导出Excel的技术分享
Excel前置知识
首先大家就是在大学的计算机导论等课程肯定有了解过office全家桶中的工具之一Excel。在印象当中就是Excel是普遍使用的就是有03和07的两个不同的版本。请问一下大家就是能说一说就是这两个版本有什么区别吗?
显而易见就是从了直观上,能看到就是07的版本在文件的后缀名上多了一个x。但是除了这个之外还有什么别的不同吗?

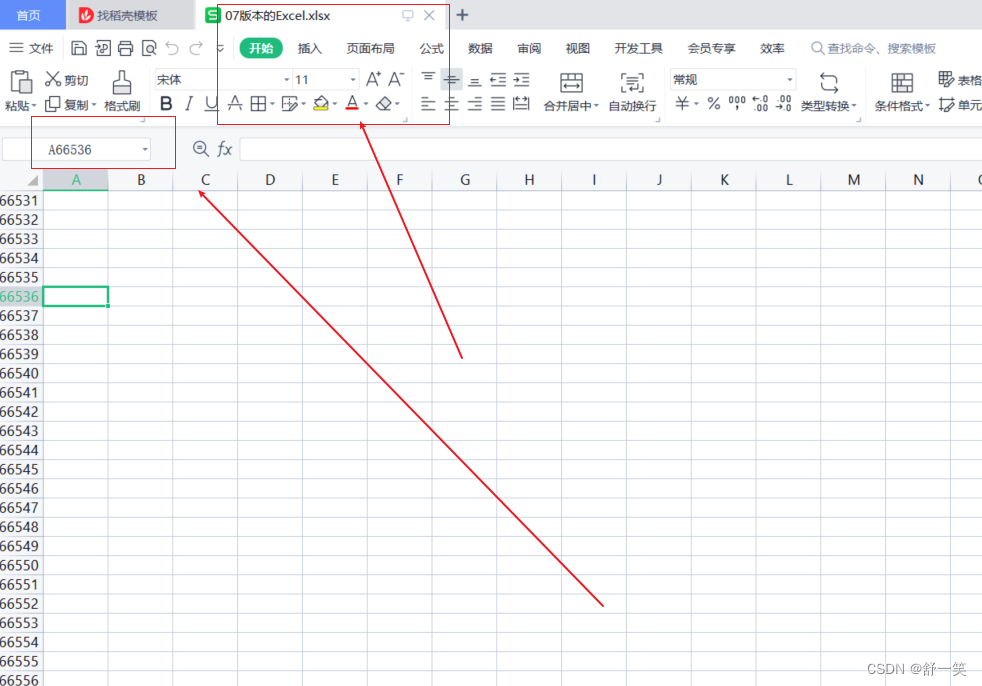
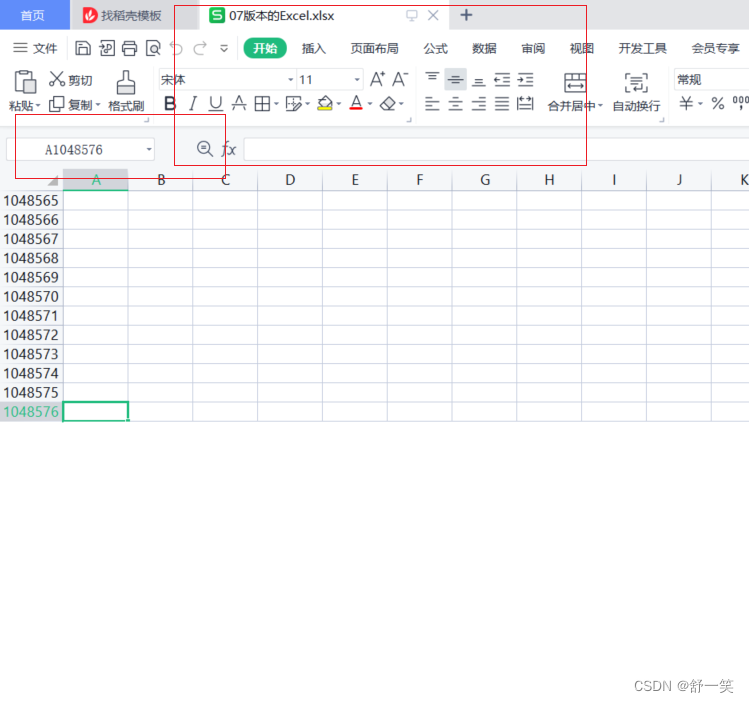
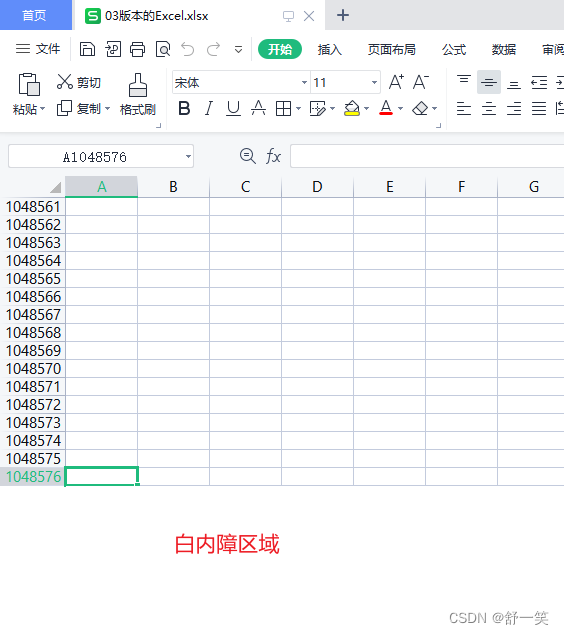
可能大家也一下就想到了那就是这两者的导出的行数是存在限制的。03版本的Excel是在65536行之后存在大量的白内障。而在07版本中则明显在数据容量上进行了巨大的提升。但是也是存在上限的。白内障出现的位置是在1048576行之后。百万行的数据量相比之前的03版本已经能极大的提高我们的日常工作数据所需。

Excel的基本组成介绍
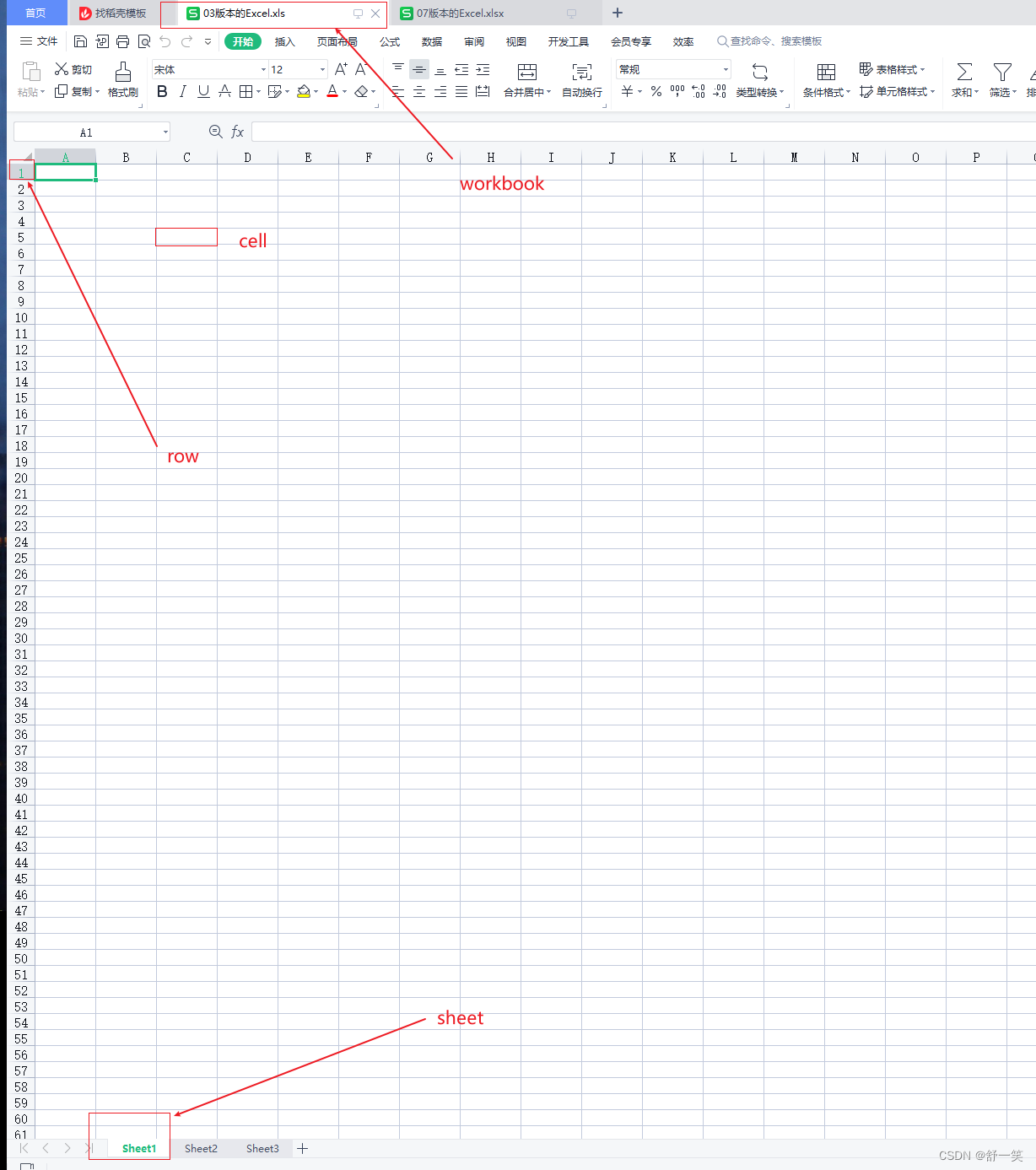
在导出一个Excel基本的组成部分在代码中体现的就是这四个骨架。
目前的主流导出Excel技术介绍
在阿里巴巴开源的导出Excel工具包中介绍了三个工具。EasyExcel、Apache poi、jxl。其中目前关于这三者的技术中的最后的JXL技术是是Java中的一个原生类库。但是它只能支持Excel 95-2000。比03Excel还要古老而且这个类库已经停止更新和维护了。EasyExcel、Apache poi这两个项目一直在更新,今天就和大家分享一下这两个工具在使用上的一些实现。
EasyExcel是在POI基础之上的一些封装,所以在介绍他之前我们先来介绍一下Apache poi。

Apache poi工具的介绍
Apache POI是用Java语言编写的工具,这一点上来不想其他的工具使用别的语言来实现(例如redis使用C/C++编写)说对Java的开发者还是比较友好的能直接看懂。Apache POI 是基于 Office Open XML 标准(OOXML)和 Microsoft 的 OLE 2 复合⽂档格式(OLE2)处理各种⽂件格式的开源项⽬。 简⽽⾔之,可以使⽤ Java 读写MS Excel ⽂件,可以使⽤ Java 读写 MS Word 和 MS PowerPoint ⽂件。
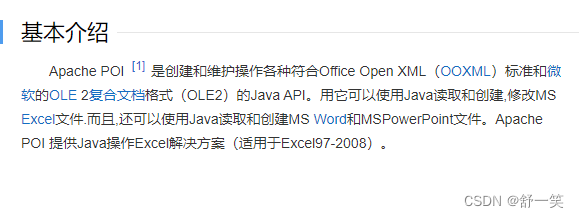
功能模块的介绍:
- HSSF:提供读写 Microsoft Excel XLS 格式 (Microsoft Excel 97 (-2003)) 档案的功能。
- XSSF:提供读写 Microsoft Excel OOXML XLSX 格式 (Microsoft Excel XML (2007+))档案的功能。
- SXSSF:提供低内存占⽤量读写 Microsoft Excel OOXML XLSX 格式档案的功能。针对大数量的写入量身打造。
- HWPF:提供读写 Microsoft Word DOC97 格式 (Microsoft Word 97 (-2003)) 档案的功能。
- XWPF:提供读写 Microsoft Word DOC2003 格式 (WordprocessingML (2007+)) 档案的功能。
- HSLF/XSLF:提供读写 Microsoft PowerPoint 格式档案的功能。
- HDGF/XDGF:提供读 Microsoft Visio 格式档案的功能。
- HPBF:提供读 Microsoft Publisher 格式档案的功能。
- HSMF:提供读 Microsoft Outlook 格式档案的功能。
上面的九大功能模块有的并没有直接显示,例如SXSSF在XSSF的内部。
使用POI完成对一个基本的Excel的数据写入
通过前面对Excel的格式骨架的介绍,大致可以将书写Eexcel的编码实现分为六大步骤。
- 创建工作簿:Workbook。
- 创建工作表:sheet。
- 创建行:Row。
- 创建列上的单元格:Cell。
- 完成对数据的写入。
- 使用字节流完成文件的最终生成
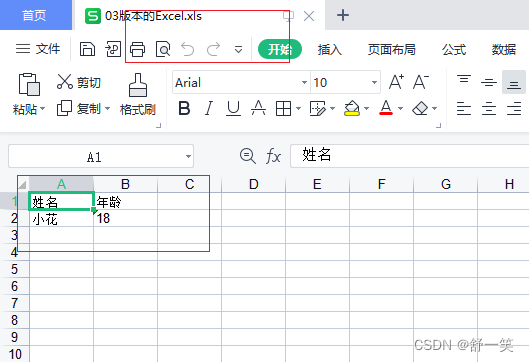
生成03版本Excel的效果演示
由下面的65536行一下就成为了白内障区域和文件名是xls后缀证明目前生成时03版本的Excel

生成03版本Excel代码示例
public static void GenerateExcel03() throws Exception {
// 创建工作簿
Workbook workbook = new HSSFWorkbook();
// 创建工作表
Sheet sheet = workbook.createSheet("03版本");
// 创建行 第0行 row0
Row row0 = sheet.createRow(0);
// 创建行上的单元格 第一行第一个
Cell cell01 = row0.createCell(0);
// 创建行上单元格 第一行第二个
Cell cell02 = row0.createCell(1);
// 创建行 第1行row0
Row row1 = sheet.createRow(1);
// 创建第二行第一个
Cell cell11 = row1.createCell(0);
// 创建第二行第二个
Cell cell12 = row1.createCell(1);
// 第二行第一个赋值
cell11.setCellValue("小花");
cell12.setCellValue("18");
// 数据写入
cell01.setCellValue("姓名");
cell02.setCellValue("年龄");
// 利用流生成Excel表格
FileOutputStream fileOutputStream = new FileOutputStream("./03版本的Excel.xls");
workbook.write(fileOutputStream);
// 关闭流
fileOutputStream.close();
System.out.println("03版本Excel生成完成");
}
生成07版本Excel的效果演示
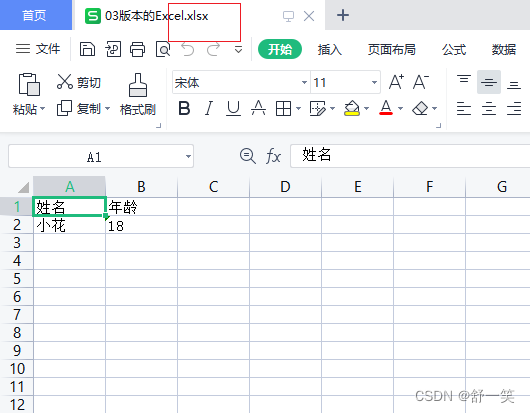
生成07版本Excel的代码示例
public static void GenerateExcel07() throws Exception {
// 创建工作簿 XSSFWorkbook这里是与03版本的不同点
Workbook workbook = new XSSFWorkbook();
// 创建工作表
Sheet sheet = workbook.createSheet("07版本");
// 创建行 第0行row0
Row row0 = sheet.createRow(0);
// 创建行上的单元格 第一行第一个
Cell cell01 = row0.createCell(0);
// 创建行上单元格 第一行第二个
Cell cell02 = row0.createCell(1);
// 创建行 第1行row0
Row row1 = sheet.createRow(1);
// 创建第二行第一个
Cell cell11 = row1.createCell(0);
// 创建第二行第二个
Cell cell12 = row1.createCell(1);
// 第二行第一个赋值
cell11.setCellValue("小花");
cell12.setCellValue("18");
// 数据写入
cell01.setCellValue("姓名");
cell02.setCellValue("年龄");
// 利用流生成Excel表格
FileOutputStream fileOutputStream = new FileOutputStream("./03版本的Excel.xlsx");
workbook.write(fileOutputStream);
// 关闭流
fileOutputStream.close();
System.out.println("07版本Excel生成完成");
}
原生POI生成Excel的速度测试

在EasyExcel官网中说明了POI存在的劣势与不足。那接下来我们来验证一下原生POI导出Excel的速度和内存溢出OOM问题。
生成03版本的Excel时间测试
按照03版本单个sheet数据容量上限,生成下面这部分数据花费14秒时间
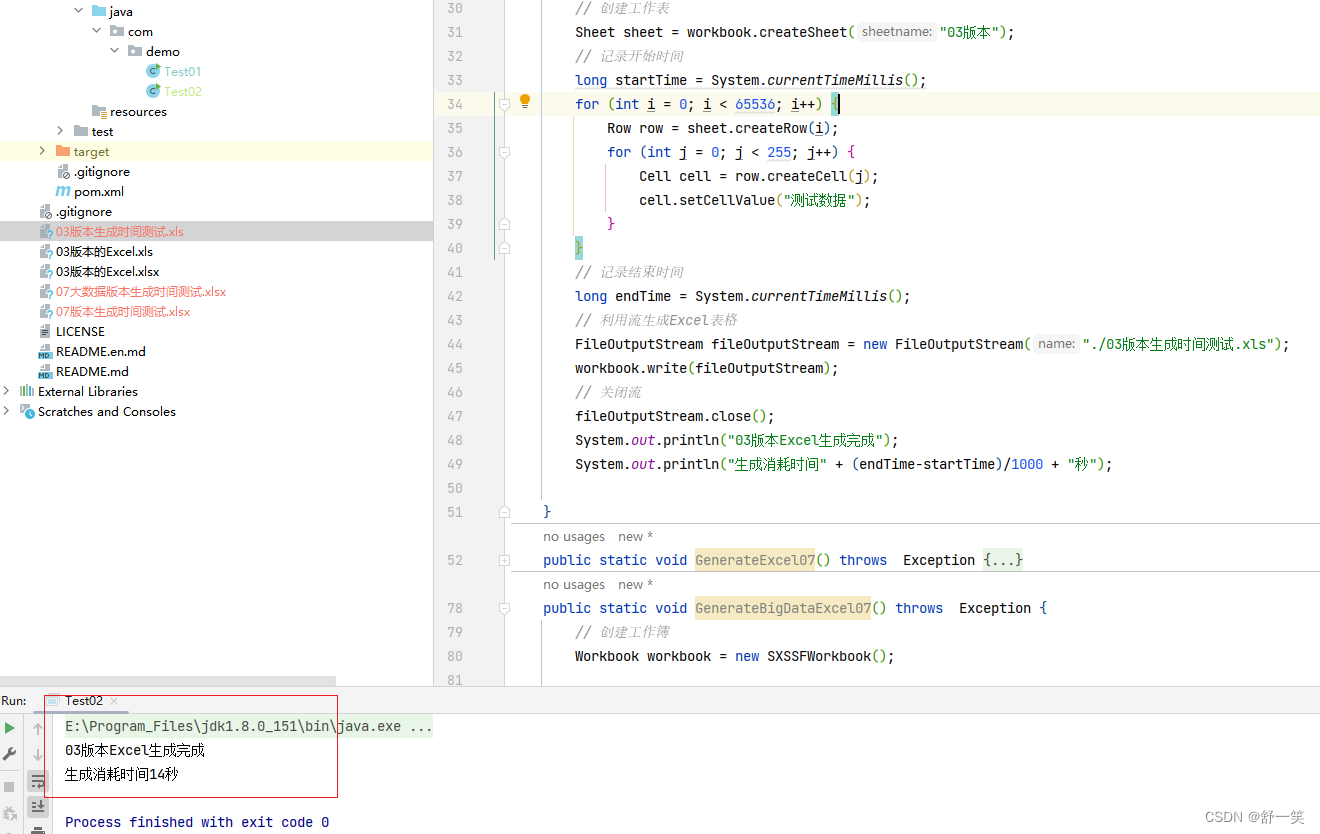
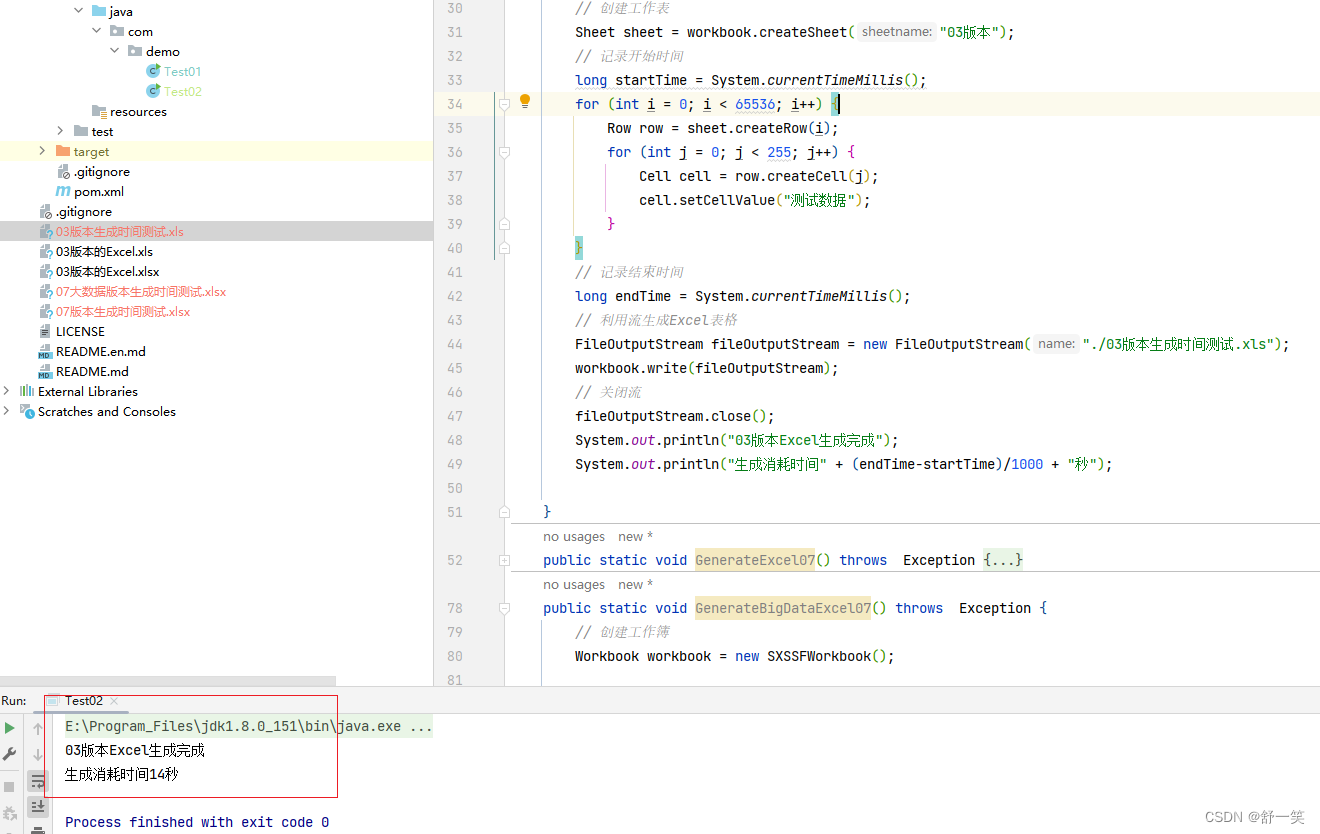
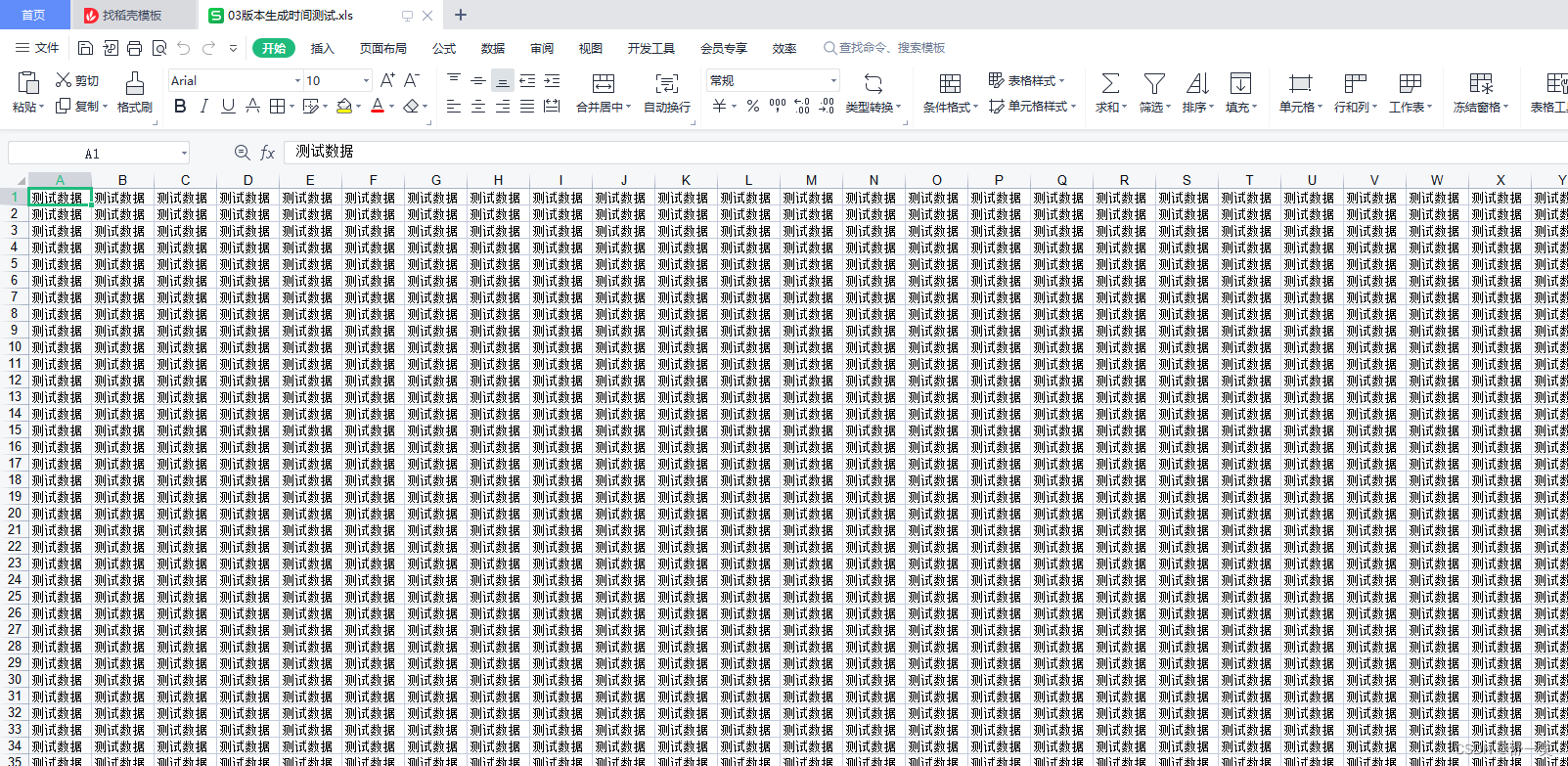
代码示例
public static void GenerateExcel03() throws Exception {
// 创建工作簿
Workbook workbook = new HSSFWorkbook();
// 创建工作表
Sheet sheet = workbook.createSheet("03版本");
// 记录开始时间
long startTime = System.currentTimeMillis();
for (int i = 0; i < 65535; i++) {
Row row = sheet.createRow(i);
for (int j = 0; j < 255; j++) {
Cell cell = row.createCell(j);
cell.setCellValue("测试数据");
}
}
// 记录结束时间
long endTime = System.currentTimeMillis();
// 利用流生成Excel表格
FileOutputStream fileOutputStream = new FileOutputStream("./03版本生成时间测试.xls");
workbook.write(fileOutputStream);
// 关闭流
fileOutputStream.close();
System.out.println("03版本Excel生成完成");
System.out.println("生成消耗时间" + (endTime-startTime)/1000 + "秒");
}
生成07版本的Excel时间测试
按照03版本的生成数据页体量数据写入方式生成07版本的Excel文件。
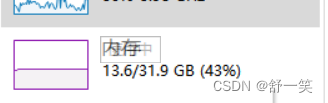
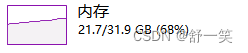
生成07版本的Excel相较与03版本,相同数据体量的情况下。时间明显长于03版本的生成,因为在使用XSSFWorkbook,07版本的Excel会在sheet页中存在百万行单元格,但是文件的生成是通过解析数据到磁盘中生成临时文件(过程是一个DOM模型),最后将临时文件转化为Excel。该类全量读取数据到内存会可能导致OOM,还有就是在数据还没有读取完之前是不会有临时文件生成,不能生成Excel会导致实际上操作的时候很慢。
生成时间由于太慢了没有结果就先kill进程先进行后续的验证。
代码示例
public static void GenerateExcel07() throws Exception {
// 创建工作簿
Workbook workbook = new XSSFWorkbook();
// 创建工作表
Sheet sheet = workbook.createSheet("07版本");
// 记录开始时间
long startTime = System.currentTimeMillis();
for (int i = 0; i < 65535; i++) {
Row row = sheet.createRow(i);
for (int j = 0; j < 255; j++) {
Cell cell = row.createCell(j);
cell.setCellValue("测试数据");
}
}
// 记录结束时间
long endTime = System.currentTimeMillis();
// 利用流生成Excel表格
FileOutputStream fileOutputStream = new FileOutputStream("./07版本生成时间测试.xls");
workbook.write(fileOutputStream);
// 关闭流
fileOutputStream.close();
System.out.println("07版本Excel生成完成");
System.out.println("生成消耗时间" + (endTime-startTime)/1000 + "秒");
}
解决大数据量的写入
官方给我们提供了一个SXSSFWorkbook对象用于生成正对大数据量的生成Excel文件。
大数据量的写是如何解决的?
这一点在官方的文档中有涉及。翻译一下这段文字大致的意思就是正对原先的的HSSFWorkbook的实现方式是一次新读取全部的行数,有一万行那就读取一万行。那么就会很容易引发OOM问题。而SXSSFWorkbook是通过增加一个窗口的方式进行,窗口值要是不手动设置默认就是100,每次也支持读取100行数据到内存,当读取到下一个101行数据的时候,就将最早的也就是最旧的索引值刷新到磁盘的临时文件中。由此来控制内存的使用。完成数据写入之后将临时文件中的数据全部写入到Excel中,最后需要显示调用dispose()。方法来将临时文件删除。
Streaming version of XSSFWorkbook implementing the “BigGridDemo” strategy. This allows to write very large files without running out of memory as only a configurable portion of the rows are kept in memory at any one time. You can provide a template workbook which is used as basis for the written data. See https://poi.apache.org/spreadsheet/how-to.html#sxssf for details. Please note that there are still things that still may consume a large amount of memory based on which features you are using, e.g. merged regions, comments, … are still only stored in memory and thus may require a lot of memory if used extensively. SXSSFWorkbook defaults to using inline strings instead of a shared strings table. This is very efficient, since no document content needs to be kept in memory, but is also known to produce documents that are incompatible with some clients. With shared strings enabled all unique strings in the document has to be kept in memory. Depending on your document content this could use a lot more resources than with shared strings disabled. Carefully review your memory budget and compatibility needs before deciding whether to enable shared strings or not.
SXSSF (package: org.apache.poi.xssf.streaming) is an API-compatible streaming extension of XSSF to be used when very large spreadsheets have to be produced, and heap space is limited. SXSSF achieves its low memory footprint by limiting access to the rows that are within a sliding window, while XSSF gives access to all rows in the document. Older rows that are no longer in the window become inaccessible, as they are written to the disk.
You can specify the window size at workbook construction time via new SXSSFWorkbook(int windowSize) or you can set it per-sheet via SXSSFSheet#setRandomAccessWindowSize(int windowSize)
When a new row is created via createRow() and the total number of unflushed records would exceed the specified window size, then the row with the lowest index value is flushed and cannot be accessed via getRow() anymore.
The default window size is 100 and defined by SXSSFWorkbook.DEFAULT_WINDOW_SIZE.
A windowSize of -1 indicates unlimited access. In this case all records that have not been flushed by a call to flushRows() are available for random access.
Note that SXSSF allocates temporary files that you must always clean up explicitly, by calling the dispose method.
SXSSFWorkbook defaults to using inline strings instead of a shared strings table. This is very efficient, since no document content needs to be kept in memory, but is also known to produce documents that are incompatible with some clients. With shared strings enabled all unique strings in the document has to be kept in memory. Depending on your document content this could use a lot more resources than with shared strings disabled.
Please note that there are still things that still may consume a large amount of memory based on which features you are using, e.g. merged regions, hyperlinks, comments, … are still only stored in memory and thus may require a lot of memory if used extensively.
Carefully review your memory budget and compatibility needs before deciding whether to enable shared strings or not.
The example below writes a sheet with a window of 100 rows. When the row count reaches 101, the row with rownum=0 is flushed to disk and removed from memory, when rownum reaches 102 then the row with rownum=1 is flushed, etc.
官网文档的链接:https://poi.apache.org/apidocs/5.0/
代码示例
public static void GenerateBigDataExcel07() throws Exception {
// 创建工作簿
Workbook workbook = new SXSSFWorkbook();
// 创建工作表
Sheet sheet = workbook.createSheet("07大数据版本");
// 记录开始时间
long startTime = System.currentTimeMillis();
for (int i = 0; i < 65536; i++) {
Row row = sheet.createRow(i);
for (int j = 0; j < 255; j++) {
Cell cell = row.createCell(j);
cell.setCellValue("测试数据");
}
}
// 记录结束时间
long endTime = System.currentTimeMillis();
// 利用流生成Excel表格
FileOutputStream fileOutputStream = new FileOutputStream("./07大数据版本生成时间测试.xlsx");
workbook.write(fileOutputStream);
// 关闭流
fileOutputStream.close();
// 清除临时文件
((SXSSFWorkbook)workbook).dispose();
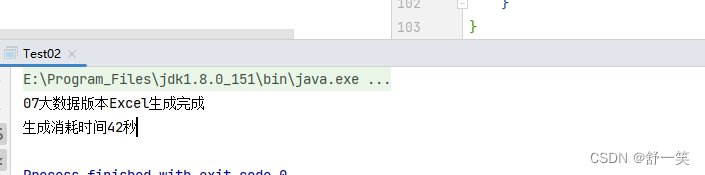
System.out.println("07大数据版本Excel生成完成");
System.out.println("生成消耗时间" + (endTime-startTime)/1000 + "秒");
}
读取Excel文件信息
实现读取的代码书写流程类似于生成EXCEL文件,大致上也分为七大步骤
- 通过文件流读取工作簿,并且这里不区分版本,一视同仁
- 通过文件流获取工作簿,这里需要更具不同的工作簿版本使用不同的类
- 获取工作表sheet
- 获取行单元格
- 获取列单元格
- 读取数据
- 关闭流
读取03版本Excel数据
效果演示
代码示例
public static void ReadExcel03() throws Exception {
// 通过文件流读取工作簿,并且这里不区分版本,一视同仁
FileInputStream fileInputStream = new FileInputStream("03版本的Excel.xls");
// 通过文件流获取工作簿,这里需要更具不同的工作簿版本使用不同的类
Workbook workbook = new HSSFWorkbook(fileInputStream);
// 获取工作表sheet
Sheet sheet = workbook.getSheet("03版本");
// Sheet sheet = workbook.getSheetAt(0);
// 获取行单元格 获取第一行
Row row = sheet.getRow(0);
// 获取列单元格 获取第一行第一个单元格
Cell cell = row.getCell(0);
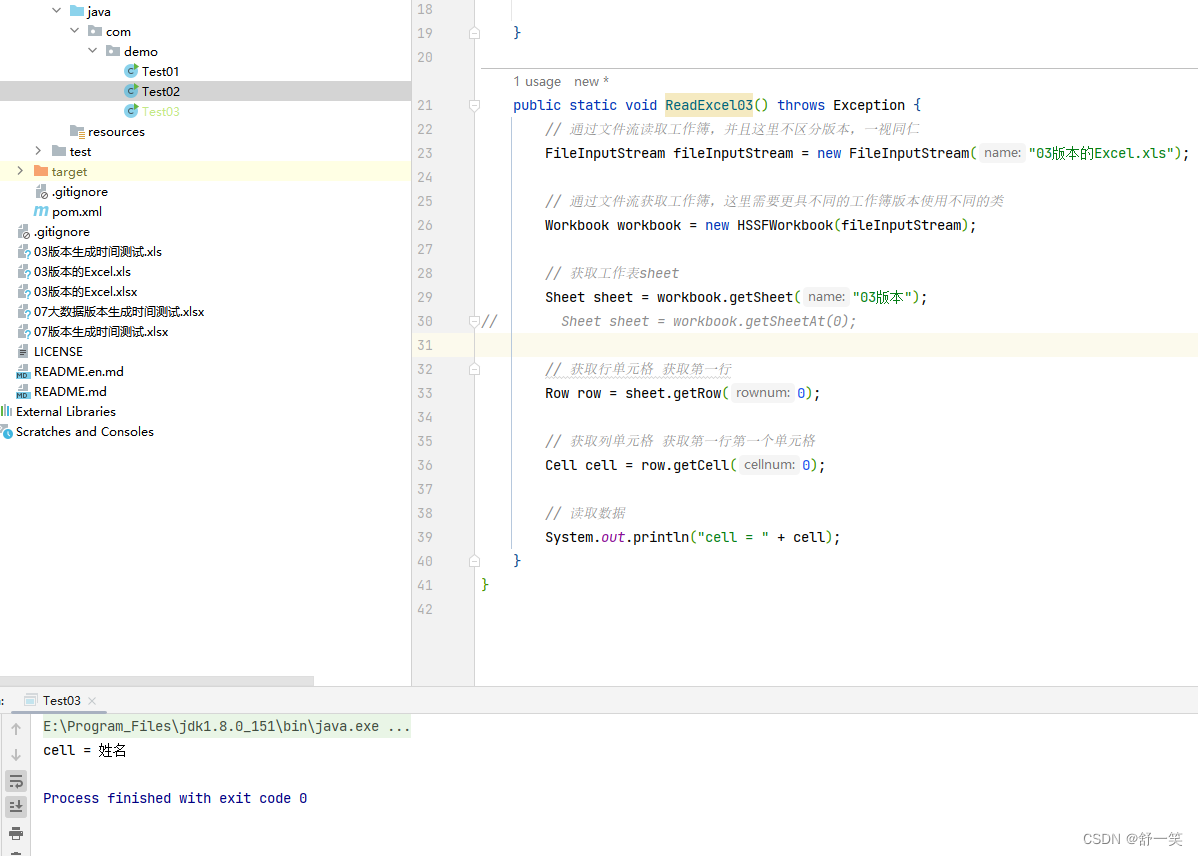
// 读取数据
System.out.println("cell = " + cell);
// 关闭流
fileInputStream.close();
}
读取Excel07版本的Excel数据
效果演示

代码展示
public static void ReadExcel07() throws Exception {
// 通过文件流读取工作簿,并且这里不区分版本,一视同仁
FileInputStream fileInputStream = new FileInputStream("07版本的Excel.xlsx");
// 通过文件流获取工作簿,这里需要更具不同的工作簿版本使用不同的类
Workbook workbook = new XSSFWorkbook(fileInputStream);
// 获取工作表sheet
Sheet sheet = workbook.getSheet("07版本");
// Sheet sheet = workbook.getSheetAt(0);
// 获取行单元格 获取第一行
Row row = sheet.getRow(0);
// 获取列单元格 获取第一行第一个单元格
Cell cell = row.getCell(0);
// 读取数据
System.out.println("cell = " + cell);
// 关闭流
fileInputStream.close();
}
批量读取Excel中的数据
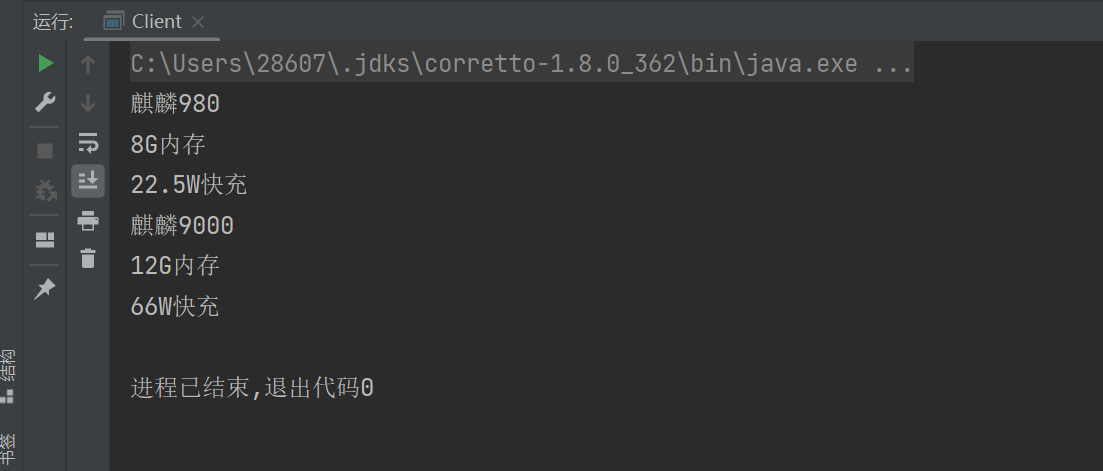
首先我们对原先生成的EXCEL进行一下字段的扩展
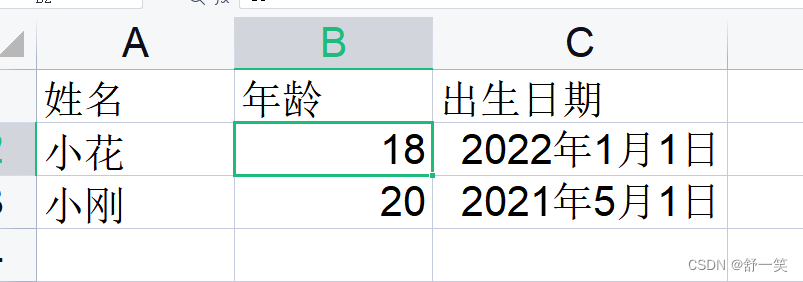
简单的批量读取03版本Excel
首先获取表头信息,接着获取表头下的具体内容信息。
效果演示
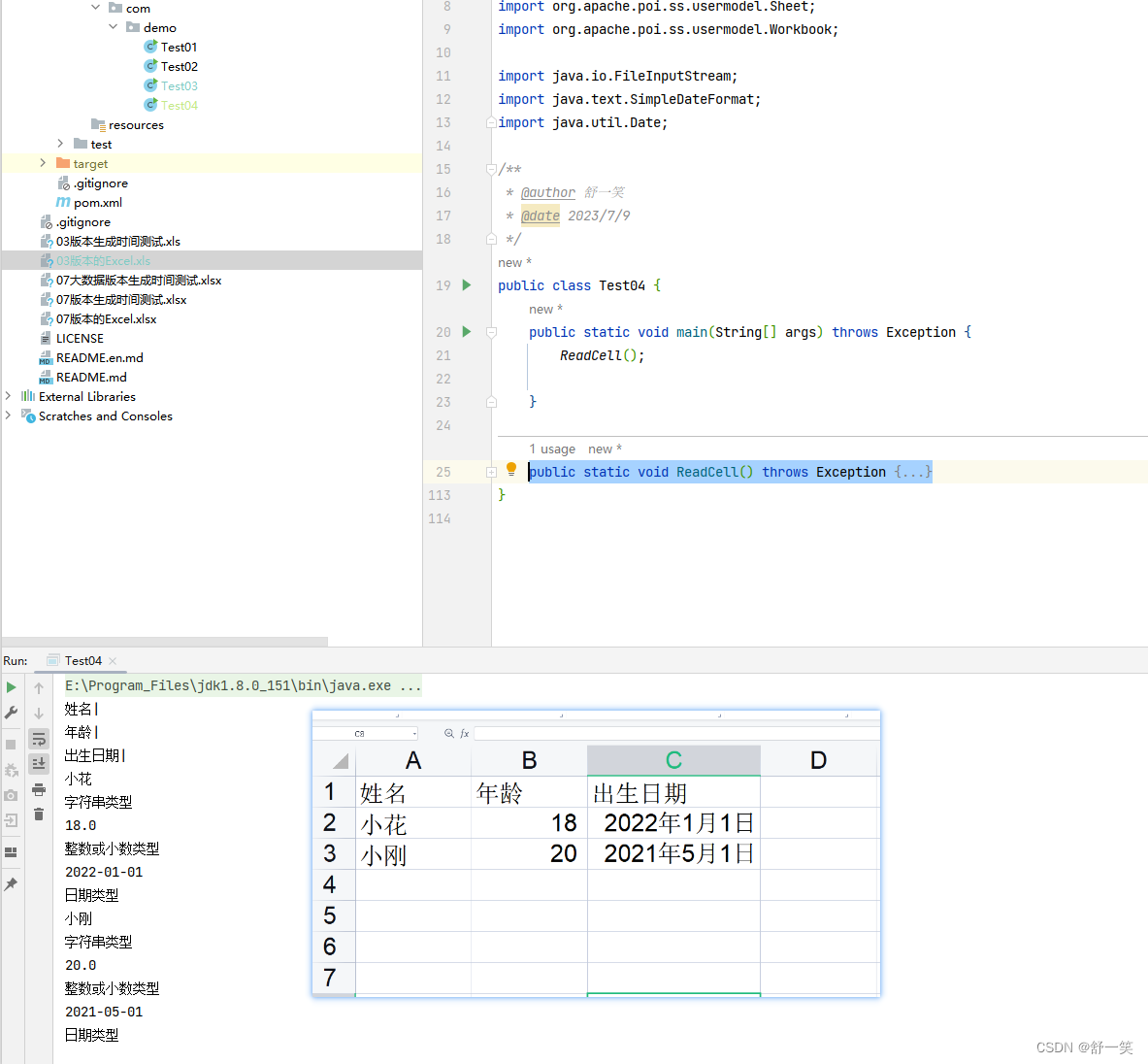
代码示例
public static void ReadCell03() throws Exception {
// 通过文件流读取工作簿,并且这里不区分版本,一视同仁
FileInputStream fileInputStream = new FileInputStream("03版本的Excel.xls");
// 通过文件流获取工作簿,这里需要更具不同的工作簿版本使用不同的类
Workbook workbook = new HSSFWorkbook(fileInputStream);
// 获取工作表sheet
Sheet sheet = workbook.getSheet("03版本");
// Sheet sheet = workbook.getSheetAt(0);
// 获取行单元格 获取第一行 获取标题行数据
Row rowTitle = sheet.getRow(0);
if (rowTitle != null) {
// 获取标题的单元格数量
int cellNum = rowTitle.getPhysicalNumberOfCells();
for (int i = 0; i < cellNum; i++) {
// 获取所有单元格
Cell cell = rowTitle.getCell(i);
if (cell != null) {
// 获取单元格数量
String value = cell.getStringCellValue();
System.out.println(value + "|");
}
}
}
// 获取内容行数据
int rowNum = sheet.getPhysicalNumberOfRows();
// 从第二行开始获取内容行数据
for (int i = 1; i < rowNum; i++) {
Row row = sheet.getRow(i);
if (row != null) {
// 获取当前行一共有多少单元格
int cellNum = row.getPhysicalNumberOfCells();
// 获取当前行中单元格的数据
for (int j = 0; j < cellNum; j++) {
Cell cell = row.getCell(j);
if (cell != null) {
// 获取单元格数据类型
CellType cellType = cell.getCellType();
// 根据不同数据类型获取数据
String cellValue = "";
switch (cellType){
// 字符串
case STRING:
cellValue = cell.getStringCellValue();
System.out.println(cellValue);
System.out.println("字符串类型");
break;
// 数值类型:包括整数、小数、日期
case NUMERIC:
// 判断是否为日期类型
if (DateUtil.isCellDateFormatted(cell)){
Date date = cell.getDateCellValue();
cellValue = new SimpleDateFormat("yyyy-MM-dd").format(date);
System.out.println(cellValue);
System.out.println("日期类型");
}else {
cellValue = cell.toString();
System.out.println(cellValue);
System.out.println("整数或小数类型");
}
break;
// 空白单元格类型
case BLANK:
System.out.println("空白单元格");
break;
case BOOLEAN:
cellValue = String.valueOf(cell.getBooleanCellValue());
System.out.println(cellValue);
System.out.println("布尔类型");
break;
case ERROR:
System.out.println("错误类型");
break;
}
}
}
}
}
// 关闭流
fileInputStream.close();
}
简单的批量读取07版本Excel
这里有一个问题就是在使用代码自动导出EXCEL之后设置导出文件的单元格熟悉,原有的单元格熟悉不会因为你修改了单元格熟悉而改变。
效果演示
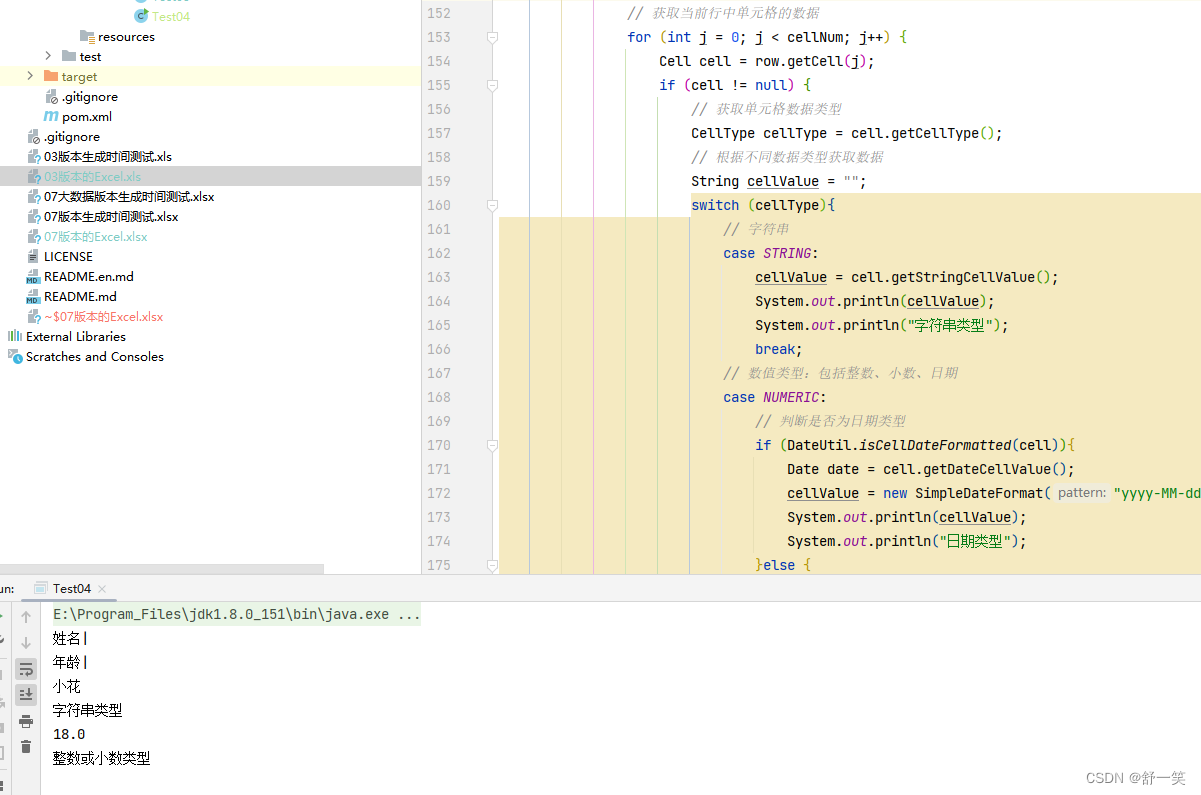
代码示例
public static void ReadCell07() throws Exception {
// 通过文件流读取工作簿,并且这里不区分版本,一视同仁
FileInputStream fileInputStream = new FileInputStream("07版本的Excel.xlsx");
// 通过文件流获取工作簿,这里需要更具不同的工作簿版本使用不同的类
Workbook workbook = new XSSFWorkbook(fileInputStream);
// 获取工作表sheet
Sheet sheet = workbook.getSheet("07版本");
// Sheet sheet = workbook.getSheetAt(0);
// 获取行单元格 获取第一行 获取标题行数据
Row rowTitle = sheet.getRow(0);
if (rowTitle != null) {
// 获取标题的单元格数量
int cellNum = rowTitle.getPhysicalNumberOfCells();
for (int i = 0; i < cellNum; i++) {
// 获取所有单元格
Cell cell = rowTitle.getCell(i);
if (cell != null) {
// 获取单元格数量
String value = cell.getStringCellValue();
System.out.println(value + "|");
}
}
}
// 获取内容行数据
int rowNum = sheet.getPhysicalNumberOfRows();
// 从第二行开始获取内容行数据
for (int i = 1; i < rowNum; i++) {
Row row = sheet.getRow(i);
if (row != null) {
// 获取当前行一共有多少单元格
int cellNum = row.getPhysicalNumberOfCells();
// 获取当前行中单元格的数据
for (int j = 0; j < cellNum; j++) {
Cell cell = row.getCell(j);
if (cell != null) {
// 获取单元格数据类型
CellType cellType = cell.getCellType();
// 根据不同数据类型获取数据
String cellValue = "";
switch (cellType){
// 字符串
case STRING:
cellValue = cell.getStringCellValue();
System.out.println(cellValue);
System.out.println("字符串类型");
break;
// 数值类型:包括整数、小数、日期
case NUMERIC:
// 判断是否为日期类型
if (DateUtil.isCellDateFormatted(cell)){
Date date = cell.getDateCellValue();
cellValue = new SimpleDateFormat("yyyy-MM-dd").format(date);
System.out.println(cellValue);
System.out.println("日期类型");
}else {
cellValue = cell.toString();
System.out.println(cellValue);
System.out.println("整数或小数类型");
}
break;
// 空白单元格类型
case BLANK:
System.out.println("空白单元格");
break;
case BOOLEAN:
cellValue = String.valueOf(cell.getBooleanCellValue());
System.out.println(cellValue);
System.out.println("布尔类型");
break;
case ERROR:
System.out.println("错误类型");
break;
}
}
}
}
}
// 关闭流
fileInputStream.close();
}







![LeetCode[面试题17.14]最小的K个数](https://img-blog.csdnimg.cn/559bce59c81f4e968c252d6b5ce0c252.png)