文章目录
- 一、停用词介绍
- 二、停用词应用场景
- 2.1 提取高频词
- 2.2 词云图
- 三、停用词获取方法
- 3.1 自定义停用词
- 3.2 用wordcloud调取停用词
- 3.3 用nltk调取停用词
- 3.3.1 nltk中文停用词
- 3.3.2 nltk英文停用词
- 3.4 用sklearn调取停用词
- 3.5 用gensim调取停用词
- 3.6 用spacy调取停用词
一、停用词介绍
您好,我是@马哥python说 ,一名10年程序猿。
在自然语言处理(NLP)研究中,停用词stopwords是指在文本中频繁出现但通常没有太多有意义的词语。这些词语往往是一些常见的功能词、虚词甚至是一些标点符号,如介词、代词、连词、助动词等,比如中文里的"的"、“是”、“和”、“了”、“。“等等,英文里的"the”、“is”、“and”、”…"等等。
停用词的作用是在文本分析过程中过滤掉这些常见词语,从而减少处理的复杂度,提高算法效率,并且在某些任务中可以改善结果的质量,避免分析结果受到这些词的干扰。
二、停用词应用场景
2.1 提取高频词
在使用jieba.analyse提取高频词时,可以事先把停用词存入stopwords.txt文件,然后用以下语句设置停用词:jieba.analyse.set_stop_words(‘stopwords.txt’) 这样提取出的高频词就不会出现停用词了。
2.2 词云图
在使用wordcloud画词云图时,可以设置WordCloud对象的参数stopwords,把需要设置的停用词放到这个参数里(通常情况下,需要手动多次增加停用词,多轮迭代,才能绘制出满意的词云图结果)。


图2掺杂了太多无意义的词语,严重影响了词频分析结果,图1效果就好多了,由此可见停用词在文本分析里的重要性。
三、停用词获取方法
3.1 自定义停用词
在科研领域,很多机构公开了一些停用词库,比如中文停用词表、哈工大停用词表、百度停用词表、四川大学机器智能实验室停用词库等,以方便广大科研者使用。
下面,以哈工大停用词表为例,完整代码如下:
# 读取停用词(哈工大通用停用词表)
with open('hit_stopwords.txt', 'r') as f:
stopwords_list = f.readlines()
stopwords_list = [i.strip() for i in stopwords_list]
print('停用词数量:', len(stopwords_list))
print('停用词列表:')
print(stopwords_list)
运行截图:
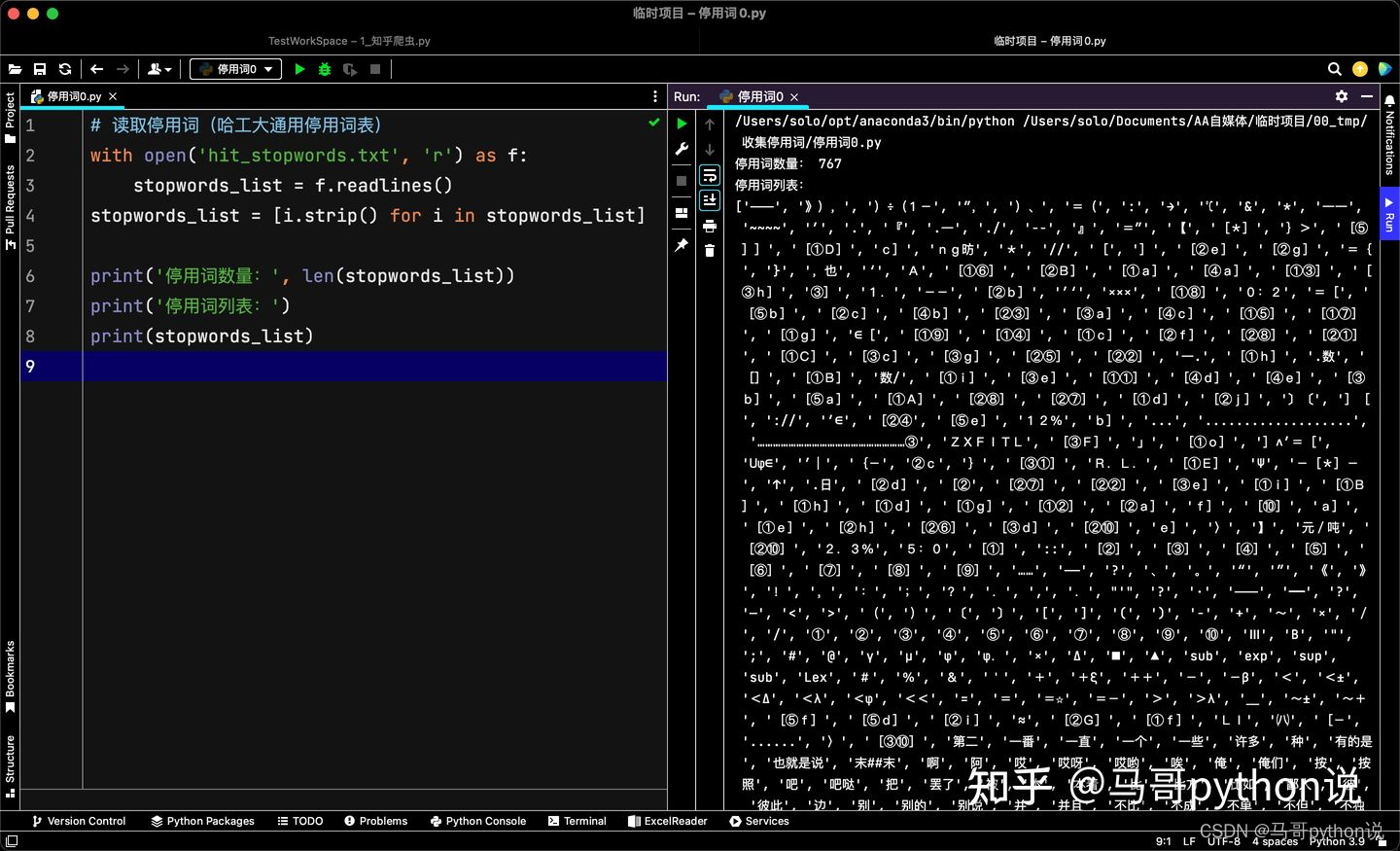
可以看到,中文停用词还是挺全面的,共767个。
我整理了一份较详尽的停用词词典,包含:中文停用词表、哈工大停用词表、百度停用词表、四川大学机器智能实验室停用词库,公众号"老男孩的平凡之路"后台回复"停用词"直接拿!
3.2 用wordcloud调取停用词
Python中的wordcloud是用来画词云图的库,它可以根据文本中单词的频率或重要性,将单词以不同的大小、颜色等形式展示在图像中,从而形成一个视觉上吸引人的词云图。
同时,它也内置了英文停用词库,完整代码如下:
from wordcloud import STOPWORDS
print('停用词数量:', len(STOPWORDS))
print('停用词列表:')
print(STOPWORDS)
运行截图:
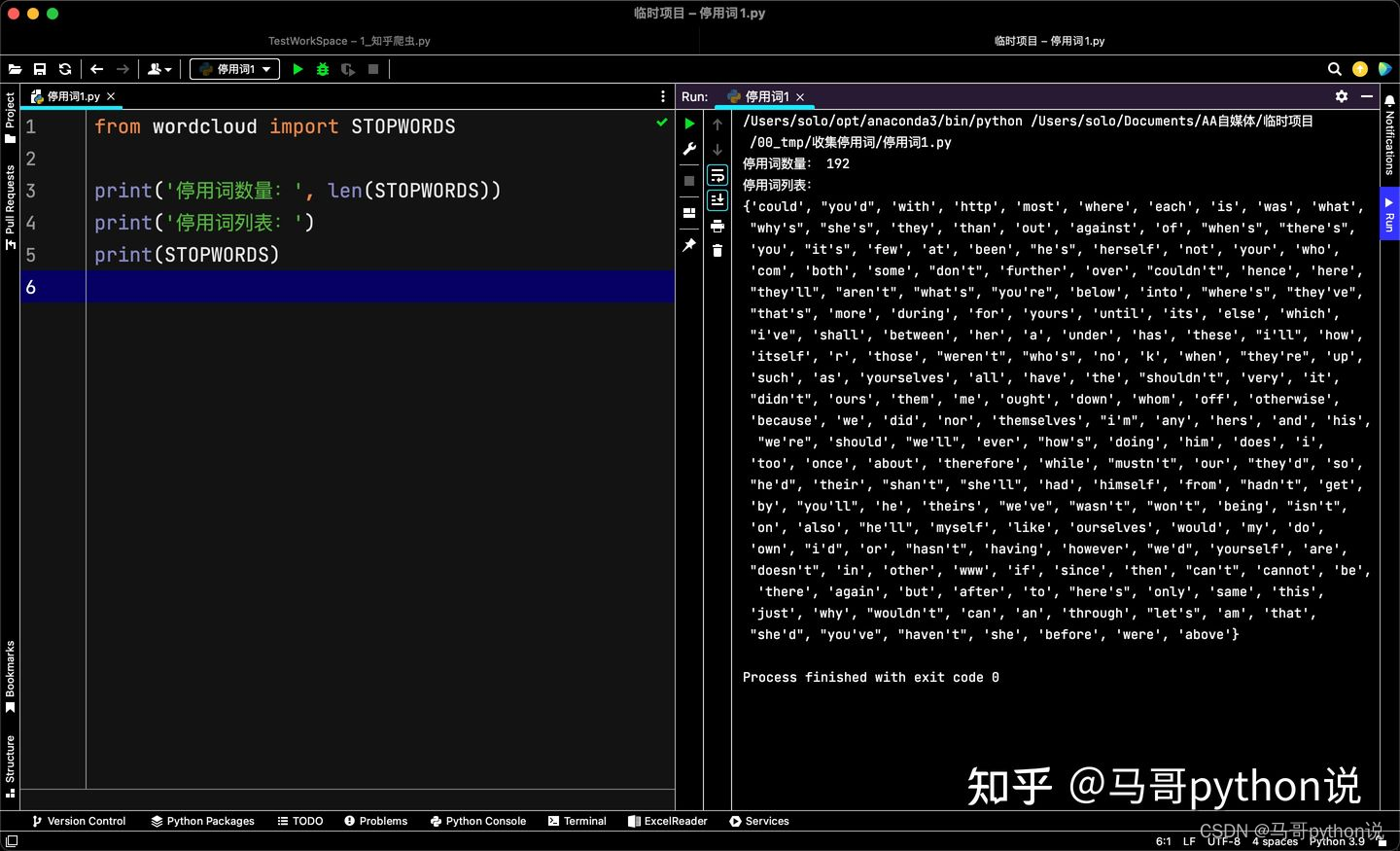
可以看到,wordcloud共包含了192个常用英文停用词。
3.3 用nltk调取停用词
nltk是一个流行的自然语言处理库,提供了许多文本处理和语言分析的功能。包含停用词加载、文本分词、词性标注、命名实体识别、词干提取和词形还原等常见功能。
其中,nltk内置了多种语言的停用词,下面分别介绍中文、英文停用词。
3.3.1 nltk中文停用词
完整代码:
import nltk
from nltk.corpus import stopwords
# 下载停用词资源
nltk.download('stopwords')
# 获取中文停用词列表
stopwords_cn_list = stopwords.words('chinese')
# 打印中文停用词列表
print('中文停用词数量:', len(stopwords_cn_list))
print('中文停用词:\n', stopwords_cn_list)
运行截图:
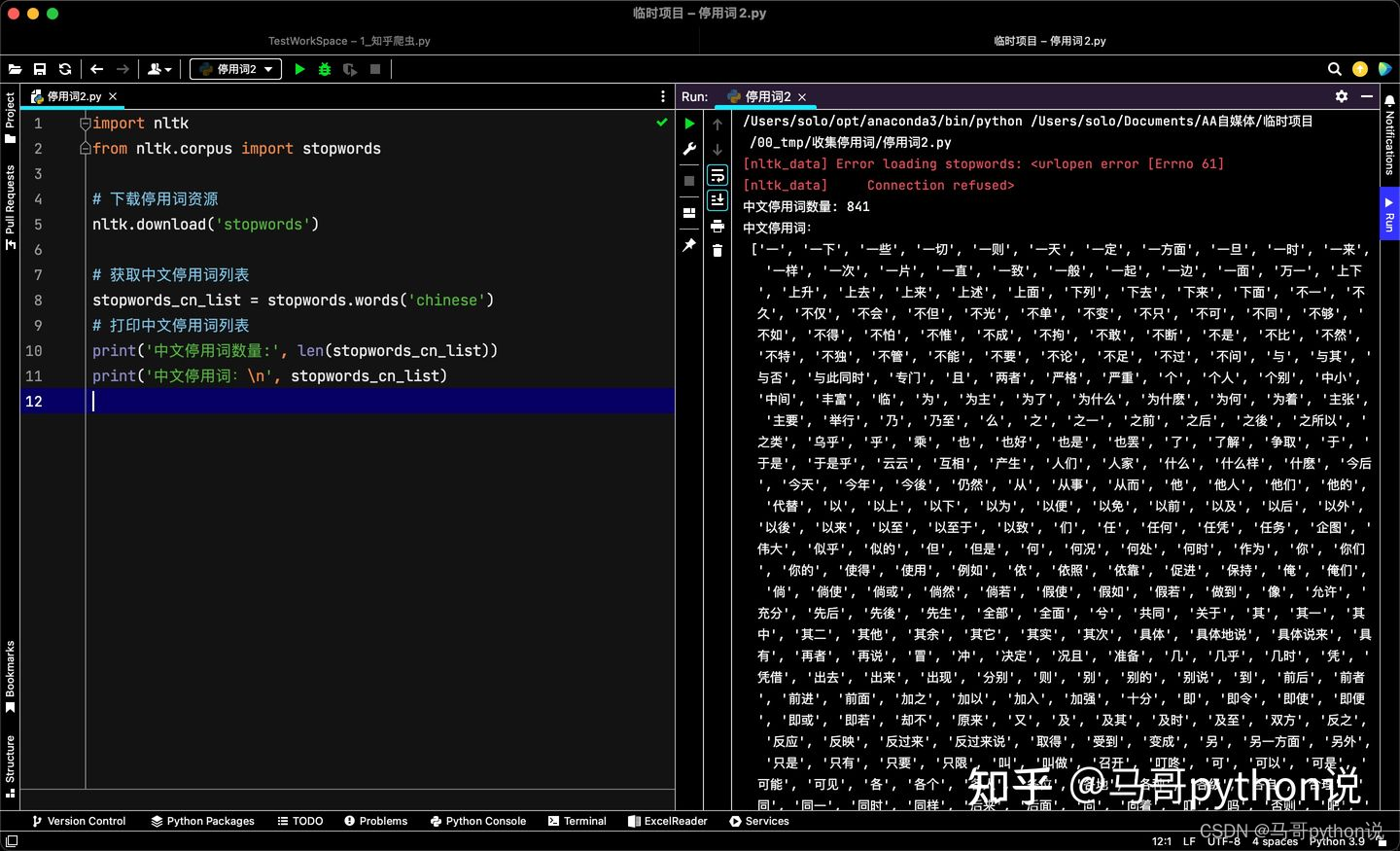
可以看到,nltk共包含841个中文停用词。
3.3.2 nltk英文停用词
完整代码:
import nltk
from nltk.corpus import stopwords
# 下载停用词资源
nltk.download('stopwords')
# 获取英文停用词列表
stopwords_en_list = stopwords.words('english')
# 打印英文停用词列表
print('英文停用词数量:', len(stopwords_en_list))
print('英文停用词:\n', stopwords_en_list)
运行截图:
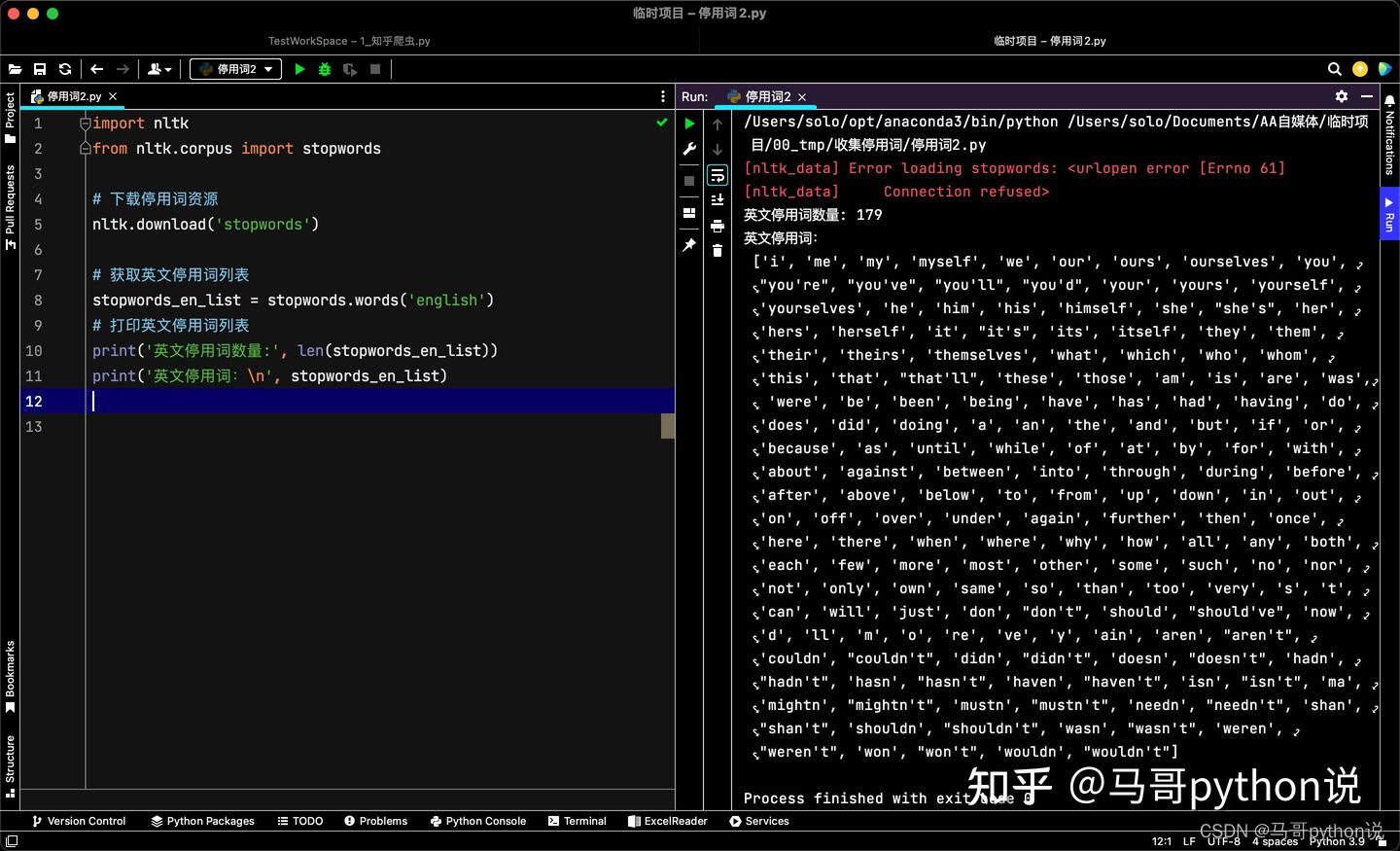
可以看到,nltk共包含179个英文停用词。
3.4 用sklearn调取停用词
sklearn是一个用于机器学习的Python库,它包含了各种经典和先进的机器学习算法,如分类、回归、聚类、降维、特征选择、模型选择等。
其中,sklearn.feature_extraction是用于特征提取的模块,可以利用它调取停用词库,完整代码如下:
from sklearn.feature_extraction.text import ENGLISH_STOP_WORDS
# 打印停用词列表
print('停用词数量:', len(ENGLISH_STOP_WORDS))
print('停用词列表:')
print(list(ENGLISH_STOP_WORDS))
运行截图:
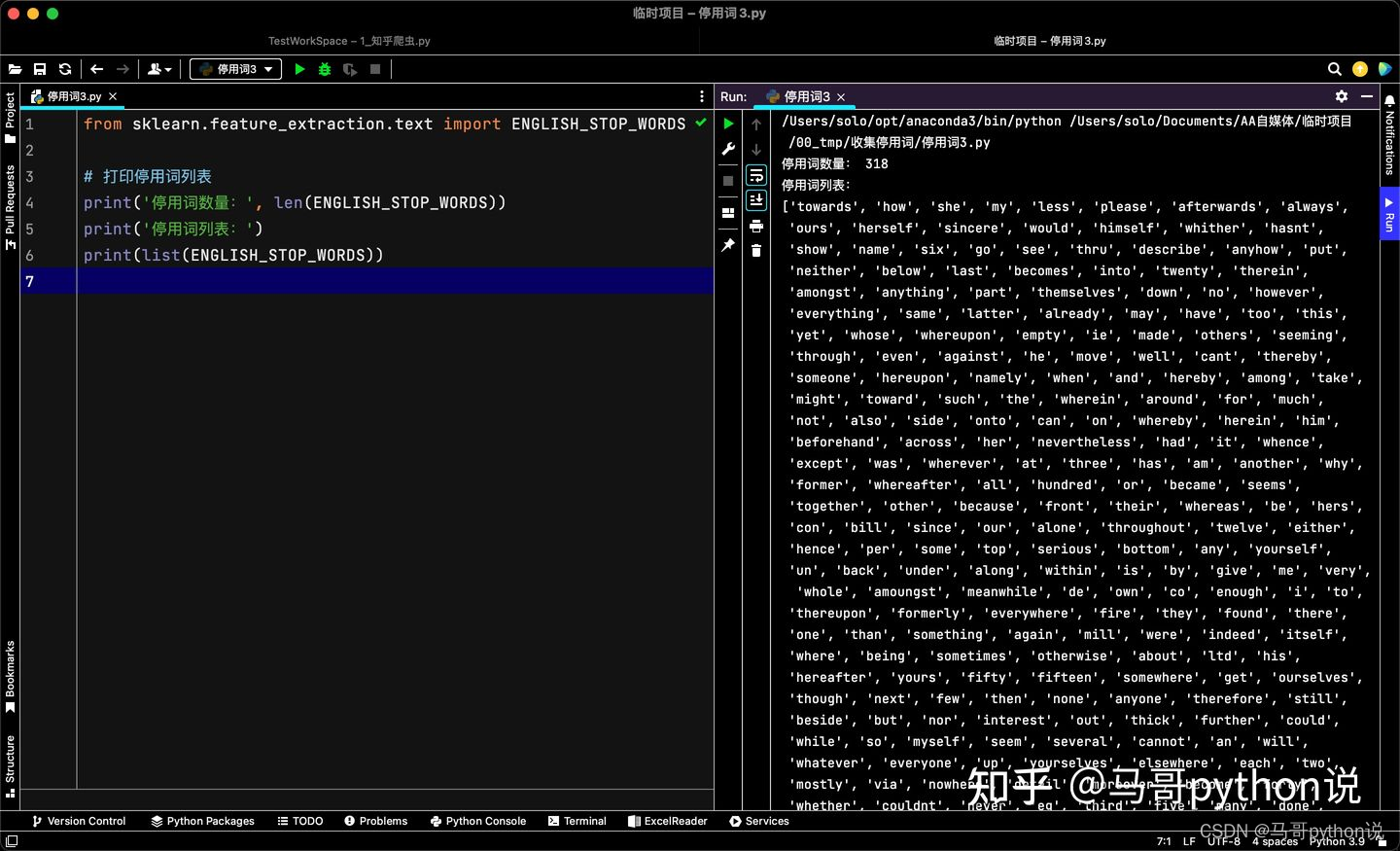
可以看到,sklearn共包含318个英文停用词。
3.5 用gensim调取停用词
gensim是一个用于主题建模和自然语言处理的Python库。它提供了一组功能强大的工具和算法,用于从大规模文本语料库中提取语义主题和执行相关的文本处理任务。
其中,gensim.parsing.preprocessing是gensim库中用于文本预处理的模块。该模块提供了一系列函数和工具,用于对文本进行标记化、停用词去除、大小写转换、标点符号去除、词干提取等常见的文本预处理任务。
用gensim调取停用词,完整代码如下:
from gensim.parsing.preprocessing import STOPWORDS
# 打印停用词列表
print('停用词数量:', len(STOPWORDS))
print('停用词列表:')
print(list(STOPWORDS))
运行截图:
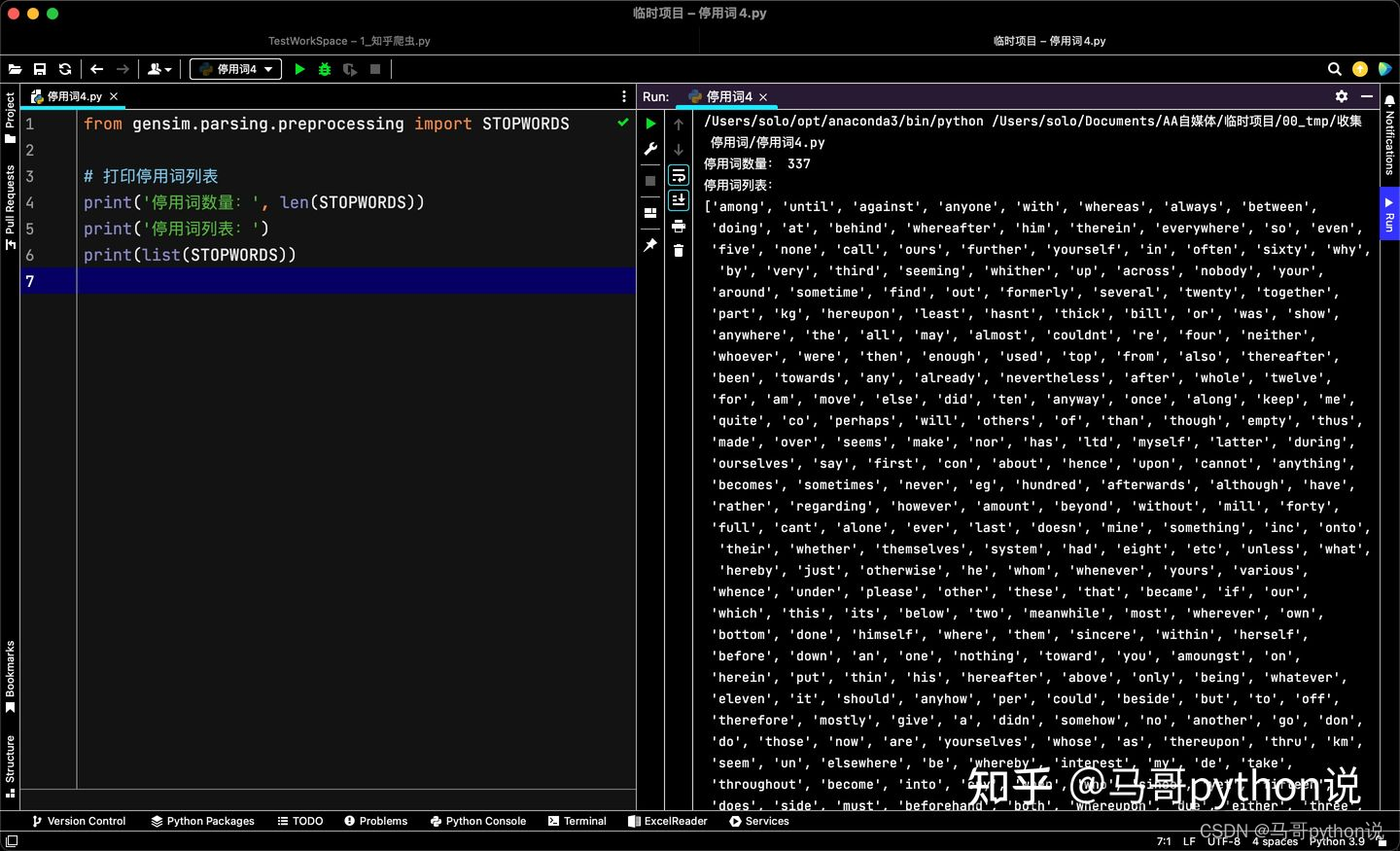
可以看到,gensim共包含337个英文停用词。
3.6 用spacy调取停用词
spacy是一个用于自然语言处理的Python库,具有高性能、易用性和多语言支持的特点。它提供了一系列的功能和工具,用于词法分析、命名实体识别、句法分析、依存关系分析等常见的自然语言处理任务。
用spacy调取停用词,完整代码如下:
import spacy
nlp = spacy.load("en_core_web_sm")
stopwords = nlp.Defaults.stop_words
# 打印停用词列表
print('停用词数量:', len(stopwords))
print('停用词列表:')
print(list(stopwords))
运行截图:
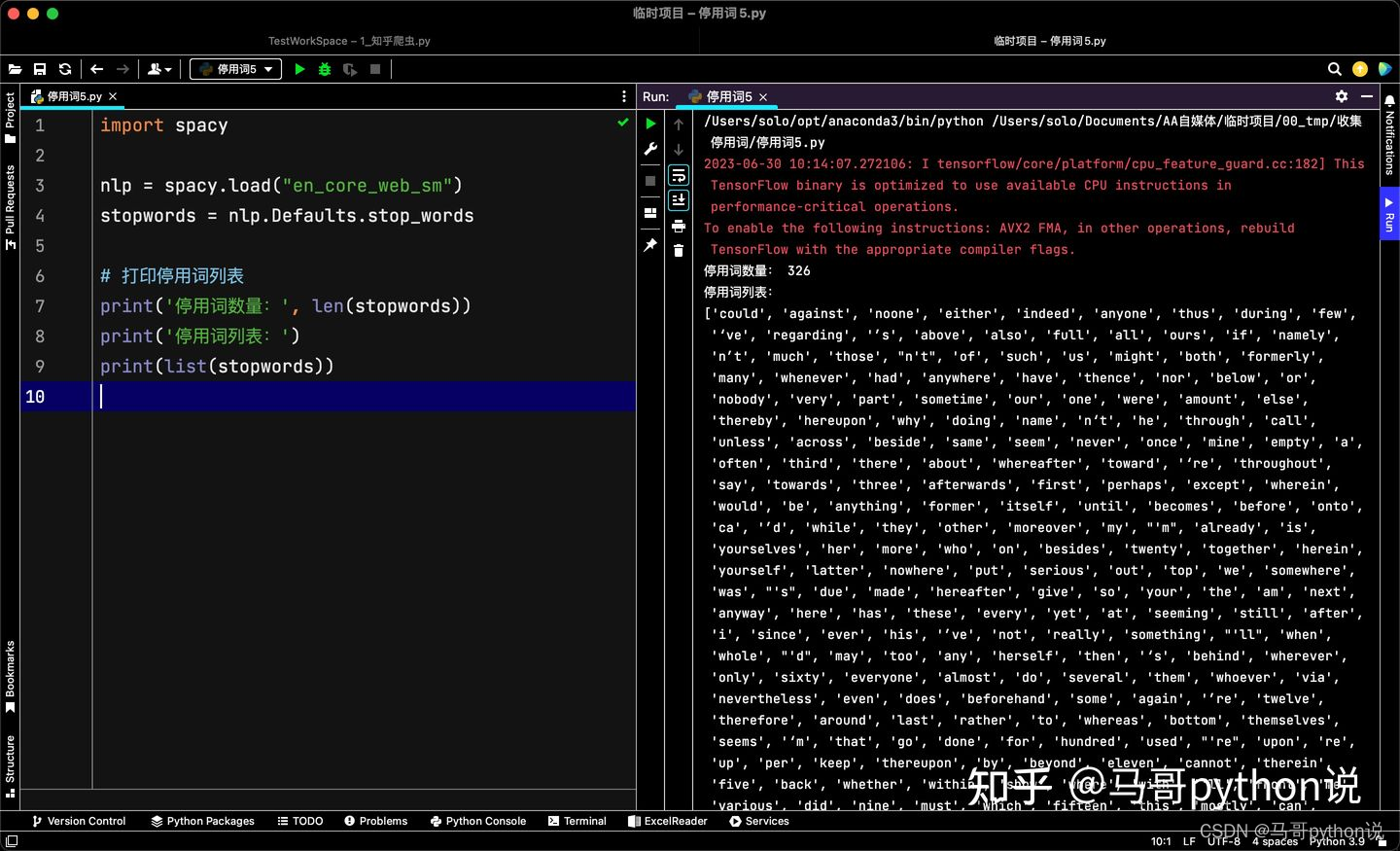
可以看到,spacy共包含326个英文停用词。
以上。
推荐阅读:
【Python可视化大屏】「淄博烧烤」热评舆情分析大屏
【爬虫+数据清洗+可视化】用Python分析“淄博烧烤“的评论数据
【爬虫+数据清洗+可视化分析】用Python分析哔哩哔哩“狂飙”的评论数据
【爬虫+数据清洗+可视化分析】用Python分析哔哩哔哩“阳了“的评论数据
首发公号:【停用词】NLP中的停用词怎么获取?我整理了6种方法
我是马哥,全网累计粉丝上万,欢迎一起交流python技术。
各平台搜索“马哥python说”:知乎、哔哩哔哩、小红书、新浪微博。