目录
一、CRUD是什么
二、什么是SQL注入
三、行转列的使用
四、CRUD中常用关键词
关键词:
GROUP BY
HAVING
ORDER BY
五、聚合函数和连表查询
聚合函数
连表查询
六、DELETE、TRUNCATE、DROP的区别
七、MySQL常见面试题讲解
一、CRUD是什么
CRUD是一个常用的缩写词,用于描述四种基本的数据库操作,即创建(Create)、读取(Read)、更新(Update)和删除(Delete)。这些操作代表了对数据的常见操作方式。
创建(Create):指向数据库中插入新的数据记录。它涉及到将新的数据行添加到数据库表中,并为每个列提供相应的值。
读取(Read):指从数据库中检索数据记录。它涉及到从数据库表中选择一行或多行数据,并获取相应的列值。
更新(Update):指更新数据库中的数据记录。它涉及到修改现有数据行的值,可以更新一列或多列的数据。
删除(Delete):指从数据库中删除数据记录。它涉及到从数据库表中移除一行或多行数据的操作。
二、什么是SQL注入
SQL注入是一种常见的数据库攻击技术,它利用了应用程序对用户输入数据的不充分过滤或验证。攻击者通过在应用程序的输入字段中插入恶意的SQL代码,从而成功执行非授权的数据库操作。
SQL注入的原理是利用应用程序没有对用户输入进行充分的验证和过滤,直接将用户输入的数据拼接到SQL查询语句中。攻击者可以通过构造恶意的输入,改变SQL查询的结构和行为,从而执行非法的操作。这包括但不限于:
绕过身份验证:攻击者可以通过注入恶意的SQL代码,绕过应用程序的身份验证机制,获得对数据库的访问权限。
盗取敏感信息:攻击者可以通过注入SQL代码,查询包含敏感信息(如用户密码、个人信息等)的数据库表。
数据库信息泄露:攻击者可以通过注入特定的SQL代码,从数据库中获取表结构、列名或其他敏感信息。
数据库篡改和损坏:攻击者可以通过注入恶意的SQL代码,修改、删除或篡改数据库中的数据,导致数据的丢失或不一致。
避免SQL注入攻击的最佳实践包括:
输入验证和过滤:对应用程序接收的所有用户输入数据进行验证和过滤,确保只接受预期的数据类型和格式。
使用参数化查询或预编译语句:通过使用参数化查询或预编译语句,使得用户输入的数据作为参数传递给数据库引擎,而不是直接拼接到SQL查询语句中。
最小权限原则:为数据库用户提供最小的权限,限制其对敏感数据和数据库结构的访问权限。
日志和监控:记录和监控应用程序和数据库的日志,及时发现异常行为和攻击尝试。
SQL注入是一种严重的安全威胁,可以导致各种安全问题和数据泄露。因此,开发者和管理员应当始终采取适当的安全措施来防范和阻止SQL注入攻击。
三、行转列的使用
行转列是一种重塑或重新组织数据的操作,将原先以行的形式存储的数据转换为以列的形式存储。行转列的技术可以使用在各种领域,如数据分析、报表生成等。
举个例子:
成绩/学生 安子 良子 文子 辉子 语文 90 89 99 90 数学 90 90 100 79 从上面这样变成下面这样
学生/成绩 语文 数学 安子 90 90 良子 89 90 文子 99 100 辉子 90 79 后面的方式是不是看起来更为简洁,这就是“行转列”。
那么在数据库中如何运用呢
SELECT t1.sid, t1.cid '"01"课程', t2.cid '"02"课程' FROM ( SELECT * FROM t_mysql_score WHERE cid = '01' ) t1 LEFT JOIN ( SELECT * FROM t_mysql_score WHERE cid = '02' ) t2 ON t1.sid = t2.sid --以上是利用别名的方式,下面是行转列的使用方式 SELECT t1.sid, (CASE WHEN t1.cid = '01' THEN t1.score END ) '"01"课程', (CASE WHEN t2.cid = '02' THEN t2.score END ) '"02"课程' FROM ( SELECT * FROM t_mysql_score WHERE cid = '01' ) t1 LEFT JOIN ( SELECT * FROM t_mysql_score WHERE cid = '02' ) t2 ON t1.sid = t2.sid
四、CRUD中常用关键词
关键词:
SELECT:用于从数据库中检索数据。
INSERT:用于向数据库表中插入新的行。
UPDATE:用于更新数据库表中的行。
DELETE:用于删除数据库表中的行。
CREATE:用于创建数据库、表、索引等对象。
ALTER:用于修改数据库表的结构,如添加、修改、删除列等操作。
DROP:用于删除数据库、表、索引等对象。
FROM:用于指定在哪个表中进行操作。
WHERE:用于在查询中添加条件,过滤满足特定条件的行。
GROUP BY:用于对查询结果进行分组。
HAVING:用于在GROUP BY后对分组结果进行过滤。
ORDER BY:用于对查询结果进行排序。
JOIN:用于将两个或多个表联接起来,以便在查询中同时获取相关数据。
DISTINCT:用于去除查询结果中的重复行。
LIMIT:用于限制查询结果的返回行数。
OFFSET:用于设置查询结果的偏移量,通常与LIMIT一起使用,用于分页查询。
NULL:表示数据库中的一个空值。
NOT NULL:约束条件,表示列中的值不能为空。
PRIMARY KEY:约束条件,用于唯一标识表中的每一行。
FOREIGN KEY:约束条件,用于创建两个表之间的关联。
INDEX:用于加快数据库的查询速度,可以在某一列上创建索引。
TRANSACTION:用于在数据库中执行一组操作,并保证这些操作要么一起成功(提交),要么一起失败(回滚)。
GROUP BY
GROUP BY语句用于按照一个或多个列对结果进行分组,并对分组后的数据进行聚合操作。它常与聚合函数(如SUM、AVG、COUNT等)一起使用,用于统计和汇总数据。
以下是GROUP BY的使用示例和注意事项:
使用示例:
假设有一个"Orders"表,其中包含"OrderID"、"CustomerID"和"TotalAmount"列。我们想要按照"CustomerID"对销售额进行分组,并计算每个客户的总销售额。SELECT CustomerID, SUM(TotalAmount) AS TotalSales FROM Orders GROUP BY CustomerID;在上述示例中,使用GROUP BY语句将"Orders"表按照"CustomerID"列进行分组。然后使用SUM函数计算每个分组中"TotalAmount"列的总和,别名为"TotalSales"。最终的结果将返回每个客户的ID和对应的总销售额。
注意事项:
GROUP BY子句只能用于SELECT语句中的列,或者是由表达式生成的列。SELECT列表中的非聚合列必须包含在GROUP BY子句中,或者在SELECT列表中使用聚合函数进行处理。
GROUP BY子句的顺序对结果有影响。相同的数据按照不同的GROUP BY列的顺序进行聚合将得到不同的结果。
GROUP BY子句中可以使用多个列进行分组。这将导致根据指定的列对结果进行多级分组。
在GROUP BY子句中可以使用表达式和函数,以便进行更复杂的数据分组。
可以在GROUP BY子句中使用列的别名,也可以使用列的序号(1、2、3…)来引用列。
HAVING子句可以与GROUP BY一起使用,用于过滤分组后的结果。它类似于WHERE子句,但作用于分组后的数据。
GROUP BY语句常用于统计和汇总数据,可以用于生成报表、分析数据等场景。
正确使用GROUP BY可以实现灵活的数据分组和聚合操作,但需要注意在SELECT语句中的列和聚合函数的使用,以及GROUP BY子句中的列顺序和HAVING子句的条件设置。这样可以确保得到正确的分组和聚合结果。
HAVING
HAVING子句用于在GROUP BY分组后对分组结果进行过滤。它类似于WHERE子句,但作用于分组后的数据。
以下是HAVING的使用示例和注意事项:
使用示例:
假设有一个"Orders"表,其中包含"OrderID"、"CustomerID"和"TotalAmount"列。我们想要按照"CustomerID"对销售额进行分组,并筛选出总销售额大于1000的客户。SELECT CustomerID, SUM(TotalAmount) AS TotalSales FROM Orders GROUP BY CustomerID HAVING SUM(TotalAmount) > 1000;在上述示例中,使用GROUP BY语句按照"CustomerID"列对"Orders"表进行分组。然后使用SUM函数计算每个分组中"TotalAmount"列的总和,并使用HAVING子句筛选出总销售额大于1000的分组结果。最终的结果将返回满足条件的客户ID和对应的总销售额。
注意事项:
HAVING子句只能在GROUP BY语句中使用,用于对分组后的数据进行过滤。
HAVING子句可以使用聚合函数(如SUM、AVG、COUNT等)对分组结果进行条件判断。
HAVING子句中可以使用比较操作符(如>、<、=、!=等)和逻辑操作符(如AND、OR、NOT)。
HAVING子句中的列不能是SELECT列表中的非聚合列,因为非聚合列在分组后不可访问。
HAVING子句可以使用分组函数的别名,也可以使用分组函数的顺序(1、2、3…)来引用分组结果。
HAVING子句可以结合AND和OR等逻辑操作符进行多个条件的组合筛选。
HAVING子句常用于在GROUP BY查询中进行更精细的筛选,过滤不需要的分组结果。
正确使用HAVING子句可以对分组后的结果进行灵活的过滤,以得到满足条件的分组数据。需要注意HAVING子句的位置和条件设置,确保它位于GROUP BY子句之后,并使用正确的分组函数和列进行条件判断。这样可以得到准确的筛选结果。
ORDER BY
ORDER BY语句用于对查询结果进行排序。它可以按照一个或多个列的值进行升序(ASC)或降序(DESC)排序。
以下是ORDER BY的使用示例和注意事项:
使用示例:
假设有一个"Customers"表,其中包含"CustomerID"、"CustomerName"和"City"列。我们想要按照"City"列对客户进行升序排序。SELECT CustomerID, CustomerName, City FROM Customers ORDER BY City ASC;在上述示例中,使用ORDER BY语句按照"City"列对"Customers"表进行升序排序。最终的结果将按照城市名称从A到Z的顺序返回客户ID、客户姓名和城市。
注意事项:
ORDER BY子句应该在SELECT语句的最后使用,用于对查询结果进行排序。
ORDER BY子句可以指定一个或多个列进行排序。多个列之间用逗号分隔,按照指定的列顺序进行排序。
ORDER BY子句支持对列的升序(ASC,默认)或降序(DESC)排序。使用ASC关键字表示升序排序,使用DESC关键字表示降序排序。
ORDER BY子句中可以使用别名、表达式或函数作为排序列。这样可以对计算结果或复杂表达式进行排序。
ORDER BY子句中可以使用列的索引位置(1、2、3…)来指定排序列,而不是使用列名。
ORDER BY子句支持NULL值的处理。默认情况下,NULL值会被排在排序的末尾。可以使用NULLS FIRST或NULLS LAST关键字来指定NULL值在排序中的位置。
在多表连接查询时,如果ORDER BY子句中的列来自多个表,应该使用完全限定列名来避免歧义。
ORDER BY子句还可以与LIMIT或OFFSET一起使用来对查询结果进行分页或限制返回的行数。
正确使用ORDER BY可以对查询结果进行灵活的排序,以满足特定的排序需求。需要注意指定正确的排序列、排序顺序(升序或降序)以及处理NULL值的方式。这样可以得到准确的排序结果。
五、聚合函数和连表查询
聚合函数
聚合函数是在数据库中用于计算和返回多个行或列的汇总值的特殊函数。这些函数可以对数据执行各种操作,如计算总和、平均值、最大值、最小值等。
以下是常见的聚合函数:
SUM:计算给定列的所有值的总和。例如,
SELECT SUM(column_name) FROM table_name;AVG:计算给定列的所有值的平均值。例如,
SELECT AVG(column_name) FROM table_name;COUNT:计算给定列的行数或返回非空值的数量。例如,
SELECT COUNT(column_name) FROM table_name;MAX:返回给定列的最大值。例如,
SELECT MAX(column_name) FROM table_name;MIN:返回给定列的最小值。例如,
SELECT MIN(column_name) FROM table_name;GROUP_CONCAT:将一列中的多个值连接成一个字符串,并用给定的分隔符分隔。例如,
SELECT GROUP_CONCAT(column_name SEPARATOR ',') FROM table_name;这些聚合函数可以与SELECT语句一起使用,通常结合GROUP BY子句来实现对分组数据的聚合操作。GROUP BY子句用于将数据按照一列或多列的值进行分组,然后对每个组应用聚合函数。
聚合函数在数据库中非常有用,可以进行数据的统计和汇总操作。通过使用聚合函数,可以快速计算和返回数据的汇总信息,从而支持数据分析和决策过程。
连表查询
连表查询提供了多种类型的连接操作来满足不同的数据查询需求。下面介绍各种连表查询的使用场景和示例:
1.内连接(Inner Join):
内连接返回两个表中满足连接条件的交集数据。它适用于需要获取两个表中共同满足某种条件的数据记录。示例:
SELECT Orders.OrderID, Customers.CustomerName FROM Orders INNER JOIN Customers ON Orders.CustomerID = Customers.CustomerID;这个示例查询将
Orders表和Customers表基于CustomerID列进行内连接,并返回匹配的OrderID和CustomerName列。2.左外连接(Left Join):
左外连接返回左表中的所有行,以及右表中满足连接条件的匹配行。对于右表中没有匹配的行,将返回NULL值。示例:
SELECT Customers.CustomerName, Orders.OrderID FROM Customers LEFT JOIN Orders ON Customers.CustomerID = Orders.CustomerID;这个示例查询将
Customers表和Orders表基于CustomerID列进行左外连接,并返回CustomerName和OrderID列的结果。左表Customers中的所有行都将被包含,无论是否在右表Orders中有匹配。3.右外连接(Right Join):
右外连接返回右表中的所有行,以及左表中满足连接条件的匹配行。对于左表中没有匹配的行,将返回NULL值。示例:
SELECT Customers.CustomerName, Orders.OrderID FROM Customers RIGHT JOIN Orders ON Customers.CustomerID = Orders.CustomerID;这个示例查询将
Customers表和Orders表基于CustomerID列进行右外连接,并返回CustomerName和OrderID列的结果。右表Orders中的所有行都将被包含,无论是否在左表Customers中有匹配。4.全外连接(Full Join):
全外连接返回左表和右表中的所有行,无论是否有匹配。对于没有匹配的行,将返回NULL值。示例:
SELECT Customers.CustomerName, Orders.OrderID FROM Customers FULL JOIN Orders ON Customers.CustomerID = Orders.CustomerID;这个示例查询将
Customers表和Orders表基于CustomerID列进行全外连接,并返回CustomerName和OrderID列的结果。左表和右表中的所有行都将被包含,无论是否有匹配。5.自连接(Self Join):
自连接是指将表与自身进行连接。它适用于需要在同一个表中比较不同行之间的关联的情况。示例:
SELECT e1.EmployeeName, e2.ManagerName FROM Employees e1 JOIN Employees e2 ON e1.ManagerID = e2.EmployeeID;这个示例查询将
Employees表与自身进行连接,基于ManagerID和EmployeeID列进行自连接。它返回每个员工的名称以及他们的上级经理名称。合理使用连表查询,可以实现复杂的数据关联和查询。
六、DELETE、TRUNCATE、DROP的区别
DELETE、TRUNCATE和DROP是在SQL中用于删除数据和对象的三种不同方式,它们的区别如下所示:
DELETE:
- DELETE用于从表中删除指定的行或符合某个条件的行。
- DELETE语句操作的是表中的数据,而不是表本身。
- DELETE语句可以包含WHERE子句,以指定删除的条件。
- DELETE语句会触发触发器(如果有设置触发器),并且可以在事务中使用。
TRUNCATE:
- TRUNCATE用于快速删除表中的数据,通常比DELETE语句的执行速度更快。
- TRUNCATE语句操作的是表本身,而不是表中的数据。
- TRUNCATE语句不能包含WHERE子句,它将删除整个表的数据。
- TRUNCATE语句无法回滚,即无法恢复删除的数据。
- TRUNCATE语句通常比DELETE语句更简洁且效率更高。
DROP:
- DROP用于删除数据库中的表、视图、索引、触发器等对象。
- DROP语句操作的是数据库中的对象,而不是对象中的数据。
- DROP TABLE语句可以彻底删除表及其相关的索引、触发器等所有对象。
- DROP语句无法回滚,一旦执行成功,对象将被永久删除。
总结:
- DELETE用于删除表中的行,TRUNCATE用于快速删除整个表的数据,而DROP用于删除整个表或其他数据库对象。
- DELETE和TRUNCATE都是操作数据,而DROP是操作对象。
- DELETE和TRUNCATE可以指定条件进行删除,而DROP无需指定条件,直接删除对象。
- TRUNCATE比DELETE执行速度更快,DROP和TRUNCATE都无法回滚操作。
注:在使用这些删除操作之前,请谨慎进行,确保你理解其影响,并备份重要数据以防意外删除。
七、MySQL常见面试题讲解
数据库脚本
一、表结构要求:
-- 1.学生表-t_mysql_student
-- sid 学生编号,sname 学生姓名,sage 学生年龄,ssex 学生性别-- 2.教师表-t_mysql_teacher
-- tid 教师编号,tname 教师名称-- 3.课程表-t_mysql_course
-- cid 课程编号,cname 课程名称,tid 教师名称-- 4.成绩表-t_mysql_score
-- sid 学生编号,cid 课程编号,score 成绩二、表数据:
-- 学生表
insert into t_mysql_student values('01' , '赵雷' , '1990-01-01' , '男');
insert into t_mysql_student values('02' , '钱电' , '1990-12-21' , '男');
insert into t_mysql_student values('03' , '孙风' , '1990-12-20' , '男');,
insert into t_mysql_student values('04' , '李云' , '1990-12-06' , '男');
insert into t_mysql_student values('05' , '周梅' , '1991-12-01' , '女');
insert into t_mysql_student values('06' , '吴兰' , '1992-01-01' , '女');
insert into t_mysql_student values('07' , '郑竹' , '1989-01-01' , '女');
insert into t_mysql_student values('09' , '张三' , '2017-12-20' , '女');
insert into t_mysql_student values('10' , '李四' , '2017-12-25' , '女');
insert into t_mysql_student values('11' , '李四' , '2012-06-06' , '女');
insert into t_mysql_student values('12' , '赵六' , '2013-06-13' , '女');
insert into t_mysql_student values('13' , '孙七' , '2014-06-01' , '女');-- 教师表
insert into t_mysql_teacher values('01' , '张三');
insert into t_mysql_teacher values('02' , '李四');
insert into t_mysql_teacher values('03' , '王五');-- 课程表
insert into t_mysql_course values('01' , '语文' , '02');
insert into t_mysql_course values('02' , '数学' , '01');
insert into t_mysql_course values('03' , '英语' , '03');-- 成绩表
insert into t_mysql_score values('01' , '01' , 80);
insert into t_mysql_score values('01' , '02' , 90);
insert into t_mysql_score values('01' , '03' , 99);
insert into t_mysql_score values('02' , '01' , 70);
insert into t_mysql_score values('02' , '02' , 60);
insert into t_mysql_score values('02' , '03' , 80);
insert into t_mysql_score values('03' , '01' , 80);
insert into t_mysql_score values('03' , '02' , 80);
insert into t_mysql_score values('03' , '03' , 80);
insert into t_mysql_score values('04' , '01' , 50);
insert into t_mysql_score values('04' , '02' , 30);
insert into t_mysql_score values('04' , '03' , 20);
insert into t_mysql_score values('05' , '01' , 76);
insert into t_mysql_score values('05' , '02' , 87);
insert into t_mysql_score values('06' , '01' , 31);
insert into t_mysql_score values('06' , '03' , 34);
insert into t_mysql_score values('07' , '02' , 89);
insert into t_mysql_score values('07' , '03' , 98);
1.查询" 01 "课程比" 02 "课程成绩高的学生的信息及课程分数
SQl语句编写:
SELECT
t3.*,
( CASE WHEN t1.cid = '01' THEN t1.score END ) '"01"课程',
( CASE WHEN t2.cid = '02' THEN t2.score END ) '"02"课程'
FROM
( SELECT * FROM t_mysql_score WHERE cid = '01' ) t1,
( SELECT * FROM t_mysql_score WHERE cid = '02' ) t2,
t_mysql_student t3
WHERE
t1.sid = t2.sid
AND t1.score > t2.score
AND t1.sid = t3.sid
crud操作结果:

2.查询同时存在" 01 "课程和" 02 "课程的情况
SQl语句编写:
SELECT
t3.*,
( CASE WHEN t1.cid = '01' THEN t1.score END ) '"01"课程',
( CASE WHEN t2.cid = '02' THEN t2.score END ) '"02"课程'
FROM
( SELECT * FROM t_mysql_score WHERE cid = '01' ) t1,
( SELECT * FROM t_mysql_score WHERE cid = '02' ) t2,
t_mysql_student t3
WHERE
t1.sid = t2.sid
AND t1.sid = t3.sid
crud操作结果:
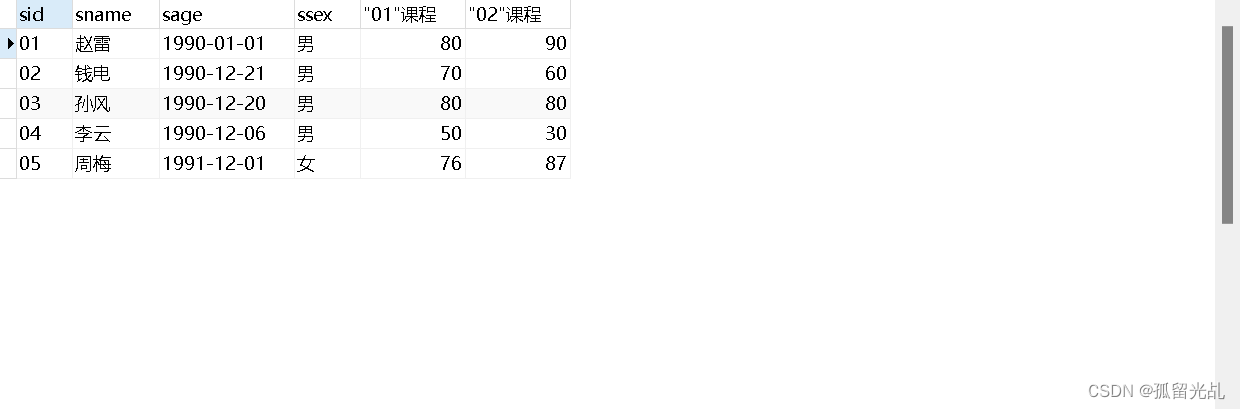
03.查询存在" 01 "课程但可能不存在" 02 "课程的情况(不存在时显示为 null )
SQl语句编写:
SELECT
t1.sid,
(CASE WHEN t1.cid = '01' THEN t1.score END ) '"01"课程',
(CASE WHEN t2.cid = '02' THEN t2.score END ) '"02"课程'
FROM
( SELECT * FROM t_mysql_score WHERE cid = '01' ) t1
LEFT JOIN ( SELECT * FROM t_mysql_score WHERE cid = '02' ) t2 ON t1.sid = t2.sid
crud操作结果:

4.查询不存在" 01 "课程但存在" 02 "课程的情况
SQl语句编写:
SELECT
*
FROM
t_mysql_score
WHERE
sid IN ( SELECT sid FROM t_mysql_student WHERE sid NOT IN ( SELECT sid FROM t_mysql_score WHERE cid = '01' ) )
AND cid = '02'
crud操作结果:

5.查询平均成绩大于等于 60 分的同学的学生编号和学生姓名和平均成绩
SQl语句编写:
SELECT
stu.sid,
stu.sname,
ROUND( AVG( sc.score ), 2 ) '平均成绩'
FROM
t_mysql_score sc,
t_mysql_student stu
WHERE
sc.sid = stu.sid
GROUP BY
sid,
sname
HAVING
AVG( sc.score ) >= 60
crud操作结果:

6.查询在t_mysql_score表存在成绩的学生信息
SQl语句编写:
SELECT
*
FROM
t_mysql_student
WHERE
sid IN ( SELECT sid FROM t_mysql_score GROUP BY sid )
crud操作结果:

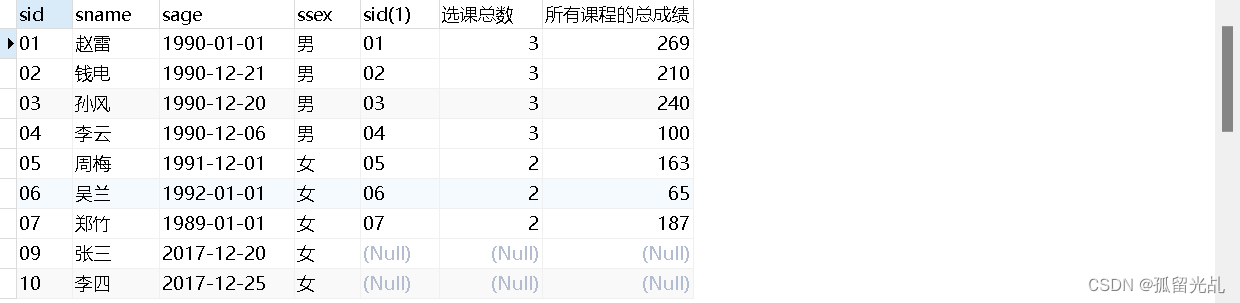
7.查询所有同学的学生编号、学生姓名、选课总数、所有课程的总成绩(没成绩的显示为 null)
SQl语句编写:
SELECT
*
FROM
( SELECT * FROM t_mysql_student ) t1
LEFT JOIN ( SELECT sid, COUNT( cid ) '选课总数', sum( score ) '所有课程的总成绩' FROM t_mysql_score GROUP BY sid ) t2 ON t1.sid = t2.sid
crud操作结果:
8.查询「李」姓老师的数量
SQl语句编写:
SELECT COUNT(*) '李姓老师的数量' from t_mysql_teacher where tname LIKE '李%'
crud操作结果:

9.查询学过「张三」老师授课的同学的信息
SQl语句编写:
SELECT
*
FROM
t_mysql_student
WHERE
sid IN (
SELECT
sid
FROM
t_mysql_score
WHERE
cid = ( SELECT cid FROM t_mysql_course WHERE tid = ( SELECT tid FROM t_mysql_teacher WHERE tname LIKE '李%' ) )
)
crud操作结果:

10.查询没有学全所有课程的同学的信息
SQl语句编写:
SELECT
s.*
FROM
t_mysql_student s
LEFT JOIN ( SELECT sid, COUNT( DISTINCT cid ) AS course_count FROM t_mysql_score GROUP BY sid ) sc ON s.sid = sc.sid
WHERE
sc.course_count < ( SELECT COUNT( * ) FROM t_mysql_course );
crud操作结果:

11.查询没学过"张三"老师讲授的任一门课程的学生姓名
SQl语句编写:
SELECT
*
FROM
t_mysql_student
WHERE
sid NOT IN (
SELECT
s.sid
FROM
t_mysql_score sc,
t_mysql_teacher t,
t_mysql_course c,
t_mysql_student s
WHERE
c.cid = sc.cid
AND c.tid = t.tid
AND sc.sid = s.sid
AND t.tname = '张三'
)crud操作结果:

12.查询两门及其以上不及格(低于60分)课程的同学的学号,姓名及其平均成绩
SQl语句编写:
SELECT
s.sid,
s.sname,
COUNT( * ) 不及格课程数,
ROUND( AVG( sc.score ), 2 ) 平均成绩
FROM
t_mysql_score sc,
t_mysql_student s
WHERE
sc.sid = s.sid
AND sc.score < 60 GROUP BY s.sid, s.sname HAVING 不及格课程数 >=2
crud操作结果:

13.检索" 01 "课程分数小于 60,按分数降序排列的学生信息
SQl语句编写:
SELECT
s.*,
sc.score
FROM
t_mysql_score sc,
t_mysql_student s
WHERE
sc.sid = s.sid
AND sc.score < 60
AND sc.cid = '01'
ORDER BY
sc.score DESC
crud操作结果:

14.按平均成绩从高到低显示所有学生的所有课程的成绩以及平均成绩
SQl语句编写:
SELECT
s.sid,
s.sname,
max(CASE WHEN sc.cid = '01' THEN sc.score END ) 语文 ,
max(CASE WHEN sc.cid = '02' THEN sc.score END ) 数学 ,
max(CASE WHEN sc.cid = '03' THEN sc.score END ) 英语,
ROUND(AVG(sc.score),2) 平均成绩
FROM
t_mysql_student s,
t_mysql_score sc
WHERE
s.sid = sc.sid
GROUP BY
s.sid,
s.snamecrud操作结果:

15.查询各科成绩最高分、最低分和平均分:
以如下形式显示:课程 ID,课程 name,最高分,最低分,平均分,及格率,中等率,优良率,优秀率及格为>=60,中等为:70-80,优良为:80-90,优秀为:>=90
要求输出课程号和选修人数,查询结果按人数降序排列,若人数相同,按课程号升序排列
SQl语句编写:
SELECT
c.cid,
c.cname,
max( sc.score ) 最高分,
min( sc.score ) 最低分,
ROUND( AVG( sc.score ), 2 ) 平均分,
CONCAT(ROUND(sum( IF ( sc.score >= 60, 1, 0 ) ) / COUNT( sc.score ) * 100,2 ),'%' ) 及格率,
CONCAT(ROUND(sum( IF ( sc.score >= 70 AND sc.score < 80, 1, 0 ) ) / COUNT( sc.score ) * 100,2 ),'%' ) 中等率,
CONCAT(ROUND(sum( IF ( sc.score >= 80 AND sc.score < 90, 1, 0 ) ) / COUNT( sc.score ) * 100,2 ),'%' ) 优良率,
CONCAT(ROUND(sum( IF ( sc.score >= 90, 1, 0 ) ) / COUNT( sc.score ) * 100,2 ),'%' ) 优秀率,
COUNT( sc.score ) 选修人数
FROM
t_mysql_score sc,
t_mysql_course c
WHERE
sc.cid = c.cid
GROUP BY
sc.cid
ORDER BY
选修人数 DESC,
c.cid ASC;crud操作结果:

MySQL面试题就讲到这啦,希望对大家有所帮助!!😊