1.数据类型
【数值型】
int或者integer,大小为4个字节,范围:(大约)-21.5亿~21.5亿;
bigint,大小为8个字节;
float大小为4个字节;
double大小为8个字节;
【字符型】
char,定长字符串,大小(0-255字节)
varchar,变长字符串,大小(0-65535字节)
text,长文本数据,大小(0-65534字节)
【日期时间型】
date,大小3个字节,格式为YYYY-MM-DD
datetime,大小为8个字节,格式为YYYY-MM-DD hh:mm:ss
timestamp,大小4个字节,格式YYYY-MM-DD hh:mm:ss
【枚举类型】
enum,全程:enumeration
2.数据表约束规则
not null,非空
default,设置默认值
unique,唯一性
auto_increment,自动增长
primary key,设置主键
foreign key,设置外键
3.简单操作
全字段插入:insert into table_name values(?, ?, ?);
部分字段插入:insert into table_name(?, ?) values(?, ?);
查询全字段数据:select * from table_name;
查询自定字段数据:select ?, ? from table_name;
修改指定数据:update table_name set ? = ? where ...
删除指定数据:delete from table_name where ...
4.查询时可使用的关键字
distinct,去重。
select distinct username from user; 查询所有用户不同的名字
where,可根据相关条件进行查询
select * from user where userId = '123'; 查询id为123的用户的所有信息
order by,对数据进行排序,asc为升序,desc
select * from user order by userName asc; 按照升序对用户名进行排序
limit n1 (offset/,) n2,从n1+1开始检索n2条记录
select * from user limit 0, 10;从第一条数据开始检索10条记录
select * from user limit 0 offset 10;从第一条数据开始检索10条记录
select * from user limit 10;检索开始时的10条记录
【其他关键字】
>, <, >=, <=, !=
and, or, not
in, not in, between ... and
is null, is not null
%任意多个字符,_单个字符
5.聚合查询统计
sum, avg, count, max, min
select count(*) from user; 统计总共有多少用户
group by,根据属性进行分组,一般配合以上词语进行使用
select usersex,count(*)from user order by usersex; 统计不同性别的人数
having,针对分组后的数据进行过滤
select usersex, count(*) from user having count > 100; 展示每种性别人数大于100的
6.关联查询
on,连接后查询查询条件的限制
inner join,内连接
select * from student inner join score on student.studentId = score.studentId; 查询学生表和成绩表,学生id相匹配的所有数据
left join,左连接,right join,右连接。如果左侧的表显示完全是左连接,如果右侧的表显示完全是右连接,如果没有匹配的显示null
select * from student left join score on student.studentId = score.studentId;查询所有学生的成绩,如果某同学在学生表里存在,且不在成绩表里,成绩表内的信息显示null即可
自连接:
select * from student s1 join student s2 where s1.name = s2.name and s1.studentId != s2.studentId; 查询学生表中姓名相同的学生
子查询:
select * from student where classes_id = (select classes_id from student where studentname ='张三'); 查询张三的同班同学,首先我们要查询张三的班级,使用班级信息查询同学
union,合并两个结果集,会自动去掉重复的行
select * from score where id < 3 union select * from score where name = ‘张三’;查询id小于3或名字为张三的成绩信息,如果重复,会去重。
union all,合并两个结果集,不会自动去重。
7.索引
查看索引:show index from table_name;
创建索引:create index index_name on table_name(?);
删除索引:drop index index_name on table_name;
索引的底层是一个B+树,如下图所示
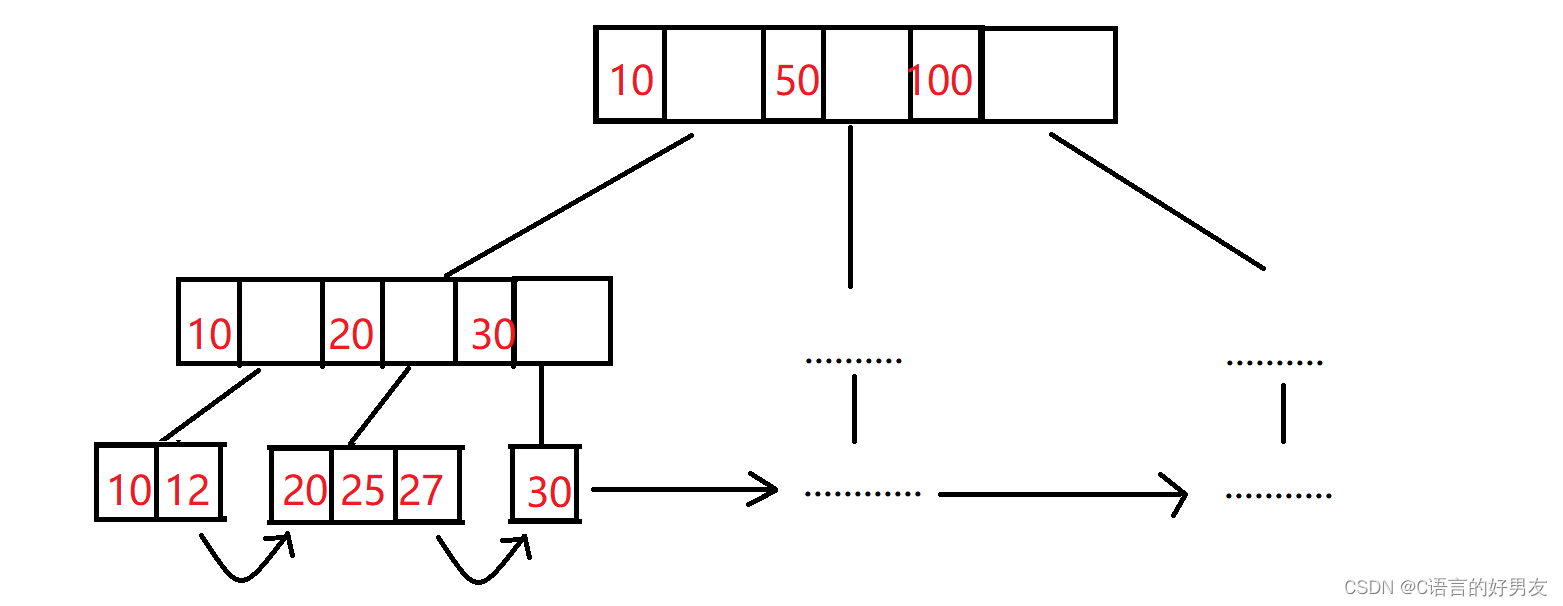
【解析】
- 这是一个B+树,里面的数字存放的是每条信息的Id
- 使用索引(Id)进行查找的时候,都会从头节点开始查找,直到叶子节点
- 只有叶子节点存放相应的完整信息,其他节点存放信息的Id.
- 每个叶子节点都与下一个叶子节点相连
【好处】
- 查询次数稳定:这是一个平衡树,且只有叶子节点存放完整的信息,每次查询的时候,都会从头节点到叶子节点,时间复杂度总是O(logN)
- 支持模糊和范围查询:模糊查询我们只需遍历叶子节点即可,时间复杂度为O(n),范围查询我们只需找到开始的位置,然后向后查找即可
- 所占的内存小:由于具体的数据只有叶子节点存储,在运行的时候相对较小。
8.事务
开始事务:start transaction;
回滚或提交:rollback/commit
事务的四大特性:
原子性:要么全部执行,要么全部不执行
一致性:事务执行前后,数据都是准确靠谱的
持久性:事务的修改的内容是写到硬盘上的,持久存在的,重启后数据不会丢失
隔离性:是为了解决“并发”执行数据引起的问题
【并发执行事务可能产生的问题】
脏读问题:一个数据正在修改,且没有提交,另一个事务进行读取到了这个没有提交的数据。(在写的时候读)
解决方法:对写进行加锁。
不可重复读:事务1修改了数据并提交,事务2读取了数据过程中,事务3修改了数据,导致事务2两次读相同的数据,却产生了不同的结果。(在读的时候写)
解决方法:对读加锁
幻读问题:在事务1读的时候,事务2对此表中其他数据进行了修改,导致产生了不一样的结果集。
解决方法:“串行化”执行事务。