仅涉及后端,全部目录看顶部专栏,代码、文档、接口路径在:
【Lilishop商城】记录一下B2B2C商城系统学习笔记~_清晨敲代码的博客-CSDN博客
全篇会结合业务介绍重点设计逻辑,其中重点包括接口类、业务类,具体的结合源代码分析,读起来也不复杂~
谨慎:源代码中有一些注释是错误的,有的注释意思完全相反,有的注释对不上号,我在阅读过程中就顺手更新了,并且在我不会的地方添加了新的注释,所以在读源代码过程中一定要谨慎啊!
目录
A1.系统配置
B1.M端(属于显式操作)
B2.B、S端(属于隐式操作)
A2.行政区划
B1.M端(属于显式操作)
B2.cosumer模块(公共模块)
A3.物流公司
B1.M端(属于显式操作)
B2.S端(属于显式操作)
B3.B端(属于显式操作)
A4.滑块验证码
B1.M端(属于显式操作)
B2.cosumer模块(公共模块)
A5.敏感词过滤
B1.M端(属于显式操作)
B2.敏感词过滤器(属于隐式业务操作,可以理解为工具类,也可以说是算法)
敏感词集合:
过滤逻辑:
过滤逻辑相关类:
敏感词过滤的使用:
系统配置属于整个项目的配置,可以说是贯穿整个项目无论哪一端,通常来说,是由运营端M进行管理,即增查改删,而店铺端S、买方端B是查看使用。
所以很多模块从页面显式出来的操作都是简单的增查改删,但是他们大多也包含隐藏的逻辑,例如商品发布时的敏感词过滤是借助于敏感词操作的,店铺端的物流公司是借助于M端的物流公司操作的。
所以简单的CRUD接口就一笔带过了,重点介绍复杂业务接口及业务~~~
A1.系统配置
首先,系统配置有很多种,每种都包含很多子配置属性,我们可以把每一种配置类型当成一份表单,例如shop项目里面有基础配置、商品设置、订单配置、积分设置、提现设置等等,基础配置里面又有平台logo、买方端logo等等。这样的配置表单大多只需要一份,并且子配置属性还大多不一样,如果我们每种类型的配置表单都创建一个数据表进行存储会很浪费资源。
如下图:
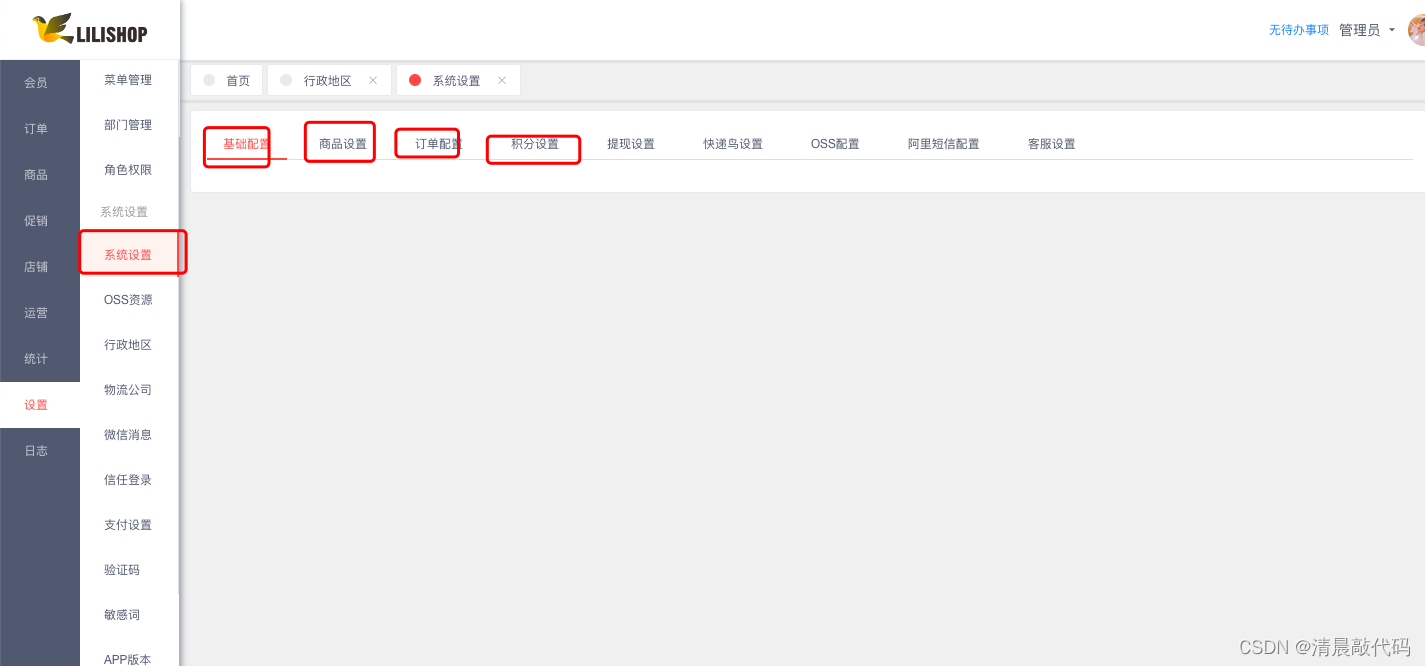
所以在shop项目中,将这种将分散的、需要修改的、单份的配置放到一起,放到了一张表里面,通过K:V键值对的方式存储,K是每种类型配置的标识,V是配置数据,用json类型存储,也是一种子属性对应一个值。
这样如果需要针对某类型配置进行修改,就可以通过标识获取json值,然后将json类型转成对象返回(也可以前端直接转换json为对象)
可以看数据库表li_setting。
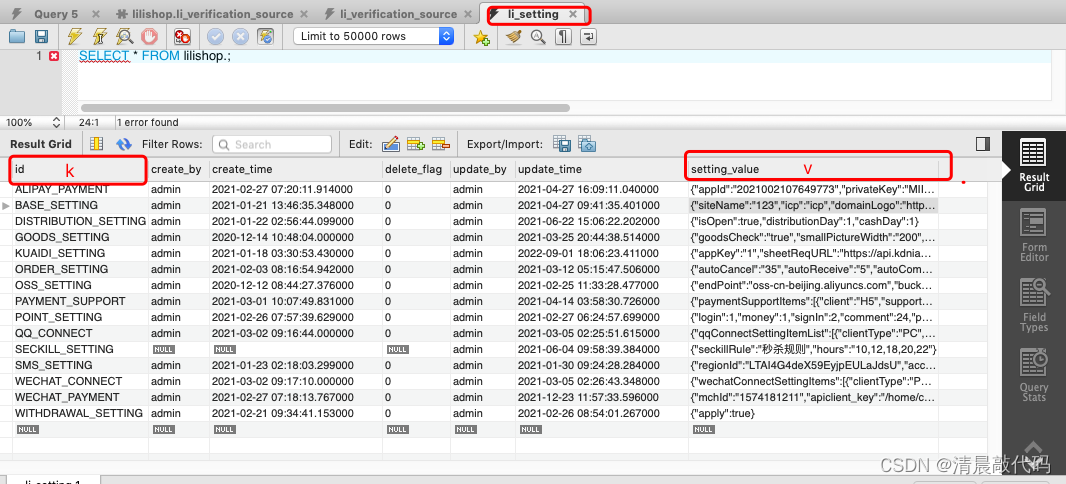
B1.M端(属于显式操作)
对于运营人员来说,系统配置的类型及属性字段不会轻易更改(更改一定会涉及到前后端修改),只有属性字段的值会需要修改,所以不需要增删接口,只需要针对某种类型的属性进行查看和修改即可。
查看的接口种,为了方便前端操作,我们可以通过标识拿到json后使用hutool的JSONUtil.toBean(String,Class)转成对象,返给前端,这就需要后端添加每种类型的pojo类。
- 编辑某种配置表、查看某种配置表
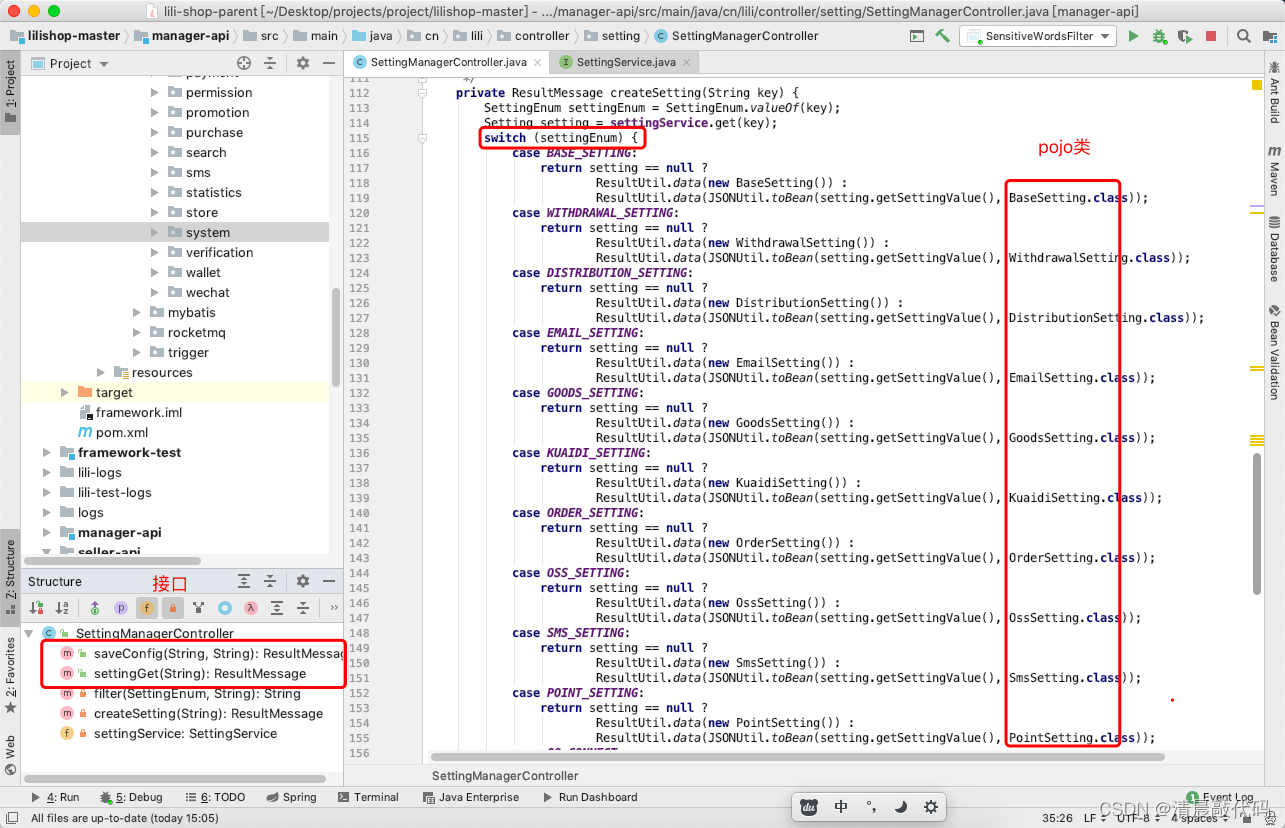
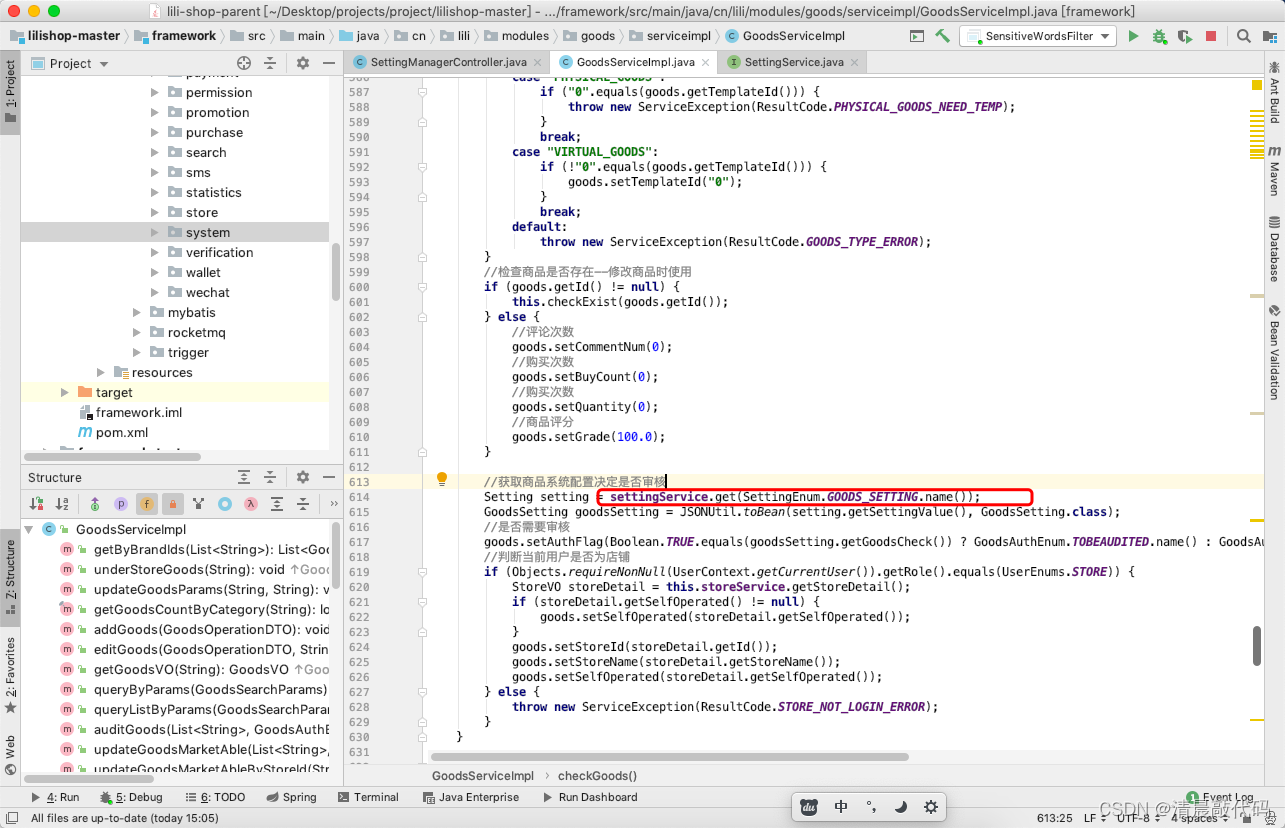
B2.B、S端(属于隐式操作)
对于B、S端端,就不会出现操作接口了,他们就不能修改这些配置。并且根据业务来说,前端页面操作时也不需要查看,只有在某类业务操作中会用到这些配置。例如发布商品时,在service的操作中会获取 GOODS_SETTING,进而判断是否需要审核。
直接就在后端的service里面调用了~
A2.行政区划
系统里面的行政区划用于地址的文字显示、物流的定位,所以不仅仅是地址文字显示,所以shop系统直接使用的高德的行政区划数据(这个需要向高德申请购买才能够调用他提供的公共接口,来拿到行政区划数据并使用~)
B1.M端(属于显式操作)
M端就是增查改删,li_region 数据表也没有特别复杂,就是同步时清除本地数据时不用清除省级(parent_id = 0 的),因为省级可不会轻易变动~~~
删除某个地区后,其名下的子级就都查询不到了哦,并且关联改地区的收货地址、运费模板等的信息就都查询不到了,会产生错乱,所以不要轻易删除这样的信息。
- 同步高德的数据、通过id获取其子地区、更新某个地区、删除某个地区

B2.cosumer模块(公共模块)
由于B、S端都会用到查询行政区划的功能,所以抽成公共模块。
- 点地图获取地址信息、根据名字获取地区地址id、通过id获取子地区、获取所有的省-市

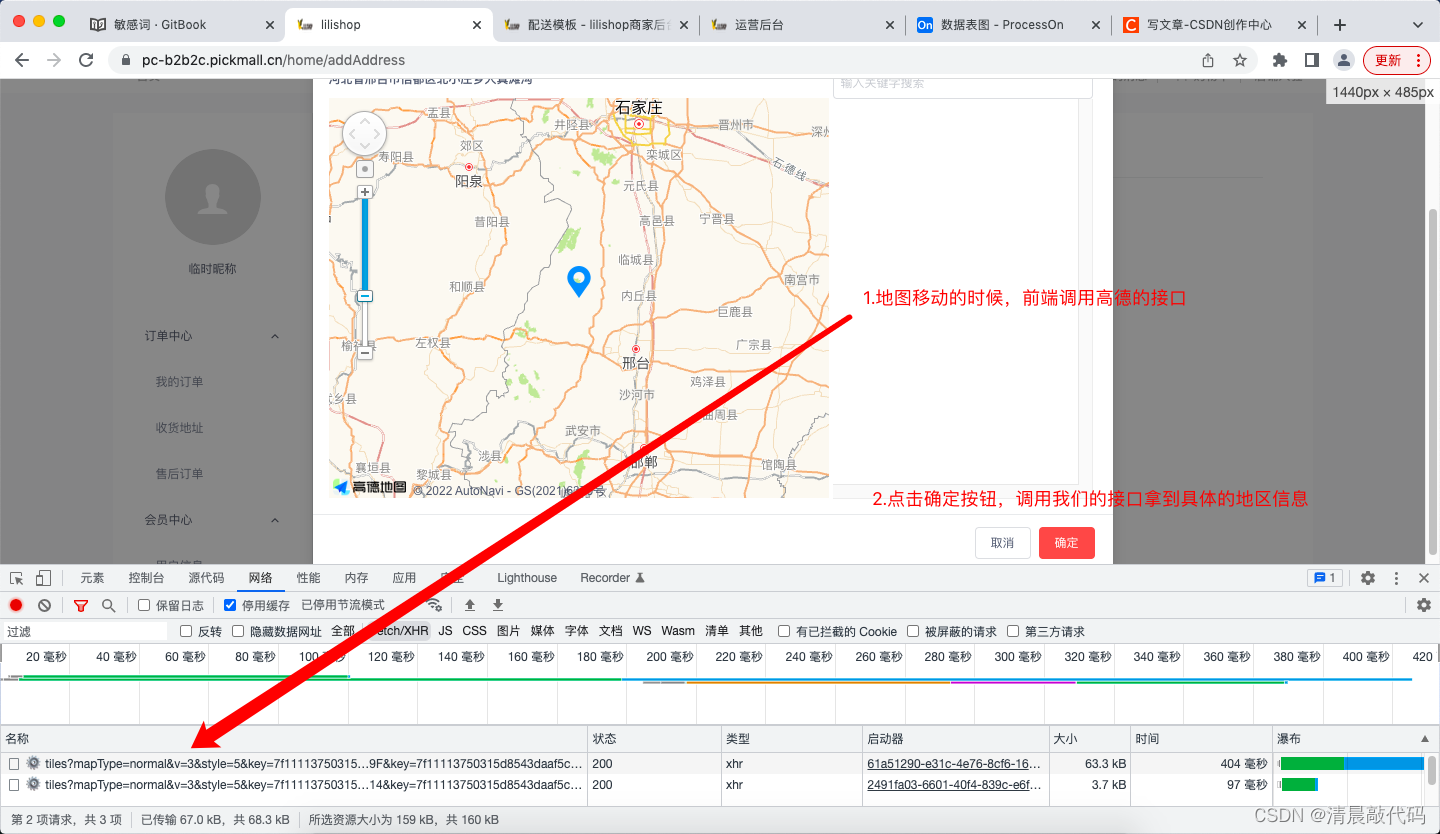
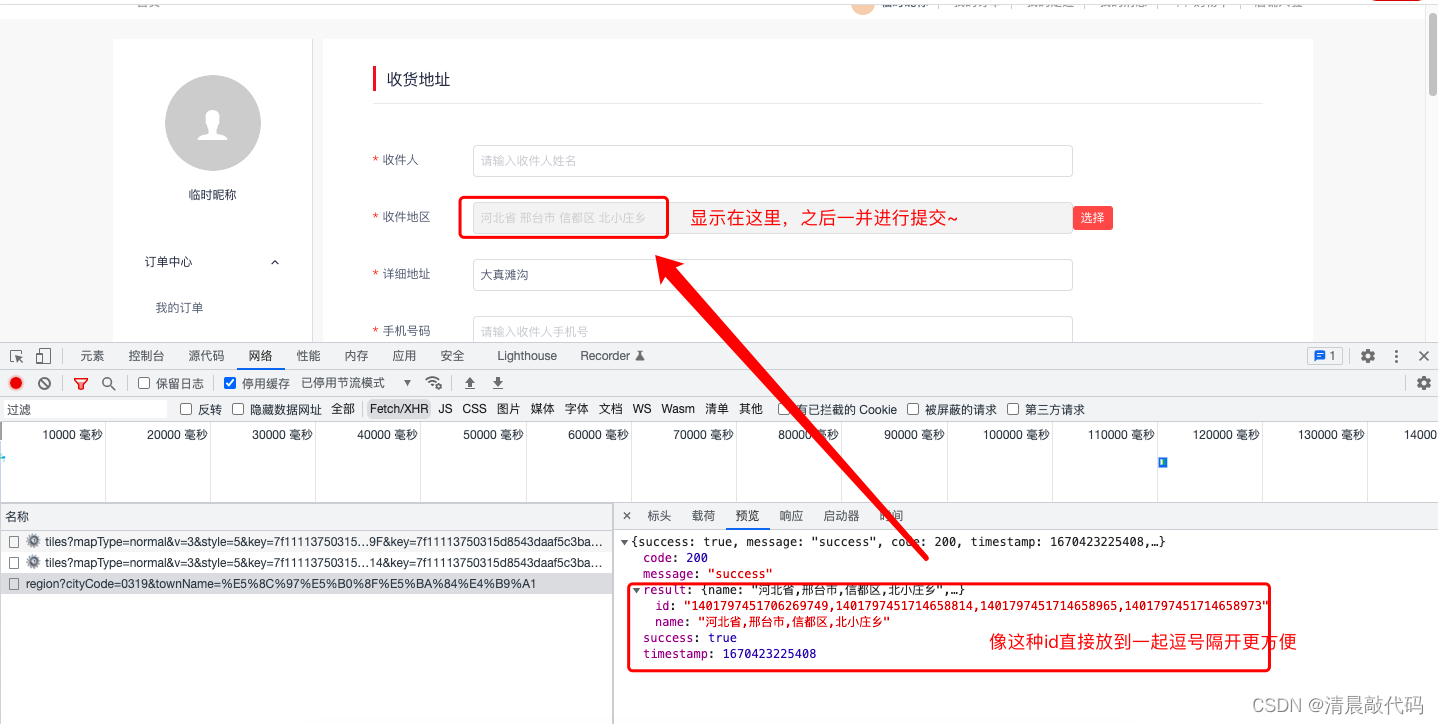
A3.物流公司
物流公司是由运营方管理的,属于全局,然后店铺端根据自己的实际物流来选择是否开启,也就是店铺物流公司,买方端会在退货/退款时选择物流公司。
【物流公司的电子面单流程无法了解,所以就先略过啦~】
B1.M端(属于显式操作)
M端就是增查改删,li_logistics 数据表也没有特别复杂,
- 分页获取物流公司、添加物流公司、编辑物流公司、删除物流公司
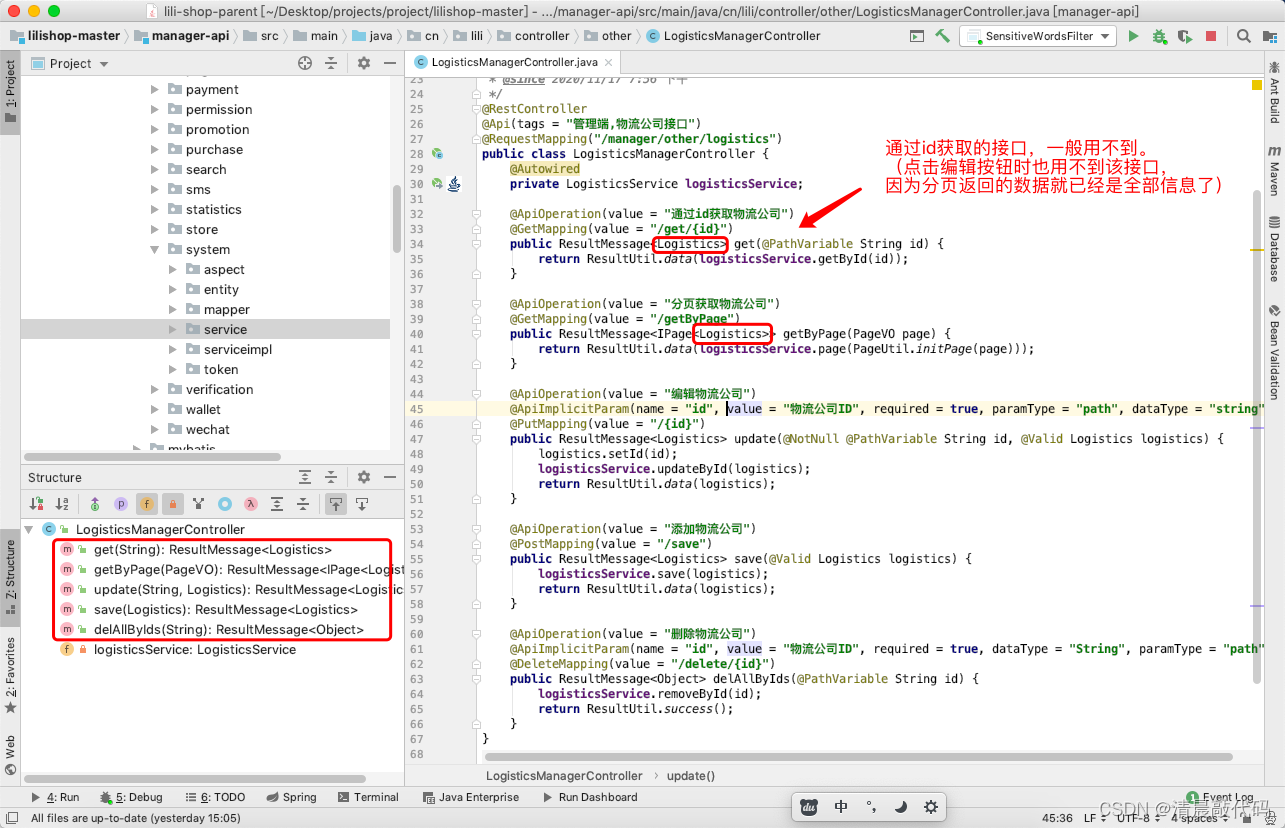
B2.S端(属于显式操作)
店铺端只能选择某些物流公司到自己的店铺下,并修改这些物流公司的面单等信息,或者从自己店铺名下去掉某些物流公司。完全不会影响到总的物流信息,和其他店铺的物流信息。
店铺端的物流公司,是根据M端的获取的,要知道店铺初始时是没有物流公司的,所有的物流公司都是关闭状态,店铺管理员将某些物流公司进行开启,然后就会将这些开启的物流公司纳入自己使用的物流公司范围内,如果关闭就会删除关闭的。
所以店铺的物流公司列表是由两部分组成的:1.总物流公司,2.店铺物流公司。【这里说的是后端具体业务,不影响接口哈~】
- 获取商家物流公司列表、根据id获取店铺-物流公司详细信息、开启某物流公司、关闭某物流公司、修改电子面单参数
- 获取商家已选择物流公司列表中包含电子面单的、获取商家已选择物流公司列表
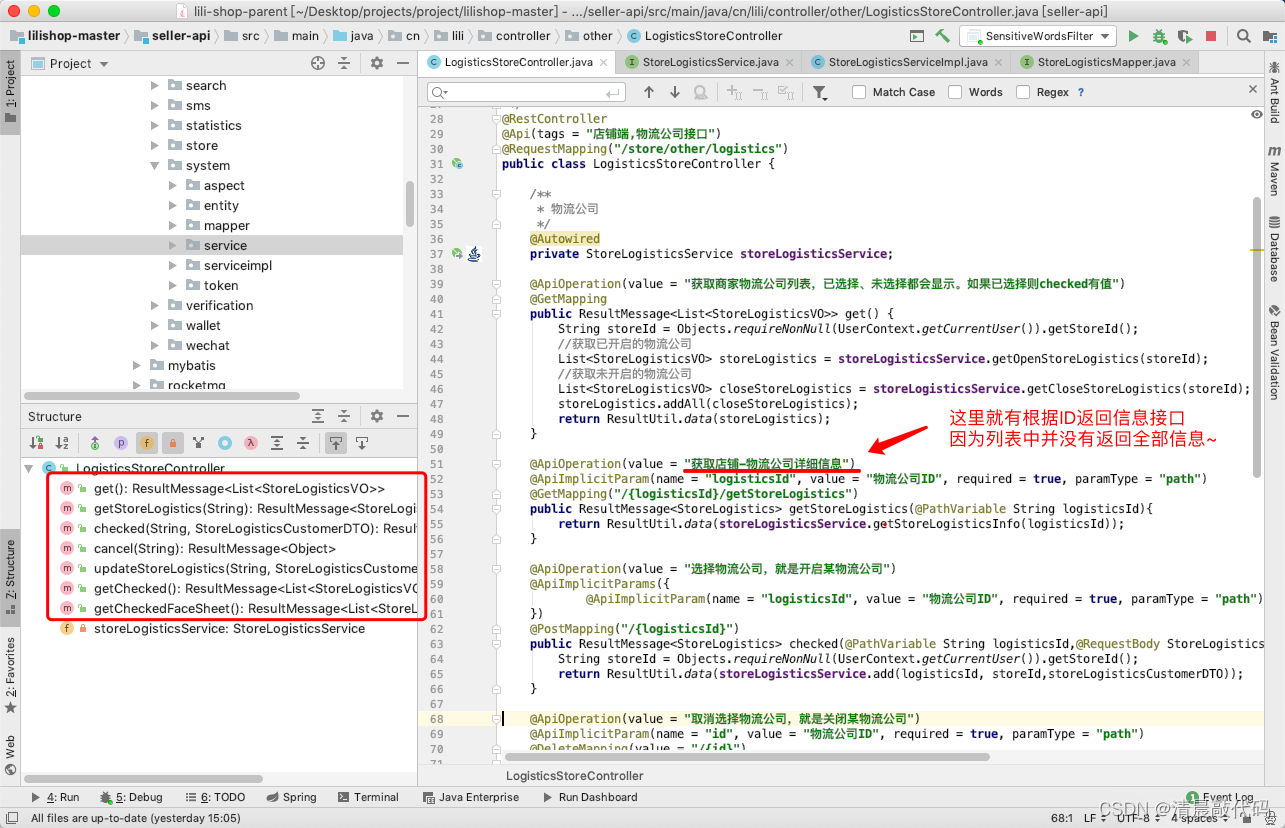
业务逻辑:
重点就是获取商家物流公司列表,这是从两张表里面获取的哦,重点反映在 mapper 层面的sql
//controller接口层
@RestController
@Api(tags = "店铺端,物流公司接口")
@RequestMapping("/store/other/logistics")
public class LogisticsStoreController {
/**
* 物流公司
*/
@Autowired
private StoreLogisticsService storeLogisticsService;
@ApiOperation(value = "获取商家物流公司列表,已选择、未选择都会显示。如果已选择则checked有值")
@GetMapping
public ResultMessage<List<StoreLogisticsVO>> get() {
String storeId = Objects.requireNonNull(UserContext.getCurrentUser()).getStoreId();
//获取已开启的物流公司
List<StoreLogisticsVO> storeLogistics = storeLogisticsService.getOpenStoreLogistics(storeId);
//获取未开启的物流公司
List<StoreLogisticsVO> closeStoreLogistics = storeLogisticsService.getCloseStoreLogistics(storeId);
storeLogistics.addAll(closeStoreLogistics);
return ResultUtil.data(storeLogistics);
}
}
//最终反映在 mapper 层
public interface StoreLogisticsMapper extends BaseMapper<StoreLogistics> {
/**
* 店铺已选择的物流公司
* 主要是从 li_store_logistics 表里面拿到开启的物流公司ID,然后关联 li_logistics 拿到name
* @param storeId 店铺Id
* @return 物流公司列表
*/
@Select("SELECT sl.logistics_id,l.name,sl.face_sheet_flag FROM li_logistics l INNER JOIN li_store_logistics sl on sl.logistics_id=l.id WHERE l.disabled = 'OPEN' AND store_id=#{storeId};")
List<StoreLogisticsVO> getOpenStoreLogistics(String storeId);
/**
* 店铺未选择的物流公司
* 主要是从 li_logistics 里面拿到不在 li_store_logistics 里面的物流公司信息
* @param storeId 店铺Id
* @return 物流公司列表
*/
@Select("SELECT id as logistics_id,name FROM li_logistics WHERE id not in(SELECT logistics_id FROM li_store_logistics WHERE store_id=#{storeId}) AND disabled = 'OPEN'")
List<StoreLogisticsVO> getCloseStroreLogistics(String storeId);
}B3.B端(属于显式操作)
B端用户在退货/换货时会选择物流公司,这里就是直接在总的物流公司中去选择,不存在纳入自己的范围。所以很简单扩展一个get接口。
-
获取物流公司

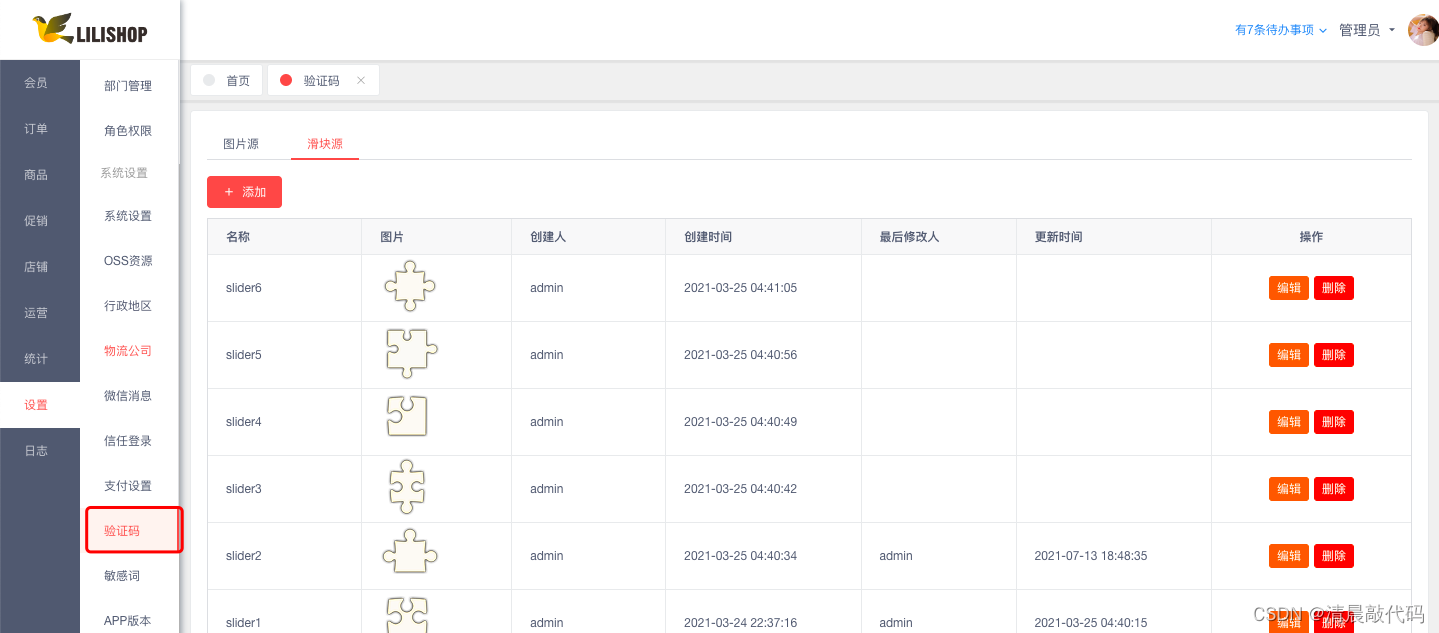
A4.滑块验证码
滑块验证码大部分用于登录时使用,其实应该放在架构里面,我就在这里简单说明了。
这一块没有用到其他工具包,基本上时使用java自带的工具包,同时又使用了spring的Base64Utils工具类。
滑块验证流程:
1.后端将底图、滑块图转化成base64并返回,同时将正确的阴影X轴位置存储到redis(key里面包含前端传过来的uuid,以便于后面getkey校验),然后返回给前端展示。
2.前端拿到base64转化成图片展示,并且实现滑动的动态效果。用户看到后滑动滑块到某个位置,此时的滑块位置为入参,松手后调用校验滑块接口,从redis里面拿到正确X轴位置与此时滑块位置作比较,比较通过后,再次缓存校验成功true(key里面也包含刚才的uuid),然后返回success。
3.前端发现滑块校验成功后,就调用登录接口,在登录接口里面会先从缓存中获取校验成功,如果是校验成功则进行登录。
两处校验:一个是滑块的校验,一个是登录时滑块校验成功的校验;
两处接口:一个是公用的 common-api 里面的,因为M、B、S端登录都会用到,一个是各个业务-api端
滑块验证码模块的管理,重点就是1.里面后端返回的滑块数据。
生成滑块流程:
先说明,数据库中存储了底图、干扰图(系统中叫滑块源)

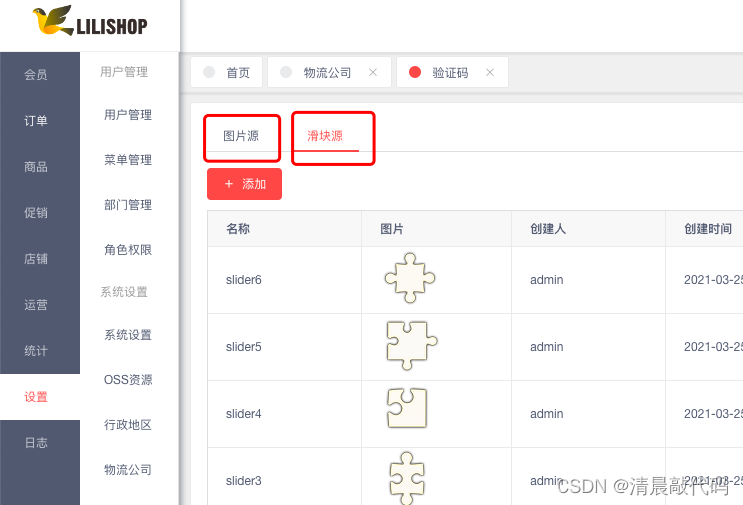
M端运营人员只需要维护底图、干扰图就行(但要注意图片大小),最终后端会随机获取一个底图、一个干扰图,随机生成干扰图左上角在底图的x,y位置,然后⭐:1.复制一个干扰图,并按照干扰图x,y位置和干扰图大小将底图重新绘画/裁剪,最终生成一个滑块图片(这就是页面展示的滑块图片);2.在底图上按照干扰图x,y位置画上干扰图(这就是页面展示的带干扰图的底图)。
【这一块会用到JAVA类 Graphics2D、BufferedImage 等。可详看shop代码里面的 ImageUtil 工具类,这一块我理解不深,虽然不会经常用到,但是还是后面有时间学习一下相关内容】
酒埠江代码了,我按照我的理解详细标备注了
B1.M端(属于显式操作)
理解了实现原理,那么这里就好说了,M端的验证码模块仅仅是维护数据。
图片源和滑块源存储是一样的,按照类型区分即可。
增改删时,要记得清除redis里面的缓存哦,在common-zpi里面获取滑动验证码图片时是从缓存中获取的~
这个就不属于操作了,属于逻辑~
- 分页获取验证码资源维护、查看验证码资源维护详情、新增验证码资源维护、更新验证码资源维护、删除验证码资源维护
B2.cosumer模块(公共模块)
三个端的登录获取都用这些接口。
【这里用到了请求限制@LimitPoint,之后记得在NO2里面再搭建这个框架~】
- 获取校验图片信息、滑块验证码预校验
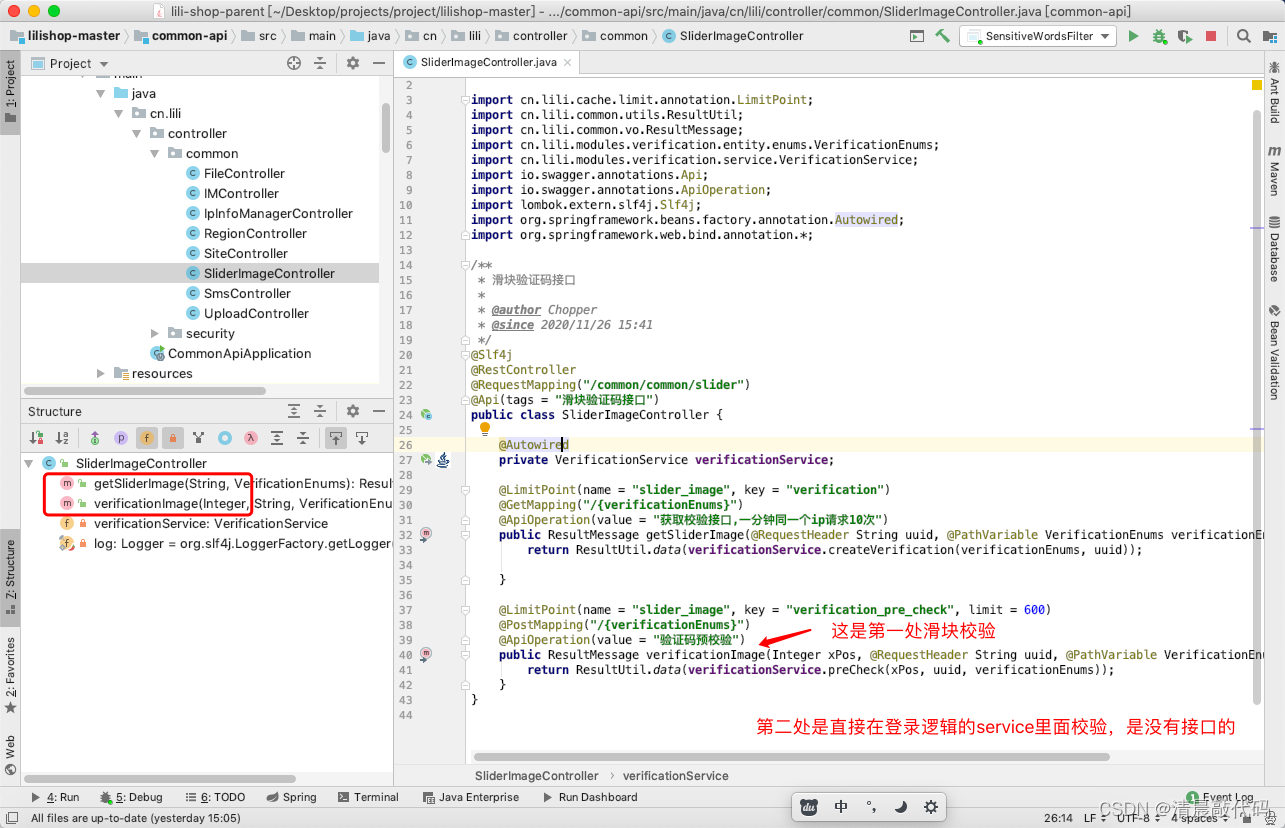
第二次登录校验是在登录的controller里面校验,例如运营M端里面的登录接口
@Slf4j
@RestController
@Api(tags = "管理员")
@RequestMapping("/manager/passport/user")
@Validated
public class AdminUserManagerController {
@Autowired
private AdminUserService adminUserService;
/**
* 会员
*/
@Autowired
private MemberService memberService;
@Autowired
private VerificationService verificationService;
@PostMapping(value = "/login")
@ApiOperation(value = "登录管理员")
public ResultMessage<Token> login(@NotNull(message = "用户名不能为空") @RequestParam String username,
@NotNull(message = "密码不能为空") @RequestParam String password,
@RequestHeader String uuid) {
//🏁这里哦
if (verificationService.check(uuid, VerificationEnums.LOGIN)) {
return ResultUtil.data(adminUserService.login(username, password));
} else {
throw new ServiceException(ResultCode.VERIFICATION_ERROR);
}
}
}A5.敏感词过滤
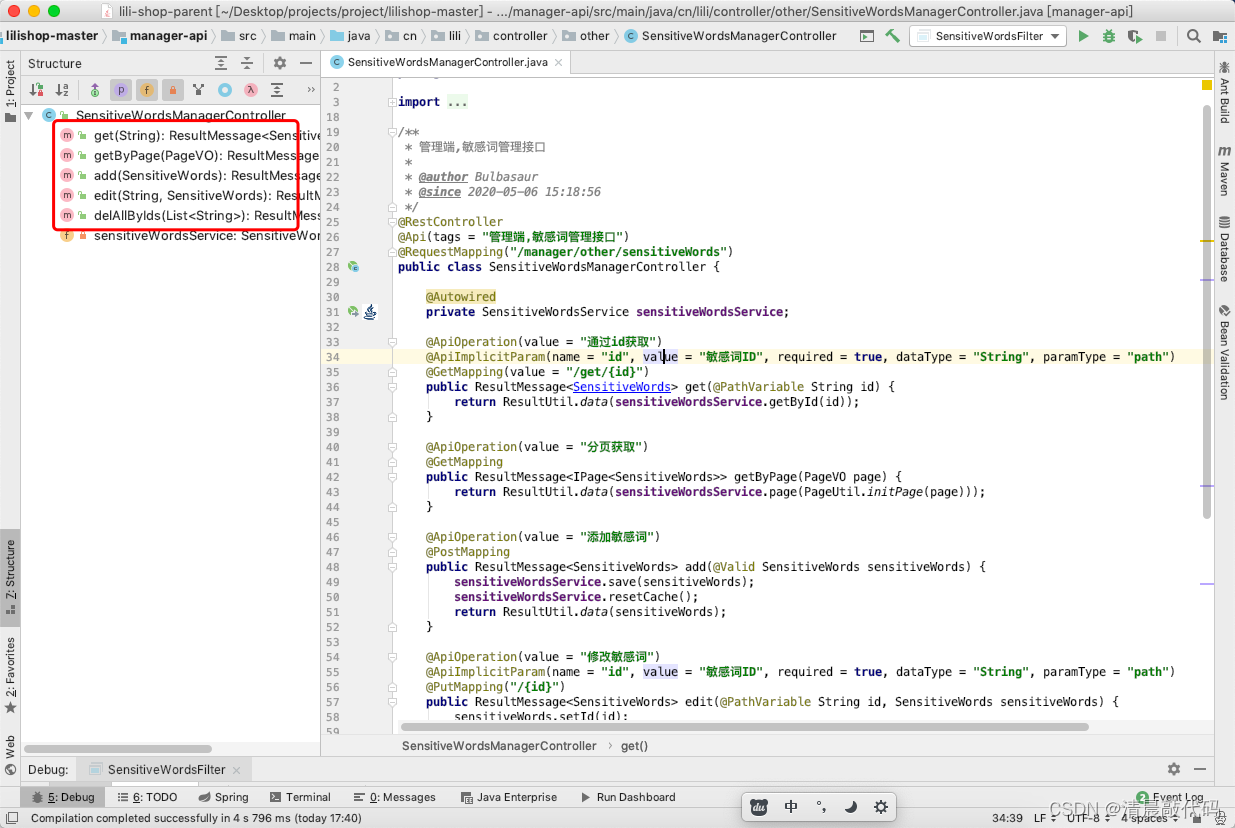
在shop项目中,敏感词过滤是直接放到了业务里面,不是通过接口过滤的。所以只有运营M端的管理敏感词的接口。
敏感词的管理就很简单了,就是关键词而已。
B1.M端(属于显式操作)
没啥复杂逻辑
- 分页获取敏感词、通过id获取敏感词、新增敏感词、更新敏感词、删除敏感词
B2.敏感词过滤器(属于隐式业务操作,可以理解为工具类,也可以说是算法)
【这里可以理解为匹配算法,只是在此之上将匹配的数据由一个变成了多个的集合。】
就解释一下大致流程,具体的看代码注释,我按照我的思路注释的很清晰了~
要实现过滤,首先要有源数据,在这里就是需要过滤的string字符串,然后要有敏感词集合。过滤时判断源数据中是否有能匹配中敏感词集合里面敏感词,匹配中就替换成*符号,也就是过滤。
接下来就直接说敏感词集合、匹配逻辑这两个逻辑了。
敏感词集合:
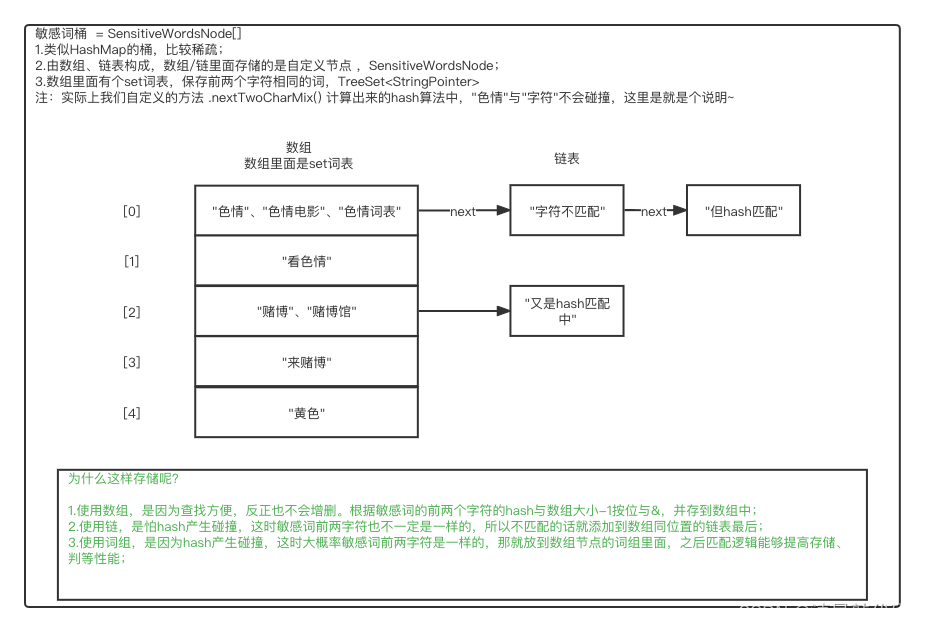
过滤逻辑:

过滤逻辑相关类:
代码特别多,直接看顶部源代码吧
//字符指针,用于过滤词和过滤内容
cn.lili.common.sensitive.StringPointer
//敏感词节点,每个节点包含了以相同的2个字符开头的所有词
cn.lili.common.sensitive.SensitiveWordsNode
//敏感词过滤器
cn.lili.common.sensitive.SensitiveWordsFilter

敏感词过滤的使用:
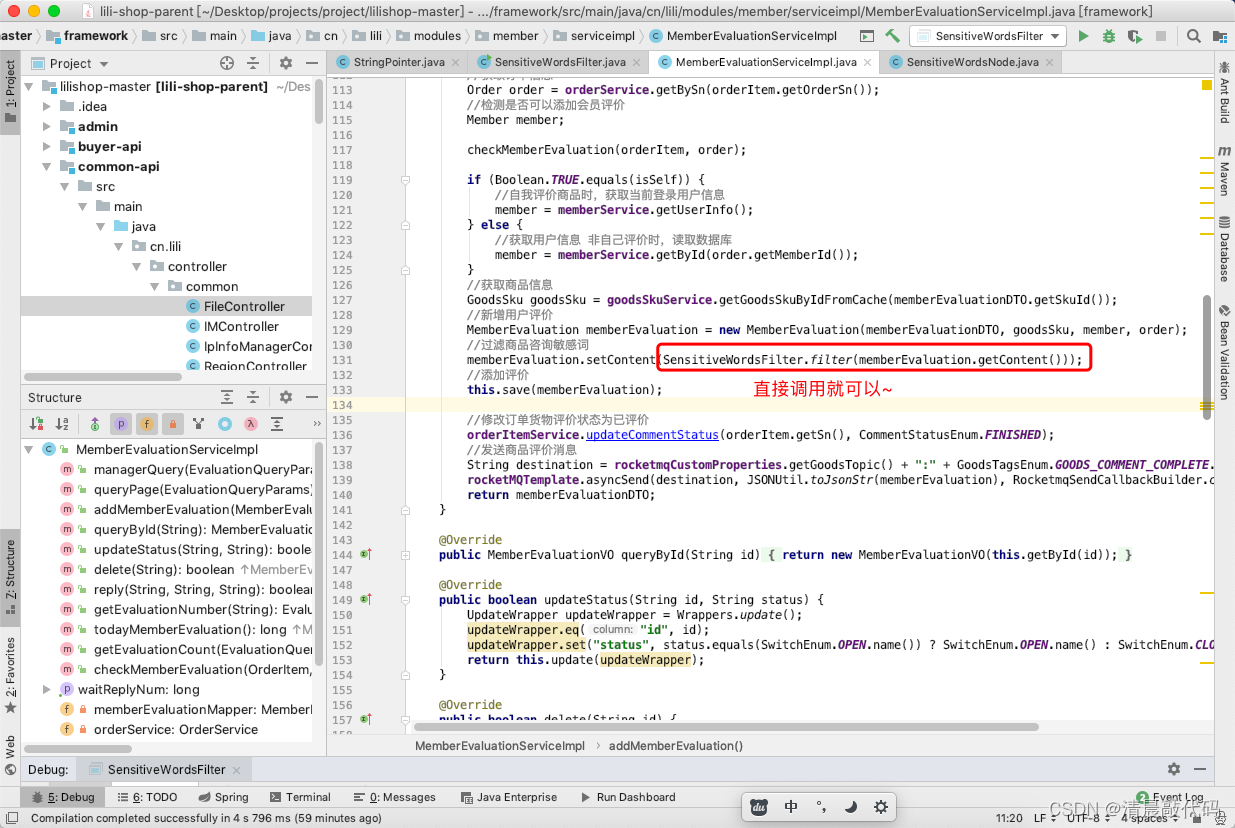
注意哦,敏感词是从数据库里面获取的。项目启动时会先初始化,拿到敏感词数组缓存到redis里面,然后启动定时器,每小时重新更新一下数组。定时器用的 Quartz
@Slf4j
public class SensitiveQuartz extends QuartzJobBean {
@Autowired
private Cache<List<String>> cache;
/**
* 定时更新敏感词信息
*
* @param jobExecutionContext
*/
@Override
protected void executeInternal(JobExecutionContext jobExecutionContext) {
log.info("敏感词定时更新");
List<String> sensitives = cache.get(CachePrefix.SENSITIVE.getPrefix());
if (sensitives == null || sensitives.isEmpty()) {
return;
}
SensitiveWordsFilter.init(sensitives);
}
}
@Configuration
public class QuartzConfig {
@Bean
public JobDetail sensitiveQuartzDetail() {
return JobBuilder.newJob(SensitiveQuartz.class).withIdentity("sensitiveQuartz").storeDurably().build();
}
@Bean
public Trigger sensitiveQuartzTrigger() {
SimpleScheduleBuilder scheduleBuilder = SimpleScheduleBuilder.simpleSchedule()
// 设置重复间隔为3600秒
.withIntervalInSeconds(3600)
.repeatForever();
return TriggerBuilder.newTrigger().forJob(sensitiveQuartzDetail())
.withIdentity("sensitiveQuartz")
.withSchedule(scheduleBuilder)
.build();
}
}