文章目录
- 概要
- 一、持久性
- 1.1、journal log刷盘机制
- 1.2、数据刷盘机制
- 1.3、复制集下的写安全机制
- 二、隔离性
- 总结
概要
MongoDB并不像MySQL一样天然支持多文档事务,其演变过程如下:
- MongoDB4.0之前只支持单文档事务,在单个文档上支持ACID原子性,并且不对外暴漏API,用户无法控制事务,完全是MongoDB自行控制;
- MongoDB4.0开始支持多文档事务以及复制集和分片集群下的事务,统称为分布式事务,并提供API允许用户像MySQL事务那样控制事务的开始与结束。
但是MongoDB4.0的事务仍有限制:
-
事务的默认最大运行时间是 60s。
1)通过在 mongod 实例级别上修改transactionLifetimeLimitSeconds 的限制来增加。对于分片集群,必须在所有分片副本集成员上设置该参数。超过此时间后,事务将被视为已过期,并由定期运行的清理进程中止。清理进程每 60 秒或每 transactionLifetimeLimitSeconds/2 运行一次,以较小的值为准。
2)要显式设置事务的时间限制,建议在提交事务时指定 maxTimeMS 参数。如果 maxTimeMS 没有设置,那么将使用 transactionLifetimeLimitSeconds;如果设置了 maxTimeMS,但这个值超过了 transactionLifetimeLimitSeconds,那么还是会使用 transactionLifetimeLimitSeconds。
3)事务等待获取其操作所需锁的默认最大时间是 5 毫秒。可以通过修改由maxTransactionLockRequestTimeoutMillis 参数控制的限制来增加。如果事务在此期间无法获得锁,则该事务会被中止。maxTransactionLockRequestTimeoutMillis 可以设置为 0、-1 或大于 0 的数字。将其设置为 0 意味着,如果事务无法立即获得所需的所有锁,则该事务会被中止。设置为 -1 将使用由 maxTimeMS 参数所指定的特定于操作的超时时间。任何大于 0 的数字都将等待时间配置为该时间(以秒为单位)以作为事务尝试获取所需锁的指定时间段。 -
MongoDB 将当前事务中的所有写操作日志放入单文档中,而oplog只是一个特殊的collection,其单个文档也象正常集合一样受16MB的大小限制。这个限制在MongoDB4.2做了很大的优化,即调整成为当前事务中的每一个写操作日志都创建一个单文档。
综上两点限制,不管如何还是要避免长事务与大事务。
MongoDB的oplog相当于MySQL的binlog,用于主备节点数据复制
MongoDB的journal log相当于MySQL的redo log,用于实现事务持久性,尽量保证数据不丢失以及崩溃恢复
事务的四大特性这里就不多说了,这里主要聊一下MongoDB的事务持久性与隔离性。
PS:针对MongoDB的WiredTiger存储引擎
一、持久性
持久性是指一个事务提交后,其所做的写操作会被永久保存到数据库中,即使此时数据库or操作系统崩溃,修改的数据也不会丢失。
下面我们来看看MongoDB事务持久性是否是这样的,先看一下下图:
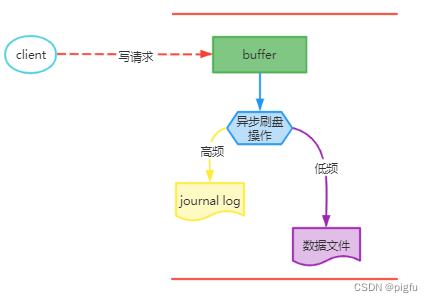
我们已经知道journal log记录的是最新的写操作内容,即redo,所以只要写的内容到了journal log,MongoDB就可以在崩溃重启后恢复。
1.1、journal log刷盘机制
journal log主要受两个配置参数控制。
storage:
journal:
enabled: <boolean> #是否开启journal log
commitIntervalMs: <num> #journal log刷盘的间隔,默认100ms,范围是1-500ms,值越小,丢失数据越少,性能越低;
除了配置文件,也可以通过如下命令调整journalCommitInterval的值:
db.adminCommand({"setParameter":1,"journalCommitInterval":10}); #设置为10ms
可知最多有journalCommitIntervalms的数据丢失。
另外在db.collection.insert({x:1}, {writeConcern: {j: true}})写命令中可以通过设置 j 的值为true来确保该语句的journal log刷盘。当然这并不意味着每一个写操作就等于一个IO。MongoDB并不会对每一个操作都立即刷盘,而是会等最多30ms,把30ms内的写操作集中到一起,采用顺序追加的方式写入到盘里。在这30ms内客户端线程会处于等待状态。这样对于单个操作的总体响应时间将有所延长,但对于高并发的场景,综合下来平均吞吐能力和响应时间不会有太大的影响。特别是你能给journal部署一个对顺序写有优化的IO带宽足够的专门的存储系统的话,这个对性能的影响可以降到最低。
还有就是缓冲区buffer中的journal log大小达到100MB(因为journal log文件的大小限制是100MB)也会触发刷盘。
总共三种,可以看到在写操作语句中指定j: true可确保journal log刷盘,保证数据不丢失。
1.2、数据刷盘机制
MongoDB的数据刷盘也有和MySQL一样的checkpoint机制,触发条件如下:
- 按一定时间周期(由storage.syncPeriodSecs控制):默认60s,执行一次checkpoint;
- 按journal log文件大小:当journal log文件大小达到2GB(如果已开启),执行一次checkpoint;
从数据刷盘机制可知,MongoDB的持久性只要靠journal log保证。
1.3、复制集下的写安全机制
db.collection.insert({x:1}, {writeConcern: {w: 1}}) #默认w值为1
- {w:0} 即Unacknowledged
Unacknowledged指的是对每一个写入操作,MongoDB并不会返回一个是否成功的状态值。这个级别是写入性能最好但也是最不安全的级别。比如说,你试图插入一个违反了唯一性的文档(重复的身份证号),那么MongoDB会拒绝写入并报错。但是由于驱动端并没有在乎你的报错,应用程序还满心欢喜以为一切都没问题,下回再来查询那条数据的时候就会出现数据缺失的情况。 - {w:1} 即Acknowledged
Acknowledged 的意思就是对每一个写入MongoDB都会确认操作的完成状态,不管是成功还是失败。当然这个确认只是基于主节点的内存写入。但是这个级别,已经可以侦测到重复主键, 网络错误,系统故障或者是无效数据等错误。 - {w:“majority”} 写到多数节点
MongoDB 的默认部署是至少3个节点的复制集(Replicaset),使用复制集的好处很多,最关键的就是提高系统的高可用性。但是也带来了一个问题,主备不一致,该参数就可以很好的解决该问题。
假设复制集中有A、B、C三个节点,A为主节点,此时w=1,那么:
1)在A接收一个写命令x并返回成功时,A与B,C失联了;
2)下一刻A发现自己无法和从节点B,C 联络上,主动降级为从节点,停止接受写操作;
3)B、C选举出B为主节点,接收客户端请求,稍后网络恢复A节点重新加入复制集。这个时候A的oplog 和B的oplog已经有不一致了。A会主动把B上面不存在的写操作回滚掉(rollback),并写入一个回滚文件。
这个时候应用如果再去查询写命令x的内容,MongoDB 将会说文档不存在,w=majority就避免了该问题。
所以说,可以通过w和j的值合理安排自己所需要的数据安全级别和性能要求。
二、隔离性
隔离性其实很好理解,即一个事务所做的写操作在它提交之前,对于其他事务是不可见的。那A事务修改了id=5的数据后B事务如何还能读到未修改数据呢,当然是记录下历史数据了,但是记录历史数据这个实现有两大流派,James Gray老爷子 的undo log流派和Michael Stonebraker老爷子的多版本派,二者在增删改上各有千秋。
所以说,MongoDB是没有undo log的,事务回滚是靠多版本,不像MySQL,SQLServer等会有undo log 段。
总结
待续…