今天在使用用run运行shell文件转为的cmd命令后,run可以正常运行,但是debug却出现问题,错误信息:
Usage:
pydevd.py --port N [(--client hostname) | --server] --file executable [file_options]
Traceback (most recent call last):
File "/home/mapengsen/.pycharm_helpers/pydev/pydevd.py", line 2016, in main
setup = process_command_line(sys.argv)
File "/home/mapengsen/.pycharm_helpers/pydev/_pydevd_bundle/pydevd_command_line_handling.py", line 146, in process_command_line
raise ValueError("Unexpected option: " + argv[i])
ValueError: Unexpected option: --local_rank=0
[2023-07-08 10:08:11,202] [INFO] [launch.py:315:sigkill_handler] Killing subprocess 2934
[2023-07-08 10:08:11,202] [ERROR] [launch.py:321:sigkill_handler] ['/home/mapengsen/anaconda3/envs/38/bin/python', '-u', '/home/mapengsen/.pycharm_helpers/pydev/pydevd.py', '--local_rank=0', '--multiprocess', '--qt-support=auto', '--client', '127.0.0.1', '--port', '58899', '--file', '/mnt/d/Pycharm_workspace/DoubleTarget/RetMol/MolBART/train_retrieval.py', '--model-parallel-size', '1', '--pipe-parallel-size', '0', '--num-layers', '4', '--hidden-size', '256', '--num-attention-heads', '8', '--seq-length', '512', '--max-position-embeddings', '512', '--batch-size', '320', '--gas', '16', '--train-iters', '50000', '--lr-decay-iters', '320000', '--data-impl', 'mmap', '--distributed-backend', 'nccl', '--lr', '0.0001', '--lr-decay-style', 'cosine', '--min-lr', '1.0e-5', '--weight-decay', '0', '--clip-grad', '1.0', '--warmup', '0.01', '--checkpoint-activations', '--log-interval', '1', '--save-interval', '10000', '--eval-interval', '50000', '--eval-iters', '10', '--fp16', '--dataset_path', '../data/zinc.tab', '--deepspeed', '--deepspeed_config', 'megatron_molbart/ds_config.json', '--zero-stage', '1', '--zero-reduce-bucket-size', '50000000', '--zero-allgather-bucket-size', '5000000000', '--zero-reduce-scatter', '--checkpoint-activations', '--checkpoint-num-layers', '1', '--partition-activations', '--synchronize-each-layer', '--contigious-checkpointing', '--stage', '1', '--train_from', 'pretrain', '--model_ckpt_itr', '50000', '--attr', 'logp-sa', '--attr_offset', '0', '--data_source', 'jtnn', '--enumeration_input', 'false', '--retriever_rule', 'random', '--pred_target', 'reconstruction', '--n_retrievals', '10', '--n_neighbors', '100'] exits with return code = 1
Process finished with exit code 1我再网上查了以后大多数说是因为分布式的原因,可能是因为我使用了deepspeed,所以导致了分布式的问题吧,
此时参考文章:pycharm终止运行_Pycharm 下如何 debug torch.distributed_祁圆圆的博客-CSDN博客
方法说起来很简单,只需要在 Pycharm 的 Configuration 中作一些设置即可:
- 打开 Run -> Edit Configurations...
- Script path 不再是你自己代码的路径,而是
launch.py文件的保存路径,例如我的是:
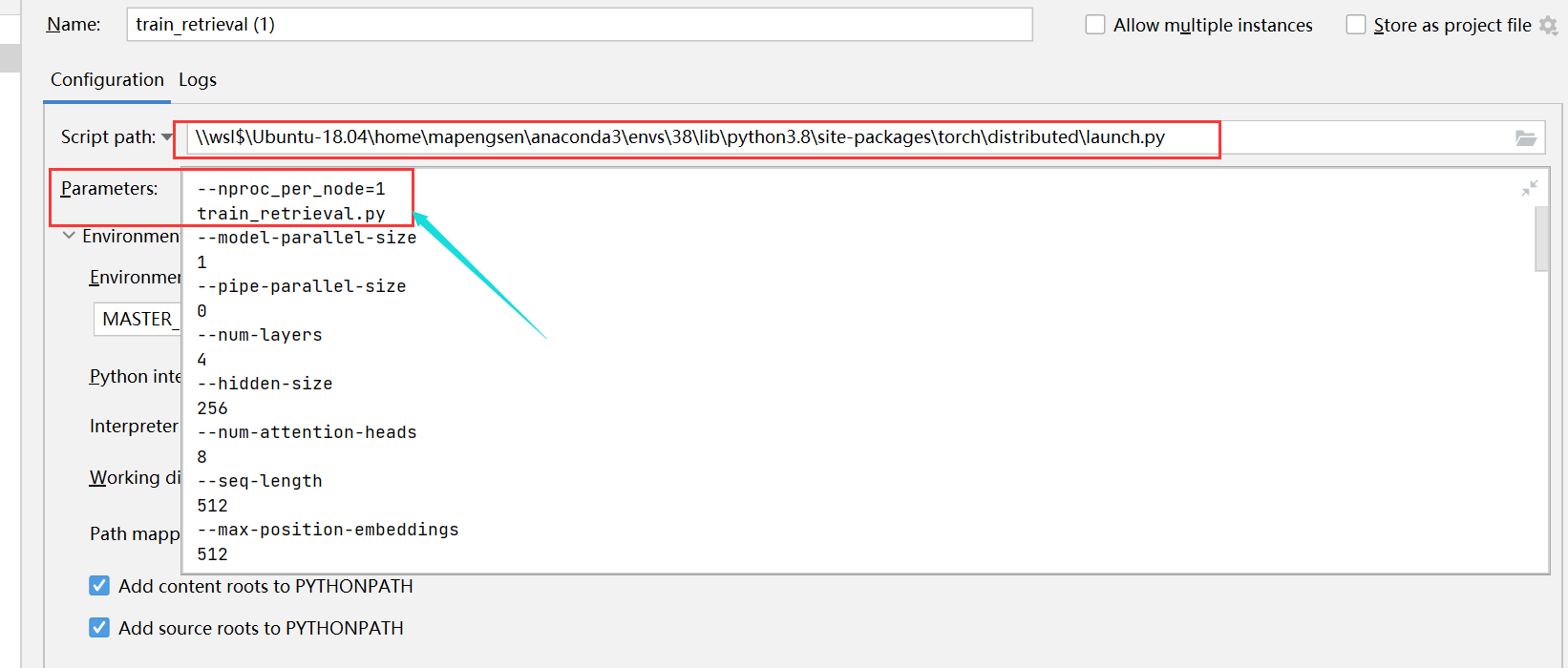
\\wsl$\Ubuntu-18.04\home\mapengsen\anaconda3\envs\38\lib\python3.8\site-packages\torch\distributed\launch.py- 设置 Parameters:
--nproc_per_node=1 main.py- 在 Environment variables 中添加
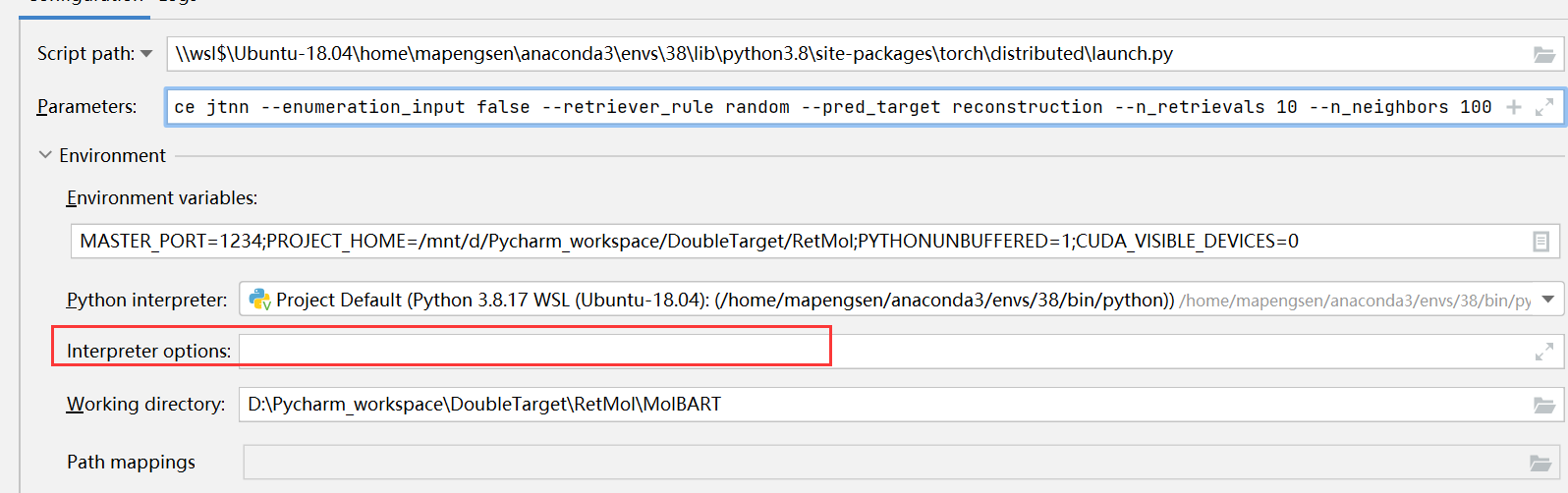
CUDA_VISIBLE_DEVICES=0,1。 - 把interpreter options中的deepspeed部分删除(因为现在使用了distribution.
launch.py作为script path) - 剩下的 Python interpreter 和 Working directory 就按照通常情况来设置即可。
经过这些步骤,就可以在 Pycharm 中 debug 分布式训练的代码了。







![火车头采集器AI伪原创[php源码]](https://img-blog.csdnimg.cn/9f263cbacb474713bc2a8a8bb1b65629.png)