在机器学习和深度学习中,位量化(Bit Quantization)是一种将模型参数或激活值表示为较低精度的二进制数的技术。通常情况下,模型的参数和激活值是以浮点数形式存储和计算的,占用较大的存储空间和计算资源。位量化通过减少参数和激活值的表示精度,可以显著减小模型的存储需求和计算复杂度,从而提高模型的运行效率。
在位量化中,常见的方法包括二值量化(Binary Quantization)、三值量化(Ternary Quantization)、四值量化(Quaternary Quantization)等。这些方法将参数或激活值限定在较小的离散值集合中,例如只使用-1和1表示二值量化,-1、0和1表示三值量化。通过减少表示精度,可以大幅降低存储空间和计算量,同时在一定程度上保持模型的性能。
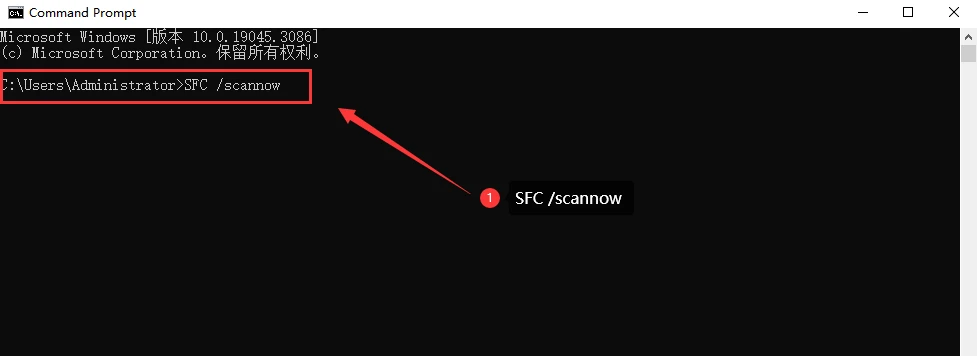
一、clone一个GitHub项目到服务器端
到目标文件夹下输入:
wget https://github.com/putshua/SNN_conversion_QCFS/archive/refs/heads/master.zip
其中地址是右键点击项目的Dowload ZIP,复制链接而来
然后就能在当前文件夹下看到zip文件
而后:
unzip master.zip
大功告成!
二、
where is /nvme/Image ?

根目录结构下的一个文件夹里。平时我们是在/home/jiahao_su这个文件夹内工作。
By the way, bin中存了一些常用的命令,eg》cat,chmod,cp,bash…
三、
wget出问题:
错误消息 “443… failed: Network is unreachable” 表示网络不可访问。这通常是由于网络连接问题或防火墙设置导致的。
四、
print基础用法
1、flush: 是否立即刷新输出,默认为 False,即在遇到换行符时才刷新输出缓冲区。通过设置 flush=True 参数,可以强制将输出立即刷新到终端,而不需要等待缓冲区填满或程序执行结束。这对于实时监控程序的输出或者确保日志信息及时显示非常有用。
2、print 函数在默认情况下会自动在输出内容的末尾添加换行符\n,以实现换行效果。如果不希望在输出内容末尾添加换行符,可以通过设置 end 参数来改变默认行为。例如,print('Hello', end='') 将在输出内容末尾不添加换行符,而是保持在同一行输出。
五、
spikes是一个形状为(batch_size, num_classes)的二维张量,其中batch_size表示批次大小,num_classes表示类别数量。当spikes是一个形状为(3, 5)的二维张量时,其中batch_size=3,num_classes=5。假设spikes的值如下所示:
spikes = tensor([[0.2, 0.5, 0.8, 0.4, 0.3],
[0.6, 0.1, 0.9, 0.7, 0.2],
[0.3, 0.7, 0.4, 0.9, 0.5]])
那么,使用spikes.max(1)将返回一个包含两个张量的元组,如下所示:
(tensor([0.8, 0.9, 0.9]), tensor([2, 2, 3]))
第一个张量表示每个样本的最大值,即每一行中的最大值。第二个张量表示每个样本最大值的索引,即每一行中最大值的列索引。spikes.max(1)[1]将返回一个形状为(3,)的一维张量,包含了每个样本中最大值所在的列索引。在分类任务中,这通常用于获取预测的类别标签。
使用 spikes.max(0) 将返回一个包含两个张量的元组,如下所示:
(tensor([0.6, 0.7, 0.9, 0.9, 0.5]), tensor([1, 2, 1, 2, 2]))
在某些情况下,这可以用于查找每个类别的最佳样本或最大激活。