今日内容
零、 复习昨日
零、 复习昨日
一、MybatisPlus快速入门

[MyBatis-Plus](简介 | MyBatis-Plus (baomidou.com))(简称 MP)是一个 MyBatis的增强工具,在 MyBatis 的基础上
只做增强不做改变,为简化开发、提高效率而生。官方网站:baomidou.com
mybatis: 半ORM框架
mp: 全ORM
1.1 创建数据库
create database mybatisplus;
DROP TABLE IF EXISTS user;
CREATE TABLE user (
id BIGINT(20) PRIMARY KEY NOT NULL COMMENT '主键',
name VARCHAR(30) DEFAULT NULL COMMENT '姓名',
age INT(11) DEFAULT NULL COMMENT '年龄',
email VARCHAR(50) DEFAULT NULL COMMENT '邮箱',
manager_id BIGINT(20) DEFAULT NULL COMMENT '直属上级id',
create_time DATETIME DEFAULT NULL COMMENT '创建时间'
) ENGINE=INNODB CHARSET=UTF8;
INSERT INTO user (id, name, age ,email, manager_id, create_time) VALUES
(1, '大BOSS', 40, 'boss@baomidou.com', NULL, '2023-03-22 09:48:00'),
(2, '李经理', 40, 'boss@baomidou.com', 1, '2023-01-22 09:48:00'),
(3, '黄主管', 40, 'boss@baomidou.com', 2, '2023-01-22 09:48:00'),
(4, '吴组长', 40, 'boss@baomidou.com', 2, '2023-02-22 09:48:00'),
(5, '小菜', 40, 'boss@baomidou.com', 2, '2023-02-22 09:48:00')
1.2 创建springboot项目
1.3 导入依赖
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<!-- 当前项目信息 -->
<groupId>com.taotie</groupId>
<artifactId>mybatisplus</artifactId>
<version>1.0-SNAPSHOT</version>
<!-- sb父工程 -->
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.7.2</version>
<relativePath/>
</parent>
<properties>
<java.version>1.8</java.version>
</properties>
<dependencies>
<!-- springboot入口 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter</artifactId>
</dependency>
<!-- 单元测试 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<scope>test</scope>
</dependency>
<!-- mybatisplus -->
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-boot-starter</artifactId>
<version>3.5.3</version>
</dependency>
<!-- mysql驱动 -->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.47</version>
</dependency>
<!-- 连接池 -->
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid-spring-boot-starter</artifactId>
<version>1.2.15</version>
</dependency>
<!-- 小辣椒 -->
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
</dependency>
<!-- 代码生成器 -->
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-generator</artifactId>
<version>3.5.3</version>
</dependency>
<!-- 代码生成器模板引擎 -->
<dependency>
<groupId>org.freemarker</groupId>
<artifactId>freemarker</artifactId>
</dependency>
</dependencies>
</project>
1.4 yaml文件
# application.yml
spring:
datasource: # 数据源配置
driver-class-name: com.mysql.jdbc.Driver
url: jdbc:mysql://localhost:3306/mybatisplus?serverTimezone=Asia/Shanghai&useSSL=false
username: root
password: 123456
# mybatis-plus配置,也可以不加,只是为了显示SQL,Springboot都自动配置好了
mybatis-plus:
configuration:
log-impl: org.apache.ibatis.logging.stdout.StdOutImpl
1.5 创建实体类
@Data
public class User {
private Long id;
private String name;
private Integer age;
private String email;
private Long managerId;
private Date createTime;
}
1.6 创建mapper接口,继承mp基础接口
public interface UserMapper extends BaseMapper<User>{
}
1.7 主启动类
@SpringBootApplication
@MapperScan("com.taotie.mapper")
public class MybatisPlusApplication {
public static void main(String[] args) {
SpringApplication.run(MybatisPlusApplication.class, args);
}
}
1.8 测试
使用SpringBoot测试,暂时无web页面,纯java测试
import com.taotie.MybatisPlusApplication;
import com.taotie.mapper.UserMapper;
import com.taotie.model.User;
import org.junit.Test;
import org.junit.runner.RunWith;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.test.context.junit4.SpringRunner;
import java.util.List;
// springboot的单元测试
@RunWith(SpringRunner.class)
@SpringBootTest(classes = MybatisPlusApplication.class)
public class TestMybatisPlus {
@Autowired
private UserMapper mapper;
@Test
public void testSelect() {
// 查询全部,不需要条件
List<User> list = mapper.selectList(null);
for (User user : list) {
System.out.println(user );
}
}
}
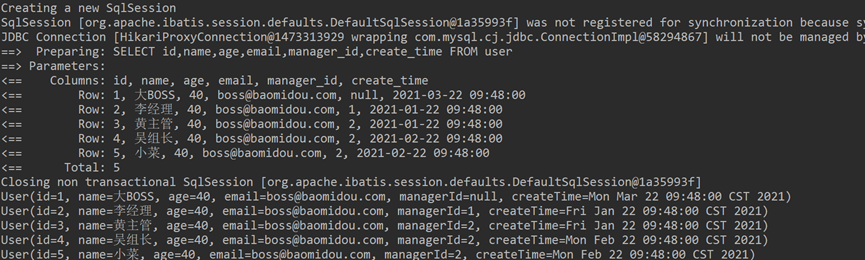
二、基础CRUD接口
2.1 Mapper层接口[重点]
只需定义好实体类,然后创建一个XxxMapper接口,继承mp提供的BaseMapper,即可使用。mp会在mybatis启动时,自动解析实体类和表的映射关系,并注入带有通用CRUD方法的mapper。BaseMapper里提供的方法,部分列举如下:
insert(T entity) 插入一条记录
deleteById(Serializable id) 根据主键id删除一条记录
delete(Wrapper wrapper) 根据条件构造器wrapper进行删除
selectById(Serializable id) 根据主键id进行查找
selectBatchIds(Collection idList) 根据主键id进行批量查找
selectByMap(Map<String,Object> map) 根据map中指定的列名和列值进行等值匹配查找
selectMaps(Wrapper wrapper) 根据 wrapper 条件,查询记录,将查询结果封装为一个Map,Map的key为结果的列,value为值
selectList(Wrapper wrapper) 根据条件构造器wrapper进行查询
update(T entity, Wrapper wrapper) 根据条件构造器wrapper进行更新
updateById(T entity)
其他…
2.1.1 基础crud演示
@RunWith(SpringRunner.class)
@SpringBootTest(classes = MybatisPlusApplication.class)
public class TestMybatisPlus {
@Autowired
private UserMapper mapper;
/**
* 无条件查全部
*/
@Test
public void testSelectAll() {
List<User> list = mapper.selectList(null);
for (User user : list) {
System.out.println(user);
}
}
/**
* 根据条件查一个
*/
@Test
public void testSelectOne() {
User user = mapper.selectById(1);
System.out.println(user);
}
/**
* 增加
*/
@Test
public void insertOne() {
User user = new User( );
user.setId(7L);
user.setName("茅十八");
user.setAge(18);
user.setEmail("237876777@qq.com");
user.setCreateTime(new Date( ));
user.setManagerId(1L);
mapper.insert(user);
}
/**
* 修改
* 根据对象修改,如果对象属性为null,则忽略该字段不修改.
*/
@Test
public void updateOne() {
User user = new User( );
user.setId(6L);
user.setName("奥特曼66");
user.setAge(200);
user.setManagerId(2L);
mapper.updateById(user);
}
/**
* 删除
*/
@Test
public void deleteOne() {
// 注意参数,是long型,否则会出现ClassCastException
int i = mapper.deleteById(6L);
System.out.println("受影响行数 : " + i);
}
}
2.1.2 特殊的查询返回
selectMaps
BaseMapper接口还提供了一个selectMaps方法,这个方法会将查询结果封装为一个Map,Map的key为结果的列,value为值
该方法的使用场景如下:
只查部分列
/**
* selectMaps方法演示
*/
@Test
public void testSelectMaps() {
// 创建条件构造器
QueryWrapper<User> wrapper = new QueryWrapper<>( );
// 设置要查询的列 like模糊查询,name列 模糊值"李"
wrapper.select("id", "name", "email").like("name", "李");
// selectMaps将查询结果封装到Map中,多个map存放在List中
List<Map<String, Object>> maps = mapper.selectMaps(wrapper);
for (Map<String, Object> map : maps) {
for (Map.Entry<String,Object> entry: map.entrySet()) {
System.out.print(entry.getKey() +" = " + entry.getValue() +" | ");
}
System.out.println( );
}
}
进行数据统计
比如,按照直属上级进行分组,查询每组的平均年龄,最大年龄,最小年龄
@Test
public void testSelectMaps2() {
QueryWrapper<User> wrapper = new QueryWrapper<>( );
wrapper.select("manager_id", "avg(age) avg_age", "min(age) min_age", "max(age) max_age").groupBy("manager_id");
List<Map<String, Object>> maps = mapper.selectMaps(wrapper);
for (Map<String, Object> map : maps) {
System.out.println(map);
}
}
2.2 Service层接口(了解)
另外一套CRUD是Service层的,只需要编写一个业务层接口,继承IService,并创建一个接口实现类,即可使用。(这个接口提供的CRUD方法,和Mapper接口提供的功能大同小异,比较明显的区别在于IService支持了更多的
批量化操作,如saveBatch,saveOrUpdateBatch等方法。
通用 Service CRUD 封装IService (opens new window)接口,进一步封装 CRUD 采用
get 查询单行remove 删除list 查询集合page 分页前缀命名方式区分Mapper层避免混淆,
使用步骤
1 首先,新建一个业务层接口,继承IService接口
public interface UserService extends IService<User> {
}
2 创建这个接口的实现类,继承ServiceImpl加上泛型,同时实现我们自己的业务层接口,最后打上@Service注解,注册到Spring容器中
@Service
public class UserServiceImpl extends ServiceImpl<UserMapper,User> implements UserService {
}
3 测试
@RunWith(SpringRunner.class)
@SpringBootTest(classes = MybatisPlusApplication.class)
public class ServiceTest {
@Autowired
private UserService userService;
@Test
public void testGetOne() {
// 创建查询条件
QueryWrapper<User> wrapper = new QueryWrapper<>( );
// 根据列 age = 28 查找
wrapper.eq("age",28);
// 第二参数指定为false,使得在查到了多行记录时,不抛出异常,而返回第一条记录
User one = userService.getOne(wrapper, false);
System.out.println(one);
}
}
三、条件构造器[重点]
mp提供了强大的条件构造器Wrapper,可以非常方便的构造WHERE,GROUP BY,ORDERBY,HAVING等条件查询语句。
条件构造器主要涉及到3个类,AbstractWrapper。QueryWrapper,UpdateWrapper,它们的类关系如下
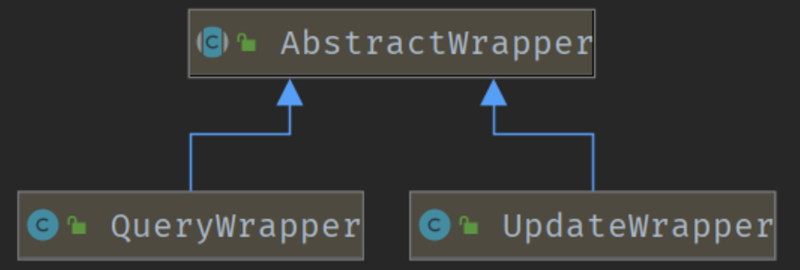
在AbstractWrapper中提供了非常多的方法用于构建WHERE条件,而QueryWrapper针对SELECT语句,提供了select()方法,可自定义需要查询的列,而UpdateWrapper针对UPDATE语句,提供了set()方法,用于构造set语句。
AbstractWrapper中常用api介绍
| API | SQL符号 | 示例 |
|---|---|---|
| eq(R column, Object val) | = | eq(“name”, “老王”) —> name = ‘老王’ |
| ne(R column, Object val); | <> != | ne(“name”, “老王”) —> name <> ‘老王’ |
| gt(R column, Object val); | > | gt(“name”, “老王”) —> name > ‘老王’ |
| ge(R column, Object val); | >= | ge(“name”, “老王”) —> name >= ‘老王’ |
| lt(R column, Object val); | < | lt(“name”, “老王”) —> name < ‘老王’ |
| le(R column, Object val); | <= | le(“name”, “老王”) —> name <= ‘老王’ |
| between(R column, Object val1, Object val2) | between a and b | between(“age”, 18, 30) —> age between 18 and 30 |
| notBetween(R column, Object val1, Object val2); | not between a and b | notBetween(“age”, 18, 30) —> age not between 18 and 30 |
| in(R column, Object… values); | IN (v0, v1, …) | in(“age”,{1,2,3}) —> age in (1,2,3) |
| notIn(R column, Object… values); | NOT IN (v0, v1, …) | notIn(“age”,{1,2,3}) —> age not in (1,2,3) |
| inSql(R column, Object… values); | IN (sql 语句) | inSql(“id”, “select id from table where id < 3”) —> id in (select id from table where id < 3) |
| notInSql(R column, Object… values); | NOT IN (sql 语句) | |
| like(R column, Object val); | LIKE ‘%值%’ | like(“name”, “王”) —> name like ‘%王%’ |
| notLike(R column, Object val) | NOT LIKE ‘%值%’ | notLike(“name”, “王”) —> name not like ‘%王%’ |
| likeLeft(R column, Object val) | LIKE ‘%值’ | likeLeft(“name”, “王”) —> name like ‘%王’ |
| likeRight(R column, Object val) | LIKE ‘值%’ | likeRight(“name”, “王”) —> name like ‘王%’ |
| isNull(R column) | IS NULL | isNull(“name”) —> name is null |
| isNotNull(R column); | IS NOT NULL | isNotNull(“name”) —> name is not null |
| groupBy(R… columns) | GROUP BY | groupBy(“id”, “name”) —> group by id,name |
| having(String sqlHaving, Object… params) | HAVING ( sql语句 ) | having(“sum(age) > {0}”, 11) —> having sum(age) > 11 |
| orderByAsc(R… columns) | ORDER BY 字段, … ASC | orderByAsc(“id”, “name”) —> order by id ASC,name ASC |
| orderByDesc(R… columns); | ORDER BY 字段, … DESC | orderByDesc(“id”, “name”) —> order by id DESC,name DESC |
| or(); | a or b | eq(“id”,1).or().eq(“name”,“老王”) —> id = 1 or name = ‘老王’ |
| or(Consumer consumer) | or嵌套 | or(i -> i.eq(“name”, “李白”).ne(“status”, “活着”)) —> or (name = ‘李白’ and status <> ‘活着’) |
| and(Consumer consumer) | and嵌套 | and(i -> i.eq(“name”, “李白”).ne(“status”, “活着”)) —> and (name = ‘李白’ and status <> ‘活着’) |
| nested(Consumer consumer); | 普通嵌套 | nested(i -> i.eq(“name”, “李白”).ne(“status”, “活着”)) —> (name = ‘李白’ and status <> ‘活着’) |
| apply(String applySql, Object… params); | 拼接sql | apply(“date_format(dateColumn,‘%Y-%m-%d’) = {0}”, “2008-08-08”) —> date_format(dateColumn,‘%Y-%m-%d’) = ‘2008-08-08’") |
| last(String lastSql) | 无视优化规则直接拼接到 sql 的最后 | |
| exists(String existsSql) | 拼接 exists 语句 | exists(“select id from table where age = 1”) —> exists (select id from table where age = 1) |
3.1 QueryWrapper 查询操作
QueryWrapper在AbstractWrapper的基础上又有自己特殊的方法
| API | 解释 | 示例> |
|---|---|---|
| select(String… sqlSelect) | 用于指定查询需要返回的字段 | select(“id”, “name”, “age”) —> select id, name, age |
3.1.1 各种条件查询
// 1. 查找名字中包含佳,且年龄小于25
// 2. 查找姓名为黄姓,且年龄大于等于20,小于等于40,且email字段不为空
// 3. 查找姓名为黄姓,或者年龄大于等于40,按照年龄降序排列,年龄相同则按照id升序排列
// **4. 查找创建日期为2021年3月22日,并且直属上级的名字为李姓
// 5. 查找名字为王姓,并且(年龄小于40,或者邮箱不为空)
// 6. 查找名字为王姓,或者(年龄小于40并且年龄大于20并且邮箱不为空)
// 7. 查找(年龄小于40或者邮箱不为空) 并且名字为王姓
// 8. 查找年龄为30,31,34,35
// **9. 查找年龄为30,31,34,35, 返回满足条件的第一条记录
// **10. 查找只选出id, name 列 (QueryWrapper 特有)
// **11. 根据领导分组,查询组长id和每组人数
以下演示都是相当于是在基础查询 select * from tablename where后的条件构造
默认都是查询全部的列,如果想要要查询指定的列也可以使用select()方法
另外,条件构造连着.的调用,就相当于是and,并列条件
/**
* 1. 查找名字中包含佳,且年龄小于25
* SELECT * FROM user WHERE name like '%佳%' AND age < 25
*/
QueryWrapper<User> wrapper = new QueryWrapper<>( );
wrapper.like("name", "佳").lt("age", 25);
// 下面展示SQL时,仅展示WHERE条件;展示代码时, 仅展示Wrapper构建部分
/**
* 2. 查找姓名为黄姓,且年龄大于等于20,小于等于40,且email字段不为空
* name like '黄%' AND age BETWEEN 20 AND 40 AND email is not null
*/
wrapper.likeRight("name", "黄").between("age", 20, 40).isNotNull("email");
/**
* 3. 查找姓名为黄姓,或者年龄大于等于40,按照年龄降序排列,年龄相同则按照id升序排列
* name like '黄%' OR age >= 40 order by age desc, id asc
*/
wrapper.likeRight("name", "黄").or( ).ge("age", 40).orderByDesc("age").orderByAsc("id");
/**
* 4.查找创建日期为2021年3月22日,并且直属上级的名字为李姓
* date_format(create_time,'%Y-%m-%d') = '2021-03-22' AND manager_id IN (SELECT id FROM user WHERE name like '李%')
* sql语句中有in条件,Wrapper条件构造器使用inSql
*/
wrapper.apply("date_format(create_time, '%Y-%m-%d') = {0}", "2021-03-22") // 建议采用{index}这种方式动态传参, 可防止SQL注入
.inSql("manager_id", "SELECT id FROM user WHERE name like '李%'");
// 上面的apply, 也可以直接使用下面这种方式做字符串拼接,但当这个日期是一个外部参数时,这种方式有SQL注入的风险
wrapper.apply("date_format(create_time, '%Y-%m-%d') = '2021-03-22'");
/**
* 5. 查找名字为王姓,并且(年龄小于40,或者邮箱不为空)
* name like '王%' AND (age < 40 OR email is not null)
*
* 注意,上述sql语句与下方的结果不一样!!
* name like '王%' AND age < 40 OR email is not null
*/
// lambda写法
wrapper.likeRight("name", "王").and(a -> a.lt("age", 40).or( ).isNotNull("email"));
// 匿名内部类
wrapper.likeRight("name", "王").and(new Function<QueryWrapper<User>, QueryWrapper<User>>( ) {
@Override
public QueryWrapper<User> apply(QueryWrapper<User> userQueryWrapper) {
userQueryWrapper.lt("age",40).or().isNotNull("email");
return userQueryWrapper;
}
});
/**
* 6. 查找名字为王姓,或者(年龄小于40并且年龄大于20并且邮箱不为空)
* name like '王%' OR (age < 40 AND age > 20 AND email is not null)
*/
wrapper.likeRight("name", "王").or(
q -> q.lt("age", 40)
.gt("age", 20)
.isNotNull("email")
);
/**
* 7. 查找(年龄小于40或者邮箱不为空) 并且名字为王姓
* (age < 40 OR email is not null) AND name like '王%'
*/
wrapper.nested(q -> q.lt("age", 40).or( ).isNotNull("email"))
.likeRight("name", "王");
/**
* 8. 查找年龄为30,31,34,35
* age IN (30,31,34,35)
*/
wrapper.in("age", Arrays.asList(30, 31, 34, 35));
// 或
wrapper.inSql("age", "30,31,34,35");
/**
* 9. 查找年龄为30,31,34,35, 返回满足条件的第一条记录
* age IN (30,31,34,35) LIMIT 1
* 也可以这样 last(“limit 2,2”);
*/
wrapper.in("age", Arrays.asList(20, 28, 34, 35)).last("LIMIT 1");
/**
* 10. 查找只选出id, name 列 (QueryWrapper 特有)
* SELECT id, name FROM user;
*/
wrapper.select("id", "name");
List<User> users = mapper.selectList(wrapper);
// 11 分组
QueryWrapper<User> wrapper = new QueryWrapper<>( );
wrapper.groupBy("manager_id").select("manager_id","count(*)");
List<User> list = userMapper.selectList(wrapper);
for (User user : list) {
System.out.println(user);
}
3.1.2 Condition
条件构造器的诸多方法中,均可以指定一个boolean类型的参数condition,用来
决定该条件是否加入最后生成的WHERE语句中,比如
/**
* condition 条件构造器中的条件
* 决定是否拼接进sql语句
*/
@Test
public void testCondition() {
String name = "";
// 假设name变量是一个外部传入的参数
QueryWrapper<User> wrapper = new QueryWrapper<>( );
wrapper.like(StringUtils.hasText(name), "name", name);
// 仅当 StringUtils.hasText(name) 为 true 时, 会拼接这个like语句到WHERE中
// 其实就是对下面代码的简化
// if (StringUtils.hasText(name)) {
// wrapper.like("name", name);
// }
List<User> users = mapper.selectList(wrapper);
users.forEach(System.out::println);
}
3.2 UpdateWrapper 删改操作
上面介绍的都是查询操作,现在来讲更新和删除操作。BaseMapper中提供了几个个关于删改时携带条件的方法
- update(T entity, Wrapper wrapper)
- delete(Wrapper wrapper)
/**
* 根据实体+条件更新
*/
@Test
public void testEntityUpdate() {
// 修改age=40的人的名字为张全蛋
User user = new User();
user.setName("张全蛋");
UpdateWrapper<User> wrapper = new UpdateWrapper<>( );
wrapper.eq("age",40);
mapper.update(user, wrapper);
}
// 删除条件自行演示
四、分页查询[重点]
BaseMapper中提供了2个方法进行分页查询,分别是
selectPage和selectMapsPage,前者会将查询的结果封装成Java实体对象,后者会封装成Map<String,Object>。mp的分页需要配置类,类中定义拦截器
@Configuration
public class MybatisPlusConfig {
/**
* 新的分页插件,一缓和二缓遵循mybatis的规则,
* 需要设置 MybatisConfiguration#useDeprecatedExecutor = false 避免缓存出现问题(该属性会在旧插件移除后一同移除)
*/
@Bean
public MybatisPlusInterceptor mybatisPlusInterceptor() {
MybatisPlusInterceptor interceptor = new MybatisPlusInterceptor();
interceptor.addInnerInterceptor(new PaginationInnerInterceptor(DbType.MYSQL));
return interceptor;
}
}
测试,查询中使用分页即可
@Test
public void testPage() {
// 设置分页信息, 查第3页, 每页2条数据
Page<User> page = new Page<>(3,2 );
// IPage<Map<String, Object>> mapIPage = mapper.selectMapsPage(page, null);
// List<Map<String, Object>> records = mapIPage.getRecords( );
IPage<User> iPage = mapper.selectPage(page, null);
// 当前页
long current = iPage.getCurrent( );
// 当前分页总页数
long pages = iPage.getPages( );
// 当页记录
List<User> records = iPage.getRecords( );
// 当前分页数据数
long size = iPage.getSize( );
// 总条数
long total = iPage.getTotal( );
System.out.println("1" );
}
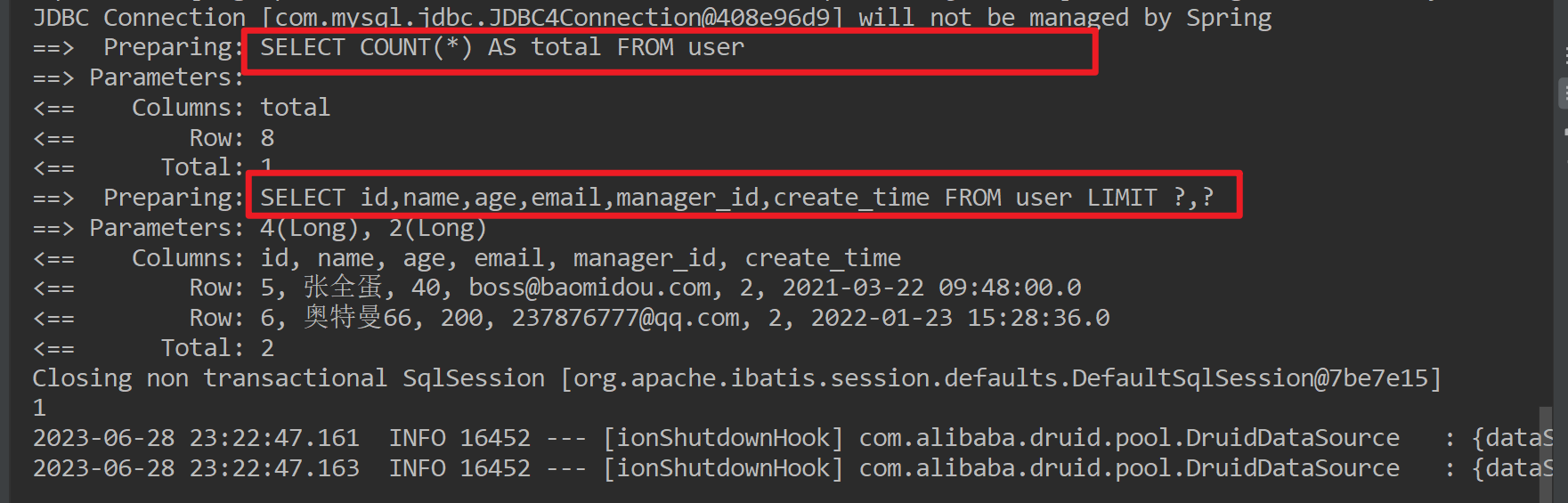
注意到,分页查询总共发出了2次SQL,一次查总记录数,一次查具体数据。若希望不查总记录数,仅查分页结果。可以通过Page的重载构造函数,指定isSearchCount为false,测试iPage.getTotal( );就不会有总条数
public Page(long current, long size, boolean isSearchCount)
五、主键策略
在定义实体类时,用@TableId指定主键,而其type属性,可以指定主键策略。
mp支持多种主键策略,默认的策略是基于雪花算法的自增id。全部主键策略定义在了枚举类IdType中,IdType有如下的取值:AUTO,NONE,INPUT,ASSIGN_ID,ASSIGN_UUID等
// 源码中解释 /** * 数据库ID自增 * <p>该类型请确保数据库设置了 ID自增 否则无效</p> */ AUTO(0), /** * 该类型为未设置主键类型(注解里等于跟随全局,全局里约等于 INPUT) */ NONE(1), /** * 用户输入ID * <p>该类型可以通过自己注册自动填充插件进行填充</p> */ INPUT(2), /* 以下2种类型、只有当插入对象ID 为空,才自动填充。 */ /** * 分配ID (主键类型为number或string), * 默认实现类 {@link com.baomidou.mybatisplus.core.incrementer.DefaultIdentifierGenerator}(雪花算法) * * @since 3.3.0 */ ASSIGN_ID(3), /** * 分配UUID (主键类型为 string) * 默认实现类 {@link com.baomidou.mybatisplus.core.incrementer.DefaultIdentifierGenerator}(UUID.replace("-","")) */ ASSIGN_UUID(4);可以针对每个实体类,使用@TableId注解指定该实体类的主键策略,这可以理解为局部策略,只对每个类生效。
若希望对所有的实体类,都采用同一种主键策略,挨个在每个实体类上进行配置,则太麻烦了,此时可以用主键的全局策略。只需要在application.yml进行配置即可。
mybatis-plus: global-config: db-config: id-type: auto
演示AUTO
数据库ID自增,依赖于数据库。在插入操作生成SQL语句时,不会插入主键这一列.
在User上对id属性加上注解,
然后将MYSQL的user表修改其主键为自增。
@Data
public class User {
@TableId(type = IdType.AUTO)
private Long id;
// ..
}
@Test
public void testPrimaryKey() {
User user = new User( );
user.setName("花和尚");
user.setCreateTime(new Date( ));
mapper.insert(user);
// 主键还回填了
System.out.println(user.getId() );
}
六、原生mybatis
当MP提供的方法无法满足需求时,比如多表联查或者特殊业务逻辑时,也可以自己写原生mybatis编写sqlmapepr文件完成功能
1 在继承BaseMapper接口的接口中自定义方法
2 在resources下创建/mapper/ XxxMapper.xml文件,写sql语句
3 application.yml
在mybatis-plus节点下添加内容
mybatis-plus: mapper-locations: classpath:mapper/*.xml type-aliases-package: com.taotie.entity4 测试
七、代码生成器
代码生成器(新) | MyBatis-Plus (baomidou.com)
package com.qf;
import com.baomidou.mybatisplus.generator.FastAutoGenerator;
import com.baomidou.mybatisplus.generator.config.OutputFile;
import com.baomidou.mybatisplus.generator.engine.FreemarkerTemplateEngine;
import org.junit.Test;
import org.junit.runner.RunWith;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.test.context.junit4.SpringRunner;
import java.util.Collections;
/**
* --- 天道酬勤 ---
*
* @author QiuShiju
* @desc
*/
@RunWith(SpringRunner.class)
@SpringBootTest(classes = Day67MybatiplusApplication.class)
public class TestGenerator {
@Test
public void generate() {
FastAutoGenerator.create("jdbc:mysql://localhost:3306/qf_apartment", "root", "123456")
.globalConfig(builder -> {
builder.author("Taotie") // 设置作者
//.enableSwagger() // 开启 swagger 模式
.fileOverride() // 覆盖已生成文件
.outputDir("src/main/java"); // 指定输出目录
})
.packageConfig(builder -> {
builder.parent("com.qf") // 设置父包名
//.moduleName("system") // 设置父包模块名
.pathInfo(Collections.singletonMap(OutputFile.xml, "src/main/resources/mapper")); // 设置mapperXml生成路径
})
.strategyConfig(builder -> {
builder.addInclude("rent") // 设置需要生成的表名
.addTablePrefix("t_", "c_"); // 设置过滤表前缀
})
.templateEngine(new FreemarkerTemplateEngine()) // 使用Freemarker引擎模板,默认的是Velocity引擎模板
.execute();
}
}
单元测试运行,然后在磁盘中找到即可,也可以直接指定路径为当前项目的src下也可以
八、代码生成器插件
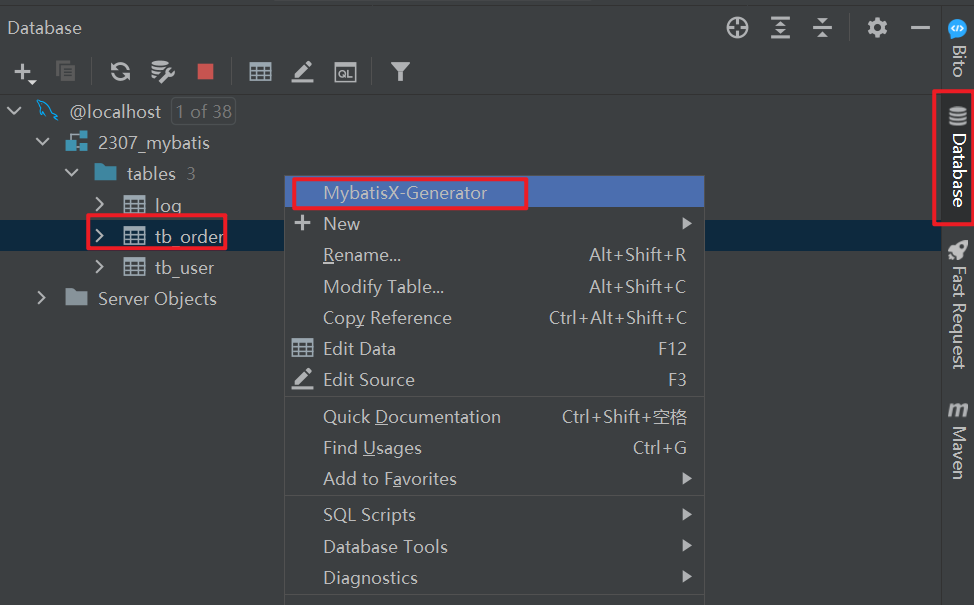
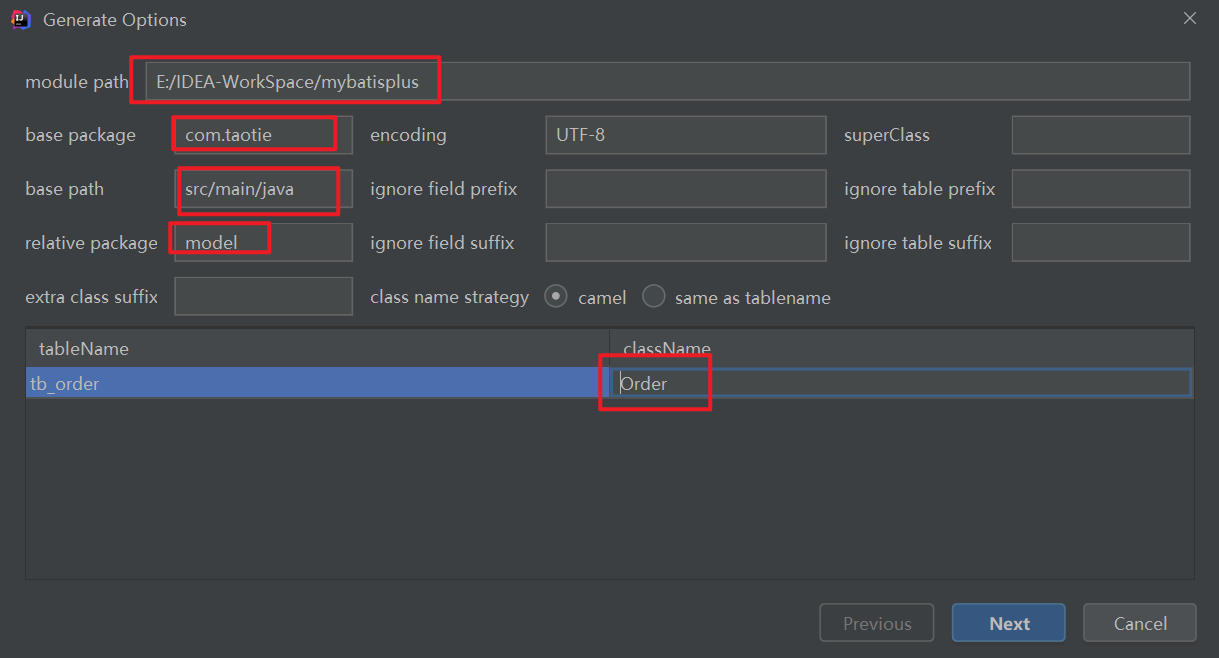
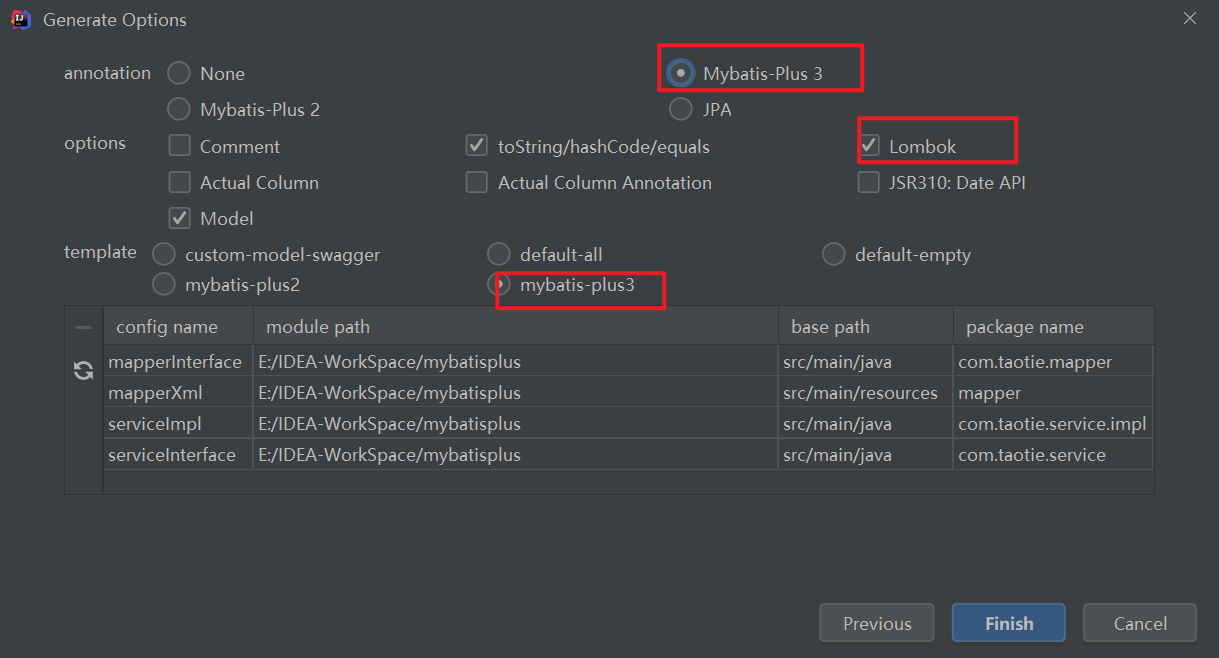
8.1 MybatisX
MybatisPlus官方推荐,家族成员MybatisX
MybatisX快速开发插件 | MyBatis-Plus (baomidou.com)
8.2 EasyCode
IDEA必备开发神器之EasyCode_Nakano_May的博客-CSDN博客
EasyCode自动生成代码(超详细) - 简书 (jianshu.com)
九、附录:注解解释
注解 | MyBatis-Plus (baomidou.com)
@TableName
注解在类上,指定类和数据库表的映射关系。实体类的类名(转成小写后)和数据库表名相同时,可以不指定该注解。
@TableId
注解在实体类的某一字段上,表示这个字段对应数据库表的主键。当主键名为id时(表中列名为id,实体类中字段名为id),无需使用该注解显式指定主键,mp会自动关联。若类的字段名和表的列名不一致,可用value属性指定表的列名。另,这个注解有个重要的属性type,用于指定主键策略。
@TableField
注解在某一字段上,指定Java实体类的字段和数据库表的列的映射关系。这个注解有如下几个应用场景。
- 排除非表字段
若Java实体类中某个字段,不对应表中的任何列,它只是用于保存一些额外的,或组装后的数据,则可以设置exist属性为false,这样在对实体对象进行插入时,会忽略这个字段。
- 字段验证策略
通过insertStrategy,updateStrategy,whereStrategy属性进行配置,可以控制在实体对象进行插入,更新,或作为WHERE条件时,对象中的字段要如何组装到SQL语句中。
- 字段填充策略
通过fill属性指定,字段为空时会进行自动填充
@Version
乐观锁注解
@EnumValue
注解在枚举字段上
@TableLogic
逻辑删除
@KeySequence
序列主键策略(oracle)
@InterceptorIgnore
) - 简书 (jianshu.com)](https://www.jianshu.com/p/63837909ca2b)
[外链图片转存中…(img-FGQ5HJn7-1688891314241)]
九、附录:注解解释
注解 | MyBatis-Plus (baomidou.com)
@TableName
注解在类上,指定类和数据库表的映射关系。实体类的类名(转成小写后)和数据库表名相同时,可以不指定该注解。
@TableId
注解在实体类的某一字段上,表示这个字段对应数据库表的主键。当主键名为id时(表中列名为id,实体类中字段名为id),无需使用该注解显式指定主键,mp会自动关联。若类的字段名和表的列名不一致,可用value属性指定表的列名。另,这个注解有个重要的属性type,用于指定主键策略。
@TableField
注解在某一字段上,指定Java实体类的字段和数据库表的列的映射关系。这个注解有如下几个应用场景。
- 排除非表字段
若Java实体类中某个字段,不对应表中的任何列,它只是用于保存一些额外的,或组装后的数据,则可以设置exist属性为false,这样在对实体对象进行插入时,会忽略这个字段。
- 字段验证策略
通过insertStrategy,updateStrategy,whereStrategy属性进行配置,可以控制在实体对象进行插入,更新,或作为WHERE条件时,对象中的字段要如何组装到SQL语句中。
- 字段填充策略
通过fill属性指定,字段为空时会进行自动填充
@Version
乐观锁注解
@EnumValue
注解在枚举字段上
@TableLogic
逻辑删除
@KeySequence
序列主键策略(oracle)
@InterceptorIgnore
插件过滤规则