背景:
随着数据量的爆发式增长,数字化转型称为了整个IT行业的热点,数据也开始需要更深度的价值挖掘,因此需要确保数据中保留的原始信息不丢失,从而应对未来不断变化的需求。当前以oracle为代表的数据库中间件已经逐渐无法适应这样的需求情况,于是业界也开始进行不断的产生的计算引擎,以便应对数据时代的到来。在此背景下,数据湖的概念被越来越多的人提起,希望能有一套系统在保留数据的原始信息情况下,又能够快速对接多种不同的计算平台,从而在数据时代占比的先机。
概述:
什么是数据湖,数据湖(Data Lake)以集中式存储各种类型的数据,包括:结构化、半结构化、非结构化数据。数据湖无需事先定义Schema,数据可以按照原始形态直接存储,覆盖多种类型的数据输入源。数据湖无缝对接多种计算分析平台,对Hadoop生态支持良好,存储在数据湖中的数据可以直接对其进行数据分析,处理、查询、通过对数据深入挖掘与分析,洞察数据中蕴含的价值。
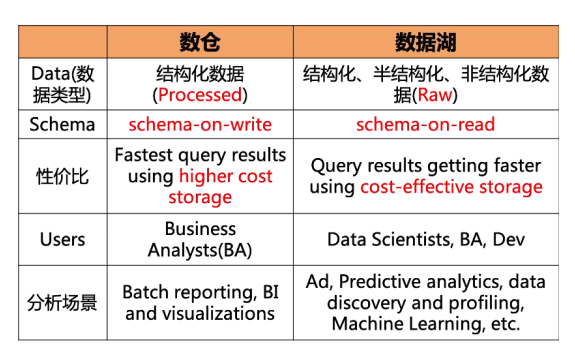
数据湖的关键特征与价值
海量数据存储:
面向海量数据存储设计,完全独立于计算框架之外,无需额外的挂载操作,数据可以直接访问,具备极大的灵活性和弹性能力,足以应对数据爆炸式发展,同时支持多层冗余能力,实现数据高可靠与高可用。
高效数据计算:
丰富的数据存储类型和共享能力,支持存储结构化、半结构化、非结构化数据,同时可以适配多种不同的计算平台,避免数据孤岛与无效的数据拷贝
安全数据管理:
支持数据目录功能,智能化的管理海量的数据资产,通过精细化权限控制保障数据安全
基于OSS的数据湖存储
OSS介绍
阿里云对象存储OSS(Object Storage Service)是阿里提供的海量、安全、低成本、高可靠的存储服务。其数据设计持久性不低于12个9,服务可用性、业务连续性不低于5个9,。OSS具有与平台无关的RestFul API接口,可用在任何应用、任何时间、任何地点存储和访问任意类型的数据
局域OSS构件数据湖存储
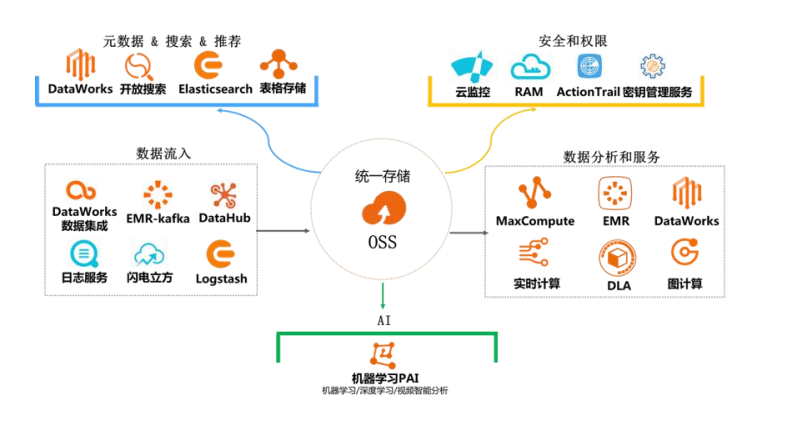
OSS在作为数据湖存储,充分满足数据湖的关键特性
海量数据存储
OSS采用分布式系统框架,扁平命名空间设计,支持无限制的存储规模,并且性能和容量可以随着系统扩展线性拉升。
OSS支持弹性扩容,容量自动扩展,不限制存储空间大小,用户可以根据所需存储量无限扩展存储空间,并且只需按照实际使用量收取费用,无需客户自己提前配置。
OSS支持数据高可用
- 在同一地域内(region)采用多可用区(AZ)冗余机制以及跨地域的复制机制,避免单点登录故障导致数据丢失或者无法访问
- 支持数据周期性校验,避免静默数据损坏
- 支持Object操作强一致性,写入Object的数据在返回成功响应后,立即可读
- 支持多版本能力,防止数据误删,整体OSS满足12个9的数据持久性以及995的服务可用性
高效数据的计算
- OSS提供RESTFul API,具有互联网可访问能力,用户可以随时随地立即存储或者 访问数据,无需提前进行映射和挂载操作
- OSS兼容开源Hadoop生态,并且无缝对接阿里云多种不同的计算平台,使得数据无需拷贝可以被计算平台共享使用。同时针对部分计算平台优化特定操作,从而提升数据处理性能。
- OSS支持算子卸载能力,目前提供了Select语句支持,可以让用户从单个文件中仅读取需要的数据,从而提升数据获取效率
安全数据管理
- OSS支持数据生命周期管理,用户可以通过设置生命周期规则,也符合规则的数据自动删除或者转存到更低成本的存储中。
- OSS支持客户端和服务端两种数据加密能力,用户可以根据自身情况灵活选择加密方案,避免数据泄露
- OSS通过WORM(Write Once Read Many)特性,支持数据保留合规,允许用户以“不可删除、不可篡改”方式保存和使用数据,符合美国证券交易委员会(SEC)和金融业监管局(FINRA)的合规要求(OSS已获得对应的合规认证)
- OSS支持多种数据访问安全控制策略,实现针对bucket、object、role的长期或者临时授权,从而满足最小权限数据共享的安全测试。
- 在未来面向海量数据湖场景下,对象存储OSS非常适合构件海量、高效、安全的数据湖
基于JindoFS+OSS构件高效数据湖
为啥要构件数据湖
大数据时代早期,Apache HDFS是构件具有海量存储能力数据仓库的首选方案。随着云计算、大数据、AI等技术的发展,所有云厂商都在不断完善自家的对象存储,来更好的适配Apache Hadoop、Spark大数据以及各种AI生态。由于对象存储有海量、安全、低成本、高可靠、易集成等优势,各种IoT设备,网站数据都把各种形式的原始文件存储在对象存储上,利用对象存储增强和扩展大数据AI也成为业界 共识,Apache Hadoop社区也推出了原生的对象存储Ozone,从HDFS到对象存储,从数据仓库到数据湖,把所有的数据都放在一个统一存储中,也可以更加高效地进行分析和处理。
对于云上的客户来说,如何构建自己的数据湖,早期的技术选型也非常重要,随着数据流的不断增加,后续进行架构升级和数据迁移的成本也会增加,在云上使用HDFS构建大规模存储系统,已经暴露出来不少问题,HDFS是Hadoop原生的存储系统,经过10年来的发展,HDFS已经成为大数据生态的存储标准,但是我们看到HDFS虽然不断的优化,但是NameNode单点瓶颈,JVM瓶颈仍然影响着集群的扩展,从1PB到100PB,需要不断的进行调优、集群拆分来,HDFS可以支持到EB级别,但是投入很高的运维成本,来解决慢启动,心跳风暴、节点扩容、节点迁移、数据平衡等问题
云原生的大数据存储方案,基于阿里云OSS构件数据湖最合适的选择。OSS是阿里云上的对象存储服务,有着高性能、无限容量、高安全、高可用、低成本等优势,JindoFS针对大数据生态对OSS进行了适配,缓存加速,甚至提供专门的文件元数据服务,满足上云客户的各种分析计算需求,因此在阿里云上,JindoFS+OSS称为客户采取数据架构迁移上云的最佳实践。
秒级启动,有大规模HDFS集群维护经验的同学比较清楚,当HDFS元数据存储量过亿之后,NameNode启动初始化要先加载Fsimage,再合并edit log,然后等待全部dataNode上报Block,这一系列流程完成要花费一个小时甚至更长的时间,由于NameNode是双机器高可用(Active\Standby),如果standby节点重启时active节点出现异常,或两条NameNode节点同时出现故障,HDFS将出现停服务一个小时以上的损失。JinDoFS的源数据服务基于Raft实现高可用,支持2N+1的部署模式,允许同时挂掉N台机器,元数据服务NameSpaceService在元数据内部存储上进行了设计和优化,进程启动之后可以提供服务,可以做到快速响应,由于namespaceservice近乎实时写入OTS的特点,元数据节点更换,甚至集群整体迁移也非常容易。
高效元数据操作,JindoFs NamespaceService基于内存+磁盘管理和存储元数据,但是性能上比使用内存的HDFS nameNode还要好,一方面JindoFS 是使用的C++开发,没有GC的问题,响应更快,另一方面由于Namespace Service内部有更好的设计,比如文件元数据上更细粒度的锁,更搞笑的数据快副本管理机制。
低资源消耗,HDFS NameNode采用内存形式来存储文件元数据,在一定规模下,这种组偶发性能上是比较不错的,但是这样做的也是使用HDFS元数据的规模受限与节点的内存,经过推算,1亿文件的HDFS文件大约需要分配60GB Java Heap给到NameNode,所以一台256GB的机器最多可以管理4亿左右的元数据,同时还要不断调优JVM GC。JindoFS的元数据采用Rocksdb存储元数据,可以轻松支持到10亿规模,对于节点的内存需要也是非常的小,资源开销不到NameNode的十分之一。
弹性运维,HDFS使用DataNode在存储节点上来管理节点存储,全部数据块都存储在节点的磁盘上,依靠DataNode定期检查和心跳把存储状态上报给NameNode,NameNode通过汇总和计算,动态地保证文件的数据块达到设定的副本数,对于大规模的集群来说,经常需要进行集群节点的扩容,节点迁移,节点下线,节点数据平衡这样的操作,大量的数据块的副本计算增加了nameNode的负载,同时节点相关的操作要等待NameNode内部的副本调度完成才能进行,通常一个存储节点的下线需要小时级别的等待才能完成,JindoFS使用StorageService管理节点上的存储,由于JindoFS 保证了数据OSS上有一个副本,所以本地的副本主要用来进行缓存加速,对于节点的迁移,节点下线等场景,JindoFS无需复杂副本计算,通过快速的标记即可完成下线。
高性能存储,StorageService采用C++语言开发,在对接最新的高性能存储硬件上也有着天然的优势,StorageService的存储后端不仅可以同时对接SSD、本磁盘、OSS满足Hadoop、Spark大数据框架各种海量、高性能的存储访问需求,可以对接内存、AEP这样的高性能设备满足AI机器学习的低延时,高吞吐的存储使用需求。
数据湖的构件
数据湖元数据服务的实现和挑战
大数据的引擎的现状
在大数据计算和存储领域,因不同业务场景、不同数据规模,诞生了很多适合处理不同需求的各类的大数据引擎,比如说计算引擎类有数据分析引擎Hive、交互式分析引擎Presto、迭代计算引擎spark以及流处理引擎Flink等等,存储类有日志存储系统的SLS、分布式文件系统HDFS等,这些引擎和系统很好的满足某一领域的业务需求,但也存在非常严重的数据孤岛问题;在同一份数据上综合使用这些系统,必然面临着大量的ETL工作,而且更关键的是在目前各种公司业务链路上这种使用方式非常常见,同时因数据加工、存储产生的成本以及整体延时大大增加,业务决策时间也相应变长,解决这一问题的关键在于引擎元数据需要互通,只有构建满足各种引擎需求的数据湖统一元数据服务视图,才能 实现数据共享,避免其中的额外的ETL成本以及降低链路的延时。
Hive:
Hive的特点:
1、可扩展性
Hive可以自由的扩展集群的规模,一般情况下不需要重启服务
2、延申性
Hive支持自定义函数,用户可以根据自己的需求来实现自己的函数
3、容错
即使节点出现错误,SQL仍然可以完成执行
Hive的优缺点:
优点:
1、操作接口采用类sql语法,提供快速开发的能力(简单、容易上手)
2、避免了去写MapReduce,减少开发人员的学习成本
3、Hive的延迟性比较高,因此Hive常用于数据分析,适用于对实时性要求不高的场合
4、Hive 优势在于处理大数据,对于处理小数据没有优势,因为 Hive 的执行延迟比较高。(不断地开关JVM虚拟机)
5、Hive 支持用户自定义函数,用户可以根据自己的需求来实现自己的函数。
6、集群可自由扩展并且具有良好的容错性,节点出现问题SQL仍可以完成执行
缺点: 1、Hive的HQL表达能力有限
(1)迭代式算法无法表达 (反复调用,mr之间独立,只有一个map一个reduce,反复开关)
(2)数据挖掘方面不擅长
2、Hive 的效率比较低
(1)Hive 自动生成的 MapReduce 作业,通常情况下不够智能化
(2)Hive 调优比较困难,粒度较粗 (hql根据模板转成mapreduce,不能像自己编写mapreduce一样精细,无法控制在map处理数据还是在reduce处理数据)
数据湖元数据服务的设计
数据湖元数据服务的设计目标是能够在大数据引擎,存储多样性的环境下,构建不同存储系统、格式和不同引擎统一元数据视图,并且具备统一的权限、元数据、并且需要兼容和扩展开源大数据生态元数据服务,支持自动获取元数据,并且达到一次管理多次使用的目的,这样既能够兼容开源生态,也具备极大的易用性。另外元数据应该支持追溯、审计、这就要求数据湖统一元数据服务具备以下能力和价值
提供统一的权限、元数据管理模块,统一的权限、元数据管理模块是各类引擎和存储互通的基础,不仅权限、元数据模型需要满足业务对于权限隔离的需要,也需要能够合理支持目前引擎的各种权限模型。
提供大规模元数据的存储和服务能力,提升元数据服务能力的极限,满足超大数据规模和场景。。
提供存储统一的元数据管理视图:将各类存储系统(对象、文件、日志等系统)上数据进行结构化既能方便数据的管理,也因为有了统一的元数据,才能进行下一步的分析和处理
丰富的计算引擎,各类引擎,通过统一的元数据服务视图访问和计算其中的数据,满足不同的场景需求,比如PAI、MaxCompute、Hive等可以在同一份OSS数据上进行计算和分析,通过引擎支持的多样化,业务场景将越来越容易进行场景转换和使用
元数据操作的追溯、审计。
元数据自动发现和收集能力,通过对文件存储的目录、文件、文件格式的自动感知、自动创建和维护元数据的一致性,方便存储数据的自动化维护和管理。
数据湖元数据服务架构
元数据服务上层是引擎接入层
- 提供各种协议的SDK和插件,能够灵活支持各种引擎的对接,满足引擎对于元数据服务的访问需要。并且通过元数据服务提供的视图,对底层文件系统进行分析和处理
- 通过插件体系无缝兼容EMR引擎,能够使EMR全家桶开箱即用,用户全程无感知,即可体验统一元数据服务,避免原Mysql等存储的可扩展性差的问题。