大模型参数高效微调(PEFT) - 知乎
让天下没有难Tuning的大模型-PEFT技术简介 - 知乎
大模型参数高效微调技术原理综述(三)-P-Tuning、P-Tuning v2 - 知乎
你似乎来到了没有知识存在的荒原 - 知乎
大模型参数高效微调技术原理综述(六)-MAM Adapter、UniPELT - 知乎
PEFT:Parameter Efficient Fine-Tuning技术旨在通过最小化微调参数的数量和计算复杂度,来提高预训练模型在新任务上的性能,从而缓解大型预训练模型的训练成本。
Prefix-Tuning(软提示/连续提示)
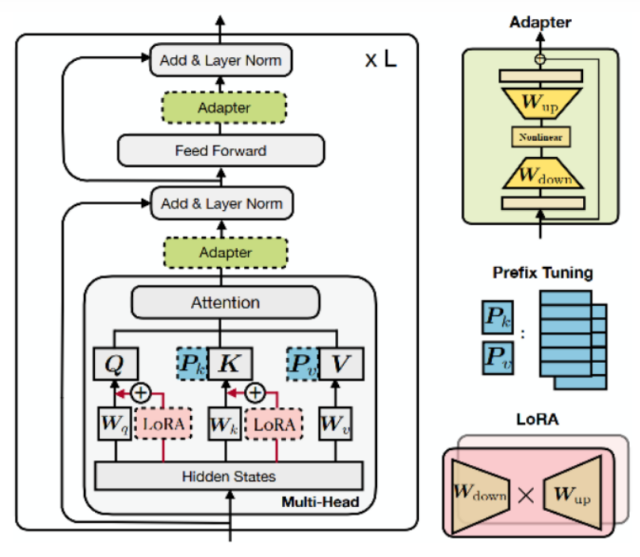
- 在每一层的token之前构造一段任务相关的tokens作为Prefix,训练时只更新Prefix部分的参数,而Transformer中的其他部分参数固定
- 一个Prefix模块就是一个可学习的id到embedding映射表,可以在多层分别添加Prefix模块
- 为了防止直接更新Prefix的参数导致训练不稳定的情况,在Prefix层前面加了MLP结构
- 作用阶段:所有transformer block的Attention注意力计算
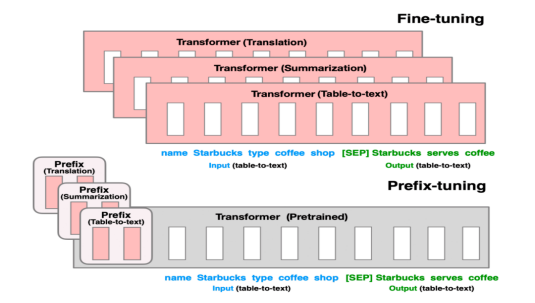
Prompt-Tuning(软提示/连续提示)
- 可看做是Prefix-Tuning的简化版本,只在输入层加入prompt tokens,并不需要加入MLP进行调整
- 提出 Prompt Ensembling 方法来集成预训练语言模型的多种 prompts
- 在只额外对增加的3.6%参数规模(相比原来预训练模型的参数量)的情况下取得和Full-finetuning接近的效果
- 作用阶段:第一层transformer block的Attention注意力计算
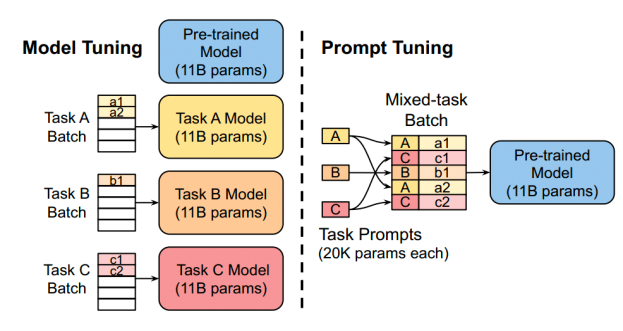
P-Tuning(软提示/连续提示)
- P-Tuning只是在输入的时候加入Embedding,并通过LSTM+MLP对prompt embedding序列进行编码
- 根据人工设计模板动态确定prompt token的添加位置,可以放在开始,也可以放在中间
- 作用阶段:第一层transformer block的Attention注意力计算
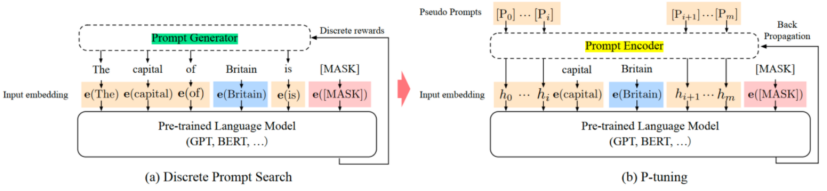
P-Tuning V2(软提示/连续提示)
- 可看做是Prefix-Tuning的优化版本。在模型的每一层都添加连续的 prompts
- P-Tuning v2在不同规模和任务中都可与微调效果相媲美
- 移除重参数化的编码器(如:Prefix Tuning中的MLP、P-Tuning中的LSTM)、针对不同任务采用不同的提示长度、引入多任务学习等
- 作用阶段:所有transformer block的Attention注意力计算
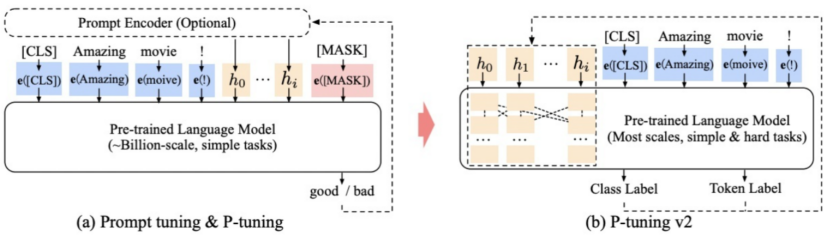
Adapter(变体:AdapterFusion、AdapterDrop)
- 在Transformer Block中加入两层MLP,固定住原来预训练模型的参数不变,只对新增的Adapter结构进行微调
- 在只额外对增加的3.6%参数规模(相比原来预训练模型的参数量)的情况下取得和Full-finetuning接近的效果
- 作用阶段:Transformer Block主体

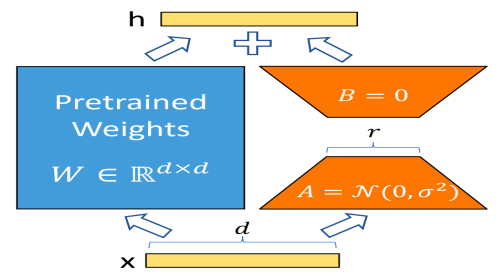
LoRA(变体:AdaLoRA、QLoRA)
- 在训练阶段,预训练参数W固定,只更新A和B参数,A和B模拟W的变化量。
- 在推理阶段,用A、B参数与原预训练参数相加替换原有预训练模型的参数。推理过程没有额外的参数量和计算量
- 相当于是用LoRA去模拟Full-finetune的过程,几乎不会带来效果损失
- 由于没有使用Prompt方式,避免了Prompt方法的一系列问题(Prompt的问题:难训练、序列长度受限、效果不如finetune),在推理阶段也没有引入额外的参数
- 作用阶段:Transformer Block主体query、value
BitFit
- 不需要对预训练模型做任何改动,只微调训练指定神经网络中的偏置Bias
- 参数量只有不到2%,但是效果可以接近全量参数
- 作用阶段:模型Backbone主体
PEFT方法总结
- 增加额外参数,如:Prefix Tuning、Prompt Tuning、Adapter Tuning及其变体
- 选取一部分参数更新,如:BitFit
- 引入重参数化,如:LoRA、AdaLoRA、QLoRA
- 混合高效微调,如:MAM Adapter、UniPELT
下面看一下hugging face peft开源代码中对于上述几种方法的实现。tuners目录下实现了PrefixTuning、PromptTuning、PTuning、Adapter、LoRA、AdaLoRA这些方法配置文件的构造、解析,新增训练参数模型的构造,各种PEFT方法配置文件类之间的继承关系,如下:
PeftConfig -> PromptLearningConfig -> (PrefixTuningConfig、PromptEncoderConfig、PromptTuningConfig)
PeftConfig -> LoraConfig -> AdaLoraConfig
PushToHubMixin -> PeftConfigMixin -> PeftConfig下面先看一下PrefixTuning、PromptTuning、PTuningV1模块的输入、输出情况:
Prefix-Tuning
from peft import PrefixEncoder, PrefixTuningConfig
import torch
config = PrefixTuningConfig(
peft_type="PREFIX_TUNING",
task_type="SEQ_2_SEQ_LM",
num_virtual_tokens=20,
token_dim=768,
num_transformer_submodules=1,
num_attention_heads=12,
num_layers=12,
encoder_hidden_size=768,
prefix_projection=False
)
print(config)
# 初始化PrefixEncoder
prefix_encoder = PrefixEncoder(config)
print(prefix_encoder)
"""
PrefixEncoder(
(embedding): Embedding(20, 18432)
)
# 2 * layers * hidden = 2 * 12 * 768 = 18432,在每一层transformer block的key和value的前面都加上virtual embedding
"""Prompt-Tuning
from peft import PromptTuningConfig, PromptEmbedding
import torch
word_embedding = torch.nn.Embedding(num_embeddings=100, embedding_dim=768)
config = PromptTuningConfig(
peft_type="PROMPT_TUNING",
task_type="SEQ_2_SEQ_LM",
num_virtual_tokens=20,
token_dim=768,
num_transformer_submodules=1,
num_attention_heads=12,
num_layers=12,
# encoder_hidden_size=768
)
print(config)
# 初始化PromptEncoder
prompt_encoder = PromptEmbedding(config, word_embedding)
print(prompt_encoder)
"""
PromptEmbedding(
(embedding): Embedding(20, 768)
)
只在输入层的原始序列上面添加prompt embedding
"""PTuningV1
from peft import PromptEncoderConfig, PromptEncoder
import torch
config = PromptEncoderConfig(
peft_type="PREFIX_TUNING",
task_type="SEQ_2_SEQ_LM",
num_virtual_tokens=20,
token_dim=768,
num_transformer_submodules=1,
num_attention_heads=12,
num_layers=12,
encoder_hidden_size=768,
# prefix_projection=False
)
print(config)
# 初始化PrefixEncoder
p_encoder = PromptEncoder(config)
print(p_encoder)
"""
PromptEncoder(
(embedding): Embedding(20, 768)
(mlp_head): Sequential(
(0): Linear(in_features=768, out_features=768, bias=True)
(1): ReLU()
(2): Linear(in_features=768, out_features=768, bias=True)
(3): ReLU()
(4): Linear(in_features=768, out_features=768, bias=True)
)
)
只在输入层的原始序列上面添加prompt embedding
"""PTuningV2
from peft import PrefixEncoder, PrefixTuningConfig
import torch
config = PrefixTuningConfig(
peft_type="PREFIX_TUNING",
task_type="SEQ_2_SEQ_LM",
num_virtual_tokens=20,
token_dim=768,
num_transformer_submodules=1,
num_attention_heads=12,
num_layers=12,
encoder_hidden_size=768,
prefix_projection=True
)
print(config)
# 初始化PrefixEncoder
prefix_encoder = PrefixEncoder(config)
print(prefix_encoder)
"""
PrefixEncoder(
(embedding): Embedding(20, 768)
(transform): Sequential(
(0): Linear(in_features=768, out_features=768, bias=True)
(1): Tanh()
(2): Linear(in_features=768, out_features=18432, bias=True)
)
)
# 2 * layers * hidden = 2 * 12 * 768 = 18432,在每一层transformer block的key和value的前面都加上virtual embedding
"""PrefixTuning和PTuningV在实现上基本上是一样的,其实就是一样的。
下面以peft_model.py文件中PeftModelForSequenceClassification的forward函数实现为例,看一下在推理阶段如何对于PrefixTuning、PromptTuning、PTuningV1、PTuningV2、Adapter、LoRA进行操作。
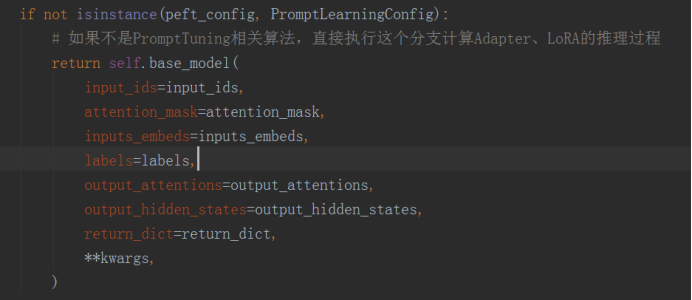
1、首先通过配置文件的所继承的父类类型来判断PEFT方法是否属于Prompt相关的,如果不是,就表示使用的是Adapter、LoRA等方法,直接执行推理。LoRA的具体推理计算过程后面再补充
2、如果通过配置文件的所继承的父类类型判断PEFT方法属于Prompt相关的,因为要在transformer block的序列开始位置添加虚拟token的embedding,所以也要补全attention mask
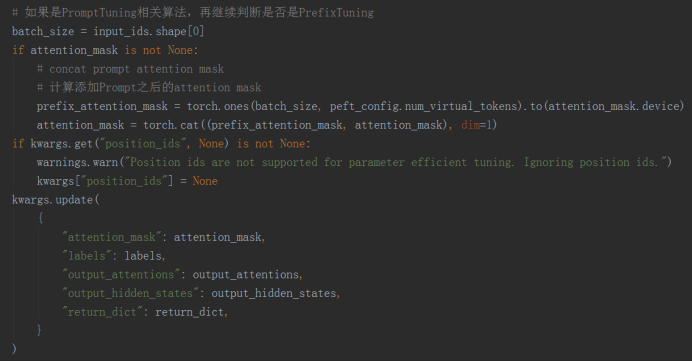
3、通过配置文件的类型来判断PEFT方法到底是PrefixTuning/PTuningV2,还是PromptTuning/PTuningV1。如果是PromptTuning/PTuningV1,则将虚拟token的embedding直接concat到原始输入序列的前面,送入base model模型进行推理。如果是PrefixTuning/PTuningV2,由于涉及到给每一个transformer block的key和value添加虚拟token的embedding,还需要使用_prefix_tuning_forward函数进行额外的处理。

PromptTuning/PTuningV1源码
PromptTuning和PTuningV1的共同点都是使用了浅层的Prompt,只在输入层使用。所以PromptTuning和PTuningV1在使用时的方式基本相同。
PromptTuning的源码详见src/peft/tuners/prompt_tuning.py,里面包含了相关的配置项以及Encoder的创建过程。
PTuningV1的源码详见src/peft/tuners/p_tuning.py,里面包含了相关的配置项以及Encoder的创建过程。
PromptTuning/PTuningV1的推理过程就是将虚拟token的embedding直接concat到原始输入序列的前面,并对attention mask进行扩充,送入base model模型进行推理。对应上面讲到的2和3。
PrefixTuning/PTuningV2源码
PrefixTuning和PTuningV2的共同点都是使用了深层的Prompt,在每层Transformer Block都使用,所以PrefixTuning和PTuningV2的实现放在一起。
上面说到当执行的PEFT类型是PrefixTuning/PTuningV2时,由于要给每个Transformer Block的Key和Value前面都加上可以学习的virtual token embedding,需要使用_prefix_tuning_forward函数进行额外的处理。
在看_prefix_tuning_forward函数之前先了解一些相关知识。自然语言处理任务可以分为Auto-Encoding(也叫NLU、自然语言理解、Masked Language Model)和Auto-Regressive(也叫NLG、自然语言生成、Language Model)。对于Auto-Encoding类型的任务,在模型的训练和预测阶段,self-attention都可以并行计算。对于Auto-Regressive类型的任务,在模型训练阶段通过使用attention mask也能够进行并行计算,但是在模型预测阶段,由于是时序生成任务,只能一步一步的生成,没办法并行。我们来看一下在生成阶段每个时间步有哪些计算:
时间步t:
Query:来自前一个时间步t-1时刻的输出,使用query矩阵(就是一个全连接层)转换之后得到
Key:来自前t-1个时间步[1,……,t-1]的输出,使用key矩阵(就是一个全连接层)转换之后得到
Value:来自前t-1个时间步[1,……,t-1]的输出,使用value矩阵(就是一个全连接层)转换之后得到
时间步t + 1:
Query:来自前一个时间步t时刻的输出,使用query矩阵(就是一个全连接层)转换之后得到
Key:来自前t个时间步[1,……,t-1,t]的输出,使用key矩阵(就是一个全连接层)转换之后得到
Value:来自前t个时间步[1,……,t-1,t]的输出,使用value矩阵(就是一个全连接层)转换之后得到
可以看到,每个时间步的Query都和上一个时间步的输出相关,每一步都需要重新计算Query,但是key和value来自前t-1个时间步的输出相关,所以t+1时刻的key和value与t时刻的key和value在[1,……,t-1]时刻上的计算结果是相同的,也就是这些结果是可以复用的,在每个时刻可以复用前一时刻计算的key和value,然后追加上当前时刻新增的key和value,构成完整的key和value。
在hugging face实现的self-attention模块中,为了复用decode生成阶段的key和value,会传入一个past_key_values参数,如果past_key_values不是None,表示前面时间步已经有计算结果了,直接复用上一步的结果,然后将当前时间步的key和value拼接上去,更新后的past_key_values将继续传递到下一个时间步。
有了上面的背景知识,对于_prefix_tuning_forward函数中关于PrefixTuning/PTuningV2方法的实现就很好理解了,就是将生成的virtual token embedding通过past_key_values参数带入到transformer block的每一层,放在每一层key和value的前面。
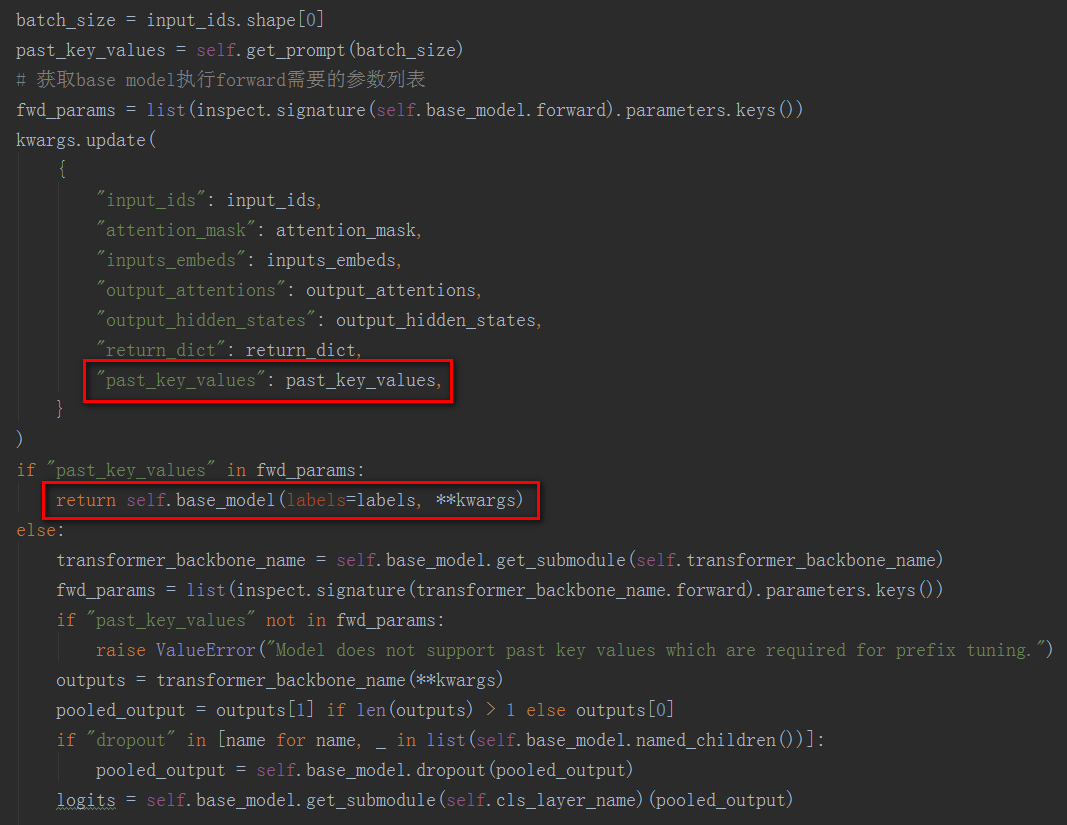
关于LoRA相关的源码部分后续补充。