大家好,我是安果!
周末是与亲朋好友相聚的好时机,可以选择一部大家都喜欢的电影,彻底放松,共同度过一个愉快而难忘的周末
本篇文章将介绍如何使用 Scrapy 爬取最新上映的电影
目标对象:
aHR0cHM6Ly93d3cubWFveWFuLmNvbS8=
1、创建爬虫项目
# 创建一个爬虫项目
scrapy startproject film
cd film
# 创建一个爬虫
scrapy genspider maoyan_film https://www.*.com/2、创建数据表及定义 Item
在数据库中创建一张表用于保存爬取下来的数据
以 Mysql 为例
create table xag.film
(
id int auto_increment
primary key,
film_name varchar(100) null,
show_time varchar(100) null,
file_type varchar(100) null,
actors varchar(100) null,
url varchar(100) null,
insert_time date null
);然后,定义 Item 存储数据对象
# items.py
import scrapy
class FilmItem(scrapy.Item):
film_name = scrapy.Field() # 电影名称
show_time = scrapy.Field() # 上映时间
file_type = scrapy.Field() # 电影类型
actors = scrapy.Field() # 电影演员
url = scrapy.Field() # 电影URL
insert_time = scrapy.Field() # 插入时间(年、月、日)3、编写爬虫解析主页面
这里以 Selenium 为例,首先创建一个浏览器对象
PS:为了在服务器上运行,这里对 CentOS 做了兼容处理
import scrapy
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.chrome.service import Service
import platform
...
def parse(self, response):
chrome_options = Options()
if platform.system().lower() == 'windows':
# win
s = Service(r"C:\work\chromedriver.exe")
self.browser = webdriver.Chrome(service=s, options=chrome_options)
else:
# Centos
DRIVER_PATH = '/home/drivers/chromedriver'
s = Service(DRIVER_PATH)
chrome_options.add_argument('--no-sandbox')
chrome_options.add_argument('--headless') # 无头参数
chrome_options.add_argument('--disable-gpu')
self.browser = webdriver.Chrome(service=s, options=chrome_options)
self.browser.implicitly_wait(5)
...然后,分析网页结构,使用 Xpath 解析最近上映的电影数据
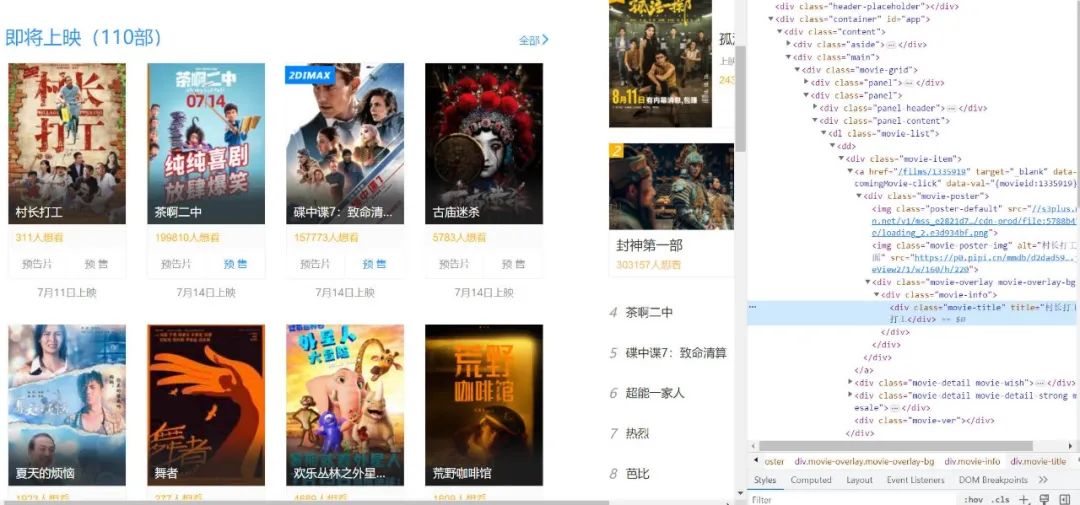
这里提取出电影的名称及上映时间(包含电影详情页面 URL)
...
url = response.url
# selenium打开网页
self.browser.get(url)
self.browser.maximize_window()
WebDriverWait(self.browser, 20).until(
EC.presence_of_element_located((By.XPATH, '//div[@class="movie-grid"]/div[2]//dl'))
)
time.sleep(10)
video_elements = self.browser.find_elements(By.XPATH, '//div[@class="movie-grid"]/div[2]//dl/dd')
for video_element in video_elements:
# 电影名称
film_name = video_element.find_element(By.XPATH, './/div[contains(@class,"movie-title")]').text
# 上映时间
show_time = video_element.find_element(By.XPATH, './/div[contains(@class,"movie-rt")]').text.replace(
"上映",
"")
# 详情页面URL
file_detail_a_element = video_element.find_element(By.XPATH, './/div[@class="movie-item"]/a')
file_detail_url = file_detail_a_element.get_attribute("href")
print('film_name:', film_name, ',show_time:', show_time, ",url:", file_detail_url)
yield Request(file_detail_url, callback=self.parse_detail, headers=self.headers,
meta={"film_name": film_name, "show_time": show_time}, dont_filter=True)
...4、电影详情页面解析
通过上面的步骤,我们可以拿到某一部电影的详情页面 URL
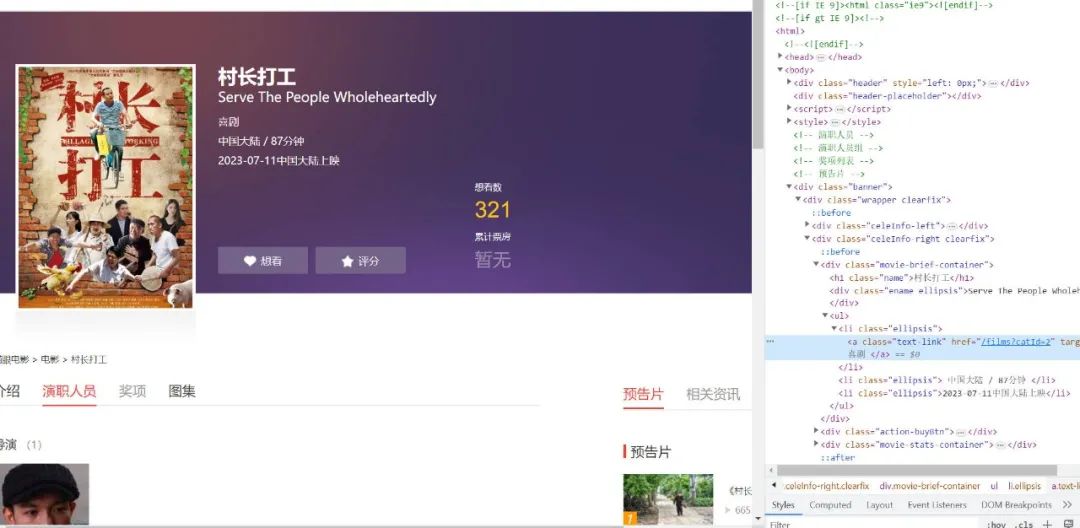
需要注意的是,如果使用 Selenium 直接打开该页面会触发反爬,这里我们需要修改浏览器特征值
...
def parse_detail(self, response):
"""
解析子页面
:param response:
:return:
"""
# 应对反爬
self.browser.execute_cdp_cmd("Page.addScriptToEvaluateOnNewDocument", {
"source": """
Object.defineProperty(navigator, 'webdriver', {
get: () => undefined
})
"""
})
...接着,打开目标页面,爬取电影的类型及演员列表
最后,将数据将存储到 Item 中
...
self.browser.get(response.url)
self.browser.maximize_window()
# 等待加载完成
WebDriverWait(self.browser, 20).until(
EC.presence_of_element_located((By.XPATH, '//div[@class="movie-brief-container"]//a[@class="text-link"]'))
)
# 获取电影类型
film_type_elements = self.browser.find_elements(By.XPATH,
'//div[@class="movie-brief-container"]//a[@class="text-link"]')
file_type = ''
for index, film_type_element in enumerate(film_type_elements):
if len(film_type_elements) >= 2:
if index != len(film_type_elements) - 1:
file_type += film_type_element.text + "|"
else:
file_type += film_type_element.text
else:
file_type += film_type_element.text
# 演员
celebritys = self.browser.find_elements(By.XPATH,
'//div[@class="celebrity-group"][2]//div[@class="info"]//a[@class="name"]')[
:3]
actors = ''
for index, celebrity in enumerate(celebritys):
if len(celebritys) >= 2:
if index != len(celebritys) - 1:
actors += celebrity.text + "|"
else:
actors += celebrity.text
else:
actors += celebrity.text
item = FilmItem()
item['film_name'] = response.meta.get("film_name", "")
item['show_time'] = response.meta.get("show_time", "")
item["file_type"] = file_type
item["actors"] = actors
item['url'] = response.url
item['insert_time'] = date.today().strftime("%Y-%m-%d")
yield item
...5、编写数据库管道,将上面的数据存储到数据库表中
from scrapy.exporters import CsvItemExporter
from film.items import FilmItem
import MySQLdb
class MysqlPipeline(object):
def __init__(self):
# 链接mysql数据库
self.conn = MySQLdb.connect("host", "root", "pwd", "xag", charset="utf8", use_unicode=True)
self.cursor = self.conn.cursor()
# 数据同步插入到mysql数据库
def process_item(self, item, spider):
table_name = ''
if isinstance(item, FilmItem):
table_name = 'film'
# sql语句
insert_sql = """
insert into {}(film_name,show_time,file_type,actors,url,insert_time) values(%s,%s,%s,%s,%s,%s)
""".format(table_name)
params = list()
params.append(item.get("film_name", ""))
params.append(item.get("show_time", ""))
params.append(item.get("file_type", ""))
params.append(item.get("actors", ""))
params.append(item.get("url", ""))
params.append(item.get("insert_time", ""))
# 执行插入数据到数据库操作
self.cursor.execute(insert_sql, tuple(params))
# 提交,保存到数据库
self.conn.commit()
return item
def close_spider(self, spider):
"""释放数据库资源"""
self.cursor.close()
self.conn.close()6、配置爬虫项目 settings.py
在 settings.py 文件中,对下载延迟、默认请求头、下载管道 Pipline等进行配置
# settings.py
# Obey robots.txt rules
ROBOTSTXT_OBEY = False
DOWNLOAD_DELAY = 3
DEFAULT_REQUEST_HEADERS = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7',
'Accept-Language': 'en',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 Safari/537.36',
'Host':'www.host.com'
}
ITEM_PIPELINES = {
'film.pipelines.MysqlPipeline': 300,
}7、运行入口
在项目根目录下创建一个文件,用于定义爬虫的运行入口
from scrapy.cmdline import execute
import sys, os
def start_scrapy():
sys.path.append(os.path.dirname(__file__))
# 运行单个爬虫
execute(["scrapy", "crawl", "maoyan_film"])
if __name__ == '__main__':
start_scrapy()最后,我们将爬虫部署到服务器,设置定时任务及消息通知
这样我们可以及时获取最近上映的电影,通过电影类型及演员阵容,挑选自己喜欢的电影
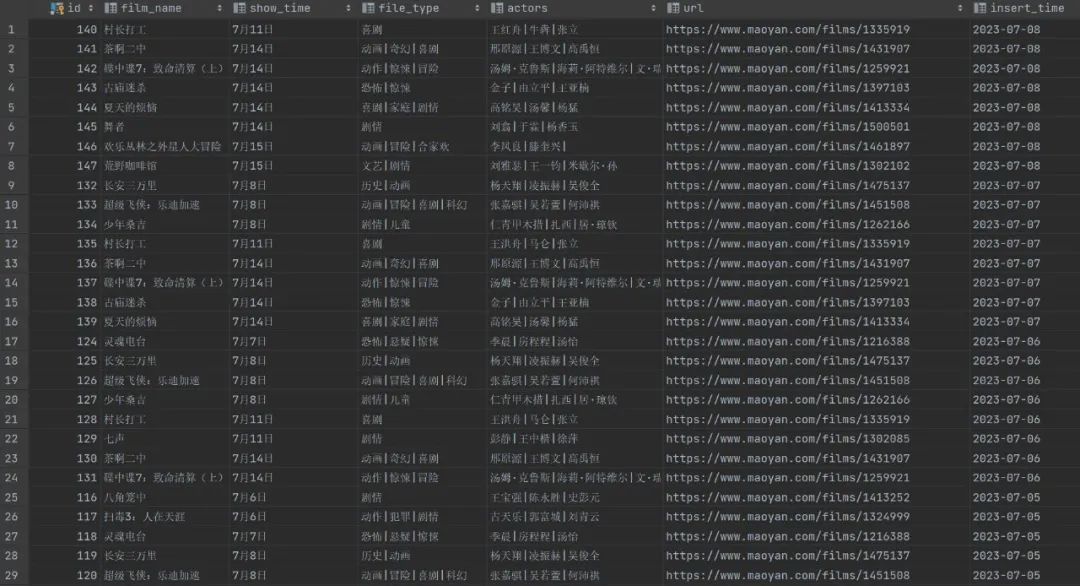
文中所有的源码我已经上传到公众号后台,回复关键字 230708 获取完整源码
如果大家有任何疑惑,欢迎在评论区留言!
推荐阅读
如何利用 Selenium 对已打开的浏览器进行爬虫!
如何利用 Playwright 对已打开的浏览器进行爬虫!
最全总结 | 聊聊 Selenium 隐藏浏览器指纹特征的几种方式!
END
好文和朋友一起看~




![[NISACTF 2022]checkin](https://img-blog.csdnimg.cn/img_convert/1892ac0aa5205deedf990641435e0d98.png)