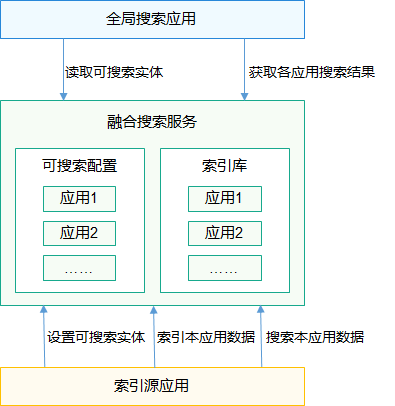
数据结构
/*
* main unit of I/O for the block layer and lower layers (ie drivers and
* stacking drivers)
*/
struct bio {
struct bio *bi_next; /* request queue link */
struct gendisk *bi_disk;
unsigned int bi_opf; /* bottom bits req flags,
* top bits REQ_OP. Use
* accessors.
*/
unsigned short bi_flags; /* status, etc and bvec pool number */
unsigned short bi_ioprio;
unsigned short bi_write_hint;
blk_status_t bi_status;
u8 bi_partno;
/* Number of segments in this BIO after
* physical address coalescing is performed.
*/
unsigned int bi_phys_segments;
/*
* To keep track of the max segment size, we account for the
* sizes of the first and last mergeable segments in this bio.
*/
unsigned int bi_seg_front_size;
unsigned int bi_seg_back_size;
struct bvec_iter bi_iter;
atomic_t __bi_remaining;
bio_end_io_t *bi_end_io;
void *bi_private;
#ifdef CONFIG_BLK_CGROUP
/*
* Optional ioc and css associated with this bio. Put on bio
* release. Read comment on top of bio_associate_current().
*/
struct io_context *bi_ioc;
struct cgroup_subsys_state *bi_css;
#ifdef CONFIG_BLK_DEV_THROTTLING_LOW
void *bi_cg_private;
struct blk_issue_stat bi_issue_stat;
#endif
#endif
union {
#if defined(CONFIG_BLK_DEV_INTEGRITY)
struct bio_integrity_payload *bi_integrity; /* data integrity */
#endif
};
unsigned short bi_vcnt; /* how many bio_vec's */
/*
* Everything starting with bi_max_vecs will be preserved by bio_reset()
*/
unsigned short bi_max_vecs; /* max bvl_vecs we can hold */
atomic_t __bi_cnt; /* pin count */
struct bio_vec *bi_io_vec; /* the actual vec list */
struct bio_set *bi_pool;
/* Encryption context. May contain secret key material. */
struct bio_crypt_ctx bi_crypt_ctx;
/*
* We can inline a number of vecs at the end of the bio, to avoid
* double allocations for a small number of bio_vecs. This member
* MUST obviously be kept at the very end of the bio.
*/
struct bio_vec bi_inline_vecs[0];
};
/*
* was unsigned short, but we might as well be ready for > 64kB I/O pages
*/
struct bio_vec {
struct page *bv_page;
unsigned int bv_len;
unsigned int bv_offset;
};
struct bvec_iter {
sector_t bi_sector; /* device address in 512 byte
sectors */
unsigned int bi_size; /* residual I/O count */
unsigned int bi_idx; /* current index into bvl_vec */
unsigned int bi_done; /* number of bytes completed */
unsigned int bi_bvec_done; /* number of bytes completed in
current bvec */
};bio的作用
已读取文件为例,必须知道文件内偏移和磁盘数据块的映射关系,比如已Ext4文件系统为例,可以通过ext4_map_blocks查找extent B+数据查到映射关系,而读取磁盘数据存放到page cache中,而bio正是:描述磁盘数据块和page cache页的对应关系。每个bio对应磁盘一块连续的位置,这个连续的位置可以对应一或者多个page,所以一个bio有一个bi_io_vec表。这样的好处是读取的文件是连续的一块,那么只要一个bio即可。磁盘数据块由bvec_iter中的bi_sector表示,代表读取的连续数据块的一个扇区号。
正如宋宝华文章中提到的(这小段引用自参考文章):
我们现在假设2种情况
第1种情况是page_cache_sync_readahead()要读的0~16KB数据,在硬盘里面正好是顺序排列的(是否顺序排列,要查文件系统,如ext3、ext4),Linux会为这一次4页的读,分配1个bio就足够了,并且让这个bio里面分配4个bi_io_vec,指向4个不同的内存页:
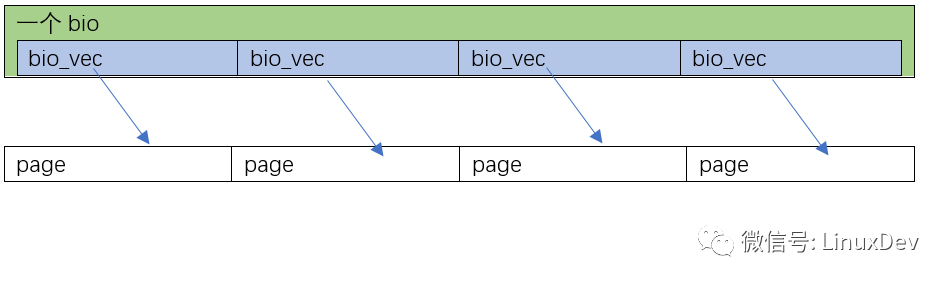
第2种情况是page_cache_sync_readahead()要读的0~16KB数据,在硬盘里面正好是完全不连续的4块 (是否顺序排列,要查文件系统,如ext3、ext4),Linux会为这一次4页的读,分配4个bio,并且让这4个bio里面,每个分配1个bi_io_vec,指向4个不同的内存页面:

当然你还可以有第3种情况,比如0~8KB在硬盘里面连续,8~16KB不连续,那可以是这样的:

读取文件场景bio的创建和使用
ext4_mpage_readpages函数就会读取磁盘数据就会构建一个个的bio,如上面描述我们知道bio指向的是一块连续的磁盘数据,也就是说如果读取文件不连续之后,就要新建一个bio,我们看看ext4_mpage_readpages是怎么实现该逻辑的:
int ext4_mpage_readpages(struct address_space *mapping,
struct list_head *pages, struct page *page,
unsigned nr_pages)
{
struct bio *bio = NULL;
sector_t last_block_in_bio = 0;
struct inode *inode = mapping->host;
const unsigned blkbits = inode->i_blkbits;
const unsigned blocks_per_page = PAGE_SIZE >> blkbits;
const unsigned blocksize = 1 << blkbits;
sector_t block_in_file;
sector_t last_block;
sector_t last_block_in_file;
sector_t blocks[MAX_BUF_PER_PAGE];
unsigned page_block;
struct block_device *bdev = inode->i_sb->s_bdev;
int length;
unsigned relative_block = 0;
struct ext4_map_blocks map;
map.m_pblk = 0;
map.m_lblk = 0;
map.m_len = 0;
map.m_flags = 0;
for (; nr_pages; nr_pages--) {
int fully_mapped = 1;
unsigned first_hole = blocks_per_page;
prefetchw(&page->flags);
if (pages) {
page = list_entry(pages->prev, struct page, lru);
list_del(&page->lru);
if (add_to_page_cache_lru(page, mapping, page->index,
readahead_gfp_mask(mapping)))
goto next_page;
}
if (page_has_buffers(page))
goto confused;
block_in_file = (sector_t)page->index << (PAGE_SHIFT - blkbits);
last_block = block_in_file + nr_pages * blocks_per_page;
last_block_in_file = (i_size_read(inode) + blocksize - 1) >> blkbits;
if (last_block > last_block_in_file)
last_block = last_block_in_file;
page_block = 0;
/*
* Map blocks using the previous result first.
*/
//1:
if ((map.m_flags & EXT4_MAP_MAPPED) &&
block_in_file > map.m_lblk &&
block_in_file < (map.m_lblk + map.m_len)) {
unsigned map_offset = block_in_file - map.m_lblk;
unsigned last = map.m_len - map_offset;
for (relative_block = 0; ; relative_block++) {
if (relative_block == last) {
/* needed? */
map.m_flags &= ~EXT4_MAP_MAPPED;
break;
}
if (page_block == blocks_per_page)
break;
blocks[page_block] = map.m_pblk + map_offset +
relative_block;
page_block++;
block_in_file++;
}
}
/*
* Then do more ext4_map_blocks() calls until we are
* done with this page.
*/
//2:
while (page_block < blocks_per_page) {
if (block_in_file < last_block) {
map.m_lblk = block_in_file;
map.m_len = last_block - block_in_file;
if (ext4_map_blocks(NULL, inode, &map, 0) < 0) {
set_error_page:
SetPageError(page);
zero_user_segment(page, 0,
PAGE_SIZE);
unlock_page(page);
goto next_page;
}
}
//3:
if ((map.m_flags & EXT4_MAP_MAPPED) == 0) {
fully_mapped = 0;
if (first_hole == blocks_per_page)
first_hole = page_block;
page_block++;
block_in_file++;
continue;
}
if (first_hole != blocks_per_page)
goto confused; /* hole -> non-hole */
/* Contiguous blocks? */
//4:
if (page_block && blocks[page_block-1] != map.m_pblk-1)
goto confused;
//5
for (relative_block = 0; ; relative_block++) {
if (relative_block == map.m_len) {
/* needed? */
map.m_flags &= ~EXT4_MAP_MAPPED;
break;
} else if (page_block == blocks_per_page)
break;
blocks[page_block] = map.m_pblk+relative_block;
page_block++;
block_in_file++;
}
}
//6:
if (first_hole != blocks_per_page) {
zero_user_segment(page, first_hole << blkbits,
PAGE_SIZE);
if (first_hole == 0) {
SetPageUptodate(page);
unlock_page(page);
goto next_page;
}
} else if (fully_mapped) {
//7
SetPageMappedToDisk(page);
}
if (fully_mapped && blocks_per_page == 1 &&
!PageUptodate(page) && cleancache_get_page(page) == 0) {
SetPageUptodate(page);
goto confused;
}
/*
* This page will go to BIO. Do we need to send this
* BIO off first?
*/
//8:
if (bio && (last_block_in_bio != blocks[0] - 1)) {
submit_and_realloc:
ext4_submit_bio_read(bio);
bio = NULL;
}
if (bio == NULL) {
struct fscrypt_ctx *ctx = NULL;
if (ext4_encrypted_inode(inode) &&
S_ISREG(inode->i_mode)) {
ctx = fscrypt_get_ctx(inode, GFP_NOFS);
if (IS_ERR(ctx))
goto set_error_page;
}
bio = bio_alloc(GFP_KERNEL,
min_t(int, nr_pages, BIO_MAX_PAGES));
if (!bio) {
if (ctx)
fscrypt_release_ctx(ctx);
goto set_error_page;
}
bio_set_dev(bio, bdev);
bio->bi_iter.bi_sector = blocks[0] << (blkbits - 9);
bio->bi_end_io = mpage_end_io;
bio->bi_private = ctx;
ext4_set_bio_ctx(inode, bio);
bio_set_op_attrs(bio, REQ_OP_READ, 0);
}
length = first_hole << blkbits;
//9
if (bio_add_page(bio, page, length, 0) < length)
goto submit_and_realloc;
if (((map.m_flags & EXT4_MAP_BOUNDARY) &&
(relative_block == map.m_len)) ||
(first_hole != blocks_per_page)) {
ext4_submit_bio_read(bio);
bio = NULL;
} else
last_block_in_bio = blocks[blocks_per_page - 1];
goto next_page;
//10
confused:
if (bio) {
ext4_submit_bio_read(bio);
bio = NULL;
}
if (!PageUptodate(page))
block_read_full_page(page, ext4_get_block);
else
unlock_page(page);
next_page:
if (pages)
put_page(page);
}
BUG_ON(pages && !list_empty(pages));
if (bio)
ext4_submit_bio_read(bio);
return 0;
}1:第2步中调用ext4_map_blocks的时候map.m_len可以连续映射多个block,这样下次循环时候EXT4_MAP_MAPPED flag就是设置,使用先前映射好的结果即可。
2:ext4_map_blocks执行真正的文件逻辑地址到磁盘地址的映射。如果错误返回值小于0,没有错误的时候返回的是映射的block数。注意:假设map.m_len = 32,实际ext4 extent tree上没有连续32个block,这种情况就无法映射32个block,比如可能仅仅映射了10个block,此时map.m_flags依然会设置EXT4_MAP_MAPPED。
ext4_map_blocks->ext4_ext_map_blocks:
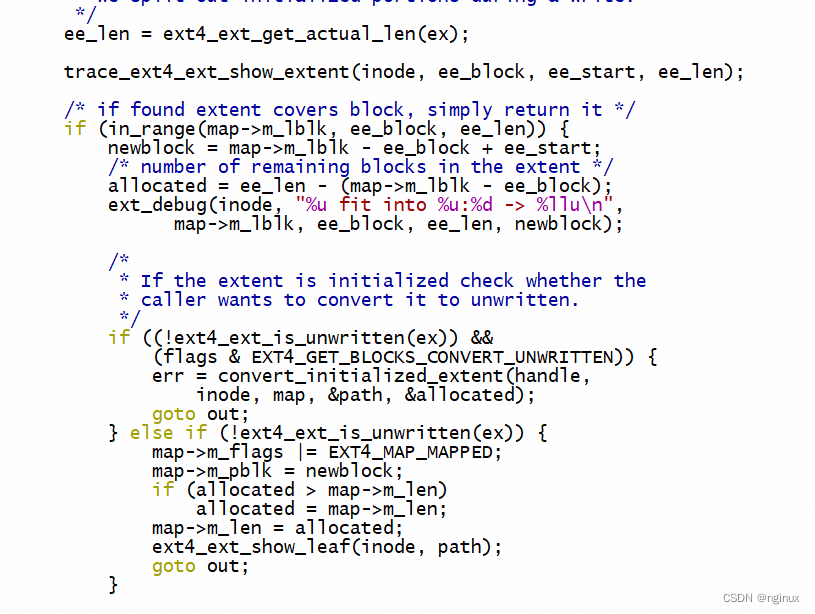
上面代码逻辑需要理解ext4 extent tree查找逻辑,ee_len代表ex映射的连续物理块个数,ee_block代表ex映射的起始路基块地址,ee_start:ex起始逻辑地址映射的起始物理块号。代码中newblock=map->m_lblk - ee_block + ee_start即是起始逻辑地址映射的磁盘块地址,allocated = ee_len - (map->m_lblk - ee_block)是成功映射的block数,注意未必等于map.m_len,有可能小于map.m_len,因为磁盘block未必有map.m_len个连续的块。
3:没有设置EXT4_MAP_MAPPED的情况,比如是file hole(文件洞)的情况,此处暂不考虑该种情况。
4:blocks[page_block-1] != map.m_pblk-1条件满足时,代表着block块不再连续,根据bio的设计原则,一旦block不连续,就需要新建一个bio,goto confuse就是处理不连续情况,提交当前的bio,并且bio = NULL,后面就新建bio了。注意这里主要是针对一个page内的block不连续,比如page size = 4K, block size = 1K,一个page中存在4个 block 块缓冲区,可能这4个block就不连续,这里就是处理这种情况,一旦不连续goto confuse就会调用进入block_read_full_page逻辑。
5:调用到这里代表block是连续,将物理block地址存入blocks数组中。
6:有file hole的情况,直接将page cache数据设置0,并且SetPageUptodate及unlock_page解锁page。否则进入7。
7:SetPageMappedToDisk设置BH_Mapped标志位,代表成功完成了逻辑地址到磁盘block地址的映射。
8:这里主要是针对page间block块不连续问题,block块不连续后submit_bio提交当前的bio,然后bio = NULL,触发if(bio = NULL)重新创建新的bio。
9:bio_add_page将page加入bio中,因为前面提到一个bio可以包含多个page,所以连续的block对应的page可以一直通过bio_add_page加入到bio中。
10:confused代表block不连续情况的一种处理逻辑。
参考文章:
宋宝华: 文件读写(BIO)波澜壮阔的一生
Linux 通用块层 bio 详解 – 字节岛技术分享