目录
- 1 性能优化的思路
- 2 引言
- 3 MySQL慢查询日志
- 3.1 慢查询参数
- 3.2 开启慢查询日志(临时)
- 3.3 开启慢查询日志(永久)
- 3.4 慢查询测试
- 4 MySQL性能分析 EXPLAIN
- 4.1 概述
- 4.2 EXPLAIN字段介绍
- 4.2.1 id字段
- 4.2.2 select_type 与 table字段
- 4.2.3 type字段
- 4.2.4 possible_keys 与 key字段
- 4.2.5 key_len字段
- 4.2.6 ref 字段
- 4.2.7 rows 字段
- 4.2.8 filtered 字段
- 4.2.9 extra 字段
1 性能优化的思路

-
- 首先需要使用慢查询功能,去获取所有查询时间比较长的SQL语句
-
- 其次使用explain命令去查询由问题的SQL的执行计划
-
- 最后可以使用show profile[s] 查看由问题的SQL的性能使用情况
-
- 优化SQL语句
2 引言
数据库查询快慢是影响项目性能的一大因素,对于数据库,我们除了要优化SQL,更重要的是得先找到需要优化的SQL语句。
MySQL数据库有一个“慢查询日志”功能,用来记录查询时间超过某个设定值的SQL,这将极大程度帮助我们快速定位到问题所在,以便对症下药。
3 MySQL慢查询日志
慢查询日志用来记录在 MySQL 中执行时间超过指定时间的查询语句。通过慢查询日志,可以查找出哪些查询语句的执行效率低,以便进行优化。
3.1 慢查询参数
- 执行下面的语句
xxxxxxxxxx
SHOW VARIABLES LIKE "%slow_query%" ;
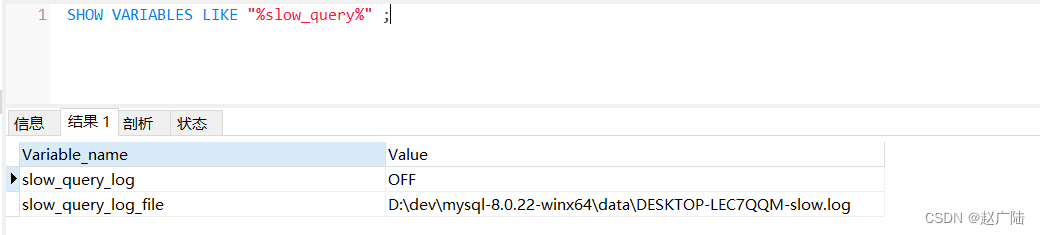
- slow_query_log:是否开启慢查询,on为开启,off为关闭;
- log-slow-queries:慢查询日志文件路径
xxxxxxxxxx
SHOW VARIABLES LIKE "%long_query_time%" ;
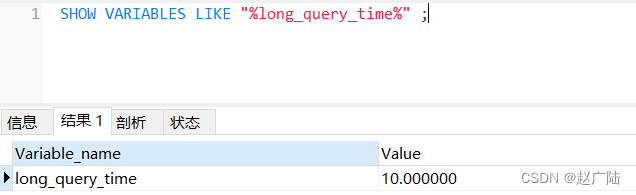
- long_query_time : 阈值,超过多少秒的查询就写入日志
xxxxxxxxxx
show variables like 'log_queries_not_using_indexes';
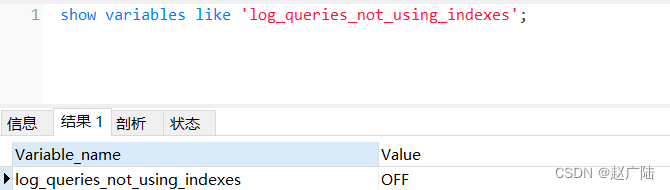
- 系统变量
log-queries-not-using-indexes:未使用索引的查询也被记录到慢查询日志中(可选项)。如果调优的话,建议开启这个选项。
3.2 开启慢查询日志(临时)
在MySQL执行SQL语句设置,但是如果重启MySQL的话会失效。
xxxxxxxxxx
set global slow_query_log=on;
set global long_query_time=1;
3.3 开启慢查询日志(永久)
修改:/etc/my.cnf,添加以下内容,然后重启MySQL服务
xxxxxxxxxx
[mysqld]
lower_case_table_names=1
slow_query_log=ON
slow_query_log_file=D:\dev\mysql-8.0.22-winx64\data\DESKTOP-LEC7QQM-slow.log
long_query_time=1
(数据库操作超过100毫秒认为是慢查询,可根据需要进行设定,如果过多,可逐步设定,比如先行设定为2秒,逐渐降低来确认瓶颈所在)
3.4 慢查询测试
xxxxxxxxxx
select SLEEP(3);

格式说明:
- 第一行,SQL查询执行的具体时间
- 第二行,执行SQL查询的连接信息,用户和连接IP
- 第三行,记录了一些我们比较有用的信息,
- Query_timme,这条SQL执行的时间,越长则越慢
- Lock_time,在MySQL服务器阶段(不是在存储引擎阶段)等待表锁时间
- Rows_sent,查询返回的行数
- Rows_examined,查询检查的行数,越长就越浪费时间
- 第四行,设置时间戳,没有实际意义,只是和第一行对应执行时间。
- 第五行,执行的SQL语句记录信息
4 MySQL性能分析 EXPLAIN
4.1 概述
explain(执行计划),使用explain关键字可以模拟优化器执行sql查询语句,从而知道MySQL是如何处理sql语句。
explain主要用于分析查询语句或表结构的性能瓶颈。
通过explain命令可以得到:
- – 表的读取顺序
- – 数据读取操作的操作类型
- – 哪些索引可以使用
- – 哪些索引被实际使用
- – 表之间的引用
- – 每张表有多少行被优化器查询
4.2 EXPLAIN字段介绍
explain使用:explain+sql语句,通过执行explain可以获得sql语句执行的相关信息。
xxxxxxxxxx
explain select * from course;

expain出来的信息有10列,分别是id、select_type、table、type、possible_keys、key、key_len、ref、rows、Extra
数据准备
xxxxxxxxxx
-- 创建数据库
CREATE DATABASE test_explain CHARACTER SET 'utf8';
-- 创建表
CREATE TABLE L1(id INT PRIMARY KEY AUTO_INCREMENT,title VARCHAR(100) );
CREATE TABLE L2(id INT PRIMARY KEY AUTO_INCREMENT,title VARCHAR(100) );
CREATE TABLE L3(id INT PRIMARY KEY AUTO_INCREMENT,title VARCHAR(100) );
CREATE TABLE L4(id INT PRIMARY KEY AUTO_INCREMENT,title VARCHAR(100) );
-- 每张表插入3条数据
INSERT INTO L1(title) VALUES('heima001'),('heima002'),('heima003');
INSERT INTO L2(title) VALUES('heima004'),('heima005'),('heima006');
INSERT INTO L3(title) VALUES('heima007'),('heima008'),('heima009');
INSERT INTO L4(title) VALUES('heima010'),('heima011'),('heima012');
4.2.1 id字段
select查询的序列号,包含一组数字,表示查询中执行select子句或操作表的顺序
- id相同,执行顺序由上至下
xxxxxxxxxx
EXPLAIN SELECT * FROM L1,L2,L3 WHERE L1.id=L2.id AND L2.id = L3.id;

- id不同,如果是子查询,id的序号会递增,id值越大优先级越高,越先被执行
xxxxxxxxxx
EXPLAIN SELECT * FROM L2 WHERE id = (
SELECT id FROM L1 WHERE id = (SELECT L3.id FROM L3 WHERE L3.title = 'heima03'));

4.2.2 select_type 与 table字段
查询类型,主要用于区别普通查询,联合查询,子查询等的复杂查询
simple: 简单的select查询,查询中不包含子查询或者UNION
xxxxxxxxxx
EXPLAIN SELECT * FROM L1;

-
primary: 查询中若包含任何复杂的子部分,最外层查询被标记xxxxxxxxxxEXPLAIN SELECT * FROM L2 WHERE id = (SELECT id FROM L1 WHERE id = (SELECT L3.id FROM L3 WHERE L3.title = 'heima03'));

-
subquery: 在select或where列表中包含了子查询xxxxxxxxxxEXPLAIN SELECT * FROM L2 WHERE L2.id = (SELECT id FROM L3 WHERE L3.title = 'heima03' )

-
derived: 在from列表中包含的子查询被标记为derived(衍生),MySQL会递归执行这些子查询, 把结果放到临时表中 -
union: 如果第二个select出现在UNION之后,则被标记为UNION,如果union包含在from子句的子查询中,外层select被标记为derived -
union result: UNION 的结果xxxxxxxxxxEXPLAIN SELECT * FROM L2UNIONSELECT * FROM L3

4.2.3 type字段
type显示的是连接类型,是较为重要的一个指标。下面给出各种连接类型,按照从最佳类型到最坏类型进行排序:
xxxxxxxxxx
system > const > eq_ref > ref > fulltext > ref_or_null > index_merge > unique_subquery > index_subquery > range > index > ALL
-- 简化
system > const > eq_ref > ref > range > index > ALL
-
system : 表仅有一行 (等于系统表)。这是const连接类型的一个特例,很少出现。
-
const : 表示通过索引 一次就找到了, const用于比较 primary key 或者 unique 索引. 因为只匹配一行数据,所以如果将主键 放在 where条件中, MySQL就能将该查询转换为一个常量
xxxxxxxxxxEXPLAIN SELECT * FROM L1 WHERE L1.id = 1

-
eq_ref : 唯一性索引扫描,对于每个索引键,表中只有一条记录与之匹配. 常见与主键或唯一索引扫描
xxxxxxxxxxEXPLAIN SELECT * FROM L1 ,L2 WHERE L1.id = L2.id ;

-
ref : 非唯一性索引扫描, 返回匹配某个单独值的所有行, 本质上也是一种索引访问, 它返回所有匹配某个单独值的行, 这是比较常见连接类型.
未加索引之前
xxxxxxxxxxEXPLAIN SELECT * FROM L1 ,L2 WHERE L1.title = L2.title ;

加索引之后
xxxxxxxxxx
CREATE INDEX idx_title ON L2(title);
EXPLAIN SELECT * FROM L1 ,L2 WHERE L1.title = L2.title ;

-
range : 只检索给定范围的行,使用一个索引来选择行。
xxxxxxxxxxEXPLAIN SELECT * FROM L1 WHERE L1.id > 10;EXPLAIN SELECT * FROM L1 WHERE L1.id IN (1,2);

key显示使用了哪个索引. where 子句后面 使用 between 、< 、> 、in 等查询, 这种范围查询要比全表扫描好
-
index : 出现index 是 SQL 使用了索引, 但是没有通过索引进行过滤,一般是使用了索引进行排序分组
xxxxxxxxxxEXPLAIN SELECT * FROM L1 ORDER BY id;

-
ALL : 对于每个来自于先前的表的行组合,进行完整的表扫描。
xxxxxxxxxxEXPLAIN SELECT * FROM L1;

一般来说,需要保证查询至少达到 range级别,最好能到ref
4.2.4 possible_keys 与 key字段
- possible_keys
- 显示可能应用到这张表上的索引, 一个或者多个. 查询涉及到的字段上若存在索引, 则该索引将被列出, 但不一定被查询实际使用.
- key
- 实际使用的索引,若为null,则没有使用到索引。(两种可能,1.没建立索引, 2.建立索引,但索引失效)。查询中若使用了覆盖索引,则该索引仅出现在key列表中。
- 覆盖索引:一个索引包含(或覆盖)所有需要查询的字段的值,通过查询索引就可以获取到字段值
- 理论上没有使用索引,但实际上使用了
xxxxxxxxxx
EXPLAIN SELECT L1.id FROM L1;

- 理论和实际上都没有使用索引
xxxxxxxxxx
EXPLAIN SELECT * FROM L1 WHERE title = 'heima01';

- 理论和实际上都使用了索引
xxxxxxxxxx
EXPLAIN SELECT * FROM L2 WHERE title = 'heima02';

4.2.5 key_len字段
表示索引中使用的字节数, 可以通过该列计算查询中使用索引的长度.
key_len 字段能够帮你检查是否充分利用了索引 ken_len 越长, 说明索引使用的越充分
-
创建表
xxxxxxxxxxCREATE TABLE L5(a INT PRIMARY KEY,b INT NOT NULL,c INT DEFAULT NULL,d CHAR(10) NOT NULL); -
使用explain 进行测试
xxxxxxxxxxEXPLAIN SELECT * FROM L5 WHERE a > 1 AND b = 1;索引中只包含了1列,所以,key_len是4。

-
为b字段添加索引
xxxxxxxxxxALTER TABLE L5 ADD INDEX idx_b(b);-- 执行SQL,这次将b字段也作为条件EXPLAIN SELECT * FROM L5 WHERE a > 1 AND b = 1;再次测试
-
为c、d字段添加联合索引,然后进行测试
xxxxxxxxxxALTER TABLE L5 ADD INDEX idx_c_b(c,d);explain select * from L5 where c = 1 and d = '';

c字段是int类型 4个字节, d字段是 char(10)代表的是10个字符相当30个字节
数据库的字符集是utf8 一个字符3个字节,d字段是 char(10)代表的是10个字符相当30个字节,多出的一个字节用来表示是联合索引
下面这个例子中,虽然使用了联合索引,但是可以根据ken_len的长度推测出该联合索引只使用了一部分,没有充分利用索引,还有优化空间.
xxxxxxxxxx
explain select * from L5 where c = 1 ;

4.2.6 ref 字段
-
显示索引的哪一列被使用了,如果可能的话,是一个常数。哪些列或常量被用于查找索引列上的值
- L1.id=‘1’; 1是常量 , ref = const
xxxxxxxxxxEXPLAIN SELECT * FROM L1 WHERE L1.id='1';

- L2表被关联查询的时候,使用了主键索引, 而值使用的是驱动表(执行计划中靠前的表是驱动表)L1表的ID, 所以 ref = test_explain.L1.id
xxxxxxxxxx
EXPLAIN SELECT * FROM L1 LEFT JOIN L2 ON L1.id = L2.id WHERE L1.title = 'heima01';

4.2.7 rows 字段
- 表示MySQL根据表统计信息及索引选用情况,估算的找到所需的记录所需要读取的行数;越少越好
- 使用like 查询,会产生全表扫描, L2中有3条记录,就需要读取3条记录进行查找
xxxxxxxxxx
EXPLAIN SELECT * FROM L1,L2 WHERE L1.id = L2.id AND L2.title LIKE '%hei%';

- 如果使用等值查询, 则可以直接找到要查询的记录,返回即可,所以只需要读取一条
xxxxxxxxxx
EXPLAIN SELECT * FROM L1,L2 WHERE L1.id = L2.id AND L2.title = 'heima03';

总结: 当我们需要优化一个SQL语句的时候,我们需要知道该SQL的执行计划,比如是全表扫描,还是索引扫描; 使用explain关键字可以模拟优化器执行sql语句,从而知道mysql是如何处理sql语句的,方便我们开发人员有针对性的对SQL进行优化.
- 表的读取顺序。(对应id)
- 数据读取操作的操作类型。(对应select_type)
- 哪些索引可以使用。(对应possible_keys)
- 哪些索引被实际使用。(对应key)
- 每张表有多少行被优化器查询。(对应rows)
- 评估sql的质量与效率 (对应type)
4.2.8 filtered 字段
- 它指返回结果的行占需要读到的行(rows列的值)的百分比
4.2.9 extra 字段
Extra 是 EXPLAIN 输出中另外一个很重要的列,该列显示MySQL在查询过程中的一些详细信息
-
准备数据
xxxxxxxxxxCREATE TABLE users (uid INT PRIMARY KEY AUTO_INCREMENT,uname VARCHAR(20),age INT(11));INSERT INTO users VALUES(NULL, 'lisa',10);INSERT INTO users VALUES(NULL, 'lisa',10);INSERT INTO users VALUES(NULL, 'rose',11);INSERT INTO users VALUES(NULL, 'jack', 12);INSERT INTO users VALUES(NULL, 'sam', 13); -
Using filesort
xxxxxxxxxxEXPLAIN SELECT * FROM users ORDER BY age;

执行结果Extra为Using filesort,这说明,得到所需结果集,需要对所有记录进行文件排序。这类SQL语句性能极差,需要进行优化。
典型的,在一个没有建立索引的列上进行了order by,就会触发filesort,常见的优化方案是,在order by的列上添加索引,避免每次查询都全量排序。
filtered 它指返回结果的行占需要读到的行(rows列的值)的百分比
-
Using temporary
xxxxxxxxxxEXPLAIN SELECT COUNT(*),uname FROM users WHERE uid > 2 GROUP BY uname;

执行结果Extra为Using temporary,这说明需要建立临时表 (temporary table) 来暂存中间结果。 常见与 group by 和 order by,这类SQL语句性能较低,往往也需要进行优化。
-
Using where
意味着全表扫描或者在查找使用索引的情况下,但是还有查询条件不在索引字段当中.
xxxxxxxxxxEXPLAIN SELECT * FROM users WHERE age=10;

此语句的执行结果Extra为Using where,表示使用了where条件过滤数据
需要注意的是:
- 返回所有记录的SQL,不使用where条件过滤数据,大概率不符合预期,对于这类SQL往往需要进行优化;
- 使用了where条件的SQL,并不代表不需要优化,往往需要配合explain结果中的type(连接类型)来综合判断。例如本例查询的 age 未设置索引,所以返回的type为ALL,仍有优化空间,可以建立索引优化查询。
-
Using index
表示直接访问索引就能够获取到所需要的数据(覆盖索引) , 不需要通过索引回表.
xxxxxxxxxx-- 为uname创建索引alter table users add index idx_uname(uname);EXPLAIN SELECT uid,uname FROM users WHERE uname='lisa';

此句执行结果为Extra为Using index,说明sql所需要返回的所有列数据均在一棵索引树上,而无需访问实际的行记录。
-
Using join buffer
使用了连接缓存, 会显示join连接查询时,MySQL选择的查询算法 .
xxxxxxxxxxEXPLAIN SELECT * FROM users u1 LEFT JOIN (SELECT * FROM users WHERE sex = '0') u2 ON u1.uname = u2.uname;

执行结果Extra为Using join buffer (Block Nested Loop) 说明,需要进行嵌套循环计算, 这里每个表都有五条记录,内外表查询的type都为ALL。
问题在于 两个关联表join 使用 uname,关联字段均未建立索引,就会出现这种情况。
常见的优化方案是,在关联字段上添加索引,避免每次嵌套循环计算。
-
Using index condition
查找使用了索引 (但是只使用了一部分,一般是指联合索引),但是需要回表查询数.
xxxxxxxxxxexplain select * from L5 where c > 10 and d = '';
Extra主要指标的含义(有时会同时出现)
using index:使用覆盖索引的时候就会出现using where:在查找使用索引的情况下,需要回表去查询所需的数据using index condition:查找使用了索引,但是需要回表查询数据using index & using where:查找使用了索引,但是需要的数据都在索引列中能找到,所以不需要回表查询数据




![NSS [NISACTF 2022]babyupload](https://img-blog.csdnimg.cn/img_convert/7716804d9e2703051ba84ea783def604.png)