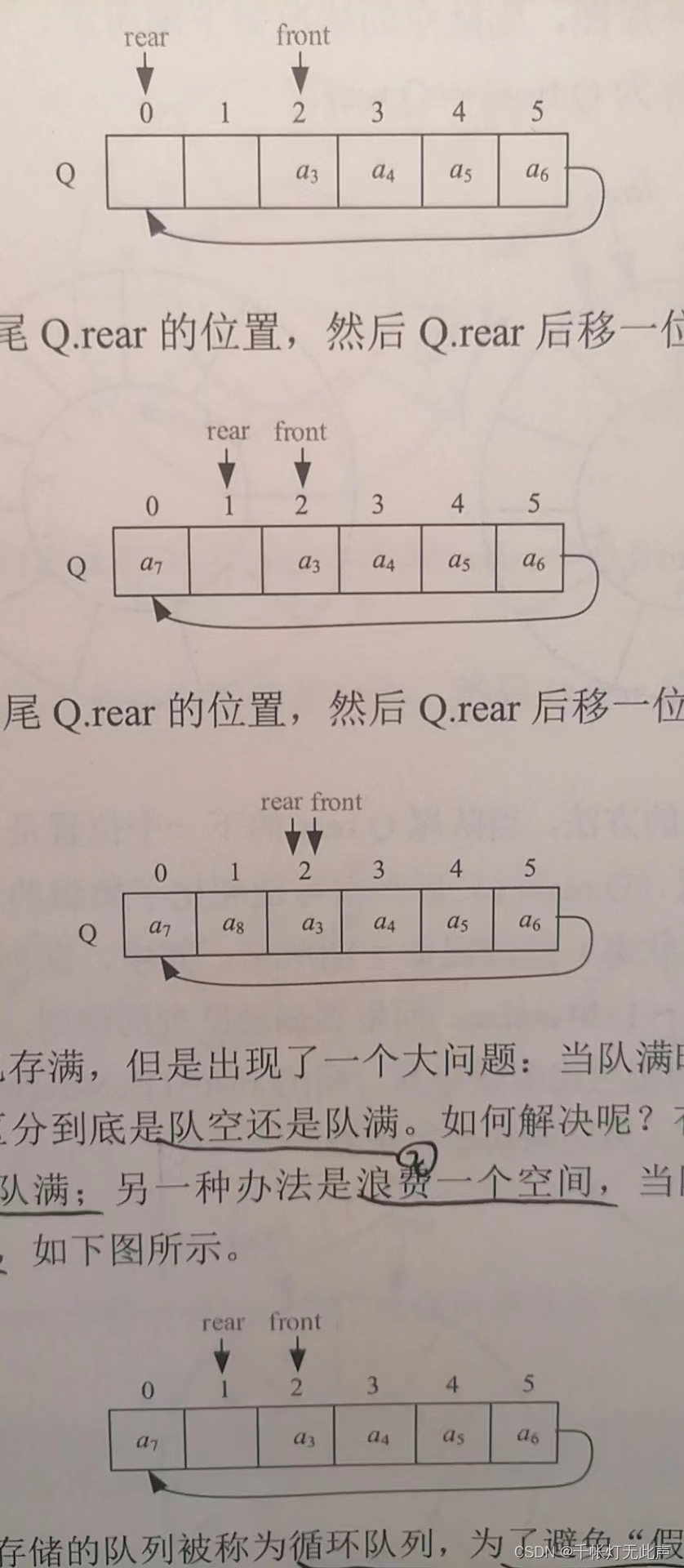
}SqQueue; front, rear记录队头和队尾的下标
 -->
--> -->
--> -->
-->
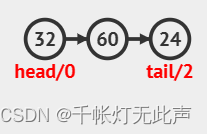
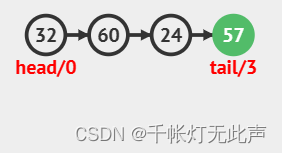
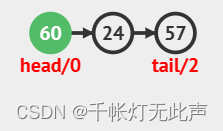
队尾入队,Q.tail++;队头出队,Q.head++
顺序队列存在一个问题,当Q.tail超过数组最大下标时,无法再进队,但是前面由于Q.head++过,存在多余空间,却出现了队满的情况,这种情况即“假溢出”,需要通过循环队列解决(到达尾部又向前存储的队列)
2. 循环队列
循环队列,判断队空 / 队满有2种方法
1,设置flag标记队空队满
2,浪费一个空间,当队尾Q.tail的下一个位置是Q.front时,认为队满
我们采取浪费一个空间的方法
注意! 循环队列无论入队还是出队,在队尾,队头加1后都要进行取余运算,是为了处理临界
(1)队空
Q.front == Q.rear; //Q.rear和Q.front指向同一个位置(2)队满
(Q.rear + 1) % Maxsize == Q.front; //Q.rear后移一位正好是Q.front(3)入队
Q.base[Q.rear] = x; //元素x放入Q.rear所指的空间
Q.rear = (Q.rear + 1) % Maxsize; //Q.rear后移一位base是空间基地址
(4)出队
e = Q.base[Q.front]; //变量e记录Q.front所指元素
Q.front = (Q.front + 1) % Maxsize; //Q.front后移一位(5)队列元素个数
(Q.rear - Q.front + Maxsize) % Maxsize因为采取舍弃一个空间的方法,所以不存在个数 == Maxsize的情况
3. 循环队列基本操作
(1)初始化
bool InitQueue(SqQueue &Q) //引用传参,函数内的改变对函数外有效
{
Q.base = new int[Maxsize]; //分配Maxsize的空间
if(!Q.base) return false; //分配空间失败
Q.front = Q.rear = 0; //队尾和队头为0,队列为空
return true;
}(2)入队
入队先判断队满
bool EnQueue(SqQueue &Q, int e) //入队,将元素e放入Q队尾
{
if((Q.rear + 1) % Maxsize == Q.front) //队尾后移一位 = 队头,队满
return false;
Q.base[Q.rear] = e; //新元素入队尾
Q.rear = (Q.rear + 1) % Maxsize; //队尾后移一位
return true;
}(3)出队
出队先判断队空
bool DeQueue(SqQueue &Q, int &e) //出队,删除Q队头元素,e返回其值
{
if(Q.front == Q.rear)
return true; //队空
e = Q.base[Q.front]; //保存队头元素
Q.front = (Q.front + 1) % Maxsize; //队头后移一位
return true;
}(4)去队头元素
int GetHead(SqQueue Q) //取队头元素,不修改队头
{
if(Q.front != Q.rear) //队列非空
return Q.base[Q.front];
return -1;
}(5)求队列长度
int QueueLength(SqQueue Q)
{
return (Q.rear - Q.front + Maxsize) % Maxsize;
}🌼4.4 链队列
链队列中,节点的结构体定义👇
typedef struct Qnode
{
ElemType data; //数据域
struct Qnode *next; //指针域, 指向下一节点的指针
}Qnode, *Qptr; //prt即pointer指针链队列的结构体定义👇
typedef struct
{
//Qnode为定义好的节点类型
Qnode *front; //头指针
Qnode *rear; //尾指针
}LinkQueue; //typedef将结构体等价于类型名LinkQueue(1)初始化
void InitQueue(LinkQueue &Q) //引用传参
{
Q.front = Q.rear = new Qnode; //创建头节点,尾指针和头指针指向该节点
Q.front->next = NULL;
}(2)入队
创建新节点后,e存入节点数据域
p = new Snode; //生成新节点
p->data = e; //元素e放入新节点数据域
完整代码
void EnQueue(LinkQueue &Q, int e) //入队,元素e放队尾
{
Qptr s; //指针*Qptr作为节点结构体
s = new Qnode; //Qnode作为节点结构体
s->data = e;
s->next = NULL;
Q.rear->next = s; //新节点插入队尾
Q.rear = s; //尾指针后移
}Q.rear本身就指向最后一个节点,所以Q.rear本来指向插入前的最后一个节点,此时Q.rear = s就指向了插入后的最后一个节点
(3)出队
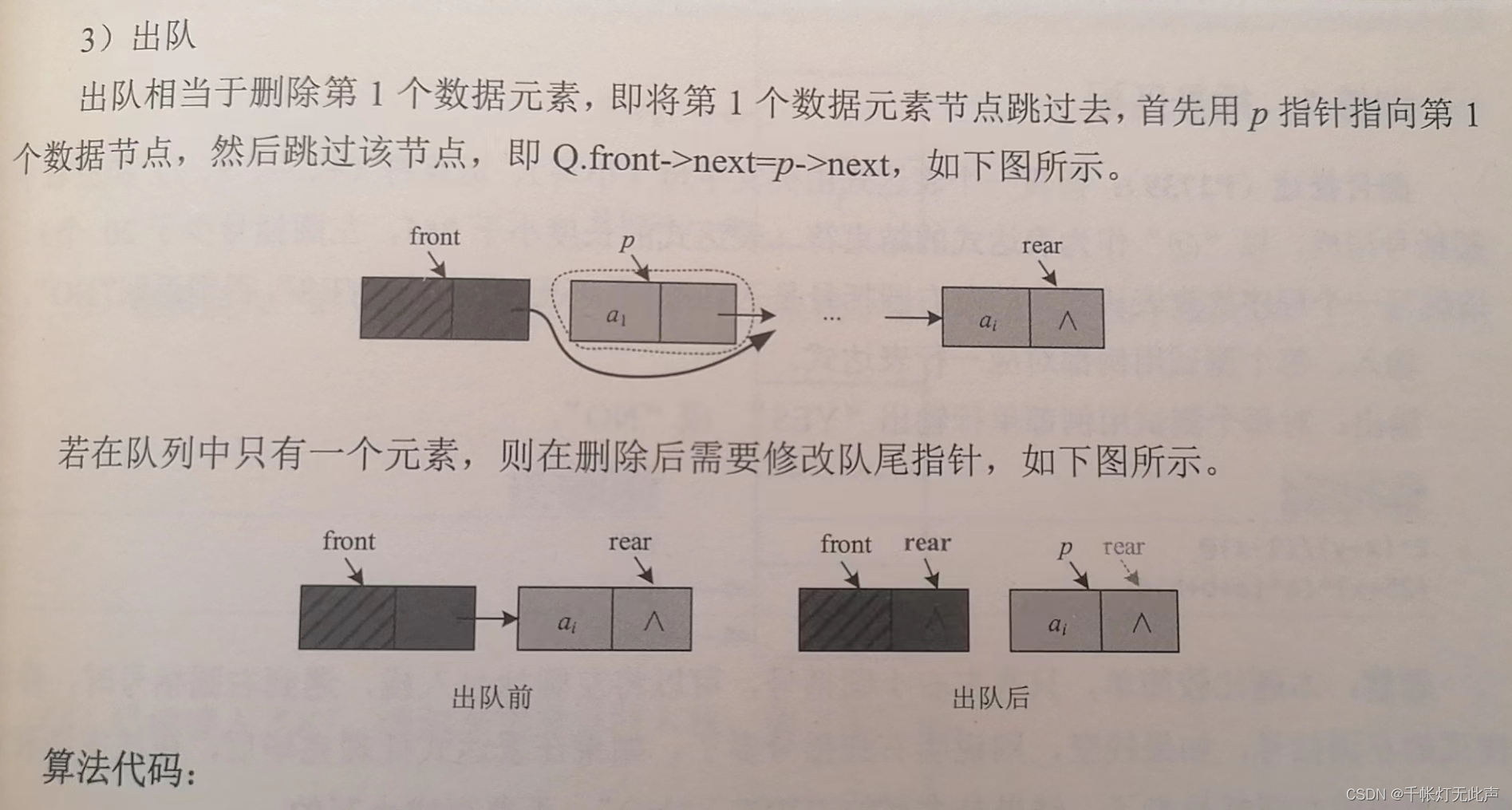
注意!Qptr p = Q.front->next; 指向的队头节点的下一节点,也就是第1个数据节点,为什么呢,因为头节点默认为空,不包含数据
bool DeQueue(LinkQueue &Q, int &e) //出队,删除队头元素,e返回其值
{
if(Q.front == Q.rear) //队空
return false;
Qptr p = Q.front->next; //p指针指向第1个数据节点
e = p->data; //保存队头元素
Q.front->next = p->next; //跳过该节点
if(Q.rear == p) //队列只有1个元素, 删除后修改尾指针
Q.rear = Q.front;
delete p; //手动new, 手动delete
return true;
}(4)取队头元素
队头实际是Q.front->next指向的节点,即第1个数据节点,队头元素就是该节点的数据域存储的元素
int GetHead(LinkQueue Q) //取队头元素, 不修改队头指针
{
if(Q.front != Q.rear) //队列非空
return Q.front->next->data;
return -1;
}虽说学了,数据结构,但是算法题不可能真让你直接手写STL的各种容器,都是用STL里现成的
🚩题目一 P1739 表达式括号匹配
P1739 表达式括号匹配 - 洛谷 | 计算机科学教育新生态 (luogu.com.cn)
1,记得return 0; 而不是 break; 这样可以避免flag的设置
2,@作为结束标记,所以不应string s; cin>>s;这样的
而应char z; while(cin>>z && z != '@')
#include<iostream>
using namespace std;
#include<stack>
int main()
{
char z;
stack<char>st;
while(cin>>z && z != '@') {
if(z == '(')
st.push(z);
else if(z == ')') {
if(!st.empty())
st.pop();
else {
cout<<"NO"<<endl;
return 0; //记得这个, 而不是break, 避免多个flag
}
}
}
if(st.empty())
cout<<"YES"<<endl;
else
cout<<"NO"<<endl;
return 0;
}🚩题目二 Rails
Rails - UVA 514 - Virtual Judge (vjudge.net)
找思路 + 调试 + 提交,耗时1小时Wrong
Debug了2小时,还是Wrong
下定决心看题解0.5小时,自己敲出来0.5小时,提交AC
普及-耗时4小时,如果早点看题解会不会好点,前期啥也不会不要乱来,前期就该多学习别人的方法,等到积累足够了再开始纯靠自己解
做之前建议画下图
AC 代码
#include<iostream>
#include<stack>
using namespace std;
//#define maxSize 1000+5
const int maxSize = 1000+5;
int a[maxSize];
int main()
{
int n;
while(cin>>n && n) {
while(1) {
cin>>a[1];
if(!a[1]) break; //输入0结束本组测试
for(int i = 2; i <= n; ++i)
cin>>a[i]; //读入后序列
int j = 1, i = 1; //j原序列, a[i]后序列
stack<int>st; //st栈
while(j <= n) { //直到处理完原序列
if(j == a[i])
j++, i++;
else
st.push(j), j++;
//栈和后序列匹配, 需要while, 否则无法清空栈和后序列
while(!st.empty() && st.top() == a[i])
st.pop(), i++;
}
if(i == n + 1) cout<<"Yes"<<endl;
else cout<<"No"<<endl;
}
cout<<endl;
}
return 0;
}
🚩题目三 Matrix Chain Multiplication
Matrix Chain Multiplication - UVA 442 - Virtual Judge (vjudge.net)
这题不打算自己啃英文了,上个题目看了半小时英文没看懂...先赶进度,PAT甲级不急在这一时,现在连乙级60分怕是都实现不了,不要好高骛远(踏实把每天的量化进度赶上先)
声明:本题有利于提高对结构体或类的认识,其实只是自定义类型,和int, float, double这些是一样的,只是太少用了导致做题时各种bug
1,
首先要直到线性代数中,矩阵相乘的规则,其次,根据题目数字,自己分析一遍
(A x B) x C 即 ( (50 x 10) x (10 x 20) ) x (20 x 5) = (50 x 20) x (20 x 5)
(注意结果是相加,不是相乘)那么15000 = 50 * 10 * 20 + 50 * 20 * 5
可以自己用 3乘2 和 2乘3 的矩阵试试
同理3500 = 10 * 20 * 5 + 50 * 10 * 5
也就是
,
相乘,乘法运算次数为 m * n * k
2,
(算法设计)
(1)矩阵和行列值存储到数组
(2)读入一行矩阵表达式
(3)遇到矩阵名称入栈
(4)遇到右括号出栈(每次出现右括号,代表一组矩阵相乘)
a.如果两个矩阵,行和列匹配(可以相乘),先将新矩阵入栈,再计算ans
b.否则输出error
(5)输出error 或 乘法运算次数
解释
(一)
struct Matrix
{
Matrix(int a = 0, int b = 0)
{
this->a = a;
this->b = b;
}
int a, b;
};等价于👇
struct Matrix
{
Matrix(int a = 0, int b = 0) : a(a), b(b) {}
};1,👆这个叫“构造函数的成员初始化列表”
: a(a), b(b)用于将传入的参数值赋给对象的成员变量a和b2,使用成员初始化列表的方式可以更加高效地初始化成员变量,并且适用于任意类型的成员变量(包括自定义类型)
(二)
关于代码中的 isalpha()
博客一:C++ isalpha()实例讲解 - 码农教程 (manongjc.com)
博客二:C++ isalpha() - C++ Standard Library (programiz.com)
头文件 #include<ctype.h> 或 #include<cctype>
(三)
关于代码👇
Matrix(m1.a, m2.b)使用表达式
Matrix(m1.a, m2.b)是通过调用Matrix类的构造函数,传递指定的参数来创建一个新的矩阵对象,并进行初始化
AC 代码1
自己写的
#include<iostream>
#include<stack>
using namespace std;
//#define maxsize 26 + 5
const int maxsize = 26 + 5;
struct Matrix
{
Matrix(int a = 0, int b = 0) : a(a), b(b) {} //构造函数成员初始化列表
int a, b; //a行b列
}m[maxsize];
int main()
{
int n;
char z;
string s;
cin>>n;
for(int i = 0; i < n; ++i) {
cin>>z;
int k = z - 'A'; //矩阵下标
cin>>m[k].a>>m[k].b;
}
while(cin>>s) {
stack<Matrix>st; //栈的元素类型为Matrix
//cin>>s; //就说怎么每2组测试输出1次, 原来如此...
int ans = 0, len = s.size();
bool error = false;
for(int i = 0; i < len; ++i) {
if(isalpha(s[i]))
st.push(m[s[i] - 'A']); //注意push的也是矩阵类型
else if(s[i] == ')') {
Matrix m2 = st.top(); st.pop(); //后一个矩阵
Matrix m1 = st.top(); st.pop(); //前一个矩阵
if(m1.b != m2.a) {
error = true;
break;
}
st.push(Matrix(m1.a, m2.b)); //容易漏新矩阵入栈这一步
ans += m1.a * m1.b * m2.b;
}
}
if(error) cout<<"error"<<endl;
else cout<<ans<<endl;
}
return 0;
}
AC 代码 2
源代码加上自己的注释,可以结合2个代码一起看
#include<bits/stdc++.h>
using namespace std;
const int maxsize=26+5;
struct Matrix{//矩阵结构体
int a,b;//矩阵行列
Matrix(int a=0,int b=0):a(a),b(b){} //构造函数的成员初始化列表
}m[maxsize]; //数组每一个元素都是Matrix对象
stack<Matrix> s; //创建一个元素类型是Matrix的栈对象
int main(){
int n;
char c;
string str;
cin>>n;
//(1) 矩阵和对应的行和列, 存储到数组中
for(int i=0;i<n;i++){
cin>>c;
int k=c-'A';//转换为整数
cin>>m[k].a>>m[k].b;//输入矩阵的行列
}
//(2) 读入一行矩阵表达式
while(cin>>str){ //多组输入, 没有结束标志
int len=str.length();
bool error=false;
int ans=0;
for(int i=0;i<len;i++){
if(isalpha(str[i]))
s.push(m[str[i]-'A']); //(3) 矩阵名称入栈, 下标根据名称转ASCII
else if(str[i]==')'){ //(4) 右括号出栈
Matrix m2=s.top();s.pop();
Matrix m1=s.top();s.pop();
if(m1.b!=m2.a){ //矩阵1的列 != 矩阵2的行
error=true;
break;
}
ans+=m1.a*m1.b*m2.b; //相乘再相加
s.push(Matrix(m1.a,m2.b)); //新的矩阵
}
}
//(5) 输出error 或 乘法次数
if(error)
cout<<"error"<<endl;
else
cout<<ans<<endl;
}
return 0;
}
🚩题目四 Printer Queue
Printer Queue - UVA 12100 - Virtual Judge (vjudge.net)
发现个小技巧,英文的话,运气好,直接看Input和Ouput以及Sample,你就可能看懂题目,而不需要看前面50%的背景介绍,,,如果看不懂测试,再回看正文也不迟
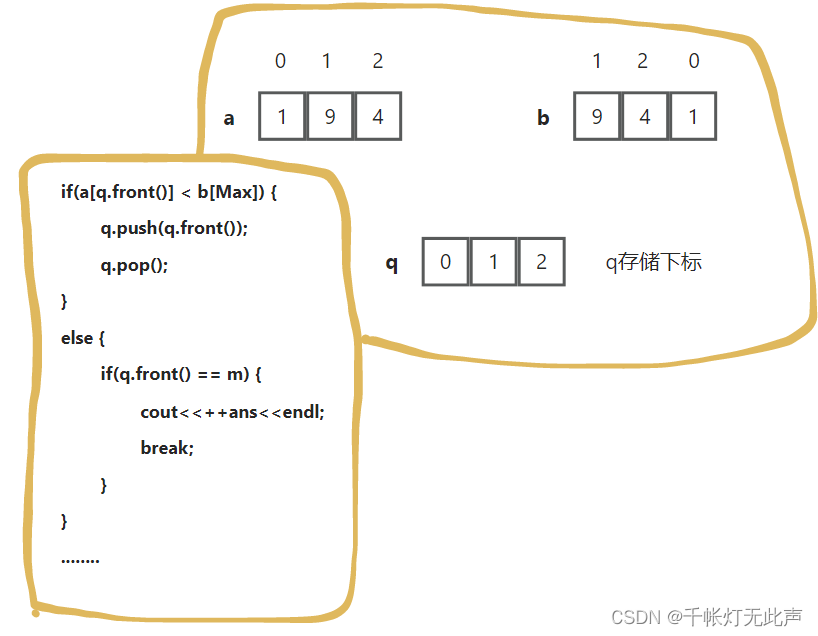
由于题目中,有队头出队,队尾入队的操作,考虑用queue,又因为涉及当前最大优先级的问题,如果直接用函数查找,单次O(n),最坏情况执行n次,时间复杂度O(n^2),过高
所以考虑2个数组,数组a保存值(优先级),数组b按值(优先级)降序
建议自己画草图模拟一遍👇
类似这样,每次做题前,将思路和核心代码简单画出来
关于排序里 greater<int>() 的解释👇
sort(b, b + n, greater<int>()); //降序
sort()是一个用于对数组或容器进行排序的函数。它接受三个参数,分别是排序的起始位置、排序的结束位置和一个比较函数
greater<int>()是一个函数对象,是定义在<functional>头文件中的模板类
注意,queue支持 .front 队头,.back 队尾,但是不支持 .top ,.top是stack的
STL不同容器常用函数对比(这篇文章结尾--总结--👇)
STL入门 + 刷题(上)_千帐灯无此声的博客-CSDN博客
AC 代码
#include<iostream>
#include<queue>
#include<vector>
#include<algorithm> //sort()
using namespace std;
int main()
{
int t, n, m;
cin>>t;
while(t--) {
int x, Max = 0, ans = 0; //Max是b[]中下标, ans已完成任务数
cin>>n>>m;
//q保存下标 a保存值 b保存逆序的值
queue<int>q;
vector<int>a, b;
for(int i = 0; i < n; ++i) {
cin>>x;
q.push(i);
a.push_back(x), b.push_back(x);
}
sort(b.begin(), b.end(), greater<int>()); //b降序
while(!q.empty()) {
if(a[q.front()] < b[Max]) {
q.push(q.front()); //队头入队尾
q.pop(); //队头出队
}
else { //直接出队 不用到队尾
if(q.front() == m) { //这里是队头下标 == m
cout<<++ans<<endl;
break;
}
else {
q.pop();
Max++, ans++; //最大值移到下一位 已打印数+1
}
}
}
}
return 0;
}
🚩题目五 Concurrency Simulator
Concurrency Simulator - UVA 210 - Virtual Judge (vjudge.net)
标签:普及+/提高
一道难题👆(坑题)书里面,题解 + 图解 + 代码,就用了13页,英文题目很长,直接看中文
大模拟! 中文题目读了4遍,题解看了2遍
洛谷中文翻译👇并行程序模拟 Concurrency Simulator - 洛谷 | 计算机科学教育新生态 (luogu.com.cn)
学过操作系统并行程序的,应该好理解,就是队列模拟
看这题目??是人看的???

题解
本题需要2个队列:就绪队列和阻止队列。---- 解锁时,会将阻止队列头部的程序放入就绪队列的头部 ---- ,因此就绪队列需要使用deque双端队列。每个程序都被存储在一个vector中,因此使用vector数组
坑
样例输入,开头少了个1和空行,误导做题者
误区
while(T--) {
...
}原来👆while(T--)后,循环刚开始,T原本是1的话,就已经变成0了,所以最后为了不多输出空行,需要 if(T)
思路
1,先看看全局变量
int n;//n个进程
//每个测试用例开头7个数的第1个
//for(int i=1;i<=n;i++)
int times[5];//表示5个指令所花的时间
//开头7个数第2~6个数
/*
case '=':{
t-=times[0];
...
}
*/
int quantum;//周期时间
//开头7个数最后一个数
int val[26];//26个变量
int p[maxNum];//进程运行在指令的位置
//比如p[1] == 3表示执行到第1个程序第3条命令字符串
vector<string>prg[maxNum];//指令
//比如vector<string>x; 表示每个元素为string的一维数组
//那么vector<string>prg[]; 就表示每个元素为string的二维数组
/*
for(int i=1;i<=n;i++){
prg[i].clear();
while(getline(cin,s)){
prg[i].push_back(s);
if(prg[i].back()=="end")
break;
}
readyQ.push_back(i);//加入就绪队列
}
*/
deque<int>readyQ;//就绪队列
queue<int>blockQ;//阻塞队列
bool locked;//锁
string s;
2,关于独占访问的解释
并行程序的独占访问(Exclusive Access)是指多个并行执行的线程或处理器在同一时间片段内只允许一个线程/处理器对共享资源进行访问和操作,而其他线程/处理器需要等待该资源释放后才能继续访问
3,步骤
注意数组 p[] 下标从0开始,p[0]表示该程序第1条命令
prg[1]代表第1个程序,prg[2]第2个程序,prg[i]第i个程序
并发意味着,先执行a = 4,再a = 3,再b = 5......然后print a,print a....
这里可以理解为3个指针依次向上移动👇
这里阻止队列有什么用呢,当prg[1]时,p[1] == 2第一次遇到"lock",此时locked从false变为true,那么后续遇到的所有"lock"都会导致该程序的指针停止移动,直到"unlocked",解锁第一个加入的程序.....
补充1
又因为,"unlocked"后,locked == false,但是,举例,比如prg[2]的位置还处于p[2]的位置,此时lock 又 == "true",也就是每个"unlocked"只能解锁一个程序
补充2
如何判断某一个程序结果了或者停止了,看它是否在就绪队列里,如果不在,再看是否在阻塞队列里,如果还在阻塞队列,说明只是locked == true并遇到了"lock",如果连阻塞队列也不在了,意味着"end"

(1)
读入T,表示T个测试用例
(2)
读入7个整数,包括程序数,5条指令执行时间,时间周期
(3)
将程序分别读入数组prg[]
(4)
将程序序号加入就绪队列,初始化阻止队列
(5)
变量均为小写字母 a ~ z,转换为数字下标 0 ~ 25,因此变量数组 val[26] 初始化为0,当前运行程序的位置数组 p[maxNum] 也初始化为0,锁初始化为 locked = false;
(6)
如果就绪队列非空,则队头元素 pid 出队,执行 pid 程序
(7)
获取当前指令,即第 pid 个程序的第 p[pid] 单元,cur = prg[pid][p[pid]],执行该指令,然后p[pid++],指向第 pid 个程序的下一条指令。如果时间周期未用完,则继续执行该程序的下一条指令,直到时间周期耗尽。时间周期已用完时,将 pid 号程序加入就绪队列的队尾
(8)
如果 cur == "lock",且 locked == true(说明前面已经出现过lock指令),将 pid 号程序加入阻止队列,p[pid] 不加1
(9)
如果 cur == "unlock",且 locked == false,解锁,当阻止队列不为空,将阻止队列队头,加入就绪队列队头
(10)
赋值 or 打印 or 结束,执行对应指令
AC 代码
第一次接触大模拟,细节太多了,还是学习题解吧,大模拟没办法,只有多做,多做以后,才有机会自己花 0.5 ~ 1 小时AC
#include<iostream>
#include<deque>
#include<queue>
#include<cstring> //memset()
using namespace std;
const int maxNum = 1005;
int n; //n个进程
int times[5]; //5个指令花的时间
int quantum; //周期时间
int val[26]; //26个变量
int p[maxNum]; //程序运行在指令的位置
vector<string>prg[maxNum]; //指令
deque<int>readyQ; //就绪队列
queue<int>blockQ; //阻塞队列
bool locked; //锁
string s;
void run(int i) //执行指令, i表示就绪队列最前面的程序编号
{
int t = quantum, v; //周期时间t
while(t > 0) {
string cur;
cur = prg[i][p[i]]; //获取指令
switch(cur[2]) { //字符串第3个字符
case '=': { //a = 58第3个字符是'='
t -= times[0];
v = cur[4] - '0'; //cur[4], 58中的5
if(cur.size() == 6)
v = v * 10 + cur[5] - '0'; //得到int的58
val[cur[0] - 'a'] = v; //保存变量a的值
break;
}
case 'i': { //print a第3个字符是i
t -= times[1];
cout<<i<<": "<<val[cur[6] - 'a']<<endl;
break;
}
case 'c': { //lock第3个字符
t -= times[2];
if(locked) { //程序加入阻塞队列
blockQ.push(i);
return; //locked == 'true'再遇"lock", 停止当前程序
}
else
locked = true; //上锁
break;
}
case 'l': { //unlock第3个字符
t -= times[3];
locked = false; //解锁
//由题目 当阻塞队列不为空 阻塞队列队头加入就绪的队头
if(!blockQ.empty()) {
int u = blockQ.front();
blockQ.pop();
readyQ.push_front(u);
}
break;
}
case 'd': { //end第3个字符
return;
}
}
p[i]++; //时间没用完, 进入该程序下一指令
}
readyQ.push_back(i); //时间用完, 该程序加入执行队列队尾
}
int main()
{
int T; //T组测试
cin>>T;
while(T--) {
cin>>n; //n个程序
for(int i = 0; i < 5; ++i) //5个时间
cin>>times[i];
cin>>quantum; //时间周期
memset(val, 0, sizeof(val)); //初始化变量的值
for(int i = 1; i <= n; ++i) {
prg[i].clear(); //清空每一个程序
while(getline(cin, s)) {
prg[i].push_back(s);
if(prg[i].back() == "end") //最新输入的字符串为end
break;
}
readyQ.push_back(i); //加入就绪队列
}
memset(p, 0, sizeof(p));
memset(val, 0, sizeof(val));
locked = false;
while(!readyQ.empty()) {
int pid = readyQ.front(); //获取就绪队列最前面的进程编号
readyQ.pop_front();
run(pid); //执行指令
}
if(T) //while(T--)执行完判断时, T == 0了
cout<<endl;
}
return 0;
}
🌼总结
血泪教训
1,
找思路 + 调试 + 提交,耗时1小时Wrong(ACM赛制就是麻烦)
Debug了2小时,还是Wrong
下定决心看题解0.5小时,自己敲出来0.5小时,提交AC
普及-耗时4小时,有点离谱,前期啥也不会不要乱来,前期就该多学习别人的方法,等到积累足够了再开始纯靠自己解题
2,
涉及到stack时,常犯错误是,用 if 代替 while 导致栈未完全清空
3,
以前一直有个误区,以为 while(t--)后t还是原值,实际上,只是说执行这个判断时,t是原值,执行完后就--了,所以循环体中的都是t - 1后的值