目录
引入
一、YOLOv3模型
1、实时目标检测YOLOv3简介
2、改进的实时目标检测模型
二、数据集建立&结果分析
1、数据集建立
2、模型结果分析
三、无人机避障实现
参考文献:
引入
目前对于障碍物的检测整体分为:激光、红外线、超声波、雷达、GPS、机器视觉六种避障技术,其中基于机器视觉的设备廉价获取信息方便,应用广泛。
超声波测距避障的距离一般在5m左右,障碍物表面的材质对于精度有很大干扰!
激光雷达避障主要用光脉冲进行测距,时间测量法和三角测量法是目前经常采用的两种测距方法。相比超声波,雷达测距更远,精度相对较高。在测距过程易导致光污染,影响测距精度,导致避障失败。
超声波和类带避障是被动接受信息,而机器视觉是主动接受光源信息,获取的信息量更大,硬件处理器要求较高。
下面介绍YOLO(You only Look Once)和SIFT(尺度不变特征变换)和两种视觉算法,用于目标检测和图像识别。SIFI在下次!

一、YOLOv3模型
传统方法:如基于Haar小波提取障碍物候选区域,对生成的候选区域进行HOG特征提取,最终采用支持向量机(SVM)实现障碍物判断等方法,特征提取过程繁杂且不可有效提取,甚至出现无效特征。
近年基于深度学习的不断发展,卷积神经网络可实现障碍物特征自动提取,典型的基于区域建议的R-CNN系列的R-CNN、Fast R-CNN和Faster R-CNN的目标检测模型不断提出。无需区域建议(one stage)的目标检测模型只需要一次前向传播运算即可完成目标检测,典型one stage系列的YOLO(You only look once)模型在检测速率上体现出其优越性。
下面的所要介绍的就是基于YOLOv3改进目标检测模型的检测识别!
1、实时目标检测YOLOv3简介
YOLOv3由1x1的卷积层和3x3的卷积层交替连接构成基础网络darknet-53。在每个卷积层之后均连接一个BN层(Batch Normalization)和一个激励函数Leaky Relu——BN层可加速网络收敛、避免训练模型过拟合。
YOLOv3检测模型没有池化层和全连接层,网络通过调整卷积核的步长进行降维。将输入数据通过回归分析得到目标位置和目标所属类别。
YOLOv3沿用YOLO思想,将输入图像分成若干网格,每个网格负责预测目标中心落在该网格内的相应目标,且每个网格有3个相应的滑动窗口,通过训练选择得分值最高的滑动窗口作为最终的目标预测框。其中每个网格对滑动窗口的得分:

YOLOv3将目标分类和定位都转化为回归问题,其损失函数由坐标误差、IOU误差和分类误差3部分组成:
2、改进的实时目标检测模型
YOLO作为one stge系列,检测实时性强,但相比two stage系列准确率较低。原因在于one stage系列将图片输入后经过卷积运算直接输出目标类型和滑动窗口,而two stage在检测之前先生成一些候选区域再进行目标分类和滑动窗口预测。借鉴产生候选区域的思想,改论文采用区域候选网络RPN(Region Proposal Network)生成候选区域对YOLOv3改进——RP-YOLOv3。

RP-YOLOv3将输入图像大小统一归化为416x416,采用基本网络darknet-53进行特征提取,图中虚线部分即为darknet-53基本结构,通过卷积层步长的调整进行降维(分别以stride=2^3,stride=2^4和stride=2^5对输入的图片进行特征提取)获得大小分别为52x52,26x26,和13x13三种尺度的特征图。
然后采用RPN网络通过3x3的卷积核在相应的特征图上进行窗口滑动,判断anchor与ground truth的重叠率IOU与阈值θ的关系,小于阈值则为背景将其舍弃,大于或等于阈值则为前景将其保留,并通过非极大值抑制筛选出相应的proposal(候选区域),将proposal与提取的特征图结合最终获得ROI(感兴趣区域),并将该ROI作为YOLO层的输入。
接着YOLO层通过上采样进行多尺度融合对输入图片中的障碍物的bounding box(滑动窗口)和种类做回归运算,最终输出预测结果。
二、数据集建立&结果分析
1、数据集建立
①原始数据收集:拍照、网上搜索、COCO数据库选取方式获得图片,每种类别1000张左右。
②数据标注:可在python环境下采用labeling对每张图片的障碍物所在区域画框,进行人工数据标注形成障碍物的ground truth。
③数据增强:为了进一步增强数据集的数量和多样性,可采用一些方法如增加噪声、改变亮度或cuntout三种方式对标注后的数据进行增强。(形象理解为是copy了一份加了”滤镜“的数据集,可使数据翻倍和多样性变多)。可拿出总数据集的80%作为训练集,20%作为测试集。

2、模型结果分析
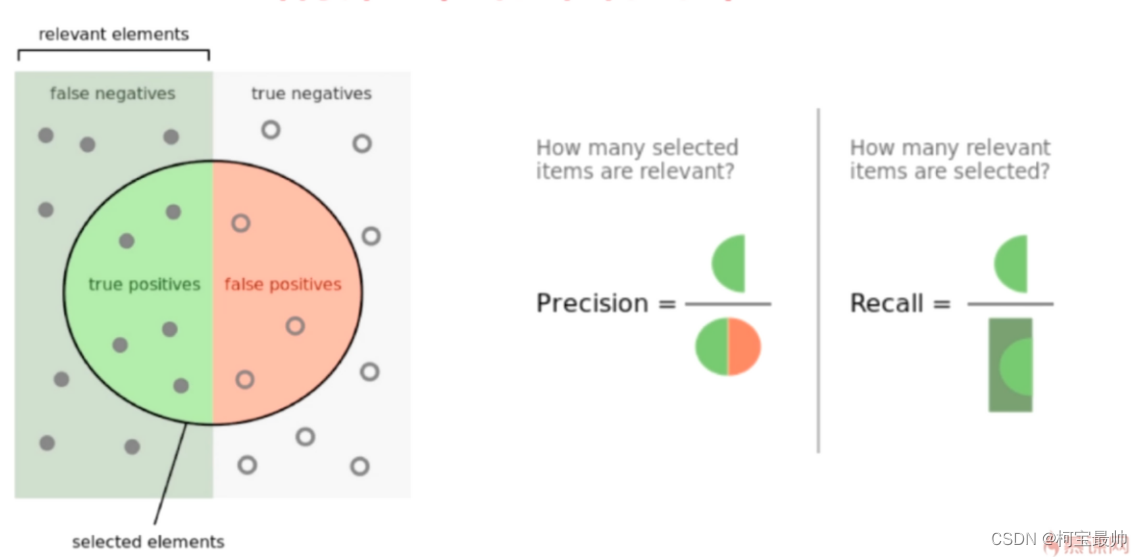
③平均精度AP:
检测系统中,精确率P与召回率R不会同时高,两者常呈现相反变化关系,只看R或P缺乏科学性,AP可起到兼顾精度和召回率的作用,且可以衡量比较单类型数据集训练效果的优劣。
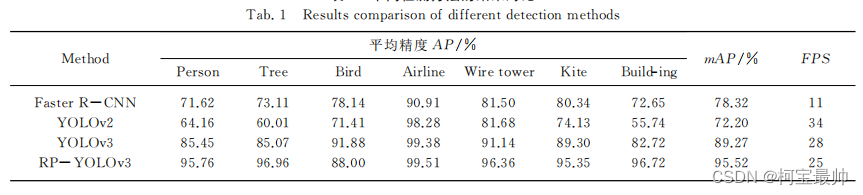
④mAP:
对各个检测算法进行综合比较采用衡量指标mAP,mAP是各个类别AP之和的平均值。n为障碍物类别总数。
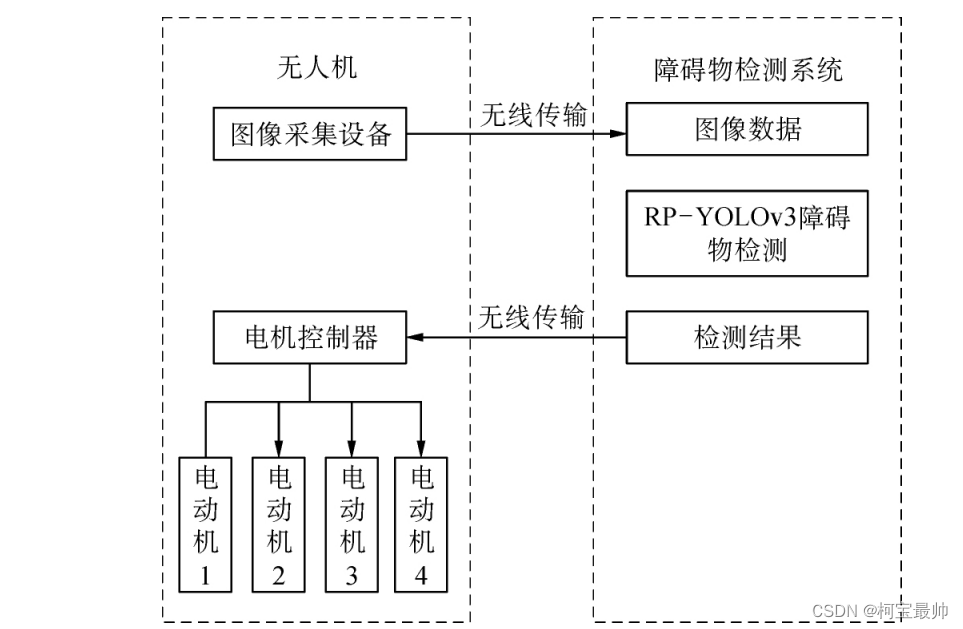
三、无人机避障实现
使用GPU可保证检测的实时性,但是由于GPU的重量和供电等原因放在无人机上不太现实,可采用将摄像头采集的图像无线传输到地面障碍物检测系统的方式。然后通过改进的RP-YOLOv3模型惊醒检测识别,检测结果通过串口传输给后台程序,后台程序通过对无人机各个电机不同的控制方案实现无人机的动作控制。(无人机的上升、下降和偏航运动可以通过控制四个电机各自的转速和转向控制)
SIFT算法及与YOLO的关系和区别见下次!
参考文献:
[1]杨娟娟,高晓阳,李红岭等.基于机器视觉的无人机避障系统研究[J].中国农机化学报,2020,41(02):155-160.DOI:10.13733/j.jcam.issn.2095-5553.2020.02.24.