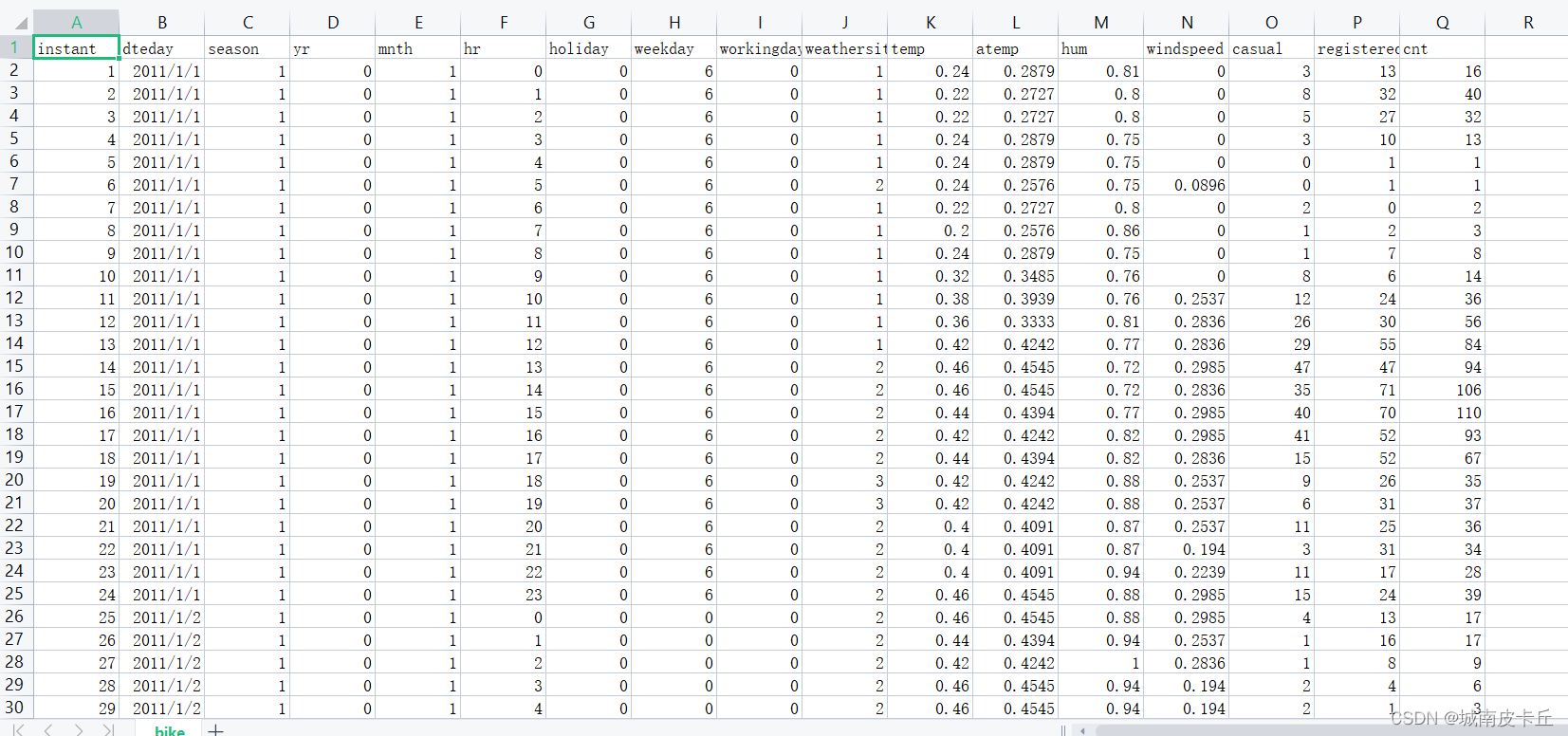
©PaperWeekly 原创 · 作者 | 庄严、宁雨亭
单位 | 中国科学技术大学BASE课题组

论文标题:
Efficiently Measuring the Cognitive Ability of LLMs: An Adaptive Testing Perspective
作者:
Yan Zhuang, Qi Liu, Yuting Ning, Weizhe Huang, Rui Lv, Zhenya Huang, Guanhao Zhao, Zheng Zhang, Qingyang Mao, Shijin Wang, Enhong Chen
单位:
中国科学技术大学、认知智能全国重点实验室
链接:
http://arxiv.org/abs/2306.10512

摘要
ChatGPT 等大规模语言模型(LLM)已经展现出与人类水平相媲美的认知能力。为了比较不同模型的能力,通常会用各个领域的 Benchmark 数据集(比如文学、化学、生物学等)进行测试,然后根据传统指标(比如答对率、召回率、F1 值)来评估它们的表现。
然而,从认知科学 [1] 的角度来看,这种评估 LLM 的方法可能是低效且不准确的。受心理测量学中的计算机自适应测试(CAT)的启发,本文提出了一个用于 LLM 评估的自适应测试框架:并非简单计算答对率,而是根据各个被试(模型)的表现动态地调整测试问题的特征,如难度等,为模型“量身定制”一场考试。
以下图为例,CAT 中的诊断模型 CDM 会根据被试之前的作答行为(对/错)对其能力进行估计。接着,选题算法(Selection Algorithm)会根据该估计值选择最具信息量或最适合他的下一道题,例如选择难度和被试能力最接近的题目。如此循环往复直到测试结束。相比传统评估方法,该框架能用更少的题目更准确地估计模型的能力 [2]。
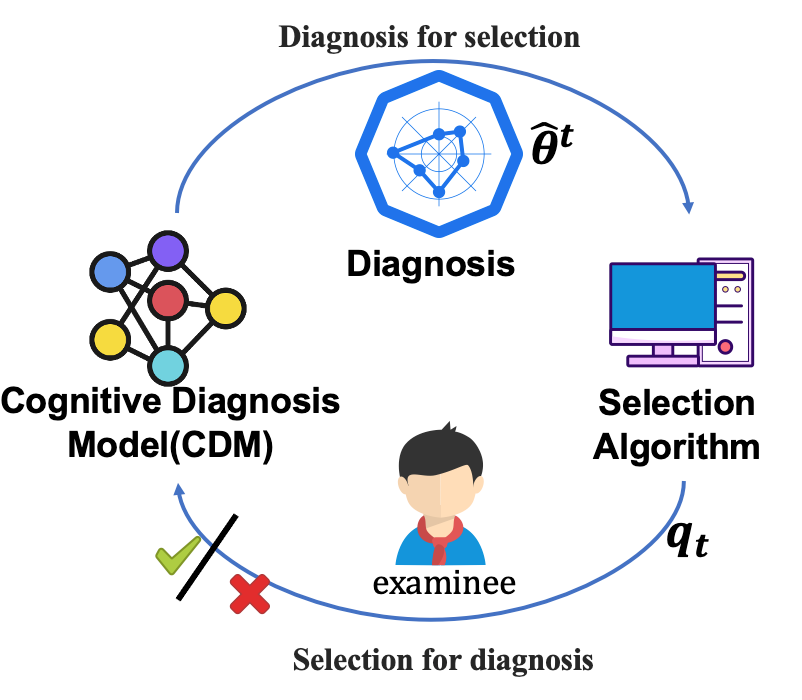
▲ 图1 CAT流程
本文对 6 个商业化的大语言模型:ChatGPT(OpenAI)、GPT4(OpenAI)、Bard(谷歌)、文心一言(百度)、通义千问(阿里)、星火(讯飞)进行细粒度的诊断,并从学科知识、数学推理和编程三个方面对它们进行了认知能力排名。其中 GPT4 显著优于其他模型,已经达到了人类平均水平的认知能力。本文的诊断报告也发现,ChatGPT 表现得像一个“粗心的学生”,容易失误,偶尔也会猜测问题的答案。
“千模千测”——这有可能成为评估大规模语言模型的新范式。

引言
近几个月来, 大规模语言模型(LLM)以其强大的能力颠覆了人们对语言模型的认知。除了传统的 NLP 任务,大模型在写作、编程、作词作曲等各方面展现出难以置信的类人水平 —— 这仅仅是 LLM 能力的冰山一角。
为了充分评估 LLM 认知能力水平,一些最初为人类设计的各类专业或学术考试被用来对模型进行评测:

▲ 图2 传统 LLM 评测方法
然而,依赖这些固定的考试并不高效:(1)它通常需要许多相应领域的专家对 LLM 的每一个回答进行评判/打分,尤其对于主观或创造性的问题。(2)模型回答过程中推理(inference)的开销是巨大的。例如,GPT3 需要在 1750 亿参数的模型上进行推理、GPT4 对每一千 tokens 收费 0.03 美元,并且限制了 API 请求的频率...
因此,本文从认知科学领域中引入了一种新的评估模式——计算机自适应测试(Computerised Adaptive Testing, CAT),建立一个自适应的、高效的评估框架:

▲ 图3 自适应 LLM 评测
本文将 LLM 视为一个学生,为各个模型“定制试卷”以准确评估其能力。相比传统基于答对率的方法,它所需要的题目数量更少(降低专家人工成本)、能力估计更准,是一种更符合认知能力评估的范式。本文贡献如下:
1. 正式将心理测量学中的 CAT 引入 LLM 的评估中,分析发现每个模型的试卷中有 20%~30% 的题目是不同的,这部分题目对测试的自适应性和个性化至关重要。同时,在相同的能力评估精度下,仅需要传统评估方法 20% 的样本/题目数量。
2. 模型 vs 人类:本文将 ChatGPT 与不同能力水平人类进行了比较,发现它在动态规划和搜索方面的编程能力已经超越了高水平的大学生。同时,ChatGPT 经常表现得像一个“粗心的学生”,很容易失误,偶尔也会靠猜。
3. 模型 vs 模型:本文研究了 6 个有代表性大模型,并得到它们在学科知识、数学推理和编程水平三个方面的细粒度诊断报告,发现 GPT4 显著超越其他大模型,其数学推理能力已经接近中等水平的高中生。

LLM 自适应评测框架
计算机自适应测试(CAT)是一种高效的、个性化的测试模式,已被广泛应用于各类标准化考试中(如 GRE、GMAT)。它的首要目标是在准确评估被试者能力的同时尽可能缩短考试长度。相比传统的纸笔测试,CAT 的测评效率更高。本节将详细介绍本文提出的两阶段 LLM 自适应评测框架:题库构建和自适应测试。
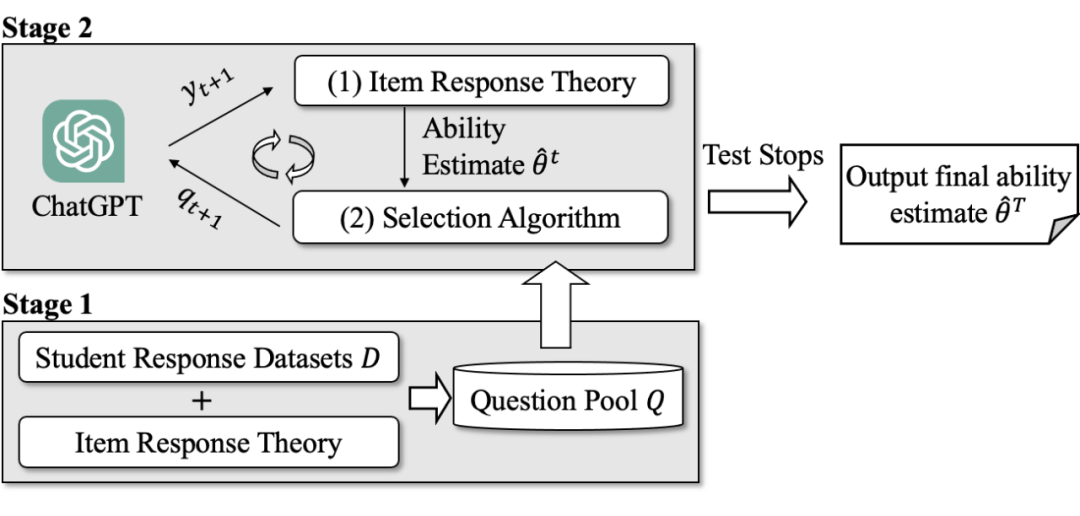
▲ 图4 LLM 自适应评测框架
3.1 阶段1:题库构建
首先需要为自适应测试构建一个多样且高质量的题库:准备好要目标领域/学科的题目集 ,题库构建的目标就是校准所有题目的参数特征(如难度、区分度等)。由于本文需要将人和 LLM 进行对比,还需要收集人类在这些题目上的作答记录。本文选择测量心理学中经典认知诊断模型——项目反应理论(Item Response Theory, IRT)来对题目参数进行校准:
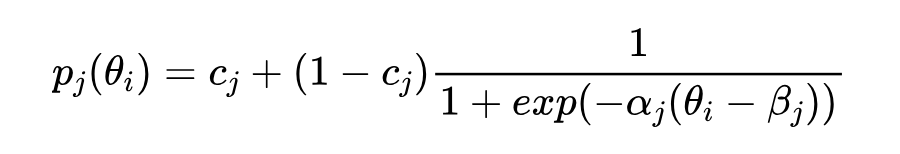
其中 表示能力为 的被试者答对题目 的概率。每个题目 有三个参数:难度 、区分度 、猜测因子 。
通过在作答记录 上进行参数估计,得到所有 个试题的参数 ,以及 个真实人类的估计能力值 ,可以后续直接用于与 LLM 进行比较。
IRT 基本假设是:不同的题目对于能力评估的重要性并不相同。例如,大模型 A 和 B 在某个 Benchmark 中的答对率分别为 0.88 和 0.89,他们的差距可能并不像看起来那么小,甚至并不准确。因为(1)大量简单的问题可能会淹没困难的问题,从而导致 B 无法显著地体现出其优越性;(2)数据集中或存在标注错误/噪声,可能导致这些传统指标失效。下面利用估计出的题目参数列举一些例子。
1. 难度 :当被试能力 保持不变时,难度 越大,答对的概率越小。下图是本文中的 MOOC 数据集中估计出最难和最简单的题目。解决问题 需要 ChatGPT 理解 PAC,这是计算学习理论中一个非常难理解的知识点。相比之下,最简单的问题和机器学习中的“感知机”有关,初学者也可以很容易地解决。

▲ 图5 难度
2. 区分度 :对于区分度高的问题,能力的微小变化可能会引起答对率的较大变化,因此这些题目可以更好地区分具有相似能力的被试。下图低区分度 非常简单,而且这种“垂直平分线”问题有固定的套路,很难真正区分不同能力的被试。高区分度问题 虽然也不难,但需要对原问题进行转换,并熟练掌握“圆与圆之间的位置关系”的相关知识。

▲ 图6 区分度
3. 猜测因子 :它主要反映低能力被试能答对的概率,可以简单理解为猜对该题的概率。对于下图 的 题,甚至不需要被试掌握任何编程语言的知识,就可以用常识“猜”对。然而,为了答对 最小的 题(下),ChatGPT 需要掌握并理解 JAVA 中 Interface 的定义和用法:Interface 是一个完全抽象的类',并且能够选出所有不相关的选项;如果没有熟练掌握 “Interface” 的概念,想要猜对几乎不可能。

▲ 图7 猜测因子
3.2 阶段2:自适应测试
题库构建后,将正式进行自适应测试。主要包含两个核心模块:认知诊断模型和自适应选题算法。首先,诊断模型会根据 LLM 之前的作答情况对其能力进行估计。接着,选题算法将根据某种的信息量度量函数选择下一个对被试最有价值/最适合的题目。这两个算法交替工作,直到满足某个停止规则。
1. 使用认知诊断进行 LLM 能力估计:与阶段 1 保持一致,本文使用 IRT 来估计 LLM 的当前能力 :在第 t 轮测试后,利用极大似然估计(交叉熵)根据 LLM 前 步的作答情况(题目 , 正确性 ) 估计出当前能力值 。
能力估计值 的渐进分布 [3] 是以真值 为均值, 为方差的正态分布(下图),其中 为 Fisher 信息量。因此为了提高能力估计的效率(减小测试长度),减小能力估计的不确定性(方差)是至关重要的。
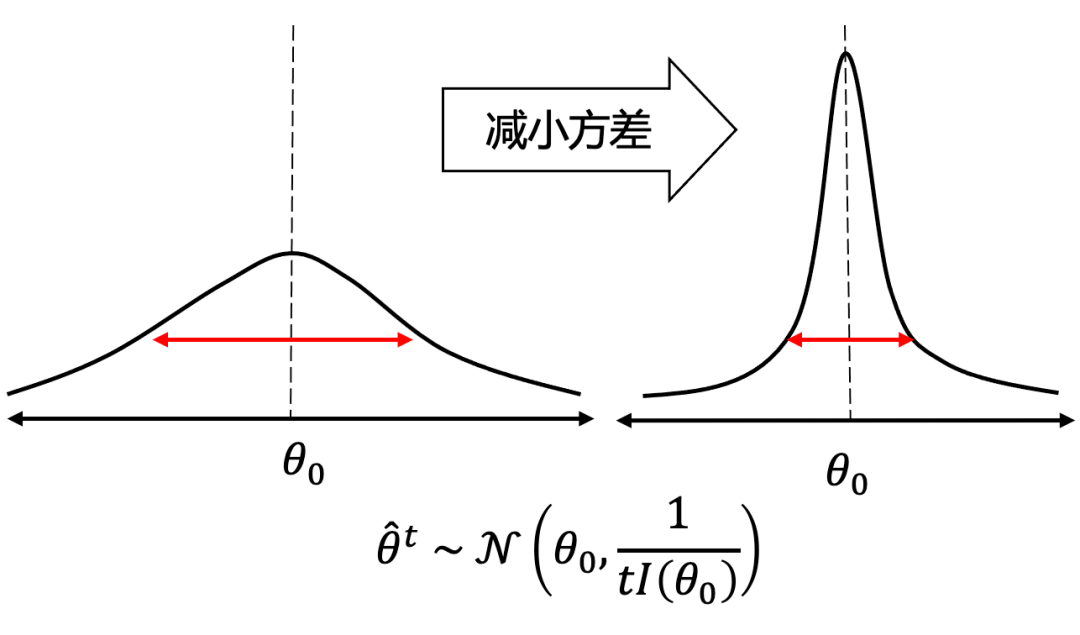
▲ 图8 能力估计值的统计特性
2. 自适应选题:为了提高能力估计的效率、减小方差,本文采用最大化 Fisher 信息量的选题算法。在每一轮测试时,根据 LLM 当前能力估计值,选择能够使得 Fisher 信息量 尽可能大的下个题目 给模型回答:
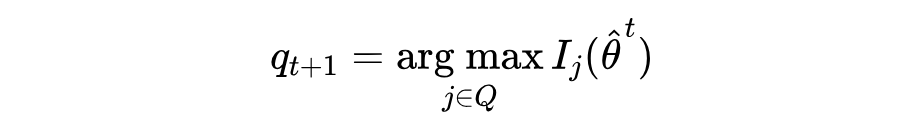
研究发现 [4]:Fisher 信息量选题方法倾向于选择(1)高区分度且(2)难度接近当前能力估计值的题目。因此 Fisher 方法不仅考虑了题目的质量(即区分度),也考虑了问题的难度对 LLM 的匹配性。例如,当 ChatGPT 在第 轮回答正确时,选题算法将为其选择一个难度更大的问题,反之亦然。这就是为什么许多能力水平高的 GRE 考生发现考试中题目变得越来越难的原因。

评测效率与可靠性
本文通过上述介绍的自适应测试框架对各个 LLM 进行评测。LLM-CAT-专家 的交互界面如下图所示。

▲ 图9 LLM-CAT-Expert 交互测试框架
评测效率:本文通过仿真实验来验证该框架的评估效率。本文随机生成 100 名被试的能力真值 ,并进行能力评估的模拟。计算每一轮的能力估计 和真实能力 的 MSE 误差(下图),发现:与使用固定 Benchmark 测试集(即从数据分布中 Random 采样)相比,自适应评估方法在相同的估计误差下最多只需要 20% 的题量。
由于 20 足以满足一般自适应测试,本文将最大长度固定为 20,并根据信息量指标 [5] 自适应调整测试长度。因此,相较于传统评估中需要 LLM 回答上百道题目 [5],该方法可以挑选出真正有价值的问题,最多只需要问模型 20 个问题,特别是对于需要大量专家评分的模型测试,它大大降低人工成本和模型推理开销。
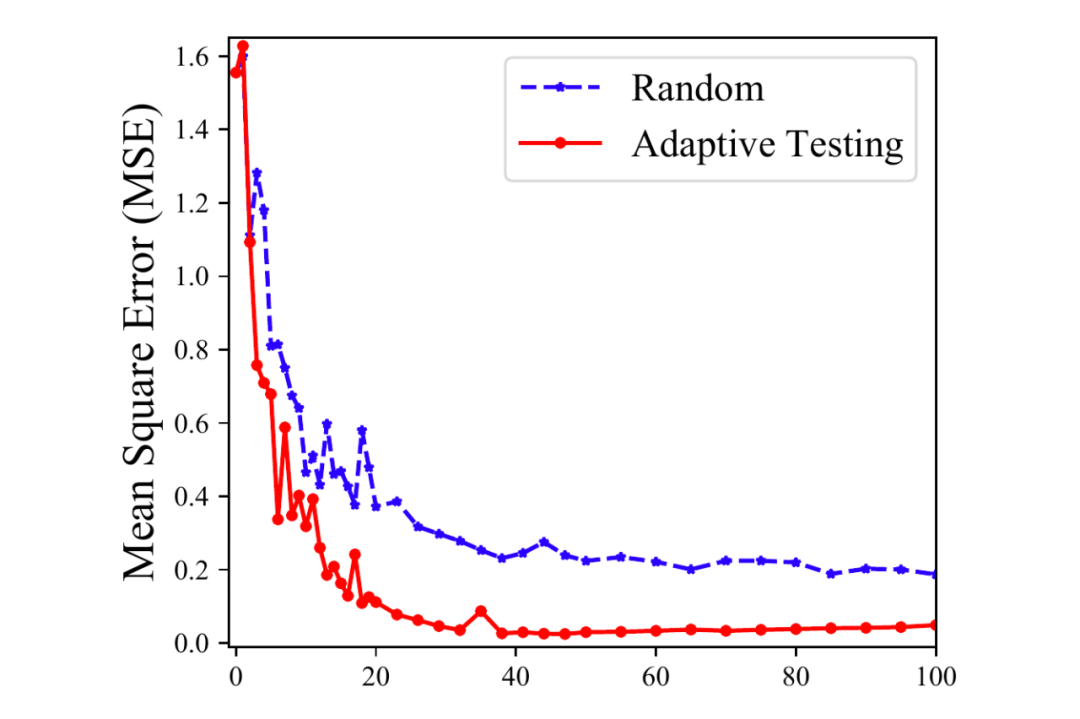
▲ 图10 自适应选择和随机选择的能力估计误差
自适应性:为验证 CAT 能否根据模型能力自适应地选择适合的问题,本文用 Jaccard 相似度来衡量任意两个模型所作答的题目集之间的相似性:,其中 和 代表两个不同的题目集合/试卷。下图展示了 CAT 为各个 LLM 定制的试卷相似度。几乎所有 Jaccard 值都在 0.6 左右,表明至少 20-30% 的问题是不同的,这部分题目是实现测试自适应性的关键。其余 70-80% 的题目是相同的,对于评估所有 LLM 都有价值。这两部分共同组成了一份试卷,以高效评估模型。
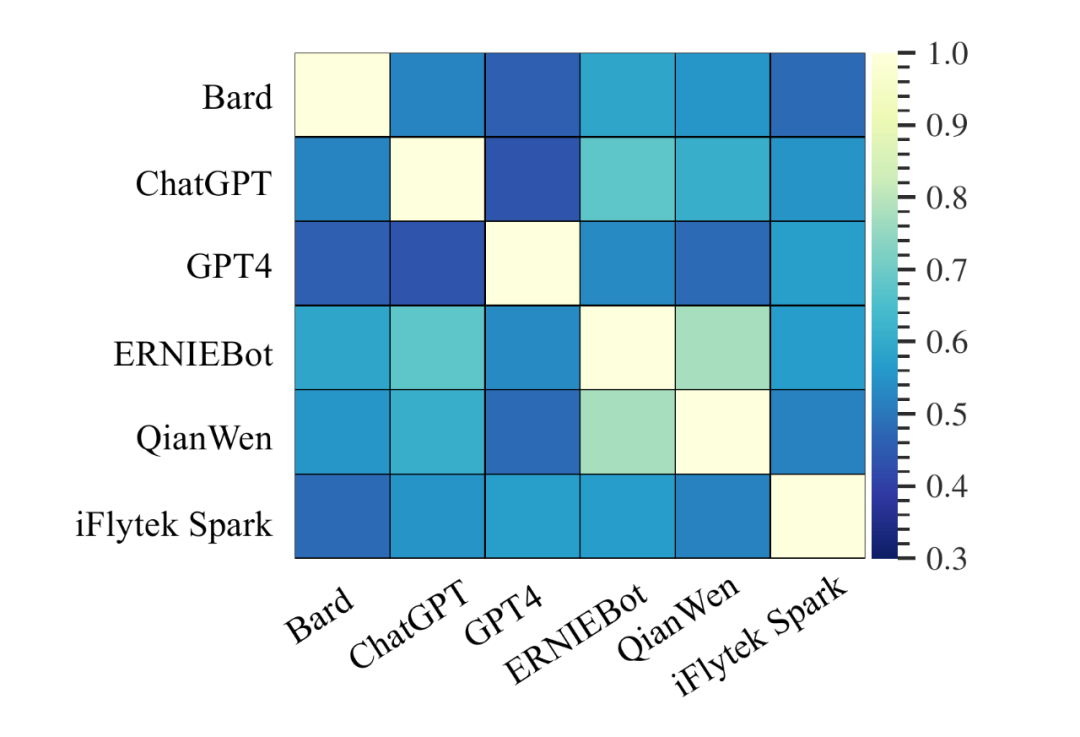
▲ 图11 试卷的Jaccard相似度
评测可靠性:为了验证用于人类的 CAT 框架是否可以用于 LLM,本文研究了它的可靠性(SE 曲线 [5])。在 CAT 中,SE值通常是指能力估计 的标准差,它反映了能力估计的精度:。较小的 SE 表示更精确且更可靠的估计 [7]。下图显示了 ChatGPT(蓝色)和 100 名学生(黑色)测试过程中的 SE 变化:ChatGPT 的 SE 曲线虽有波动,但是比真实学生更快、更容易收敛。
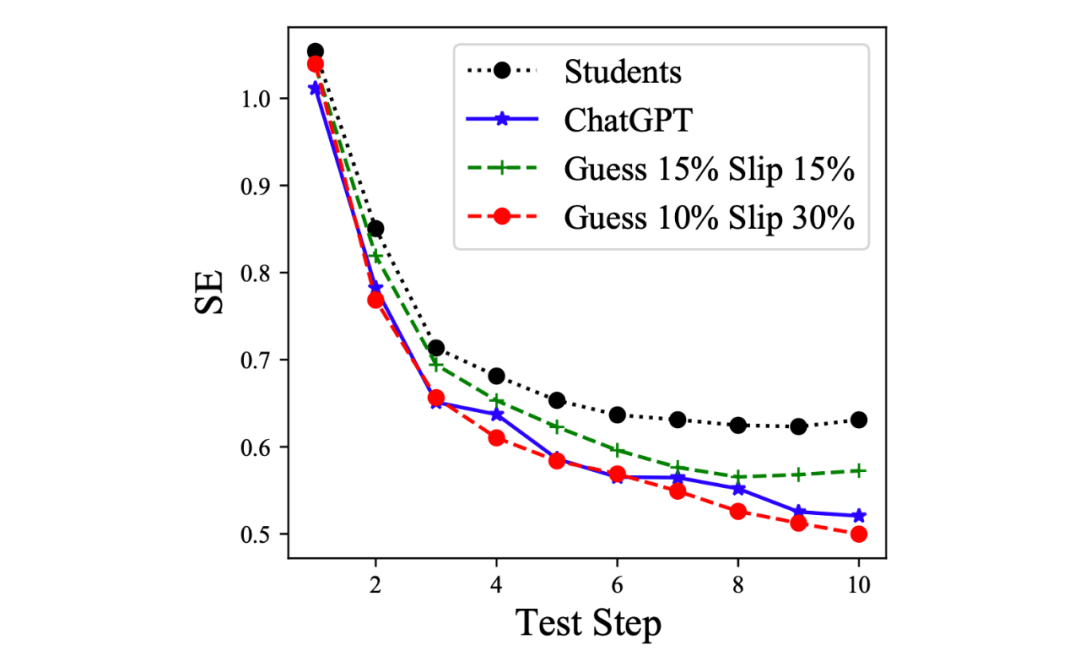
▲ 图12 ChatGPT 和学生的 SE 曲线
为探究 ChatGPT 与人类的相似性,本文在学生的测试过程中添加了猜测和失误因素:(1)猜测因素:即使被试没有掌握,仍有概率答猜对;(2)失误因素:即使掌握了该题,仍有小概率失误答错。因此,Guess10% 表示正确性标签从错误变为正确的概率为 10%,而 Slip10% 表示标签从正确变为错误的概率为 10%。有趣的是,ChatGPT 的 SE 曲线非常接近 Guess=10%、Slip=30% 的学生(红色)。由此,本文推断 ChatGPT 更像一个“粗心的学生”,容易失误(30%)并且偶尔会去猜答案(10%)。

诊断报告
本文选择了国内外较有代表性的 6 个 instruction-tuned LLM 进行评测:ChatGPT、GPT4、谷歌 Bard、百度文心一言(ERNIEBOT)、阿里通义千问(QianWen)、讯飞星火(Spark)。并将他们与高水平(High-Ability)、中等水平(Mid-Level)的人类学生进行比较。
数据集:本文选择学科知识、数学推理、编程三个领域为例对 LLM 进行细粒度评测,分别对应三个数据集:MOOC、MATH 和 CODIA。
学科知识水平(MOOC):MOOC 是目前最知名的在线学习平台之一,本数据集收集了 1.5 万大学生对计算机科学中不同知识概念(如人工智能、计算机系统等)的回答记录。
数学推理水平(MATH):该数据通过智学网收集,其中包含了超过 10 万名高中生的数学考试数据。
编程水平(CODIA):该数据由中国科学技术大学自主研发的在线编程平台 CODIA(https://code.bdaa.pro/)。提供,其中包含了来自 120 所大学的大学生的编程提交数据。
5.1 ChatGPT VS 人类
本文以 ChatGPT(蓝色)为例对其从上述三个方面进行高效诊断,并和高水平学生(红色)进行比较:
1. 编程水平:尽管 ChatGPT 在官方报告和海量用户case中已经展示出其惊人的编程水平,但它并非全能,并不擅长所有类型的问题。本文使用 CODIA 平台对 ChatGPT 的编程能力中“动态编规划和贪心算法”、“搜索”、“数学问题”、“数据结构”、“树和图论”进行评估。ChatGPT 表现最佳的是“搜索”、“动态规划和贪心算法”。它在这些类型的问题上超过高水平大学生。然而,“数据结构”、“树和图论”是其编程能力上的短板。因此,下次让 ChatGPT 写代码时,可以避免这些类型;而如果你遇到关于动态规划的问题,则可以放心交给 ChatGPT。
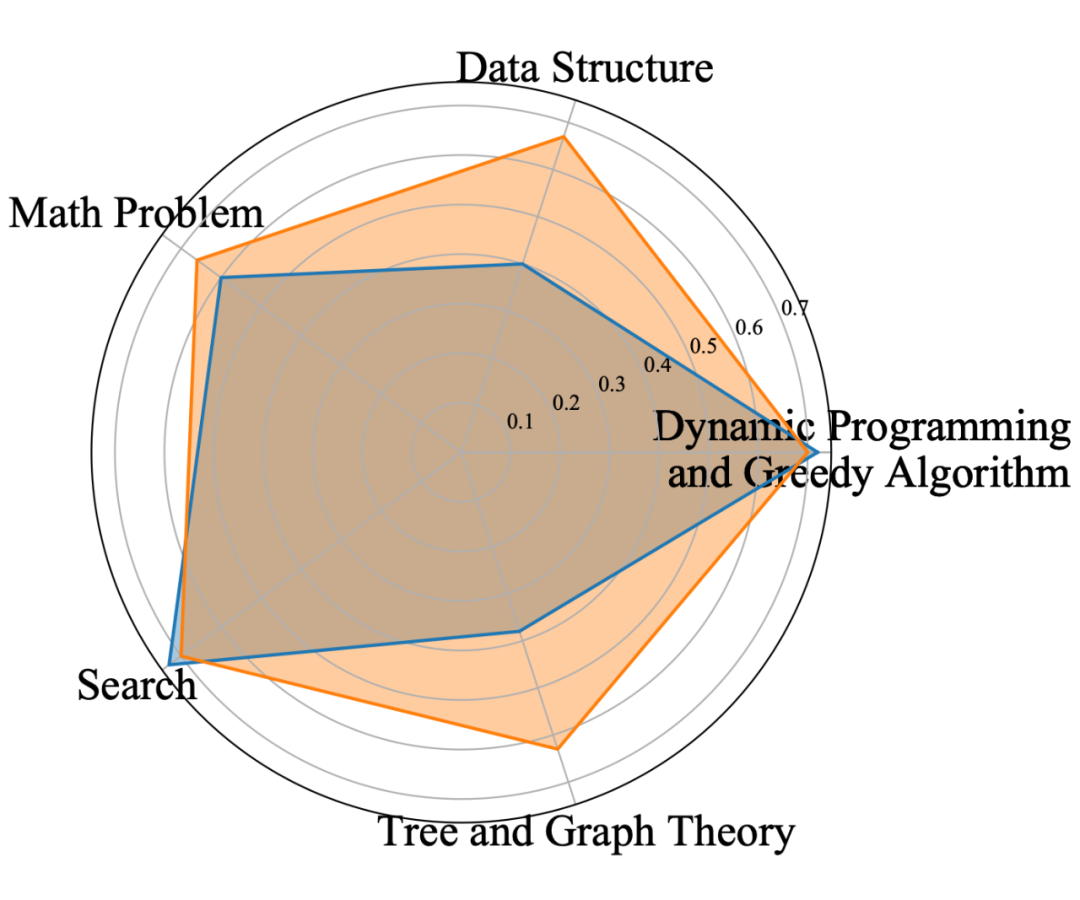
▲ 图13 编程水平对比:ChatGPT(蓝)vs 学生(红)
2. 学科知识水平:如下图,ChatGPT 在“算法”和“机器学习”这两个知识点上的能力水平显著高于高水平学生。然而,它在编程语言方面相对较弱,这似乎与人们对其的认知不太相符。为了探索原因,本文在下图右侧展示了一个关于编程语言的例子。这是一道非常基础的问题,但是 ChatGPT 却答错了,类似的例子在 ChatGPT 的考试中并不罕见。这说明它在掌握和理解编程语言的一些基础概念方面并不准确。而结合它在 CODIA 上惊人的编码水平(上图),本文有理由相信:ChatGPT 更像是一个 “实干家”,而不是一个 “书呆子”。
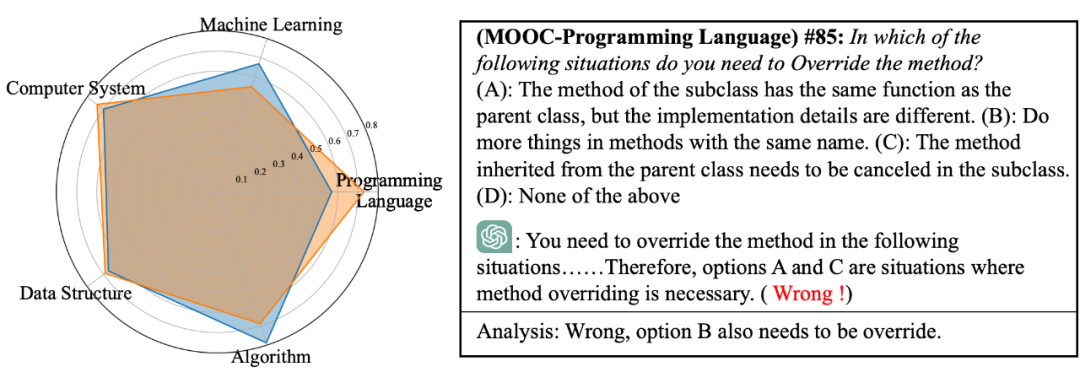
▲ 图14 学科知识水平对比:ChatGPT(蓝)vs 学生(红)
3. 数学推理水平:ChatGPT 的数学推理能力与人类的数学推理能力仍有相当大的差距:在“概率与统计”、“排列与组合”以及“几何”的问题的上尤其差;在“函数”、“方程和不等式”方面的表现相对好一些。因此,对于方程、函数这种有固定解题套路的基本计算问题,ChatGPT 是合格的。但面对现实场景中的推理问题[7](例如,概率和统计、排列组合)显然还差得远。
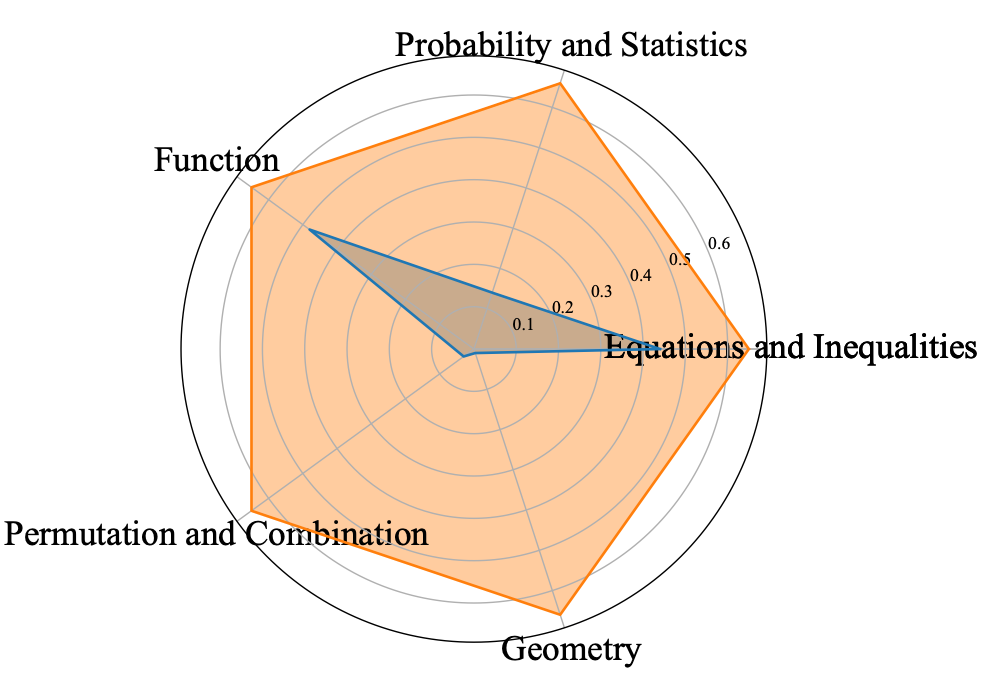
▲ 图15 数学推理能力对比:ChatGPT(蓝色) vs 学生(红色)
5.2 LLM排名
本文在国内外 6 个有代表性的商业化 LLM 进行了 CAT 测试,并同时与不同水平的人类学生进行比较:
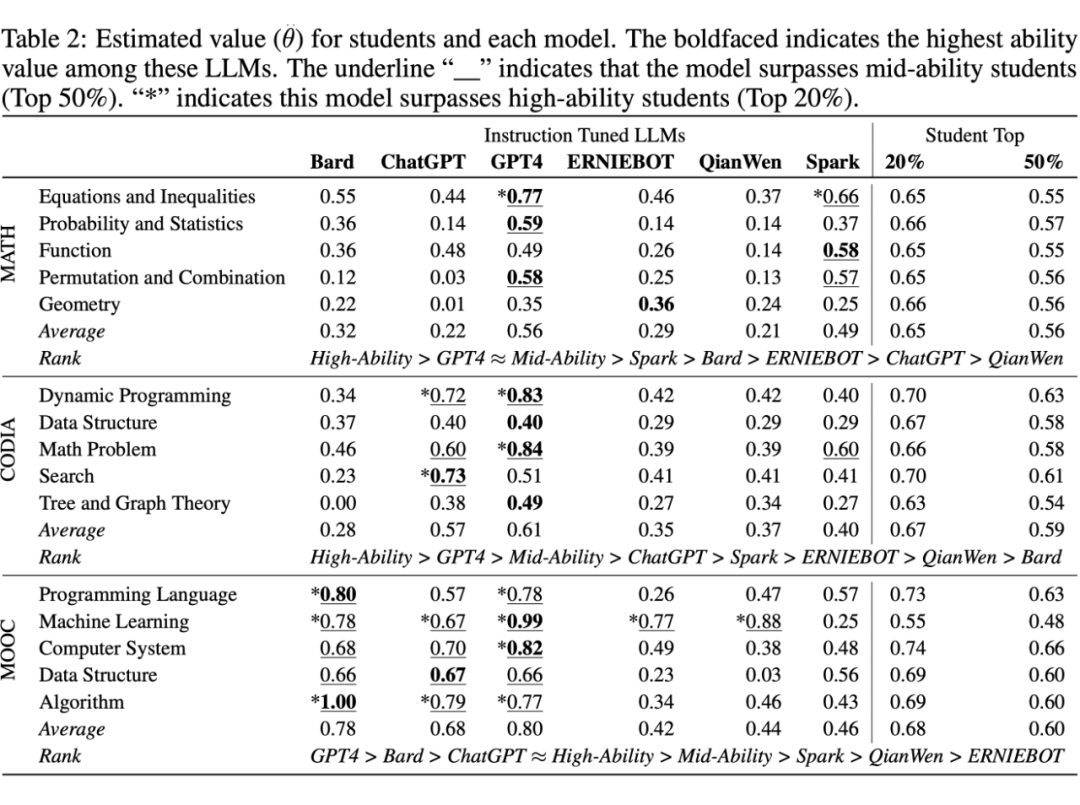
▲ 表1 不同 LLM 及不同水平学生能力诊断结果
数学推理:高水平高中生 > GPT4 ≈ 中等水平高中生 > 星火 > Bard > 文心 > ChatGPT > 千问
编程:高水平大学生 > GPT4 > 中等水平大学生 > ChatGPT > 星火 > 文心 > 千问 > Bard
学科知识:GPT4 > Bard > ChatGPT ≈ 高水平大学生 > 中等水平大学生 > 星火 > 千问 > 文心
GPT4 在学科知识、数学推理、编程水平上明显优于其他 LLM。其学科知识水平几乎在每个知识点上都超过了高水平大学生(Top20%)。
每个 LLM 都有其自己的“特长”。例如编程中,GPT4 擅长“动态规划”和“数学问题”;ChatGPT 更擅长“搜索”问题;星火平均编程水平低于 GPT4/ChatGPT,但是用编程解决数学问题是它的强项。因此,尽管这些 LLM 没有公布它们预训练所用数据的配比和具体细节,本文有理由推断,ChatGPT/GPT4 可能在训练阶段使用了更多的编程相关数据,而星火则使用了更多的数学学科数据。
大模型要实现媲美人类的数学推理仍有很长的路要走。根据 CAT 诊断的结果,即使最强的 GPT4,其推理能力也接近于中等水平的高中生。毕竟 LLM 的本质还是数据驱动的概率生成模型,并非像人类那样去思考和推理。因此,基于或模仿人类的认知结构 [9],或许是未来提升 LLM 推理能力的“捷径”。

总结
大语言模型正逐步改变人们日常的工作和生活方式。越来越多的人尝试探索 LLM 能力边界,让它们完成传统 NLP 时代难以想象的事情,如生成代码、制作 PPT、作诗作曲等等。因此,如何科学有效地诊断并分析 LLM 的能力显得愈发重要。本文尝试引入原本用于人类的认知能力评估框架——计算机自适应测试,来对 LLM 进行评估。在相同的评估精度下,CAT 需要的测试数据更少,极大地降低了 对 LLM 评估的人工成本和计算开销。
原论文由于中国科学技术大学计算机学院 BASE(http://base.ustc.edu.cn/)课题组撰写。该课题组聚焦于将大数据和人工智能技术应用于教育科学,包括:教育资源理解、认知诊断与学生建模、个性化教育服务等。本文希望 CAT 这一科学的评估范式可以促进 LLM 的研究与迭代,欢迎交流探讨!

参考文献
[1] Liu Q. Towards a New Generation of Cognitive Diagnosis[C]//IJCAI. 2021: 4961-4964.
[2] Zhuang Y, Liu Q, Huang Z, et al. A Robust Computerized Adaptive Testing Approach in Educational Question Retrieval[C]//Proceedings of the 45th International ACM SIGIR Conference on Research and Development in Information Retrieval. 2022: 416-426.
[3] Sheldon M Ross. A first course in probability. Pearson, 2014.
[4] Zhuang Y, Liu Q, Huang Z, et al. Fully Adaptive Framework: Neural Computerized Adaptive Testing for Online Education[C]//Proceedings of the AAAI Conference on Artificial Intelligence. 2022, 36(4): 4734-4742.
[5] C. Wang, D. J. Weiss, and Z. Shang. Variable-length stopping rules for multidimensional computerized adaptive testing. Psychometrika, 2018.
[6] OpenAI. Gpt-4 technical report, 2023.
[7] Wim J Van der Linden and Cees AW Glas. Elements of adaptive testing, volume 10. Springer, 2010.
[8] Lin X, Huang Z, Zhao H, et al. Learning Relation-Enhanced Hierarchical Solver for Math Word Problems[J]. IEEE Transactions on Neural Networks and Learning Systems, 2023.
[9] Liu J, Huang Z, Lin X, et al. A cognitive solver with autonomously knowledge learning for reasoning mathematical answers[C]//2022 IEEE International Conference on Data Mining (ICDM). IEEE, 2022: 269-278.
更多阅读




#投 稿 通 道#
让你的文字被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学术热点剖析、科研心得或竞赛经验讲解等。我们的目的只有一个,让知识真正流动起来。
📝 稿件基本要求:
• 文章确系个人原创作品,未曾在公开渠道发表,如为其他平台已发表或待发表的文章,请明确标注
• 稿件建议以 markdown 格式撰写,文中配图以附件形式发送,要求图片清晰,无版权问题
• PaperWeekly 尊重原作者署名权,并将为每篇被采纳的原创首发稿件,提供业内具有竞争力稿酬,具体依据文章阅读量和文章质量阶梯制结算
📬 投稿通道:
• 投稿邮箱:hr@paperweekly.site
• 来稿请备注即时联系方式(微信),以便我们在稿件选用的第一时间联系作者
• 您也可以直接添加小编微信(pwbot02)快速投稿,备注:姓名-投稿

△长按添加PaperWeekly小编
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
·
·