下面例题基于同一个网页讲解,进入网页后右键查看页面源代码对应着看
文章目录
- 前言
- 一、BeautifulSoup库简介
- 什么是BeautifulSoup库?
- BeautifulSoup库解析器
- 网页爬虫
- 解析网页的基本方法
- 二、BeautifulSoup库的安装
- 安装测试
- 三、BeautifulSoup库的基本元素
- 获取标签
- 输出标签和名称类型
- 输出父亲标签的名称
- 输出属性
- 输出相关属性的类型
- 输出非属性字符串的内容
- 【正例(取到)】
- 【反例(取不到)】
- 获取a标签的名称、属性和非属性字符串
- 四、BeautifulSoup库的内容获取
- 下行遍历案例
前言
BeautifulSoup库算是小型爬虫的包
一、BeautifulSoup库简介
什么是BeautifulSoup库?
BeautifulSoup库==beautifulsoup4== bs4
使用方法
from bs4 import BeautifulSoup
BeautifulSoup主要的功能:从复杂的网页中解析和提取HTML或XML内容
基于海量的网站源码的分析工作
实现过程也非常简单
提高分析源码的效率
BeautifulSoup库解析器
| 解析器 | 使用方法 | 特点 |
|---|---|---|
| 标准库HTML解析器 | BeautifulSoup(demo,"html.parser") | 内置标准库,容错性能差 |
| 1xml HTML解析器 | BeautifulSoup(demo,"1xml") | 速度快,需要安装库 |
| 1xml XML解析器 | BeautifulSoup(demo,"["1xml","xml"]") | 支持XML解析器,需要安装库 |
| html5lib | BeautifulSoup(demo,"html5lib") | 容错性好,速度慢,需要安装库 |
网页爬虫
网页爬虫的主要工作是抓取网页的HTML源码等内容,对其进行分析,然后提取相应的内容。
用普通的正则表达式进行匹配,对于内容简单的网页分析,则是可以实现的。
针对工作量较重,分析内容很繁杂的网站而言,利用正则表达式的re模块实现爬虫是非常烦琐的。
此时需要更为高效的分析工具。
解析网页的基本方法
解析HTML、XML
将复杂的文档转换为一个树形结构:标签树
标签树的另一种表现形式
把标签树转换成变量,用于标签树的各种处理

提示:以下是本篇文章正文内容,下面案例可供参考
二、BeautifulSoup库的安装
找到安装的Anaconda Powershell Prompt (Anaconda)
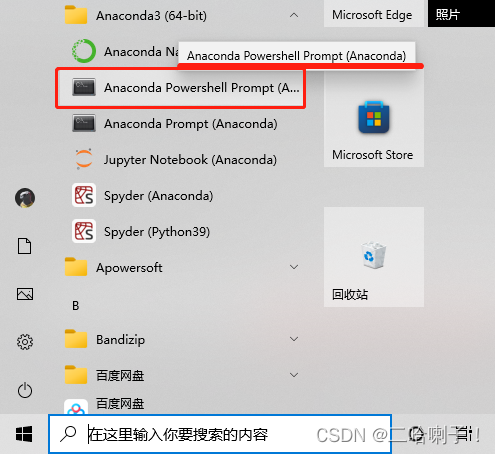
查一下现在都有哪些环境:conda info --envs
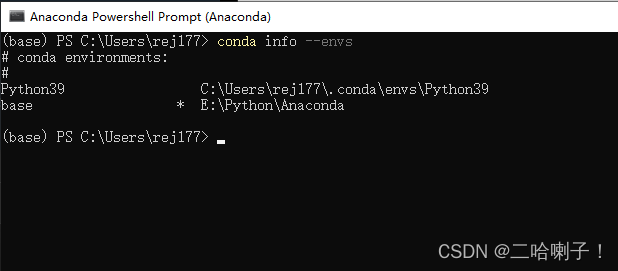
输入自己的环境(我的是Python39):activate Python39
安装beautifulsoup库 pip install beautifulsoup4
如果没安装过会有进度条
我的已经安装过一次了,如下图所示:
安装测试
测试网站:http://emotion.bxbw-jyz.cn/Home/index/showPartData.html
获取网页数据、看看是否输出页面源代码
import requests
from bs4 import BeautifulSoup
r = requests.get("http://emotion.bxbw-jyz.cn/Home/index/showPartData.html")
demo = r.text
#按照html形式做解析
soup = BeautifulSoup(demo,"html.parser")
print(soup)
#如果最后一行换成了print(soup.prettify())
#那么程序结果会加一些换行、缩进,看起来更美观一些
三、BeautifulSoup库的基本元素
| 基本元素 | 名称 | 使用方法 |
|---|---|---|
| Tag | 标签 | .tag |
| Name | 名称 | tag.name |
| Attributes | 属性 | tag.attrs |
| NavigableString | 非属性字符串 | tag.string |
| Comment | 注释,一种特殊类型 |
获取标签
【例】http://emotion.bxbw-jyz.cn/Home/index/showPartData.html
此处以<h4>标签为例

import requests
from bs4 import BeautifulSoup
r=requests.get("http://emotion.bxbw-jyz.cn/Home/index/showPartData.html")
demo = r.text
soup = BeautifulSoup(demo,"html.parser")
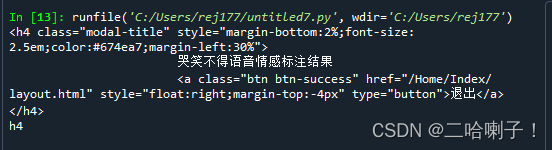
h4 = soup.h4 #获取标签h4
print(h4) #输出标签h4
print(h4.name) #输出标签的name元素
【例】http://emotion.bxbw-jyz.cn/Home/index/showPartData.html
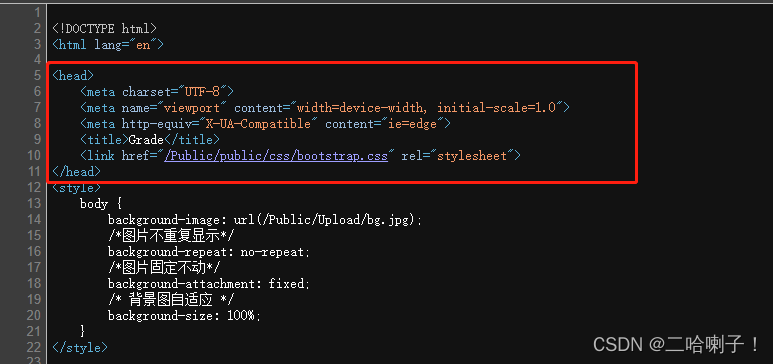
此处以<head>标签为例
import requests
from bs4 import BeautifulSoup
r=requests.get("http://emotion.bxbw-jyz.cn/Home/index/showPartData.html")
demo = r.text
soup = BeautifulSoup(demo,"html.parser")
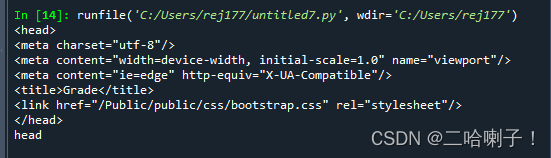
head = soup.head #获取标签head
print(head) #输出标签head
print(head.name) #输出标签的name元素
输出标签和名称类型
【例】http://emotion.bxbw-jyz.cn/Home/index/showPartData.html
import requests
from bs4 import BeautifulSoup
r = requests.get("http://emotion.bxbw-jyz.cn/Home/index/showPartData.html")
demo = r.text
soup = BeautifulSoup(demo,"html.parser")
h4 = soup.h4
print(type(h4))
print(type(h4.name))

输出父亲标签的名称
【例】http://emotion.bxbw-jyz.cn/Home/index/showPartData.html

import requests
from bs4 import BeautifulSoup
r = requests.get("http://emotion.bxbw-jyz.cn/Home/index/showPartData.html")
demo = r.text
soup = BeautifulSoup(demo,"html.parser")
h4 = soup.h4
print(h4.parent.name)

输出属性
【例】http://emotion.bxbw-jyz.cn/Home/index/showPartData.html

import requests
from bs4 import BeautifulSoup
r = requests.get("http://emotion.bxbw-jyz.cn/Home/index/showPartData.html")
demo = r.text
soup = BeautifulSoup(demo,"html.parser")
h4 = soup.h4
attrs = soup.h4.attrs
print(attrs)
print(len(attrs))
print(attrs['class'])
print(attrs['style'])

输出相关属性的类型
import requests
from bs4 import BeautifulSoup
r = requests.get("http://emotion.bxbw-jyz.cn/Home/index/showPartData.html")
demo = r.text
soup = BeautifulSoup(demo,"html.parser")
h4 = soup.h4
attrs = soup.h4.attrs
print(type(attrs))
print(type(attrs['class']))

输出非属性字符串的内容
【正例(取到)】
http://emotion.bxbw-jyz.cn/Home/index/showPartData.html

import requests
from bs4 import BeautifulSoup
r = requests.get("http://emotion.bxbw-jyz.cn/Home/index/showPartData.html")
demo = r.text
soup = BeautifulSoup(demo,"html.parser")
h4 = soup.h4
attrs = soup.h4.attrs
strings = soup.h5.string
print(strings)

【反例(取不到)】
http://emotion.bxbw-jyz.cn/Home/index/showPartData.html

import requests
from bs4 import BeautifulSoup
r = requests.get("http://emotion.bxbw-jyz.cn/Home/index/showPartData.html")
demo = r.text
soup = BeautifulSoup(demo,"html.parser")
attrs = soup.h4.attrs
strings = soup.h4.string
print(strings)

非属性字符串存在多个时,无法进行判断,系统认为是NONE
获取a标签的名称、属性和非属性字符串
网站:http://emotion.bxbw-jyz.cn/Home/index/showPartData.html
import requests
from bs4 import BeautifulSoup
r = requests.get("http://emotion.bxbw-jyz.cn/Home/index/showPartData.html")
demo = r.text
soup = BeautifulSoup(demo,"html.parser")
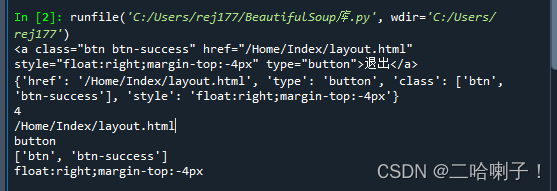
tag_a = soup.a
attrs_a = soup.a.attrs
string_a = soup.a.string
print(tag_a)
print(attrs_a)
print(len(attrs_a))
print(attrs_a['href'])
print(attrs_a['type'])
print(attrs_a['class'])
print(attrs_a['style'])
四、BeautifulSoup库的内容获取
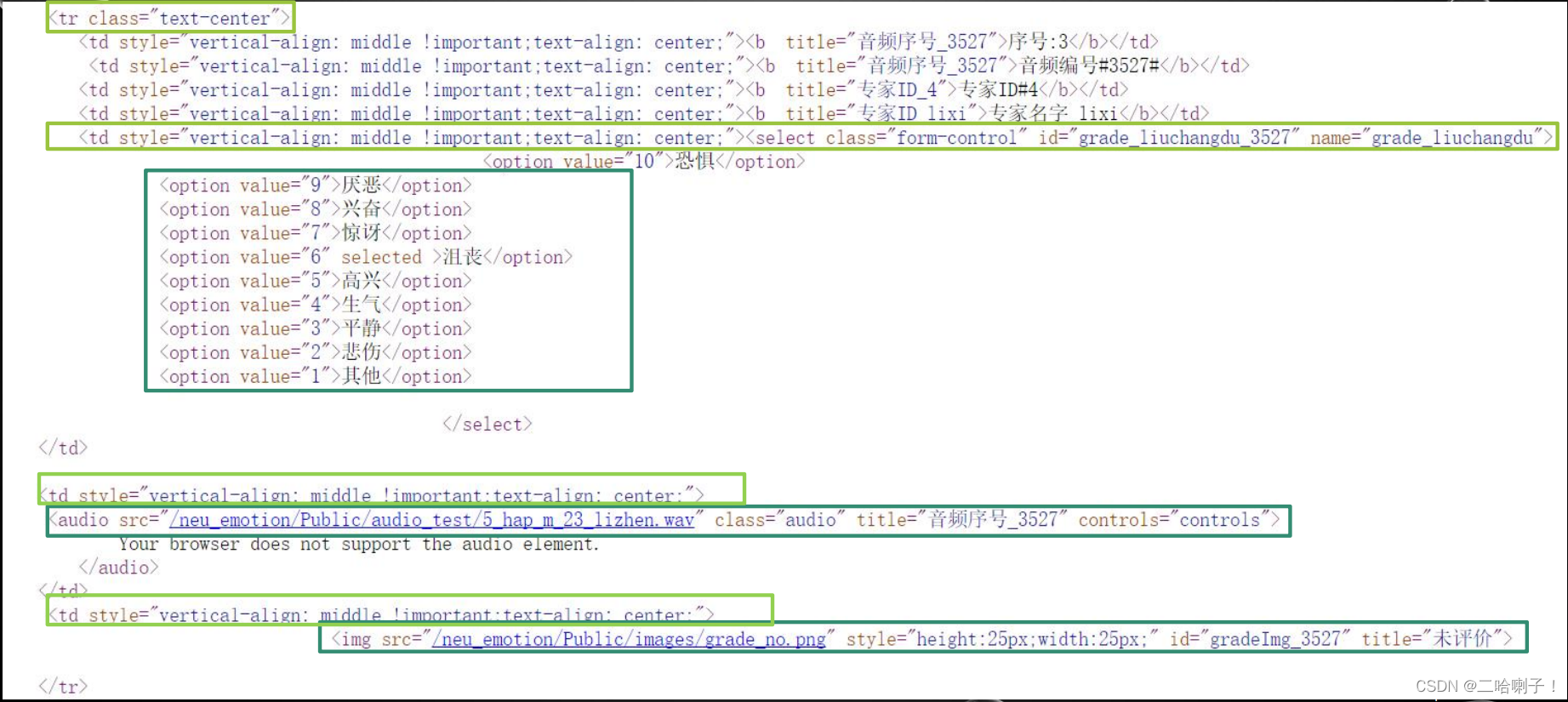
BeautifulSoup内容获取树形结构
上层是父节点 下层是子节点
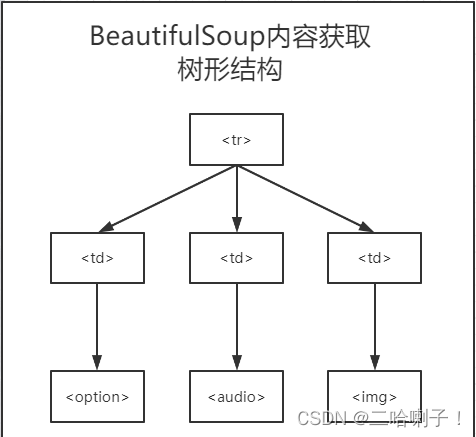
BeautifulSoup内容获取上行遍历
向上遍历
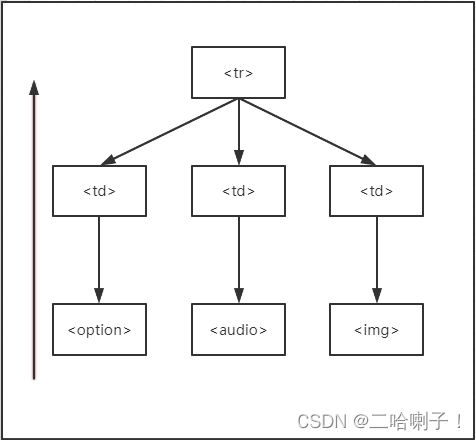
BeautifulSoup内容获取下行遍历
向下遍历
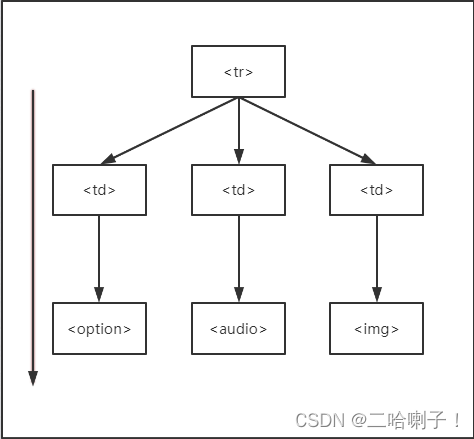
BeautifulSoup内容获取平行遍历
亲兄弟之间的遍历<td>
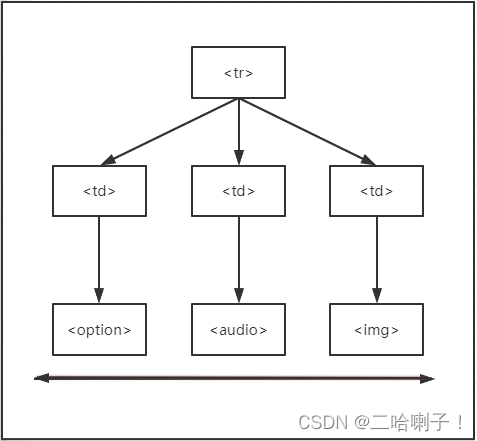
下行遍历案例
contents
子节点的列表,将子节点存入列表
children
子节点的迭代类型,循环遍历子节点
descendants
子孙节点的迭代类型
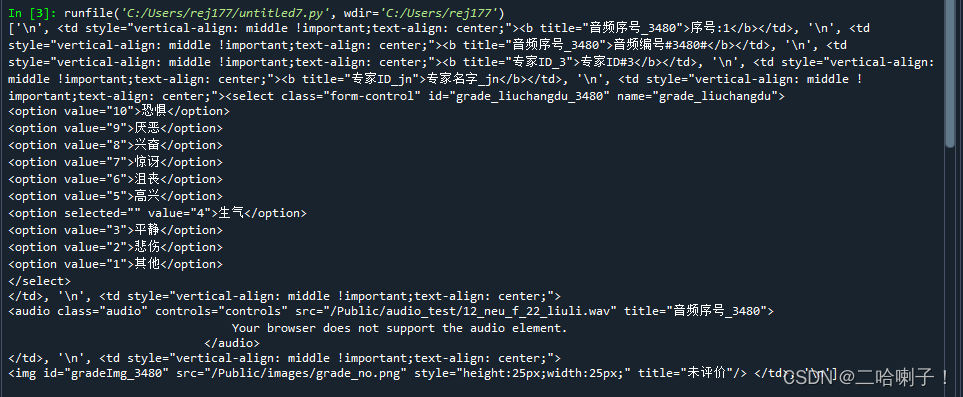
【例】查看子节点的列表
网站:http://emotion.bxbw-jyz.cn/Home/index/showPartData.html
import requests
from bs4 import BeautifulSoup
r = requests.get("http://emotion.bxbw-jyz.cn/Home/index/showPartData.html")
demo = r.text
soup = BeautifulSoup(demo,"html.parser")
content = soup.tr.contents
print(content)
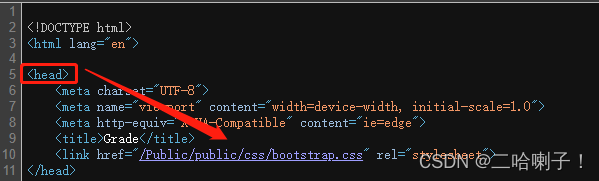
【例】如何利用head下行遍历,找到link标签的属性href ?
网站:http://emotion.bxbw-jyz.cn/Home/index/showPartData.html
import requests
from bs4 import BeautifulSoup
r = requests.get("http://emotion.bxbw-jyz.cn/Home/index/showPartData.html")
demo = r.text
soup = BeautifulSoup(demo,"html.parser")
content = soup.head.contents
attrs = content[9].attrs
link_href = attrs['href']
rel = attrs['rel']
print(content)
print(len(content))
print(link_href)
print(rel)
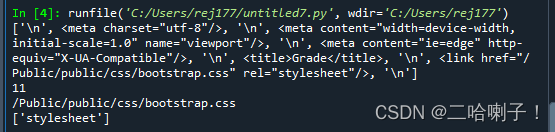
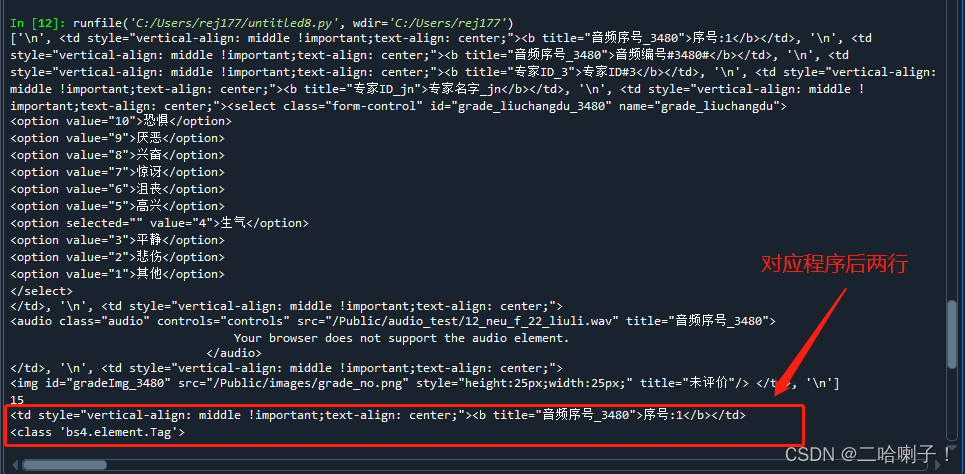
【例】查看源代码中有多少对tr子标签
网站:http://emotion.bxbw-jyz.cn/Home/index/showPartData.html
import requests
from bs4 import BeautifulSoup
r = requests.get("http://emotion.bxbw-jyz.cn/Home/index/showPartData.html")
demo = r.text
soup = BeautifulSoup(demo,"html.parser")
content = soup.tr.contents
print(content)
print(len(content))
print(content[1])
print(type(content[1]))








![Docker环境安装OWT Server[Open WebRTC Toolkit]](https://img-blog.csdnimg.cn/18b74be61abf4b4e9194ce4eba5bc770.png)