论文笔记--SentEval: An Evaluation Toolkit for Universal Sentence Representations
- 1. 文章简介
- 2. 文章概括
- 3 文章重点技术
- 3.1 evaluation pipeline
- 3.2 使用
- 4. 代码
- 4.1 数据下载
- 4.2 句子嵌入
- 4.3 句子嵌入评估
- 5. 文章亮点
- 6. 原文传送门
- 7. References
1. 文章简介
- 标题:SentEval: An Evaluation Toolkit for Universal Sentence Representations
- 作者:Alexis Conneau, Douwe Kiela
- 日期:2018
- 期刊:arxiv preprint
2. 文章概括
文章给出了一个可以自动评估NLP句子嵌入向量的开源工具SentEval,思想简单,操作便捷。由于很多当前的语言模型在评估下游任务的时候直接采用该工具包,所以笔者今天来学习一下原论文(也很精简)
3 文章重点技术
3.1 evaluation pipeline
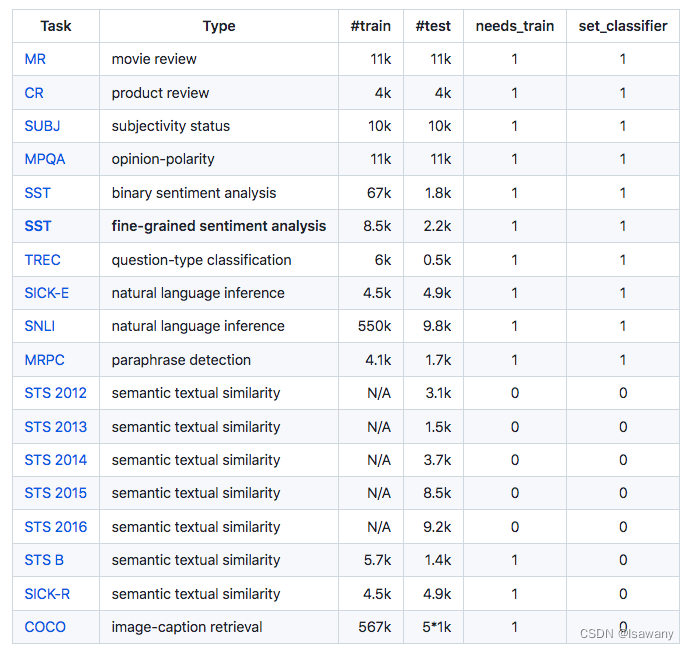
文章尝试将句子嵌入评估封装为一套简单清晰的pipeline。原文的SentEval支持一下NLP任务的评估
- 二分类/多分类:包括情感分类(MR, SST)、问答类分类(TREC))、产品评论分类(CR)、主观客观分类(SUBJ)、倾向性分类(MPQA)。文章会将句子嵌入的顶层增加一个Logistic Regression/MLP(Multiple Perceptron)分类器,然后通过10-fold交叉验证评估句子嵌入的性能。
- 句子蕴含和语义相关性分析:文章选用SICK-E数据集来评估句子蕴含类任务,和上述分类方法一致;针对语义相关性任务,文章使用SICK-R和STS数据集进行评估:数据集包含0~5之间的分值表示两个句子的相似度,文章采用[1]中的句子相关性分析方法来计算句子相关性得分,最后给出采用当前句子嵌入得到的相关性得分和真实得分之间的Pearson/Spearman相关系数作为评估标准。
- STS语义相似度:文章在SemEval数据集(包括新闻、评论、图像视频描述、标题、新闻对话)上进行相似度评估,该数据集每个句子对应一个0-5之间的相似度得分,文章会计算给定句子嵌入之间的cosine相似度,然后得到cosine相似度和真实相似度之间的Pearson/Spearman相关系数作为评估标准
- 段落检测:文章采用MRPC数据集用于评估段落检测类NLP任务,该数据集包含句子对及标签,标签反应句子是否为同义/同段落
- 标题图像检索
当前SentEval支持的下游任务可在github上查看:
3.2 使用
工具的使用非常简单,开发人员只需要自定义prepare和batcher函数,分别用于句子与处理和句子嵌入生成即可。此外开发人员可通过修改params来控制参数
4. 代码
下面为实际使用SentEval的代码/命令行
4.1 数据下载
SentEval可通过运行get_transfer_data.bash自动下载全部数据集,读者可以自行注释掉无关的数据集以提升效率/节约存储。下载成功之后数据集会自动存储到data/downstream/文件夹下。
4.2 句子嵌入
现在我们要评估句子嵌入的表现。假设我们要评估fastText向量(读者可以替换为自己训练的向量),首先通过curl -Lo crawl-300d-2M.vec.zip https://dl.fbaipublicfiles.com/fasttext/vectors-english/crawl-300d-2M.vec.zip下载fasttext/crawl-300d-2M.vec向量,要保证下载路径和bow.py中的PATH_TO_VEC一致,然后将文件解压即可。
4.3 句子嵌入评估
以bow向量(fastText)为例,SentEval给出了bow.py示例,开发人员可以类似地构造自己的句子嵌入类。首先要构造函数prepare(params, dataset),后续传入评估pipeline中的do_prepare。这里只需要包含必要的预处理即可。
然后构造函数batcher(params, batch),对传入的句子batch进行嵌入表示,返回嵌入数组,传入评估pipeline中的run()
最后只需要运行python bow.py即可,可在main方法中将不需要的tasks注释掉。注意如果没有cuda,需要在classifier.py中和cuda相关的注释掉或者改成cpu
笔者这里只试验了一小部分Vec和一小部分TREC数据,最终可以得到如下评估结果。使用还是非常简单的。

5. 文章亮点
文章给出了一种自动评估NLP下游任务/probing任务的工具,可以自动下载多种NLP任务的数据,且将预处理、句子嵌入生成和评估集成为一套pipeline,使用非常便捷,为NLP模型发展提供了便利性,实现NLP学术研究成果评估的一致性。
6. 原文传送门
SentEval: An Evaluation Toolkit for Universal Sentence Representations
7. References
[1] Improved semantic representations from tree-structured long short-term memory networks
[2]