作者: 有猫万事足 原文来源: https://tidb.net/blog/666ab16d
前言
稳定了tidb的集群,确定了写入热点问题的处理方式,搞好了监控,就要准备接入生产服的写入流量进入tidb集群了。这就轮到了dm工具的出场。这个过程十分繁琐也十分重要。所以这篇应该是4篇中最长的一篇。
上游的现状
上游的tps/qps很低,单台平均也就是50左右。
这是恶性循环的结果,mysql长期没人维护,所以读取性能不太行,读取不太行还要做事就只能尽量少用mysql读取,所以大量的读取其实是放在redis里面,只有不得不使用mysql的时候才读取一下。所以tps/qps也高不了。写入据我观察倒是没有什么太大的问题。
上游分表分库,算下来大致有70+个库,总计600多张表。有两种分片策略,根据uid分片以及根据时间分片。
把上游这些表做了合并看,下游需要建立300多张表。业务量不高,结构倒是巨复杂。
前期准备
部署dm集群的方式,只要你有前面部署tidb集群经验,部署这个dm集群不说是一样一样的,那也是差不太多。只说需要注意的点。
1,强烈建议在写topology文件建立dm集群时,就打开openapi
https://docs.pingcap.com/zh/tidb/stable/dm-open-api#%E4%BD%BF%E7%94%A8-openapi-%E8%BF%90%E7%BB%B4-tidb-data-migration-%E9%9B%86%E7%BE%A4
server_configs:
master:
openapi: true
把上述配置直接加入topology文件。
这个openapi提供一套http的接口,功能和tiup dmctl类似,但是有些细节不同,你要用之前要仔细测试对比一下,不能假定他们的行为是一致的。
考虑到最后dm的运维工作还是要和游戏服的生命周期对应的。开服合服的时候你要是每次都ssh到中控机上跑个脚本来关闭一些数据源,停掉一批数据源上的任务,等合服后再开启另一批是一个令人烦躁的过程。
有http接口可以调用管理起来就轻松多了。只要你开放对应端口给你想要调用这些接口的主机就可以了。不必一定要ssh到中控机上通过tiup dmctl做。我相信对于非游戏业务场景来说,这样也会方便很多。当然不要忘了端口上的安全防护,起码的访问范围还是要控制一下的。
https://docs.pingcap.com/zh/tidb/stable/dm-webui-guide#%E8%AE%BF%E9%97%AE%E6%96%B9%E5%BC%8F
同时,这个参数同时提供了一个图形化界面,如果你一开始对于书写source.yaml和task.yaml没有任何头绪的时候,这个图形化界面可以大大加速你熟悉这两个配置文件的过程。你可以通过点几下鼠标生成一个数据源和任务,然后反过来查看这个数据源和任务的yaml格式文件,快速的熟悉这两个文件的配置。
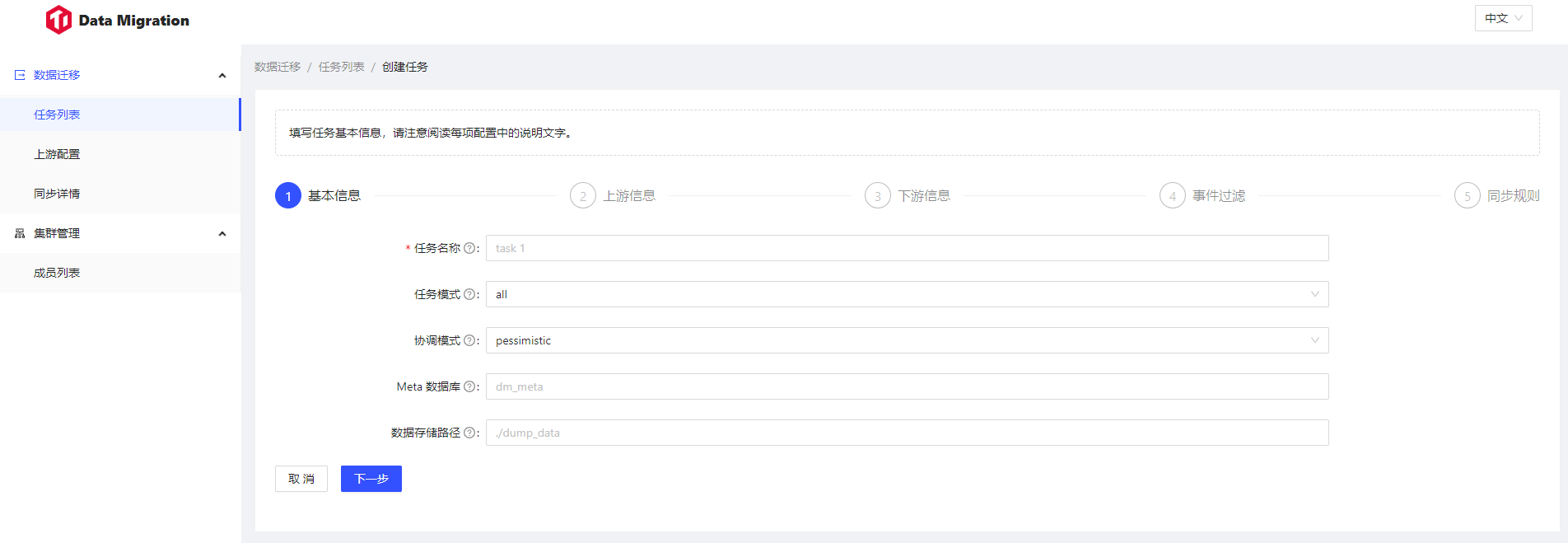
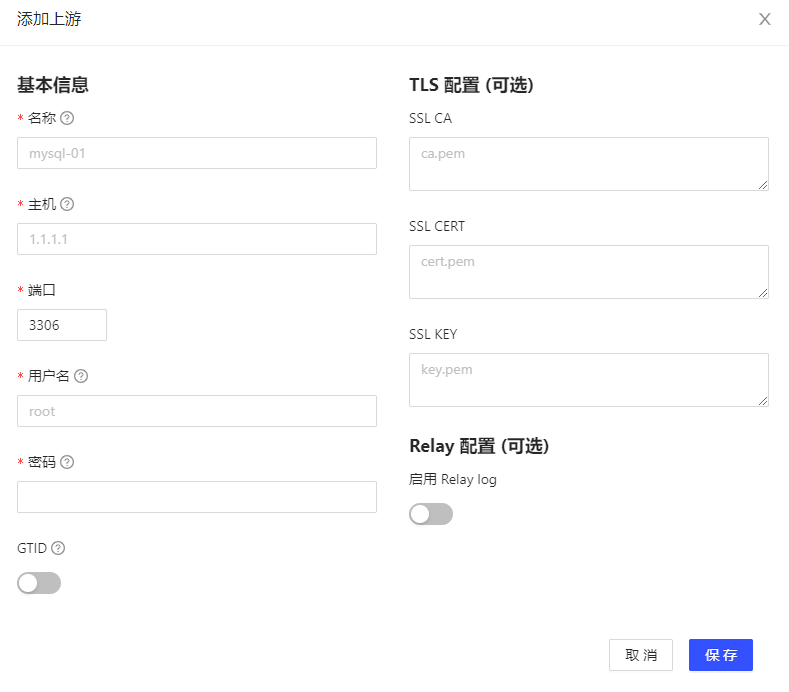
别担心文档里面的大红实验特性警告了,这个webui后期source/task一多打开的时间巨长,也就是前期练练手有用,一旦你熟悉了source.yaml和task.yaml的书写格式,就会迫不及待和这个webui说再见,奔向tiup dmctl的怀抱。
我推荐的熟悉dm管理工具模式是:小白webui->大白tiup dmctl->巨白openapi http调用。
2,tiup dmctl使用前要设置好环境变量DM_MASTER_ADDR
https://docs.pingcap.com/zh/tidb/stable/dmctl-introduction#dmctl-%E5%91%BD%E4%BB%A4%E6%A8%A1%E5%BC%8F
不然每次都敲一遍 dmctl --master-addr <dm-master-ip>:8261 ,对手碗极不友好。
3,另一个需要拿出来重点提一下的仍然是监控问题。
整个系统的写入流量是否稳定都是dm集群在做,dm集群的监控甚至比tidb集群的监控更加重要。
dm集群上的任务全挂,tidb集群是好的,对我们要做的事来说是没有任何意义的。所以按照上一篇最末尾类似的配置好dm集群监控只是最低的要求,最好是dm集群使用的告警模板能和tidb集群的告警模板有所区分——不管是标题还是其他什么醒目的标志,做到能一眼分辨来自哪个集群。
再想想上游那么多表,书写整理task.yaml是个艰巨的任务,就不花时间研究别的了,直接部署两套告警监控,以后再考虑如何合并监控告警到一套吧。
4,准备好版本控制工具
编写source.yaml和task.yaml有个反复修改调试的过程。除非你的上游系统的表结构很简单,数据量也不大。
否则数据分片的调整,那些表应该放在一个任务里面,这些都有一个反复调整的过程。
你需要一个版本控制工具来管理这种变化。相信我,前期就准备好,否则像我一样等意识到需要版本控制工具的时候,已经面临着另人头秃的返工问题了。
被否决的第一版方案
从一开始我只想解决bi的分析问题,根本没有考虑其他,而且既然tidb只要解决了写入热点,也不再担心分表分库的问题。那我何不将上游的表全部导入一张大表呢?这样对分析非常友好,只是这种导入上下游的表结构是异构的,下游会比上游多几个字段,但下游300多张表一次建好,以后有新服接入也不用再次建表了。有意思的是,dm工具还真的支持这个想法。 https://docs.pingcap.com/zh/tidb/stable/dm-table-routing#%E6%8F%90%E5%8F%96%E5%88%86%E5%BA%93%E5%88%86%E8%A1%A8%E6%95%B0%E6%8D%AE%E6%BA%90%E4%BF%A1%E6%81%AF%E5%86%99%E5%85%A5%E5%90%88%E8%A1%A8
注意在这个模式下
rule-2:
schema-pattern: "test_*"
target-schema: "test"
这个是必须的,并不是文档写的有问题,我一开始会觉得这个规则在语义上是多余的,结果怎么调都没有我想要的结果,才明白这是不可或缺的。当然test_*匹配的上有库里有多个表需要额外抽取3个字段,这个rule-2可以只写一次,即类似下面这样:
rule-1:
schema-pattern: "test_*"
table-pattern: "t_*"
target-schema: "test"
target-table: "t"
extract-table:
table-regexp: "t_(.*)"
target-column: "c_table"
extract-schema:
schema-regexp: "test_(.*)"
target-column: "c_schema"
extract-source:
source-regexp: "(.*)"
target-column: "c_source"
rule-11:
schema-pattern: "test_*"
table-pattern: "t1_*"
target-schema: "test"
target-table: "t1"
extract-table:
table-regexp: "t1_(.*)"
target-column: "c_table"
extract-schema:
schema-regexp: "test_(.*)"
target-column: "c_schema"
extract-source:
source-regexp: "(.*)"
target-column: "c_source"
rule-2:
schema-pattern: "test_*"
target-schema: "test"
上游test_**.t_* 对应下游test.t。上游test_* .t1_**对应下游test.t1,到了下游都会额外抽取3个字段,分别是表的后缀,库的后缀,和对应数据源的名字。因为是都在上游的test_*这个库里面的2个表,所以为了配置成功rule-2必须要有,但可以只写一次。
这个配置也碰到过麻烦,就是上有执行create table if not exists的时候,会变更下游的表结构。导致映射到下游的表结构少了3个字段。
https://asktug.com/t/topic/1005509?_gl=1*2g8n18*_ga*MTMzMTY5MTI3Mi4xNjgyNjkzNDU5*_ga_5FQSB5GH7F*MTY4ODQwMzY0MS4zNy4xLjE2ODg0MDM2NDMuMC4wLjA.
于是我在问答论坛咨询这个问题,不得不说强大社区是开源软件必不可少的一环。问答论坛定位问题的效率令我十分满意。也找到了对应的解决办法。 可就在这个时候老板也找到了我,说他考虑了一下如果tidb接入mysql写入流量没有问题,还是考虑以后使用tidb完全替换mysql。本来跟在别人create table if not exists后面去修改binlog-schema就是一个比较难受的做法。再加上老板的这个计划,我考虑了一下,选择上游一个mysql实例对应下游一个db,无论是现在对我来说,还是以后对研发接入习惯来说都会是个比较轻松的方案。那就从善入流吧。 大表对查询的友好是不用怀疑的。为了弥补上面的遗憾,后面这类日志表选择了视图来把他们逻辑上放在一起。 就像下面这样
CREATE OR REPLACE VIEW LogAll AS
(
select *,'s1' server_name from server_s1.Log union all
select *,'s2' server_name from server_s2.Log
)
下游的库名包含了上游的服务器名称。所以创建视图中间()内的内容可以从INFORMATION_SCHEMA.TABLES中的内容查询后自动生成。 在每次上游游戏服生命周期变化的时候,弄个脚本同步管理这个视图的刷新,用以添加新开的服进视图就可以了。老服合并后,上游可以把库备份了就把服务器退了,下游的业务分析还是离不开的,所以合服的时候我们用不着特别处理这个视图。
方法论
block-allow-list+routes 双白名单控制同步表的范围
总体来说,推荐使用block-allow-list+routes 双白名单控制同步表的范围。举例如下: 在block-allow-list设置do-tables,在routes里面对应设置这个表的路由。确保一一对应。
routes:
route-db1_t1: #规则名字还是要管理好的,虽然你提交到dm worker上再看就是route-1,route-2了。
schema-pattern: "db1"
table-pattern: "t1"
target-schema: s1 #下游库的名字和上游服务器的名字对应,这个前文说过
target-table: "t1"
...
block-allow-list:
balist-01:
do-dbs:
- "db1"
do-tables:
- db-name: "db1"
tbl-name: "t1"
确保不再计划内的建表/删表完全不同步,这类表不是上游在随手备份某个表,就是在做一些测试,完全没有必要跟着上游折腾。 而且一定要想着——写入热点。如果你照着上游mysql的建表方式同步,但凡数据量上去了就是写入热点。何必费这劲呢。 后续如果真的发现需要添加一些表的同步,那就单独做个任务把这个表同步过来就好了。 filter配置,ddl只有alter table可以放到下游,其他的ddl一概不要,dml全都要。 上游每个服的生命周期不同,我这里也做不到一个task对应多个上游mysql-instances。还是选择了一个task对应一个mysql-instances。 任务文件的命名也是{source_id}-{任务类型}。从taskname上就可以区分是在同步那个源上的那个类型的表。 在切写入流量到下游的时候,这种配置方式也适合一台一台的切上游的写入流量进下游。只要一个服调通了。批量替换一下source_id,和routes配置里面的target-schema就生成了另一个服的task文件。
任务类型的设置
对于我们公司的业务来说,上游的表可以笼统的区分为3类。对着3类表采取分而治之的方式。
第一类,配置数据/字典表
这种表的特点就是基本每次版本大小更新都有他们。更新的频率不好预测,一更新就是整表更新,因为这种数据在mysql中写一次就进了redis,以后的读取基本都是redis。所以一更新可能就是drop table/truncate table重新insert一遍。
所以这类表的特点就是:没有delete,每次都会insert一遍全量的数据,表的数据量很小,基本不超过10w。不用在意写入热点,也不会有分片。这类表直接照搬mysql的建表方式到下游是问题不大。表结构基本不需要什么额外的改造。
只需要注意一点,我在filter里面忽略了drop table/truncate table的事件,所以全量insert一遍这个表,肯定会有主键冲突。所以在这类表的task里面,需要在syncers的配置下面把safe-mode设置为true。
这样syncer在碰到上游binlog里面的insert into,就会把它改成replace into。
第二类,状态表
这种表的意思,就是某人有某个物品/道具。
有高频繁的根据主键的update。select的频率次之,insert,delete再次。还记的我在tidb架构篇里面提到的聚簇索引表吗?从任何角度看,这都是使用聚簇索引表最好的场景。当然我最后还是没有用聚簇索引表来消除这类表的写入热点,原因我在tidb架构篇也提过了。
这类表多数也有根据uid的分片,分在2个库的8个表里面。下游表结构的改造是必须的,一定要在原来的主键和唯一键索引上,添加uid字段。否则同步肯定是要出问题的。视情况数据量也大,写入热点的风险中等,对应的表结构改造也要留心。
当你把状态表放在一个task里面的时候还要注意:当task包括很多分片合并的表,tiup dmctl start-task/check-task的时候上游的mysql 连接数量可能会不够,需要你把上游的max_connections参数调大一些。
另外上游需要合并的表多了,如果start-task出错可能根本找不到错误提示在哪里,json返回的结果只有10条数据,这10条如果恰好都是警告,你是不知道提交任务失败的真正原因的。这时候就需要你改用
tiup dmctl check-task task.yaml -e 1000 -w 1000
总之就是把-e -w后面的数字调大,让他可以在json返回结果里面输出更多的提示,方便你找到错误的原因。
第三类,日志表
这类表的特点看就懂的,数据量大就是最大的特点。基本上只有insert/select,update/delete基本不会有。数据分片也多数按照时间分片。
如果说前面两类我会推荐你写一个task文件把他们放在一起处理,那么到了日志表,我只会建议你一个大表就写一个task文件。除非确实是小表再考虑和其他task放在一起。
在没有7.1版本的资源管控前,这类大表的导入最容易导致我这个台均4核8g乞丐版的集群不稳定——主要表现为tikv会轮流挂。
如果你把大表和其他表放在一个task里面,那些和他在一起的表放在一个任务里的表一直卡在load阶段也不是不可能的。所以为了不影响其他表的导入,应该把大表单独放入一个task文件。
同时注意调整loaders配置下的pool-size,默认是16,如果导入的时候不稳定可以调小一点。尽量等一个大表同步完了,再开下一个大表task。
当然以上注意事项,仅限7.1以前没有资源管控的版本,到了7.1,什么pool-size,什么启动task的个数,都不是问题,tikv挂一次算我输。
这类任务名,按照{source_id}-{table_name}命名。
relay log
因为我们已经把上游的表拆到了几个task文件里面,在这种情况下需要开启relay log。
https://docs.pingcap.com/zh/tidb/stable/relay-log#%E9%80%82%E7%94%A8%E5%9C%BA%E6%99%AF
当前系统对延迟并不敏感,差个3-5分钟都不是大事。而保证上游mysql运行平稳不对线上业务产生大的波动是老板非常关注的一点,不得不说老板很喜欢这个功能。
https://docs.pingcap.com/zh/tidb/stable/relay-log#%E8%87%AA%E5%8A%A8%E6%95%B0%E6%8D%AE%E6%B8%85%E7%90%86
开了就要管理好,所以自动数据清理也要配置好。
在实际的dm使用中,发现dm对上游的额外负载非常小,不管我执行那种类型/那个阶段(dump,load,sync)的同步任务,上游的mysql基本都不会有明显的波动。玩家在游戏服里面也是没有反馈任何卡之类的问题。这也是来自老板的认可。
设置好relay log以后,上游mysql binlog的保存周期就可以激进一些,压缩到1天甚至几个小时都可以,因为mysql保留binlog的时间,只要足够dm-worker把binlog从mysql服务器上拉走,在dm-worker上重新写入relay log就可以了。之后同步任务都是在读取relay log而不是上游mysql服务器的binlog。
美国的业务
我们公司的游戏是有外服的,同样是在腾讯云的美国机房。这次也要想办法把这部分数据也同步进国内的tidb集群。
这就衍生出一个很有意思的问题,dm集群应该贴近上游还是贴近下游?
从我个人的实践的情况来看,我的回答是上游。
跨国连接,看上去使用的是tcp,但实际可能是udp。所以这个连接的长期稳定是没有办法保证的。
当dm集群部署在中国,提交task文件建立任务的时间非常长,几乎不可用。而且会导致你用tiup dmctl query-status查询国内的任务也变的很慢。
所以我又在美国区部署了一套dm集群,提交任务是顺利的。同步状态是磕磕绊绊的。
当任务进入Sync状态,观察到延迟偶尔也会变的很高,但基本能保持在300s以内。这个延迟对跨国同步数据来说是完全可以接受的。
dm集群只要贴近上游,即便对下游tidb连接不稳定,也能正常工作。但因为我们的业务可能对数据一致性是不太敏感的,至今未发现上下游有数据不一致的情况。如果你的业务对数据一致性有更高的要求,还是需要仔细的测试,或找个稳定的链路。
成本
至此,整个dm导入任务已经理顺。一台台的把写入流量切过来是比较容易的事,后续管理开服合服这些生命周期的问题,还需要通过http openapi做一些脚本,自动执行起来也不难管理。
如果你的上游mysql也是这样同构的,建议还是一台一台来切写入流量进tidb,不容易出问题。
第一个dm-worker可以给好一点的资源观察一下,我上游的业务量很小,所以在4核8g的机器上观察了一下,cpu和内存的占用都不高。后面就干脆用2核2g的配置放2个dm-worker节点,存储有relay log,还是两份,还有导出时候的dump也要保存在dm-worker节点上,算了下每个dm-worker有50g空间也差不多了。
这种2核2g100g存储的配置一个70左右,有6-7个差不多了,算上外服,大致也就9-10个。总成本在2000块每月的tidb集群的基础上,再增加700。
后面的配置不会再额外增加成本,这每月3000块不到的成本就是我做这项改造最后的总花费。






![[CISCN 2019华北Day2]Web1](https://img-blog.csdnimg.cn/img_convert/5ba071370b5615b9978b5d493815b169.png)