AIFORE: Smart Fuzzing Based on Automatic Input Format Reverse Engineering

1 中国科学院信息工程研究所2清华大学网络科学与网络空间研究院;中关村实验室3华为技术有限公司奇异安全实验室4中国科学院大学网络安全学院5中国人民大学6洛桑联邦理工学院
论文链接 :https://www.usenix.org/system/files/sec23summer_427-shi_ji-prepub.pdf
摘要
在模糊测试中,了解程序的输入格式对于有效地生成输入至关重要。自动输入格式逆向工程是一种有吸引力但具有挑战性的学习格式的方法。本文针对自动化输入格式逆向工程的几个挑战,提出了一种充分利用逆向格式并从中获益的智能模糊测试解决方案AIFORE。
输入字段的结构和语义由处理它们的基本块(BB)决定,而不是由输入规范决定。因此,本文首先利用字节级污染分析来识别每个BB处理的输入字节,然后识别不可分割的输入字段,这些字段总是与最小聚类算法一起处理,并使用表征BB行为的神经网络模型来学习它们的类型。最后,本文设计了一种新的基于推断格式知识的能量调度算法来指导智能模糊测试。本文实现了AIFORE的原型,并针对最先进的(SOTA)格式反转解决方案和模糊器评估了格式推理的准确性和模糊测试的性能。AIFORE在场边界和类型识别精度上明显优于SOTA基线。通过AIFORE,本文发现了15个程序中的20个bug,这些bug是其他fuzzers没有发现的
背景
模糊测试是一种有效的发现程序漏洞的技术,通常,模糊测试会产生大量输入,并将它们提供给正在测试的程序,从而检测安全违规。一个智能和有效的模糊器依赖于高质量的输入,它可以有效地探索程序状态空间,并增加触发漏洞的机会。了解输入格式对于生成高质量的输入至关重要。输入格式描述了程序期望如何组织输入字节。理想情况下,格式良好的输入将得到正确的解析和处理,从而达到预期的结果。格式错误的输入将被程序中的完整性检查器过滤掉,并尽早丢弃。
因此,fuzzer可以按照格式规范生成输入,这将有助于绕过浅层代码中的一些完整性检查,并最终到达和测试更深、更复杂的代码。此外,由于程序中的健全机制并不总是健全和完整的,因此很有可能一些违反格式规范的输入没有被过滤掉,而是传递给更深层的代码。这些输入通常有更大的机会触发意想不到的行为或错误,因此应该受到模糊器的青睐。因此,在格式知识的指导下,模糊器可以为探索和开发目的提供有价值的输入。
举例说明
以readelf为例说明它如何解析ELF文件格式,如下图所示为elf头定义:
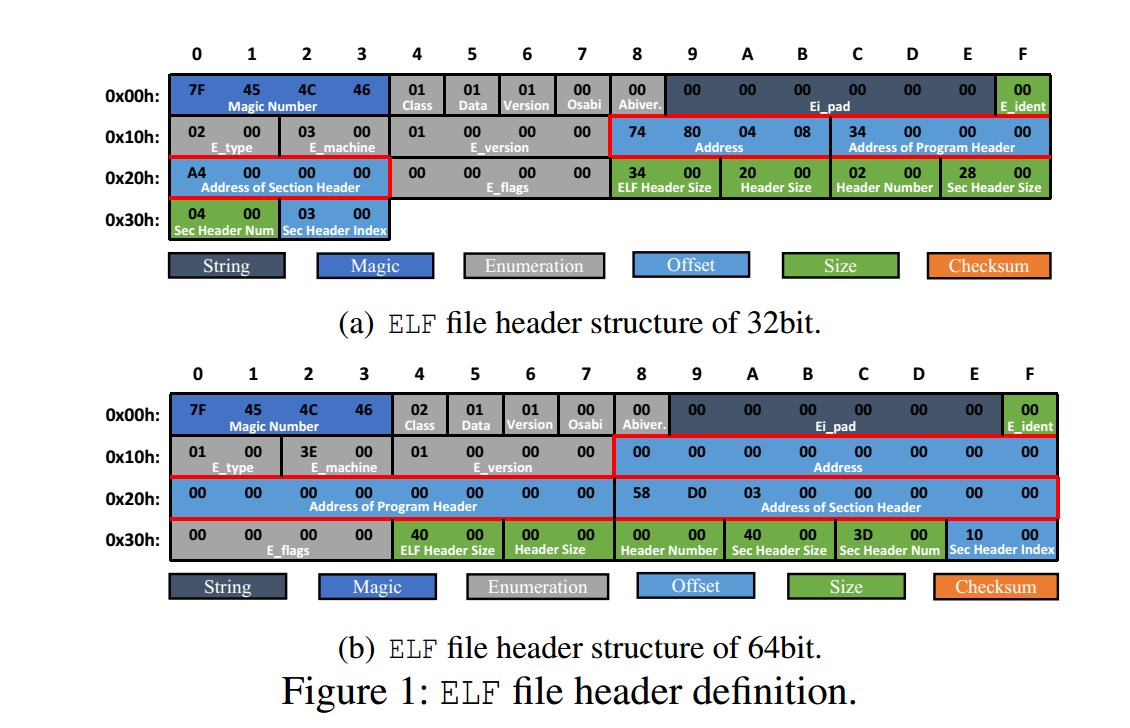
一个ELF文件由几个数据结构(例如,文件头、程序头和段头)组成,每个数据结构由几个字段组成。对于如图1所示的文件头结构,它有一些由连续字节组成的字段(例如,从偏移量0x00到0x03的magic number)和一些具有单字节值的字段(例如,偏移量0x04处的class)。以偏移量0x12处的e_machine为例,它表示改变了ELF结构的机器架构(例如,AArch64、i386或x86_64)(例如,地址字段的长度可以是4个字节或8个字节,用红色框标记)。

如上图显示了readelf的代码片段,用于解析ELF格式的输入。解析输入文件有两个主要步骤。第一步是读取输入并初始化与输入字段相对应的某些变量。例如,第3行到第6行从输入中读取字段并初始化相应的变量(例如,file_header.e_machine)。下一步是在函数process_file_header中进一步处理这些初始化的变量。不同的基本块(BB)用于处理不同类型的变量(即输入字段)。例如,在第21行,每次比较一个字节的四字节Magic number,而e_machine则作为带有switch-case语句的枚举处理。
在对程序进行分析时作者提出了以下三个发现:
- 在大多数情况下,一个不可分割的字段中的字节被放在一个基本块中一起解析
- 当程序处理不同类型字段时,程序代码显示出不同的模式
- 程序可能会根据输入结构的不同调度不同的代码来解析输入
根据以上三点观察,作者认为由于输入字段是由基本块分析的,无论输入格式规范如何,都可以从基本块中推断出输入的结构和语义信息,因此可以通过分析处理不同输入字段的基本块来学习输入字段的结构和语义,然后利用这些知识来进行智能 Fuzzing。
相关工作
基于格式感知的模糊
-
TIFF-fuzzer通过推断输入字段的一些程序变量类型(例如int, char*)来执行bug导向的突变。ProFuzzer使用预定义的规则来推断字段和相应的类型。然而,添加更多的数据类型是一项劳动密集型工作。此外,这些规则可能不够准确,无法涵盖所有情况
-
Steelix识别输入中的幻数以通过值验证。但是它不分析其他类型的字段
-
Interfier利用轻量级污点分析找到程序中指令处理的多字节字段,然后利用字段级知识优化符号执行。但从文件格式的角度来看,由于其轨迹不完整,它只能提取一小部分字段
-
WEIZZ根据输入字节与比较指令之间的依赖关系将输入分割为字段,忽略了不影响程序控制流的字节
输入格式逆向工程 字段边界识别
- Tupni :使用指令中的加权污点信息和贪心算法来识别不同字段。是一种粗粒度的方法,识别的记录可能包含多个字段而不是单个字段,且由于不考虑语义,可能产生误报
- AutoFormat:使用动态污点分析和调用栈来构建字段树,过度依赖于标记和树本身的操作,而不是程序去不同字段的处理
- MIMID和AUTOGRAM都依赖于动态污染分析和调用堆栈分析。它们用于为基于文本的输入提取与上下文无关的语法,而不是像基于二进制的输入这样的上下文敏感的语法
- Reverx:通过预定义的分隔符将输入分割成字段,它不能用于二进制消息
字段类型识别
- Dispatcher使用污点分析和启发式规则来识别字段类型
- Polyglot尝试识别协议消息中的关键字和分隔符,并尝试使用启发式算法来识别字段长度,然而它在识别字段长度或类型是都存在限制,如一个协议可能允许多个分隔符,同时启发式算法在信息不完整的情况下也存在局限性
- AIFORE利用机器学习模型自动提取特征并预测字段类型。从相关BBs中的受污染指令、格式字符串和库调用中提供多维语义特征来训练模型。通过这种方式,AIFORE不需要额外的手动定义规则
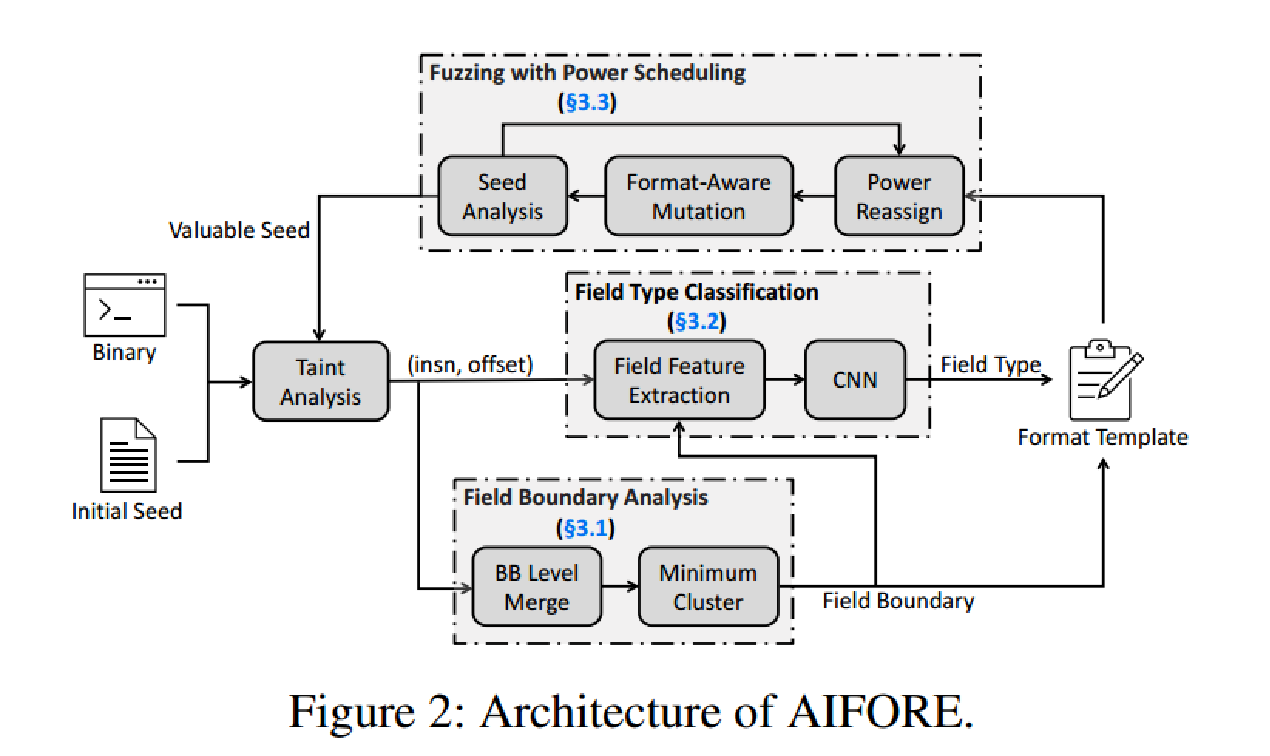
方法
如下图所示为AIFORE的基本框架,在模糊测试期间,如果一个种子带来的覆盖增量是可区分的(即,增加平均覆盖率的3%),那么我们将其标记为有价值的种子。对于每个有价值的种子,我们使用AIFORE分析其格式,并使用包含提取的字段边界和字段类型知识的格式模型对文件进行模糊处理。AIFORE的核心观点是,输入格式知识可以从BBs处理输入文件的模式中推断出来。因此,AIFORE利用污染分析来构建输入字节和处理它们的BB之间的映射。图3演示了取自readelf的两个BB,它们解析图一示例中的输入格式。每条指令末尾的注释列出了它处理的输入字节的偏移量,由污染分析引擎跟踪。
考虑到每条指令处理的输入字节的知识,以上三个模块共同反转输入格式,平衡对种子的模糊能力。第一个模块分析字段边界并将输入拆分为字段,即具有相同语义的连续字节对程序行为的影响。第二个模块通过基于cnn的模型预测字段类型信息,该模型经过训练以理解程序如何解析不同类型的字段。字段边界和字段类型由格式模板(即peach file)组成。对于每个字段,我们记录其边界及其起始位置、大小和类型。最后一个模块将决定哪些种子值得格式提取,并将对那些较少变异的格式重新分配更多的能量。
字段边界识别
如下图所示,以readelf的两个基本块为例,收集并合并每个基本块中处理的输入字节,例如在图三中第一个BB在偏移量18和19处处理来那个个输入字节,第二个基本块处理偏移量为16-19和40-51的输入字节。接下来根据每个块的污染属性拆分字段,包括一般的BB和特定于字段的BB。对于连续字节的每个最小集群(MC),在所有BB中作为一个整体处理,因为将被识别为同一个字段,如18和19字节。

字段类型识别
这篇论文主要支持这几种字段:Size,Enumeration,Magic number, String ,Checksum, Offset。
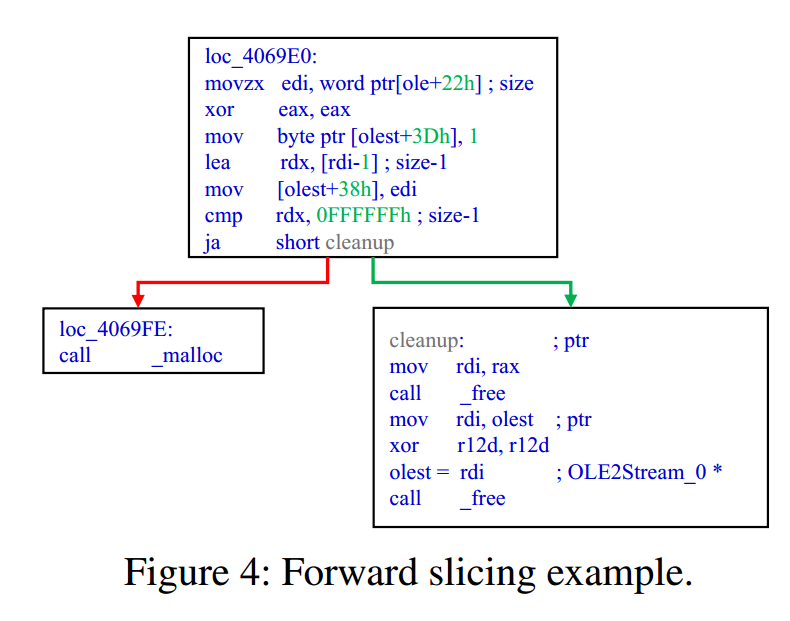
给定一个输入字段,首先确定其类型,定位其偏移量,然后从污染分析结果中过滤处理该字段的相关BB。对于每个相关BB,执行前向切片,以合并具有给定字段重要语义依赖的连续子BB。
以图4中的代码片段为例。size字段在第一个块中加载,并与阈值进行比较,然后由连续子块中的malloc调用使用。将代码向前切片以合并这两个块,这样我们就可以了解malloc将使用该字段并收集更有意义的特性。
数据向量化
如下图所示为数据向量的实现代码,(1)首先将BBs中的指令转换为中间表示(IR),对单热编码对应的IR操作进行矢量化。(2)接下来将标准库调用的使用作为一个重要的语义信息,首先选择一组常见的标准库函数,如memcpy、strcpy和malloc。对于这样的库函数的每次调用,将其记录为一次热编码。(3)记录BB中使用的格式字符串,并将其统计到语义信息特征中。例如,%x表示一个整数,而%s可能表示字符串的一个字段。该特性也以单热编码方式呈现。
将上述特征的这三部分(算法2中第26行右侧)连接起来,得到切片的特征向量。如果一个字段由多个代码切片处理,那么这些切片的向量将被加在一起(第26行左侧),以获得该字段的总体特征向量。
接下来本文使用(特征向量,字段类型)对来训练神经网络模型。

能量分配策略
如下图所示为它的能量调度策略,首先,AIFORE会尝试分析初始种子,建立其格式模型(第3 ~ 5行)。然后,fuzzer会在格式知识的指导下对种子进行变异(第7行)。如果新变异的种子有价值,重新分析其格式(第19 ~ 21行)。当模糊器卡住时(即,模糊器在给定时间内无法获得新的覆盖范围),将把模糊能力分配给那些尚未完全变异的格式(第8行到第12行)。

实验测评
格式提取性能
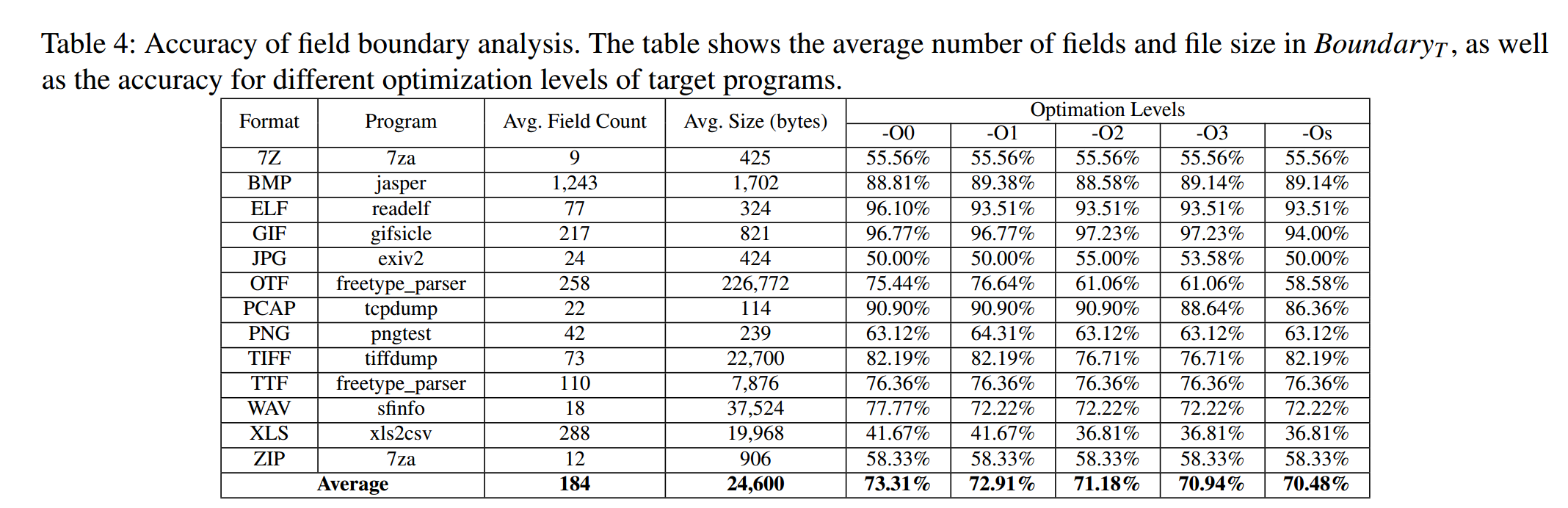
如上图所示,可以看到倒数第1到5行说明,格式抽取性能精度与编译器优化级别无关。这是由于MC方法是从语义块的角度考虑的,很少受到编译器优化的影响。同时作者手动分析了准确率较低的目标,发现原因是程序以自己的方式解析字段,在规范中被定义为一个整体却由于在不同BB解析而被分成不同字段,作者认为因为模糊测试是测试程序的实现,而不是与规范相比提取准确的字段边界,因此这并不会影响模糊效率。
字段类型准确的
如下图所示,通过图中可以得出结论:字段类型精确度与编译器优化级别有关,同时字段类型识别的平均准确率在85%以上,混合编译器优化后的精度结果是稳定的,说明该模型适用于实际情况。
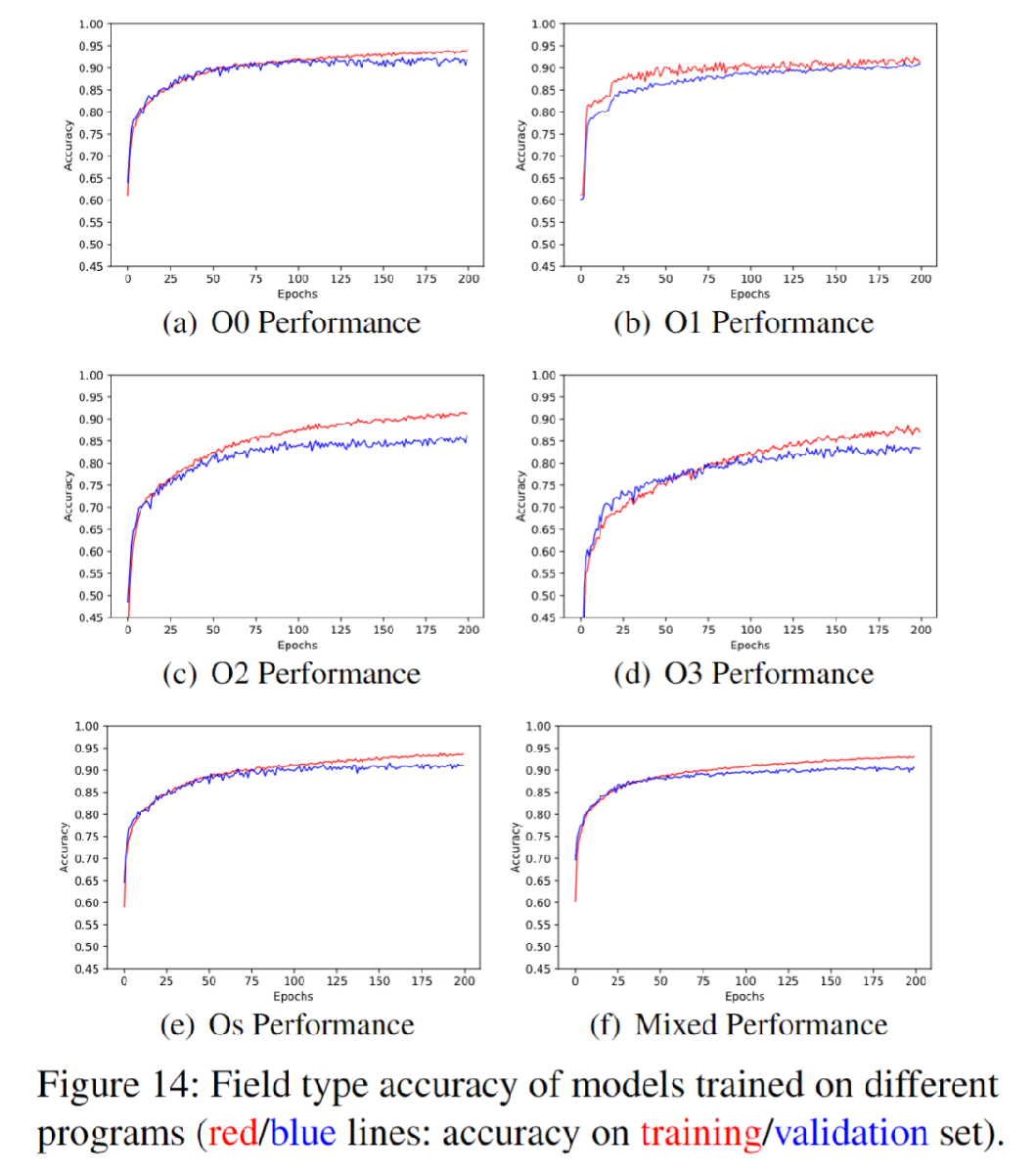
需要的模型训练数据量
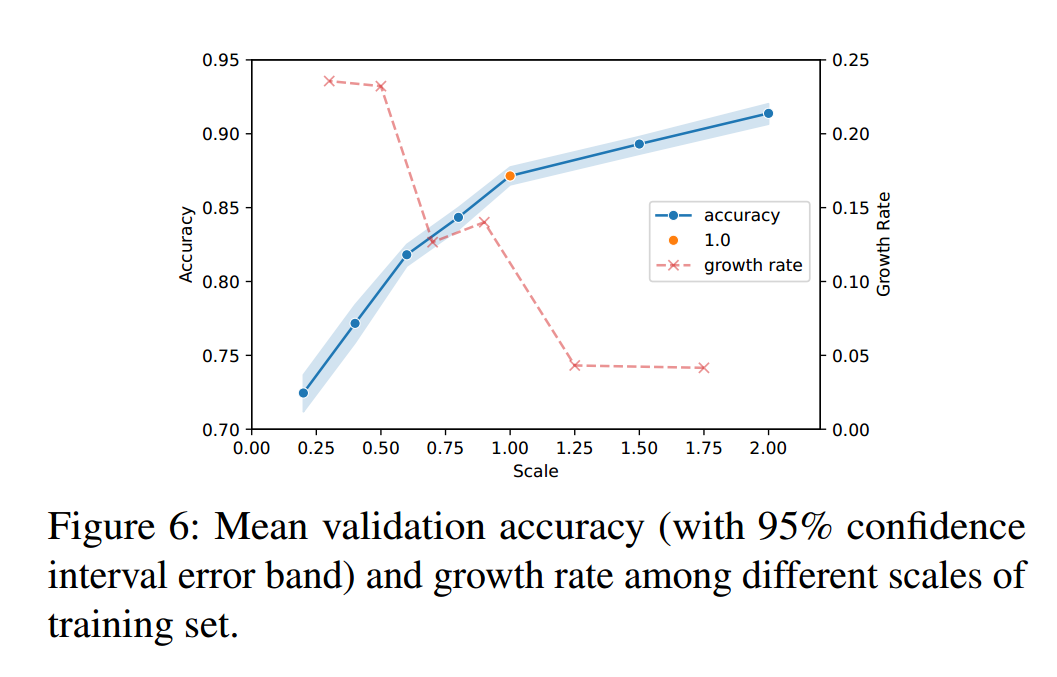
如下图所示,作者测试了需要多少数据来训练一个足够可靠的CNN模型,以10582个字段为单位尺度,通过对比可得出结论:训练数据量越大,模型精度越高。然而,当规模大于1.0时,增长率迅速停滞。
字段类型预测
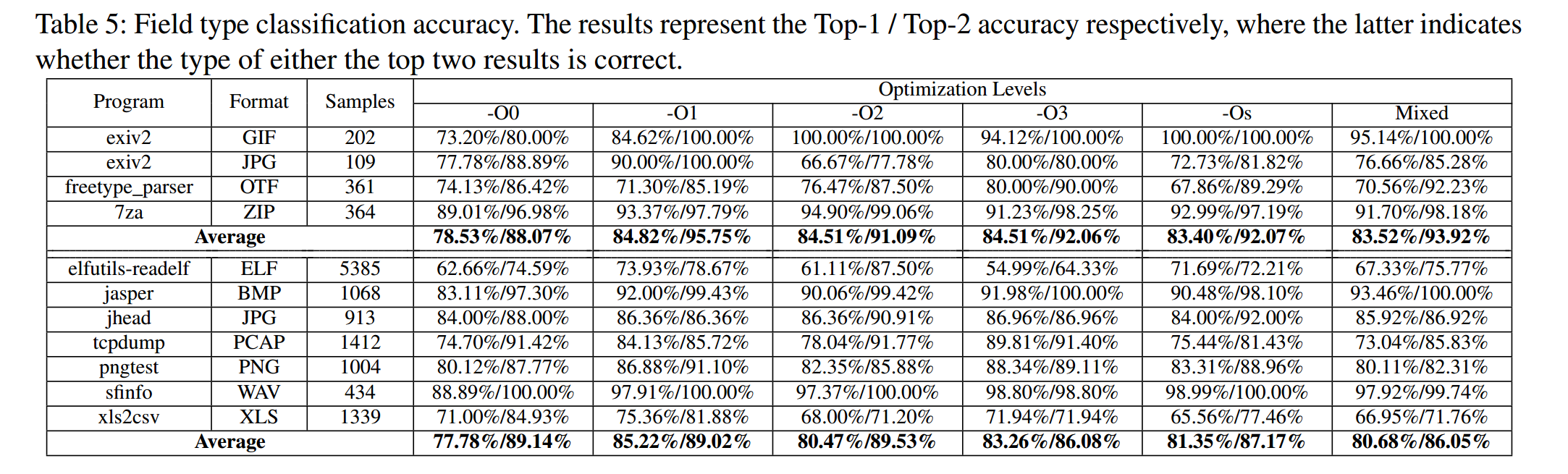
如下图所示,作者进行了两组实验,分别验证经过训练和未经训练的程序,模型能否预测它们看不见的输入格式,结果如下:对于经过训练的未见字段的预测,AIFORE对未见格式的字段类型预测准确率较高,Top-1的平均准确率在80%以上,Top-2的平均准确率在90%以上;模型性能与程序优化水平无关。尽管编译器优化可能会改变代码的特性,但模型可以通过优化学习稳定的模式对于未经训练的程序预测:Top1的平均精确度到达81%,top2为88%。
格式提取比较
如下图所示,表6显示了字段边界和类型分析的准确性,表7分别显示了解析输入的平均时间成本。
从表6可以看出,AIFORE在字段边界识别和字段类型预测方面都有较高的准确率。AIFORE在经过训练的项目中的表现优于未经训练的项目。
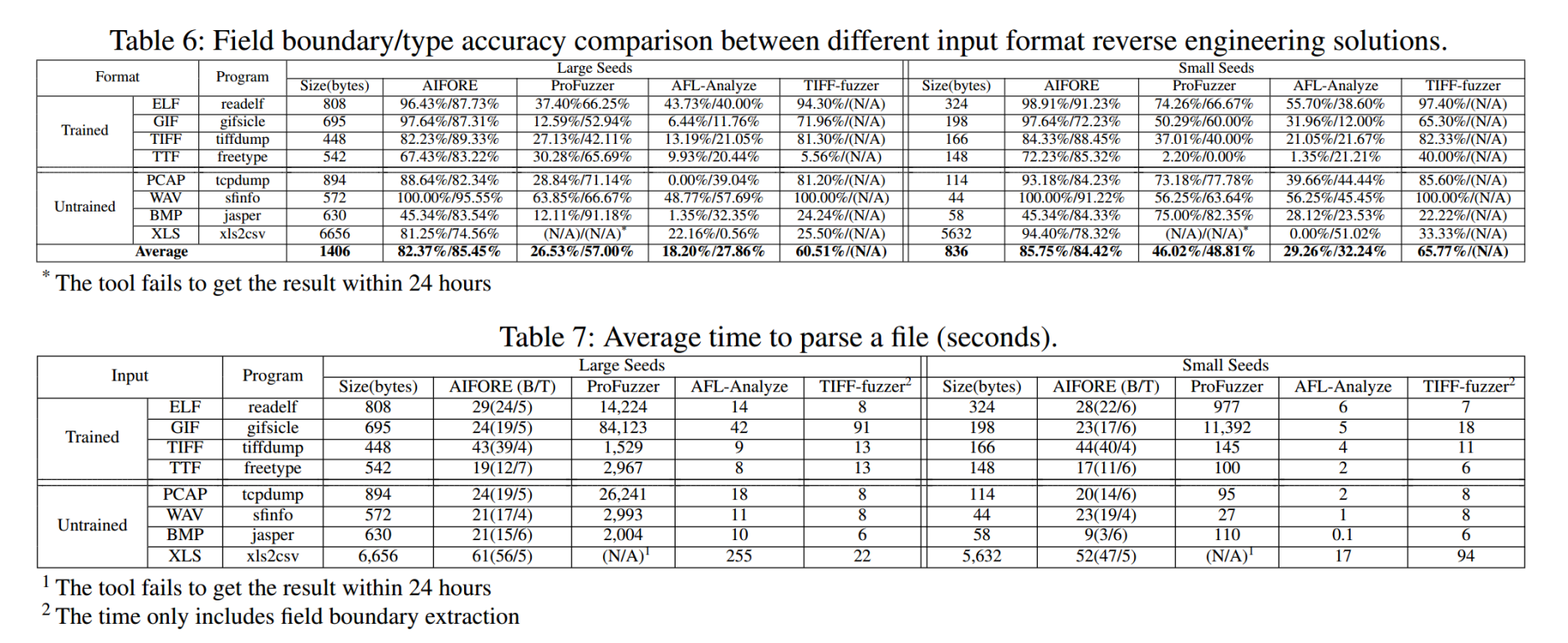
对于不同大小的类,使用AIFORE(和TIFFfuzzer)解析文件的平均时间没有显著差异,而ProFuzzer和AFL-Analyze在解析较大文件上花费的时间要多得多。由于AFLAnalyze和TIFF-fuzzer进行了一些粗略的分析,因此它们具有更好的执行时间,但平均精度低于AIFORE。
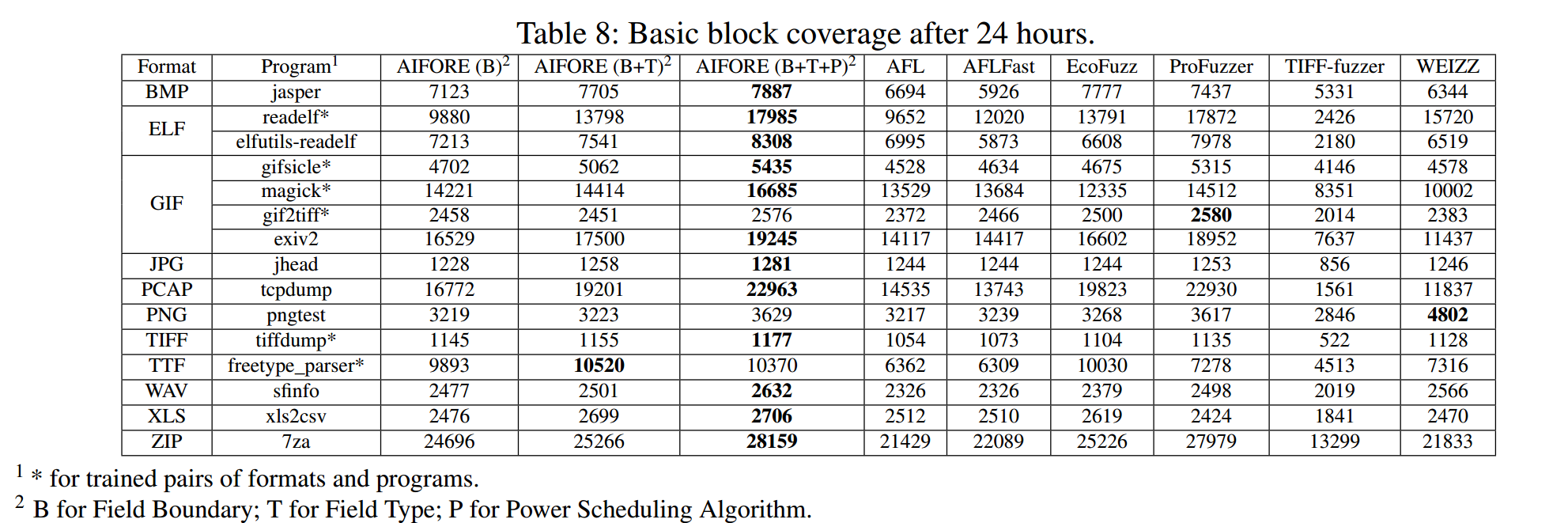
模糊性能
如下图所示为基本块覆盖信息,AIFORE显著提高了除pngtest外的大多数目标的覆盖率,而pngtest是WEIZZ表现最好的目标。原因是WEIZZ不仅可以检测文件中的校验和字段,还可以纠正校验和值。然而,AIFORE不支持校验和值校正,即使它能意识到该字段是校验和字段。对于所有目标,AIFORE (B+T+P)(即启用字段边界、类型分析和利用能量调度算法)与ProFuzzer和WEIZZ相比,平均增量分别为6%和26%。
其次,AIFORE的覆盖增量是显著的,即使目标程序和文件格式是不可见的。
发现bug
AIFORE在人工重复数据删除后共发现34个bug(20个是其他fuzzers发现的),其中缓冲区移除漏洞10个(CWE-122), NULL指针解引用bug 18个(CWE-476), double-free bug 6个(CWE-617)。
在其他fuzzers发现的20个bug中,有18个是供应商之前已经知道的。AIFORE在最新版本的xls2csv中发现了2个漏洞。
各个模块功能
如table 8 所示,边界识别模块帮助AIFORE对语义相同且属于同一字段的字节进行变异,使AIFORE比AFL多覆盖9.3%的BB,AIFORE利用人工智能模型来预测字段的类型,这有助于模糊器了解如何突变。得益于字段类型预测模块,AIFORE为所有目标平均增加了6.9%的代码覆盖率,AIFORE采用了一种新颖的能量调度算法,帮助模糊器将更多的能量分配给那些没有充分突变的格式。它带来了8.8%的覆盖率增长。
不足
- 方法基本上依赖于动态污染分析:因此,AIFORE的关键限制是程序如何解析输入会严重影响结果。例如,如果程序不解析某些字段,AIFORE就无法提取格式知识。此外,如果程序单独解析字段的单个字节,AIFORE可能会产生误报。可以通过将输入提供给几个可以解析这种格式的程序来克服这个问题
- 分析以字节粒度运行,这意味着不能分析位级字段。支持位级分析在技术上是可能的,但需要进一步的工程和优化。字节级分析还表明AIFORE不支持基于文本的输入。基于文本的输入的最小单位是关键字,而不是字节
字段,AIFORE就无法提取格式知识。此外,如果程序单独解析字段的单个字节,AIFORE可能会产生误报。可以通过将输入提供给几个可以解析这种格式的程序来克服这个问题 - 分析以字节粒度运行,这意味着不能分析位级字段。支持位级分析在技术上是可能的,但需要进一步的工程和优化。字节级分析还表明AIFORE不支持基于文本的输入。基于文本的输入的最小单位是关键字,而不是字节
- 很难分析输入加密或代码混淆的情况(例如恶意软件或勒索软件)。加密输入中没有明显的格式信息,开发人员还可以使用混淆代码来隐藏解析文件的操作模式