引言
本着“凡我不能创造的,我就不能理解”的思想,本系列文章会基于纯Python以及NumPy从零创建自己的深度学习框架,该框架类似PyTorch能实现自动求导。
💡系列文章完整目录: 👉点此👈
要深入理解深度学习,从零开始创建的经验非常重要,从自己可以理解的角度出发,尽量不适用外部框架的前提下,实现我们想要的模型。本系列文章的宗旨就是通过这样的过程,让大家切实掌握深度学习底层实现,而不是仅做一个调包侠。
当我们训练RNN时,如果想要进行批次化训练,就得需要截断和填充。
因为句子的长短不一,一般选择一个合适的长度来进行截断;而填充是在句子过短时,需要以 填充字符 填充,使得该批次内所有的句子长度相同。
PyTorch提供pack_padded_sequence可以压缩这些填充字符,加快RNN的计算效率。我们这里参考PyTorch也实现这些相关函数。
为什么要压缩填充
填充会带来两个问题:
- 增加了计算复杂度。假设一个批次内有2个句子,长度分别为5和2。我们要保证批次内所有的句子长度相同,就需要把长度为2的句子填充为5。这样喂给RNN时,需要计算2 × 5 = 10 次,而实际真正需要的是5 + 2 = 7次。
- 得到的结果可能不准确。我们知道RNN取的是最后一个时间步的隐藏状态做为输出,虽然一般是以0填充,权重乘以零不会影响最终的输出,但在Pytorch中还有偏差b bb,如果b ≠ 0 ,还是会影响到最后的输出。当然这个问题不大。主要是第1个问题。 毕竟批次大小很大的时候影响还是不小的。
如何压缩
假设一个批次有6个句子,我们将这些句子填充后如下所示。
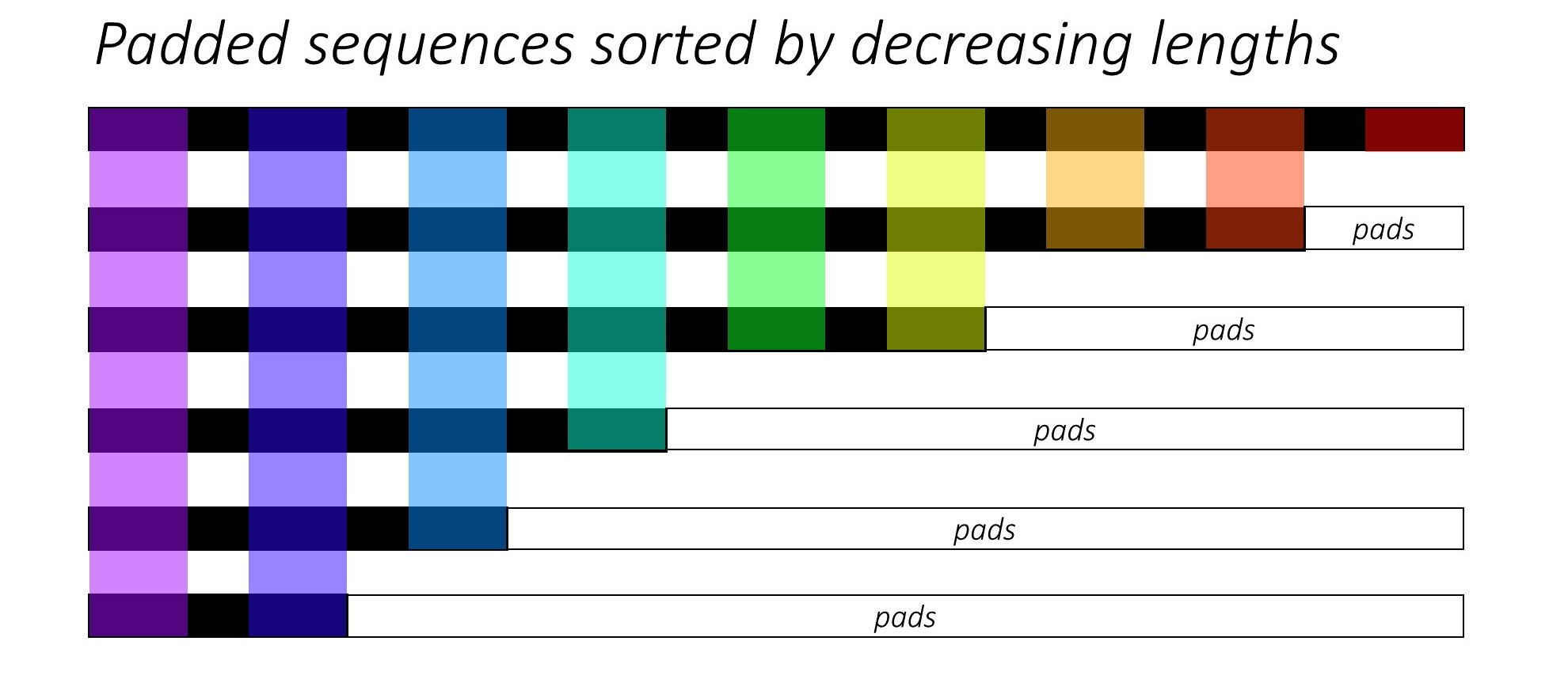
这里按句子长度逆序排序,pads就是填充。不同的颜色代表不同时间步的单词。
下面我们看pack_padded_sequence是如何压缩的。如下图所示:

pack_padded_sequence根据时间步拉平了上面排序后的句子,在每个时间步维护一个数值,代表当前时间步内有效的批大小。比如上图右边黄色区域的时间步内,只有3个输入是有效的,其他都是填充。因此说该时间步内的批大小为3。
该方法会返回一个PackedSequence对象,其中包含 data保存拉平的数据 和 batch_sizes保存时间步相应的批大小,比如上面就是tensor([6,6,5,4,3,3,2,2,1])。
这个PackedSequence对象可以传递给RNN,它会返回一个新的PackedSequence对象,接着我们可以用pad_packed_sequence方法把返回的PackedSequence还原成我们想要的形式。
实例说明
该样例由参考1中的例子改造而来。
下面我们结合一个实例来说明。
假设有一些单词序列如下:
sentences = ['crazy', 'complicate', 'medium', 'hard', 'rookie']
我们首先转换成数值并填充使长度一致:
import metagrad.module as nn
from metagrad.tensor import Tensor
from metagrad.utils import pack_padded_sequence, pad_packed_sequence, pad_sequence
sentences = ['crazy', 'complicate', 'medium', 'hard', 'rookie']
# 词典
vocab = ['<pad>'] + sorted(set([char for sentence in sentences for char in sentence]))
# 转换成数值
vectorized = [Tensor([vocab.index(t) for t in seq]) for seq in sentences]
# 每个序列的长度
lengths = Tensor(list(map(len, vectorized)))
print(lengths)
Tensor([ 5 10 6 4 6], requires_grad=False)
假设这是一个批次的话,那么该批次最大长度为10,我们填充其他序列:
padded_seq = pad_sequence(vectorized)
print(padded_seq)
Tensor(
[[ 2 12 1 16 15 0 0 0 0 0] # crazy
[ 2 10 9 11 8 6 2 1 13 4] # complicate
[ 9 4 3 6 14 9 0 0 0 0] # medium
[ 5 1 12 3 0 0 0 0 0 0] # hard
[12 10 10 7 6 4 0 0 0 0]]# rookie
,requires_grad=False)
可以看到,每个单词序列都被填充为长度10。此时的形状是(batch_size, seq_len) = (5, 10)。
我们就得到了padded sequence,要打包成packed sequence,需要先按长度由大到小对上述批数据进行排序。
较新版本的pytorch打packed sequence时支持自动排序,即不需要显示地进行排序。我们这里第一版实现的还是需要预先排序的。
为了支持排序,我们需要实现一个新的操作sort。
实现Sort Function
class Sort(Function):
def forward(self, x: NdArray, axis=-1, descending=False) -> Tuple[NdArray, NdArray]:
xp = get_array_module(x)
# 在指定维度上对数组进行排序
# sorted_x = xp.sort(x, axis=axis)
sorted_indices = xp.argsort(x, axis=axis)
sorted_x = xp.take_along_axis(x, sorted_indices, axis=axis)
if descending:
# 如果设置了descending为True,则按降序排序
sorted_x = xp.flip(sorted_x, axis=axis)
sorted_indices = xp.flip(sorted_indices, axis=axis)
self.save_for_backward(axis, xp, sorted_indices)
return sorted_x, sorted_indices
def backward(self, *grad: NdArray) -> NdArray:
axis, xp, indices = self.saved_tensors
# forward返回了多个,只有非索引才有梯度
grad = grad[0]
# 逆转排序后的索引
inverse_permutation = xp.argsort(indices, axis=axis)
return xp.take_along_axis(grad, inverse_permutation, axis=axis)
内部调用numpy/cupy#argsort对输入x进行排序,返回排序后的索引,然后通过这个索引得到排序后的序列。这里支持指定维度axis和降序/升序descending。就像torch.sort一样。
在反向传播时,我们只取排序后的序列的grad,因为索引是没有梯度的。
这里关键的一步是逆转排序后的索引,通过argsort(indices, axis=axis)实现。indices是排序后的索引。然后根据逆转排序后的索引和维度从grad中取梯度。
并且添加了几个测试用例,具体可以看源码。
好了,实现了sort之后,我们就对上面的批数据进行排序。
sorted_lengths, sorted_indices = lengths.sort(0, descending=True)
padded_seq = padded_seq[sorted_indices]
print(padded_seq)
实际上是对长度Tensor进行排序,然后通过排序后的索引,得到排序后的批数据:
Tensor(
[[ 2 10 9 11 8 6 2 1 13 4] # complicate
[12 10 10 7 6 4 0 0 0 0] # rookie
[ 9 4 3 6 14 9 0 0 0 0] # medium
[ 2 12 1 16 15 0 0 0 0 0] # crazy
[ 5 1 12 3 0 0 0 0 0 0]]# hard
, requires_grad=False)
每个单词都标出来了。这里要注意的是,同样长度的单词rookie和medium交换了顺序,因为numpy.argsort默认为quicksort,这是一种非稳定算法,感兴趣的可以看看 快速排序分析。
现在我们有了填充后的数据,并且也按照长度进行排序,接下来看如何压缩。
在压缩之前,我们先经过词嵌入层:
embed = nn.Embedding(len(vocab), 3) # embedding_dim = 3
embedded_seq = embed(padded_seq)
print(embedded_seq) # (batch_size, seq_len, embed_size)
Tensor(
[[[0.3222 0.2082 0.0166] # c
[0.5821 0.8482 0.6586] # o
[0.2423 0.8599 0.5947] # m
[0.5781 0.4923 0.6869] # p
[0.3805 0.0511 0.2411] # l
[0.3645 0.778 0.3711] # i
[0.3222 0.2082 0.0166] # c
[0.3982 0.2133 0.7391] # a
[0.2787 0.4415 0.975 ] # t
[0.6541 0.3558 0.5387]]# e
[[0.1267 0.457 0.2262] # r
[0.5821 0.8482 0.6586] # o
[0.5821 0.8482 0.6586] # o
[0.6753 0.5637 0.4325] # k
[0.3645 0.778 0.3711] # i
[0.6541 0.3558 0.5387] # e
[0.514 0.874 0.8689] # <pad>
[0.514 0.874 0.8689] # <pad>
[0.514 0.874 0.8689] # <pad>
[0.514 0.874 0.8689]]# <pad>
[[0.2423 0.8599 0.5947] # m
[0.6541 0.3558 0.5387] # e
[0.2034 0.0254 0.2949] # d
[0.3645 0.778 0.3711] # i
[0.4798 0.7325 0.7202] # u
[0.2423 0.8599 0.5947] # m
[0.514 0.874 0.8689] # <pad>
[0.514 0.874 0.8689] # <pad>
[0.514 0.874 0.8689] # <pad>
[0.514 0.874 0.8689]]# <pad>
[[0.3222 0.2082 0.0166] # c
[0.1267 0.457 0.2262] # r
[0.3982 0.2133 0.7391] # a
[0.1112 0.6079 0.877 ] # z
[0.5113 0.9715 0.5163] # y
[0.514 0.874 0.8689] # <pad>
[0.514 0.874 0.8689] # <pad>
[0.514 0.874 0.8689] # <pad>
[0.514 0.874 0.8689] # <pad>
[0.514 0.874 0.8689]]# <pad>
[[0.7185 0.5206 0.25 ] # h
[0.3982 0.2133 0.7391] # a
[0.1267 0.457 0.2262] # r
[0.2034 0.0254 0.2949] # d
[0.514 0.874 0.8689] # <pad>
[0.514 0.874 0.8689] # <pad>
[0.514 0.874 0.8689] # <pad>
[0.514 0.874 0.8689] # <pad>
[0.514 0.874 0.8689] # <pad>
[0.514 0.874 0.8689]]# <pad>
], requires_grad=True)
它的形状是(batch_size, seq_len, embed_size) = (5, 10, 3)。
接下来就调用pack_padded_sequence方法,传入嵌入序列以及排序后的长度(转换为list)。且这里是批大小在前的形式:
result = pack_padded_sequence(embedded_seq, sorted_lengths.tolist(), batch_first=True)
它返回的result是PackedSequence对象,包含data和batch_sizes。
PackedSequence(data=Tensor(
[[0.3222 0.2082 0.0166] # c
[0.1267 0.457 0.2262] # r
[0.2423 0.8599 0.5947] # m
[0.3222 0.2082 0.0166] # c
[0.7185 0.5206 0.25 ] # h ---------------------- batch_size 5
[0.5821 0.8482 0.6586] # o
[0.5821 0.8482 0.6586] # o
[0.6541 0.3558 0.5387] # e
[0.1267 0.457 0.2262] # r
[0.3982 0.2133 0.7391] # a ---------------------- batch_size 5
[0.2423 0.8599 0.5947] # m
[0.5821 0.8482 0.6586] # o
[0.2034 0.0254 0.2949] # d
[0.3982 0.2133 0.7391] # a
[0.1267 0.457 0.2262] # r ---------------------- batch_size 5
[0.5781 0.4923 0.6869] # p
[0.6753 0.5637 0.4325] # k
[0.3645 0.778 0.3711] # i
[0.1112 0.6079 0.877 ] # z
[0.2034 0.0254 0.2949] # d ---------------------- batch_size 5
[0.3805 0.0511 0.2411] # l
[0.3645 0.778 0.3711] # i
[0.4798 0.7325 0.7202] # u
[0.5113 0.9715 0.5163] # y ---------------------- batch_size 4
[0.3645 0.778 0.3711] # i
[0.6541 0.3558 0.5387] # e
[0.2423 0.8599 0.5947] # m ---------------------- batch_size 3
[0.3222 0.2082 0.0166] # c ---------------------- batch_size 1
[0.3982 0.2133 0.7391] # a ---------------------- batch_size 1
[0.2787 0.4415 0.975 ] # t ---------------------- batch_size 1
[0.6541 0.3558 0.5387]]# e ---------------------- batch_size 1
,requires_grad=True), batch_sizes=[5, 5, 5, 5, 4, 3, 1, 1, 1, 1])
data的形状是(sum_seq_len,embedding_dim) = (31,3)
其中sum_seq_len是该批次内序列有效的长度之和。可以看到,经过压缩后的序列不再包含填充<pad>对应的嵌入。
可以看到共有10个时间步,每个时间步上有效的batch_size可能不一样,也可能一样。反映在batch_sizes字段。
上面标出了单词中每个字母,如果没理解可以结合前面的图片描述以及下面:
# c o m p l i c a t e # complicate
# r o o k i e # rookie
# m e d i u m # medium
# c r a z y # crazy
# h a r d # hard
# 5 5 5 5 4 3 1 1 1 1 # batch_sizes (sum = 31 [sum_seq_len])
比如c r m c h分别是排序后输入单词的第一个字母,即第一个时间步的输入。最短的单词长度为4,因此前面4步都有5个输入;在第5个时间步的(有效)输入只包含前4个单词;从第7个时间步开始到最后一个时间步,只有complicate的输入,对应cate。
此时在回顾前文那句话: “pack_padded_sequence根据时间步拉平了上面排序后的句子,在每个时间步维护一个数值,代表当前时间步内有效的批大小。”应该就好理解了。
压缩后的输入就可以传给RNN进行更加高效地计算了。
不过,光理解原理还不够,我们还要实现它。
实现PackedSequence
class PackedSequence(NamedTuple):
data: Tensor # 包含packed sequence
batch_sizes: List[int] # 序列每个时间步的批大小
我们这里实现简单的PackedSequence,只包含两个属性,分别保存压缩后的变量和每个时间步的批大小。
实现pack_padded_sequence
def pack_padded_sequence(input: Tensor, lengths: List[int], batch_first: bool = False):
"""
压缩填充后的序列,批次内序列需要先按照有效长度降序排序
:param input: 输入序列 如果batch_first=True,形状为(batch_size, seq_len, embdding_size)
如果batch_first=False,形状为(seq_len, batch_size, embdding_size)
:param lengths: 批次内每个序列的有效长度
:param batch_first: 是否批大小维度在前
:return:
"""
if batch_first:
# 转换成seq_len在前的形式
input = input.transpose((1, 0, 2))
steps = []
# 每个step的批大小
batch_sizes = []
# 对长度进行逆序
lengths_iter = reversed(lengths)
# 当前长度
current_length = next(lengths_iter)
# 取出批大小
batch_size = input.size(1)
# lengths应该包含批大小个序列
if len(lengths) != batch_size:
raise ValueError("lengths array has incorrect size")
# 现在是seq_len在前的形式,按seq_len维度取出每个句子,索引(step)从1开始
for step, step_value in enumerate(input, 1):
steps.append(step_value[:batch_size]) # 把step_value添加到steps,:batch_size取有效数据(不包括填充)
batch_sizes.append(batch_size) # 记录该step有效的序列个数
while step == current_length: # 表示此时长度为current_length的填完了
try:
new_length = next(lengths_iter) # 按照逆序取新的长度
except StopIteration: # 遍历完lengths_iter
current_length = None # 将current_length设为None
break # 跳出while循环
batch_size -= 1 # 但批大小减去1
current_length = new_length # 新的长度赋值给current_length
if current_length is None: # 表示此时已经遍历完了
break # 可以跳出for循环
return PackedSequence(F.cat(steps), batch_sizes)
参数就三个,填充后的序列、排序后的长度列表、是否batch_first。
比如上面那个例子中,排序后的长度列表就是 [10 6 6 5 4]。
上面方法主要的过程为,将排序后的长度列表取逆序,依次遍历。比如,上面第一个是4,前4个时间步的批大小都是batch_size=5,将前4个时间步的 形状为(5,3)的有效输入存入steps ,此时hard处理完了;然后取出新的长度5,批大小也减1,变成了batch_size=4。将(4,3)(对应l,i,u,y)存入steps。此时满足while循环,说明crazy也处理完了;继续取出新长度6,批大小又减1,变成了batch_size=3,把(3,3)(对应 i,e,m)存入steps;接着再次取出新的长度(还是)6,批大小又减1,变成了batch_size=2,但发现长度6的已经处理完了;再次取出新的长度10,批大小又减1,变成了batch_size=1,最后依次处理complicate最后四个字母cate。
最终返回PackedSequence对象,包含压缩后的输入和每个时间步内有效的批大小。
实现pad_packed_sequence
通常拿到PackedSequence对象后,我们就可以输入到RNN中进行运算了,然后在运算结果上调用pack_padded_sequence的逆操作pad_packed_sequence把它转换会原来的填充后的形式。
这中间可能会发现词嵌入维度转变成隐藏状态维度,但序列长度是不变的。
一般没有人直接压缩后就进行解压缩的,我们为了演示,马上进行解压缩。
output, input_sizes = pad_packed_sequence(result, batch_first=True)
print(output.shape)
print(input_sizes)
(5, 10, 3)
[10, 6, 6, 5, 4]
我们打印还原后的output:
print(output)
Tensor(
[[[0.3222 0.2082 0.0166] # c
[0.5821 0.8482 0.6586] # o
[0.2423 0.8599 0.5947] # m
[0.5781 0.4923 0.6869] # p
[0.3805 0.0511 0.2411] # l
[0.3645 0.778 0.3711] # i
[0.3222 0.2082 0.0166] # c
[0.3982 0.2133 0.7391] # a
[0.2787 0.4415 0.975 ] # t
[0.6541 0.3558 0.5387]]# e
[[0.1267 0.457 0.2262] # r
[0.5821 0.8482 0.6586] # o
[0.5821 0.8482 0.6586] # o
[0.6753 0.5637 0.4325] # k
[0.3645 0.778 0.3711] # i
[0.6541 0.3558 0.5387] # e
[0. 0. 0. ] # <pad>
[0. 0. 0. ] # <pad>
[0. 0. 0. ] # <pad>
[0. 0. 0. ]]# <pad>
[[0.2423 0.8599 0.5947] # m
[0.6541 0.3558 0.5387] # e
[0.2034 0.0254 0.2949] # d
[0.3645 0.778 0.3711] # i
[0.4798 0.7325 0.7202] # u
[0.2423 0.8599 0.5947] # m
[0. 0. 0. ] # <pad>
[0. 0. 0. ] # <pad>
[0. 0. 0. ] # <pad>
[0. 0. 0. ]]# <pad>
[[0.3222 0.2082 0.0166] # c
[0.1267 0.457 0.2262] # r
[0.3982 0.2133 0.7391] # a
[0.1112 0.6079 0.877 ] # z
[0.5113 0.9715 0.5163] # y
[0. 0. 0. ] # <pad>
[0. 0. 0. ] # <pad>
[0. 0. 0. ] # <pad>
[0. 0. 0. ] # <pad>
[0. 0. 0. ]]# <pad>
[[0.7185 0.5206 0.25 ] # h
[0.3982 0.2133 0.7391] # a
[0.1267 0.457 0.2262] # r
[0.2034 0.0254 0.2949] # d
[0. 0. 0. ] # <pad>
[0. 0. 0. ] # <pad>
[0. 0. 0. ] # <pad>
[0. 0. 0. ] # <pad>
[0. 0. 0. ] # <pad>
[0. 0. 0. ] # <pad>
]], requires_grad=False)
由于我们在压缩的时候没有记录<pad>对应的嵌入,实际上也没必要记录,这里默认用0.表示。
下面就来实现解压缩:
def pad_packed_sequence(sequence: PackedSequence, batch_first=False):
"""
pack_padded_sequence的逆操作
:param sequence: PackedSequence
:param batch_first: 是否批大小维度在前
:return:
"""
# 取出data和batch_sizes
var_data, batch_sizes = sequence
# 0位置一定包含最大的批大小
max_batch_size = batch_sizes[0]
# 构建一个输出Tensor 形状为 (seq_len, batch_size, hidden_size?)
output = Tensor.zeros((len(batch_sizes), max_batch_size, *var_data.shape[1:]))
# 批次内实际的序列长度
lengths = []
# data的偏移量
data_offset = 0
# 前一个批大小
prev_batch_size = batch_sizes[0]
# 遍历batch_sizes,索引从0开始
for i, batch_size in enumerate(batch_sizes):
# 第i个位置(seq_len维度)取var_data从data_offset开始到第batch_size个
output[i, :batch_size] = var_data[data_offset:data_offset + batch_size]
# 偏移量加上实际取的batch_size
data_offset += batch_size
# 上一个batch_size 减去 当前batch_size
dec = prev_batch_size - batch_size
# 如果结果大于0
if dec > 0:
# 表示有dec个长度为i的序列
lengths.extend((i,) * dec)
# 把batch_size赋给prev_batch_size
prev_batch_size = batch_size
# 剩下batch_size个长度为i+1的序列
lengths.extend((i + 1,) * batch_size)
# 现在是从小到大的顺序,逆序成从大到小
lengths.reverse()
# 如果是batch_first,则转回batch_first的形式,因为在pack_padded_sequence中转了一次
if batch_first:
output = output.transpose((1, 0, 2))
return output, lengths
每行代码都有解释,实际上就是根据batch_sizes依次取出有效的输入填充到(seq_len, batch_size, hidden_size?)的output。这里hidden_size多了个?表示也可能是embed_size。
这样,我们实现了压缩和解压填充序列,下篇文章我们看如何应用到RNN中。
完整代码
本文对应的代码在 : github
参考
- Minimal tutorial on packing
- Pytorch中pack_padded_sequence和pad_packed_sequence的理解
- PyTorch源码