1.groupby
1.1 函数功能
先对数据进行分组,然后在每个分组上运用聚合函数、转换函数
1.2 函数语法
DataFrame.groupby(by=None, axis=0, level=None, as_index=True, sort=True, group_keys=True, observed=False, dropna=True)
1.3 函数参数
| 参数 | 含义 |
|---|---|
| by | 分组依据 |
| axis | 沿着行还是列分隔DataFrame,默认按照行分隔;行:0或“index”;列:1或“columns” |
| level | 用于多层级索引 |
| as_index | 布尔值,默认True:是否将分组列名作为输出内容的索引,默认是 |
| sort | 布尔值,默认为True:不清楚 |
| group_keys | 布尔值,默认为True;不清楚 |
| observed | 布尔值,默认为False:针对Categoricals,不清楚 |
| dropna | 布尔值,默认值为True:聚合键中包含的空值会被删除掉,否则保留 |
1.3.1 默认情况分组统计
order = pd.read_excel('C:\\Users\\changyanhua\\Desktop\\order.xlsx')
print(order)
print(order.groupby('学历要求').count())
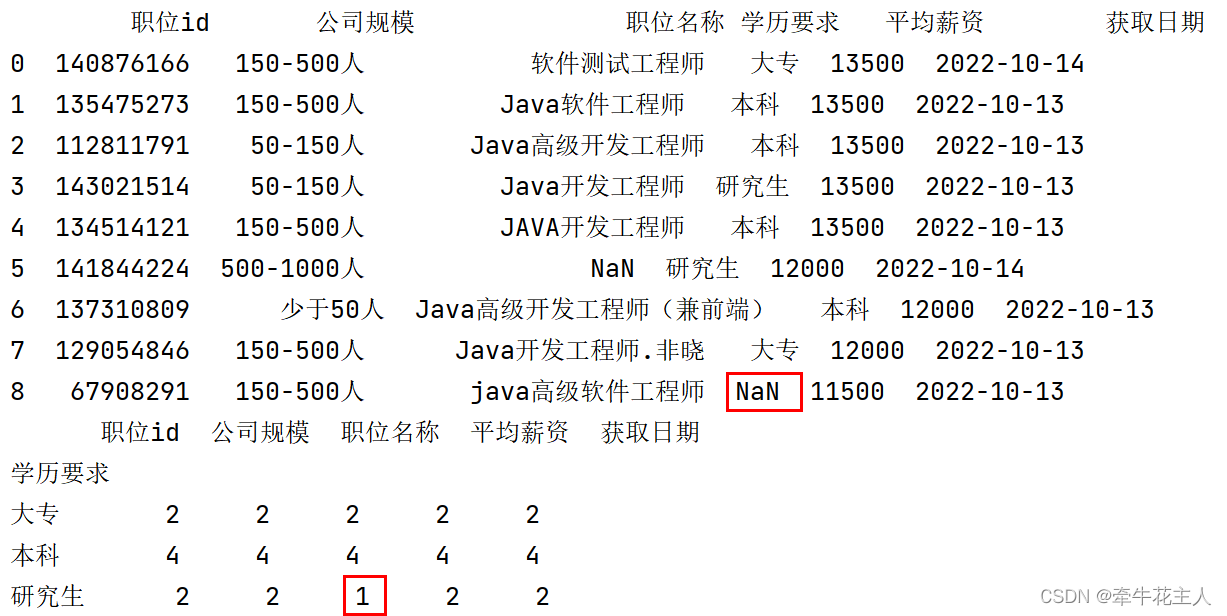
可以看到默认情况下,分组依据并不统计依据【学历要求】为缺失值的部分。
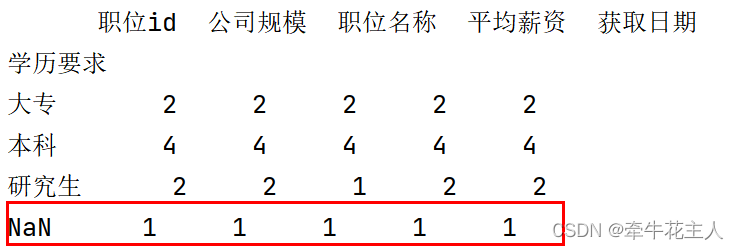
1.3.2 分组统计包含缺失值部分
print(order.groupby('学历要求',dropna=False).count())
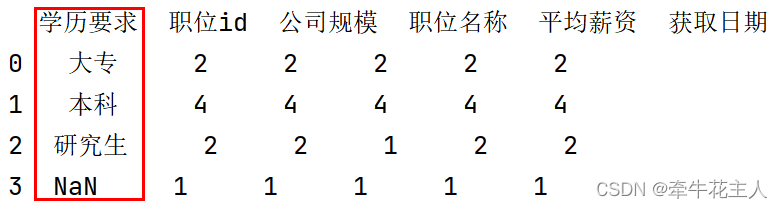
1.3.3 将分组依据作为新的略而不是索引
print(order.groupby('学历要求',dropna=False,as_index=False).count())
1.3.4 多列作为分组依据
print(order.groupby(['学历要求','公司规模'],dropna=False).count())
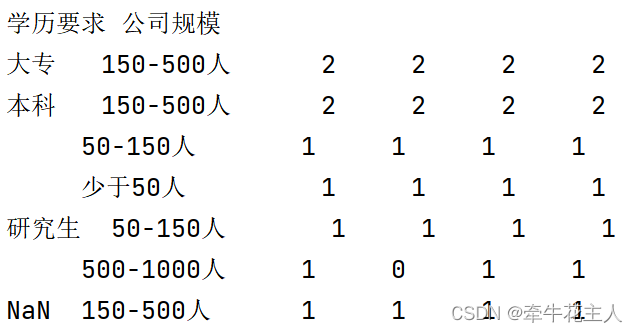
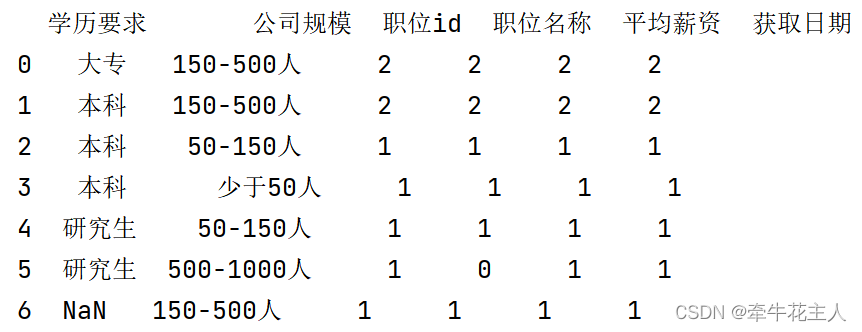
print(order.groupby(['学历要求','公司规模'],dropna=False,as_index=False).count())
1.3.5 理解辅助
单个分组依据
# 我们可以输出groupby中的内容,分别是分组依据值和对应的内容
for a, b in gb:
print(a)
print('*******')
print(b)
print('__________')
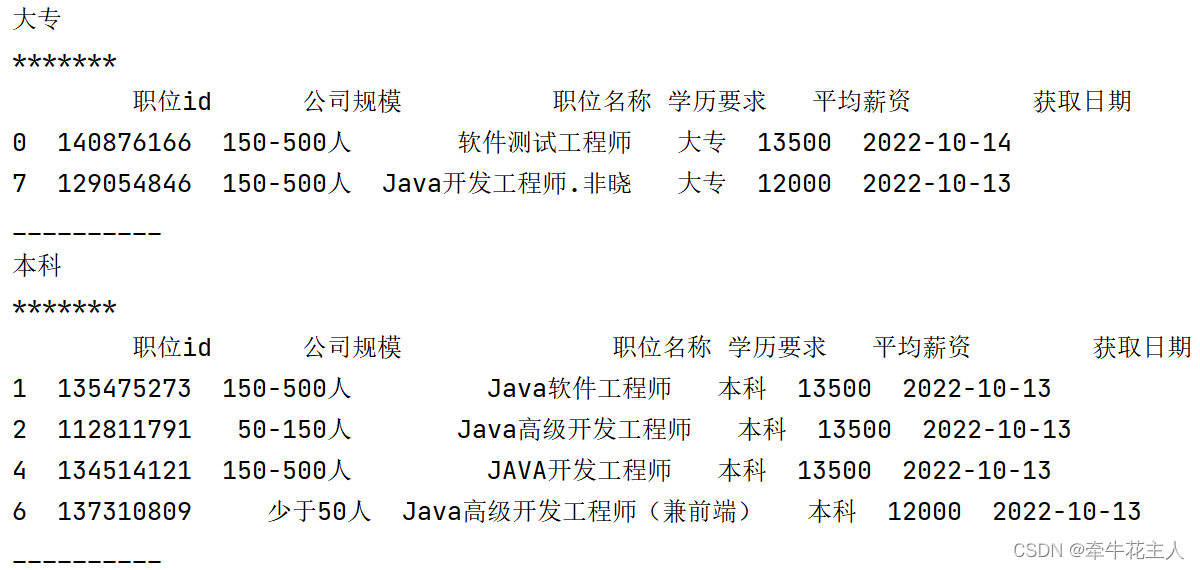

多个分组依据
可以看到此时的索引是一个元组,我们要获取某个索引对应的内容也需要传入一个元组
gb = order.groupby(['学历要求','公司规模'],dropna=False,as_index=False)
# 我们可以输出groupby中的内容,分别是分组依据值和对应的内容
for a, b in gb:
print(a)
print('*******')
print(b)
print('__________')



print(gb.get_group(('本科', '150-500人')))