1.引用的细节
引用,简单来说就是“取别名”。既然是别名,那么引用就一定具有以下的特点
-
引用在定义时必须初始化。
就好比起别名起码得告诉别人是给谁起的别名吧
-
一个变量可以有多个引用
就好比一个人可以有多个别名。比如张某某,有两个外号,一个是张三,另一个是张老三
-
引用一旦引用一个实体,就不能引用其他实体
假如b是a的别名,b就不能再是c的别名了,要不然就搞不清b到底是谁了
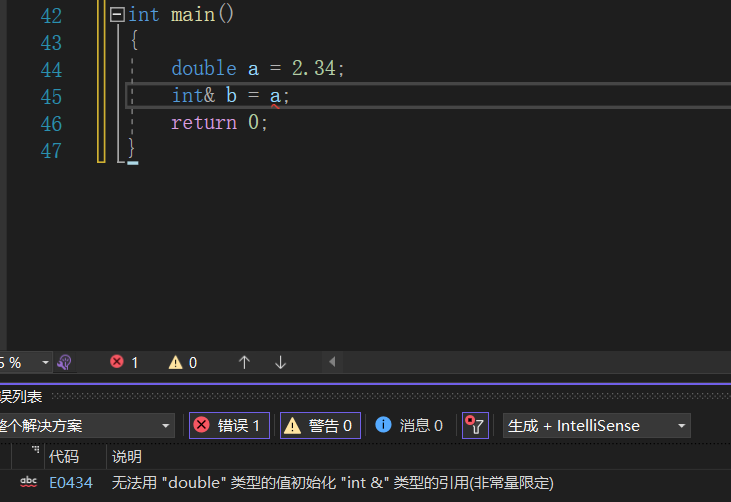
今天看到这样一段有意思的代码
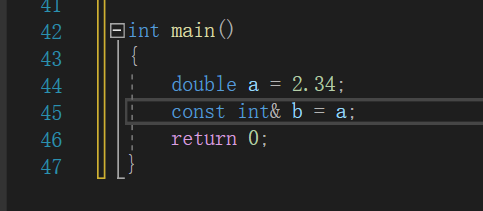
而我在引用前面加上const就不会报错了
这是为什么呢?
-
首先,a是一个double类型的变量,给int类型的变量赋值的时候会发生隐式类型转换,此时,会产生一个int类型的临时变量,也就是相当于
double a = 2.34; int tmp = a; const int& b = tmp;这个临时变量具有常性,所以必须const引用才能接收这个临时变量,不带const相当于权限的放大,这显然是不合理的。
此时,你会不会有这样的疑惑呢?
double a = 2.34;
int b = a;//这里也会发生隐式类型转换,产生临时变量,而临时变量具有常性,这个int类型的b又如何接收这个具有常性的临时变量呢?
我们要知道,我们在引用的时候有没有在内存中开辟空间呢?并没有,我们只是在起别名,这个别名与被其别名的量的地址相同。如果被起别名的量本身具有常性,那么这个别名就也必须具有常性。而int b = a;这句代码,是在内存中开辟了四个字节的空间,然后将临时变量的值拷贝一份过来,我只是对你的值的拷贝,有必要一定和你同样具有常性吗,显然没有。
2.内联函数
以关键字inline修饰的函数叫做内联函数,编译时C++编译器会在调用内联函数的地方展开,没有函数压栈的开销,
内联函数提升程序运行的效率。
当一个函数比较短小,并且经常被调用的时候,我们就可以考虑把该函数定义为内联函数。
下面我们以vs2022为例,看一看是否使用内联函数的区别
-
不使用内联函数时
int Add(int x, int y) { return x + y; } int main() { int ret = Add(1, 2); printf("%d\n", ret); return 0; }我们转到反汇编会发现call Add函数,意味着有函数栈帧的开销

-
使用内联函数时
inline int Add(int x, int y) { return x + y; } int main() { int ret = Add(1, 2); printf("%d\n", ret); return 0; }如果我们直接转到反汇编去看,会发现还是call Add,并没有在调用处直接展开,我们需要先对vs2022做一下属性修改,然后才能看到内联函数的作用

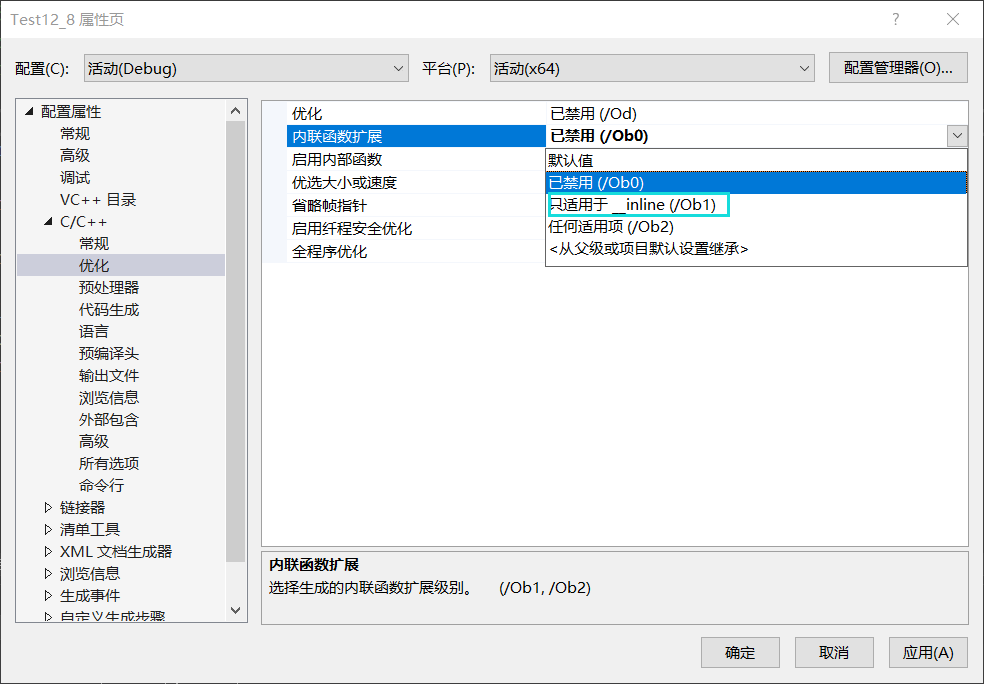
改完之后,我们再进入到反汇编看发现没有了栈帧的开销
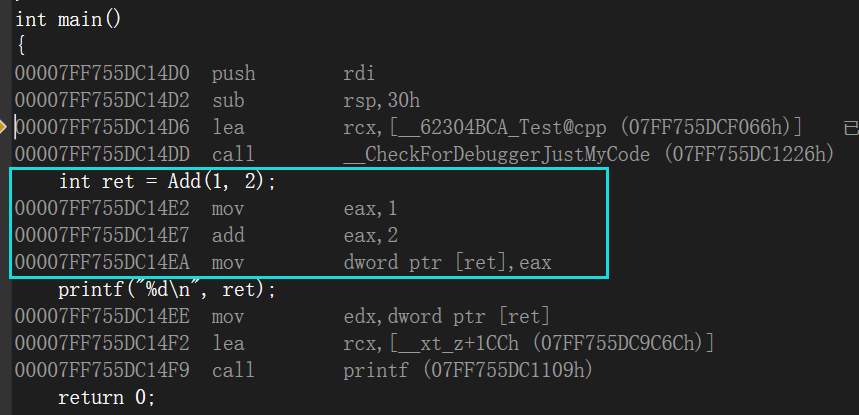
-
内联函数时一种空间换时间的方法
-
内联函数对于编译器只是一个建议,编译器会自动优化。假如说你的内联函数使用的不合理,把一个递归的函数或者循环多次的函数写成内联函数,编译器很聪明,会直接忽略你的inline,直接当成普通函数处理
-
内联函数定义和声明不要分开,最好在头文件中定义。inline 函数的定义对编译器而言必须是可见的,以便编译器能够在调用点内联展开该函数的代码。此时,仅有函数原型是不够的。如果分开定义,链接的时候就会出错,因为内联函数展开了之后就没有函数地址了,链接的时候不可能找的到
说到内联函数,我们很容易想起c语言里面的宏,还记得如何用宏写一个Add函数吗?
#define ADD(x, y) ((x)+(y))
int main()
{
int ret = Add(1, 2);
cout << ret << endl;
return 0;
}
在编译的第一步预处理过程中就会进行宏替换,这种短小的函数用宏写,也减少了栈帧的开销,下面我们对比一下内联函数和宏
-
宏写起来易出错,一不小心就会出现少加个括号,多加个分号之类的错误,而内联函数的写法和普通函数的写法一样,只需在前面加一个inline关键字
行宏替换,这种短小的函数用宏写,也减少了栈帧的开销,下面我们对比一下内联函数和宏 -
宏写起来易出错,一不小心就会出现少加个括号,多加个分号之类的错误,而内联函数的写法和普通函数的写法一样,只需在前面加一个inline关键字
-
宏不支持调试,而内联函数可以