- 《SimCSE: Simple Contrastive Learning of Sentence Embeddings》EMNLP 2021 (CCF-B) Tianyu Gao†∗ Xingcheng Yao‡∗ Danqi Chen†
- 作者来自普林斯顿计算机系和清华大学交叉信息研究院
- Code & Pre-trained Models
【研究对象】:Sentence Embedding;
【研究方法】:对比学习;
【评估任务】:STS Task(语义文本相似度);
【研究问题】:语言 embedding 表示中的各向异性问题;
@inproceedings{gao2021simcse,
title={{SimCSE}: Simple Contrastive Learning of Sentence Embeddings},
author={Gao, Tianyu and Yao, Xingcheng and Chen, Danqi},
booktitle={Empirical Methods in Natural Language Processing (EMNLP)},
year={2021}
}
Abstract
本文介绍了 SimCSE,一个简单的对比学习框架,极大地推进了 state-of-the-art sentence embedding。首先介绍了一种无监督学习方法,takes an input sentence and predicts itself in a contrastive objective, with only standard dropout used as noise.这种简单的方法效果出奇地好,与以前的监督方法相当. We find that dropout acts as minimal data augmentation, and removing it leads to a representation collapse.然后我们提出了一种监督方法,which incorporates annotated pairs from natural language inference datasets into our contrastive learning framework by using “entailment” pairs as positives and “contradiction” pairs as hard negatives。
在 standard semantic textual similarity (STS) tasks 上评估了 SimCSE,our unsupervised and supervised models using B E R T b a s e BERT_{base} BERTbase achieve an average of 76.3% and 81.6% Spearman’s correlation respectively, a 4.2% and 2.2% improvement compared to the previous best results. 本文还从理论上和经验上证明,contrastive learning objective regularizes pre-trained embeddings’ anisotropic space to be more uniform,and it better aligns positive pairs when supervised signals are available。
1 Introduction
学习通用的句子嵌入是NLP中的一个基本问题。本文推进了当前最前沿的方法,并证明与 BERT、RoBERTa 等预训练模型结合时对比目标可能非常有效。
无监督 SimCSE 只在把 dropout 作为噪声的情况下预测输入的句子自身,换句话说,将同一个句子传递给预训练编码器两次:也即利用标准的 dropout 两次,然后我们可以获得两个不同的 embeddings 作为正例对。然后我们采用 mini-batch 中的其他句子作为负例,模型需要在其中预测出正例。尽管看起来很简单,但这种方法大幅优于如 predicting next sentences、discrete data augmentation 这类的训练目标,甚至与监督的方法相当。我们认为这里的 dropout 实际上相当于最小形式的数据增强,删除它会导致模型的表示崩溃。
监督 SimCSE 在 natural language inference (NLI) datasets for sentence embeddings 的基础上,在对比学习中加入了 annotated sentence pairs。Unlike previous work that casts it as a 3-way classification task (entailment, neutral, and contradiction), we leverage the fact that entailment pairs can be naturally used as positive instances.We also find that adding corresponding contradiction pairs as hard negatives further improves performance. 这里也用了别的 labeled sentence-pair 数据集实验,但 NLI datasets 效果最好。
为了更好的理解 SimCSE,使用了 Wang and Isola (2020) 的分析工具,which takes alignment between semantically-related positive pairs and uniformityof the whole representation space to measure the quality of learned embeddings.【alignment 和 uniformity 是对比学习中比较重要的两种属性,可用于衡量对比学习的效果】Through empirical analysis, we find that our unsupervised SimCSE essentially improves uniformity while avoiding degenerated alignment via dropout noise, thus improving the expressiveness of the representations.并且 NLI 数据中的监督信号可以进一步提高正例之间的对齐,产生更好的句子嵌入。We also draw a connection to the recent findings that pre-trained word embeddings suffer from anisotropy【各向异性】 (Ethayarajh, 2019; Li et al., 2020) and prove that—through a spectrum perspective—the contrastive learning objective “flattens” the singular value distribution【奇异值分布】 of the sentence embedding space, hence improving uniformity.
本文在 7 个 STS 任务和 7 个迁移任务上对 SimCSE 进行了全面评估,均取得不错的效果。
2 Background: Contrastive Learning
Contrastive learning aims to learn effective representation by pulling semantically close neighbors together and pushing apart non-neighbors (Hadsell et al., 2006).

本文 follow the contrastive framework in Chen et al. (2020),对 in-batch negatives 采用交叉熵目标,下面的 h 是 x 的 embedding,一个带有 N pairs 的 mini-batch 的训练目标是:
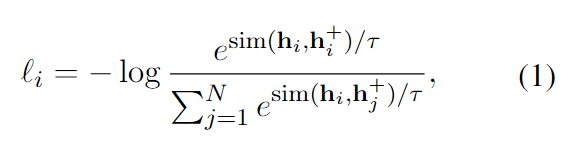

τ
τ
τ是温度超参数,本文使用 BERT 或者 RoBERTa 来对输入进行编码。
Positive instances:关键问题是如何构建正例对,由于自然语言的离散性质,NLP 上的数据增强相对困难。本文的发现是在中间表示上简单地使用 dropout 比这些离散运算的数据增强效果更好。
在监督数据上, ( x i , x i + ) (x_i,x_i^+) (xi,xi+) 通常是类似 question-passage pairs 这样的具有不同性质的文本,因此通常用双编码器(dual-encoder)来处理。在 Sentence Embedding 场景,一种做法是把当前句子和下一句作为 ( x i , x i + ) (x_i,x_i^+) (xi,xi+),然后用 dual-encoder 处理。
Alignment and uniformity:
-
alignment 计算所有正样本对之间的距离,如果 alignment 越小,则正样本的向量越接近,对比学习效果越好,计算公式如下:

-
uniformity 表示所有句子向量分布的均匀程度,越小表示向量分布越均匀,对比学习效果越好,计算公式如下:

p d a t a p_{data} pdata 代表数据分布,这俩指标与对比学习的目标很好的契合,正例应该尽可能接近,随机实例的embedding应该尽可能分散在超球面上。
3 Unsupervised SimCSE

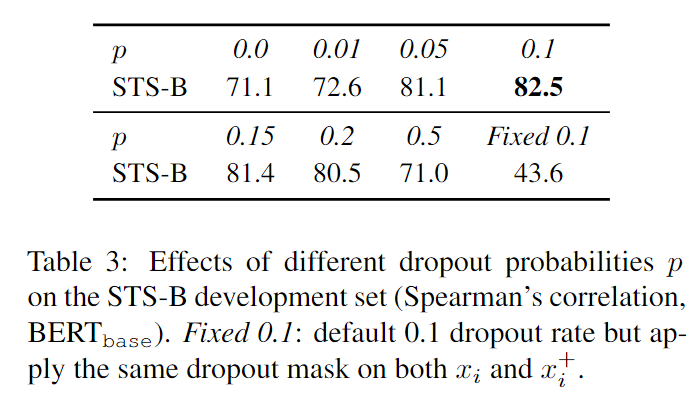
关键点上面其实已经提到了,就是自我对照,但用了独立的 dropout masks 采样。本文和标准的 Transformer 结构中 dropout masks 放置于全连接层中且 p=0.1 的设置相同。定义 z 表示 dropout 的随机 mask,把一句话在不同的 dropout mask 的情况下喂进两次:

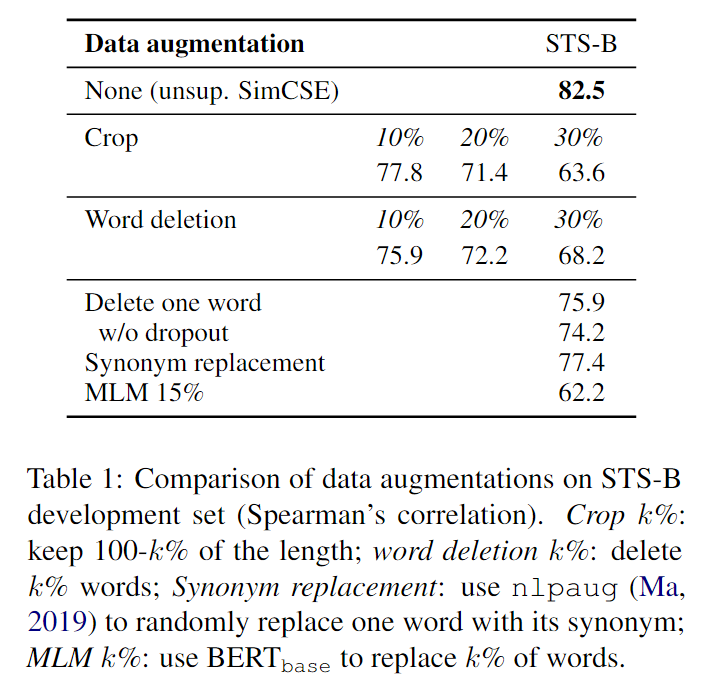
Dropout noise as data augmentation:将本文的方法与 STS-B development set 上的其他训练目标对比,证明 dropout 效果最好。还将自我预测这种方法与预测下一句的目标进行比较,也证明本文方法更好。

Why does it work? take the checkpoints of these models every 10 steps during training and visualize the alignment and uniformity metrics in Figure 2,along with a simple data augmentation model “delete one word”。预训练的起点也很重要,提供了一个良好的初始对齐。

4 Supervised SimCSE
此处研究利用监督数据集来提供更好的对齐。
Choices of labeled data:探索了哪些数据集比较合适用来构造正例,1)QQP:Quora question pairs;2)Flickr30k:each image is annotated with 5 human-written captions and we consider any two captions of the same image as a positive pair;3)ParaNMT:a large-scale back-translation paraphrase dataset;4)NLI datasets: SNLI and MNLI;
为了公平,训练数据量保持相同。NLI 数据集标注质量更高。

Contradiction as hard negatives:使用 NLI 数据集中的 contradiction pairs 作为 hard negatives。In NLI datasets, given one premise, annotators are required to manually write one sentence that is absolutely true (entailment), one that might be true (neutral), and one that is definitely false (contradiction).

其他做过的实验:在有监督数据上增加 ANLI dataset 或者将 ANLI dataset 与无监督结合,或者使用DualEncoder,但结果没有明显改进或更差。
5 Connection to Anisotropy
最近的工作确定了语言表示中的各向异性问题,即学习的嵌入在向量空间中占据一个狭窄的圆锥体,这严重限制了它们的表达能力。Gao et al. (2019) 证明 language models trained with tied input/output embeddings lead to anisotropic word embeddings。缓解该问题的一个简单方法是后处理,either to eliminate the dominant principal components、or to map embeddings to an isotropic distribution。另一个常见措施是添加正则化,但本文证明,对比目标也可以解决该问题(并且效果更好)。
各向异性问题自然与均匀性有关,两者都强调嵌入应该均匀分布在空间中。直观地说,优化对比学习目标可以提高一致性(或缓解各向异性问题),因为目标让负例更远。这里以 singular spectrum perspective 的视角来看,结果表明,对比目标可以“扁平化”句子嵌入的奇异值分布,使表示趋于各向同性。【下面的证明感兴趣的可以自己看】



6 Experiment
略。
6.1 Evaluation Setup
对 7 个语义文本相似性 (STS) 任务(无监督)和 7 个迁移学习任务进行了实验。
6.2 Main Results
6.3 Ablation Studies
7 Analysis
略。
8 Related Work
略。
9 Conclusion
- 提出了 SimCSE 并在 STS 任务上评估;提出一种无监督方法,该方法在带有 dropout 噪声的情况下预测自身的输入,以及一种利用 NLI 数据集的监督方法。
- We further justify the inner workings of our approach by analyzing alignment and uniformity of SimCSE along with other baseline models.
- 本文中的 contrastive objective 尤其是无监督下的,具有广泛应用前景,It provides a new perspective on data augmentation with text input, and can be extended to other continuous representations and integrated in language model pre-training。