随着时代的发展,大数据越来越重要,数据获取很关键
提到数据获取大家应该都会想到爬虫,但是我不会写代码怎么玩爬虫
今天给大家分享一个不会代码也可以进行爬虫的工具,实现无代码进行数据获取
强调
这里介绍的工具大家合理合法使用,不要随意爬取数据
1.工具介绍、安装
web scraper
直达链接:web scraper

大姐可以通过浏览器加装这个插件,然后你在简单的学习了解一点前端界面知识,比如最基本的HTML、CSS 等,我们就可以借助这个插件进行无代码数据获取。
插件安装包:
链接:https://pan.baidu.com/s/1LYT_cym28epYYudr49EDIw?pwd=0200
提取码:0200
大家可以直接下载,然后安装在自己的浏览器,推荐谷歌浏览器
浏览器插件安装教程:
-
下载压缩包到本地,并解压

-
打开浏览器插件管理中心

我这里是以谷歌浏览器为演示,其他的浏览器也是大差不差,大家自行摸索 -
插件安装

记得先打开开发者模式
然后找到解压的文件,将.crx文件拖拽进来就行了
安装检验
随便打开一个网站,摁下F12,控制板的菜单栏出现 web scraper 就是成功了

2.小试牛刀
1.控制台进入初界面

2.创建sitemap
一般最开始抓取,我们新建一个sitemap

sitemap name就是根据项目自己随意了,我这里为了抓取douban_top250数据,所有我就直接这样写了,url就是目标网站了,大家根据实际进行填写

3.add new selector
 自己定义数据id之后,选择数据类型
自己定义数据id之后,选择数据类型

数据类型包括text文本、link链接、Link popup弹出链接、Image图像、Table表格、等选项
选择完数据类型之后,点击 select 直接在界面选择目标数据所在位置
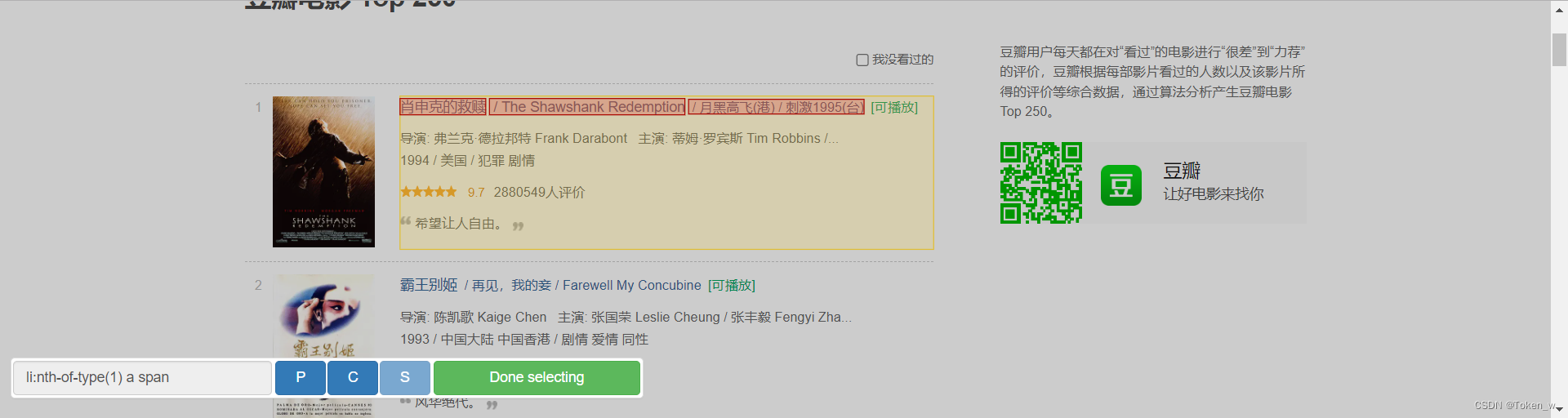
然后根据需要是否选择勾选 multiple ,如果要选择多个记录需勾选此项。从两个或多个选中 multiple 的选择器中提取的数据不会合并到一个单独记录中。
最后点击save保存,我们的一个基本的元素选择就结束了
选择更多元素大家可以自己继续选择,这里不再一一演示了
4.data preview
元素抓取是否正确,我们可以通过右上角 data preview 预览,查看是否正确

5.scrape
数据获取,在我们前期的一系列准备下,我们目前只需要点击scraps获取数据。

进行scrape时,注意设置延迟,默认2000就可以

数据导出
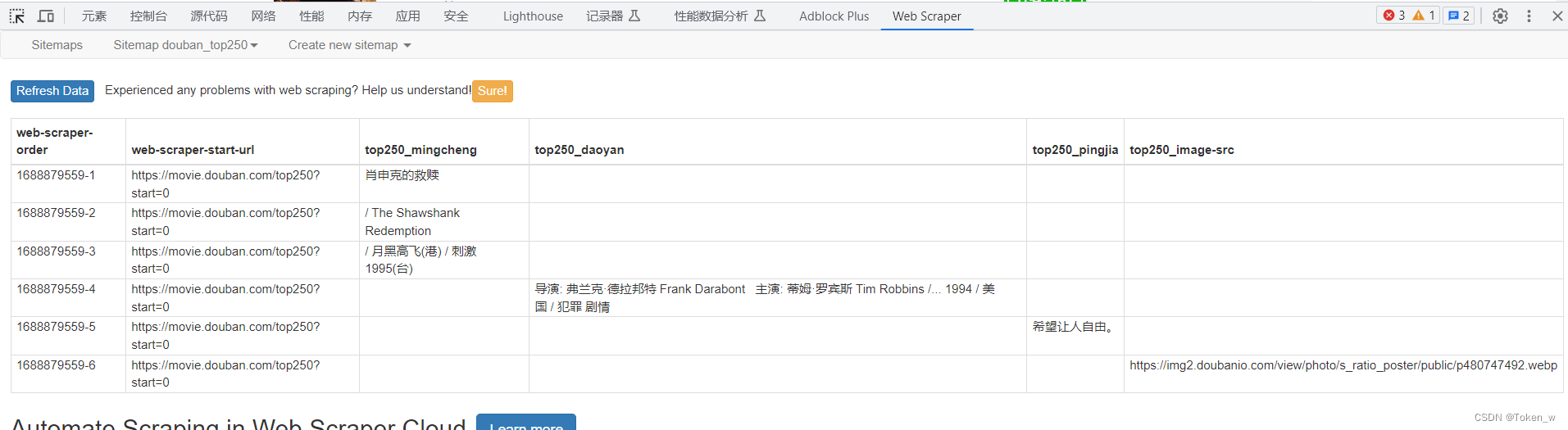
这是抓取的数据,直接再网页插件可视,当然也是可以选择export data导出

导出文件格式两中选择,根据需要选择
3.不要随意使用
这里只是给不会爬虫但是想获取信息的朋友推荐一个插件,但是大家获取数据一定要合法,不要随意爬取别人数据