Databricks 介绍
Databricks是一家美国的大数据独角兽公司,由 Apache Spark 的创建者所创立。Databricks 开源了 Delta Lake--基于 Apache Spark 的下一代数据湖存储引擎。Delta Lake 是目前市面上主流的数据湖存储引擎之一,与 Apache Hudi 和 Apache Iceberg 并称为数据湖三剑客。
在最近结束的 Databricks Data + AI Summit 上,Databricks CEO Ali Ghodsi 发布了 Delta Lake 3.0。这个新版本引入了一种名为通用格式(UniForm)的开放表格式,可读写三种流行的数据表格式,包括 Delta Lake、Apache Iceberg 和 Apache Hudi。这体现了 Databricks 拥抱开放数据生态的决心。
开放表格式通过提供一个标准和统一的方式来访问大数据集,而表格式的一统可以帮助用户降低多种格式共存的技术成本。可以说,这个理念与 StarRocks 期望构建的基于开放生态的,极速统一的湖仓分析新范式不谋而合!

Ali Ghodsi 在主题演讲中提及了 StarRocks
StarRocks--极速统一的湖仓新范式
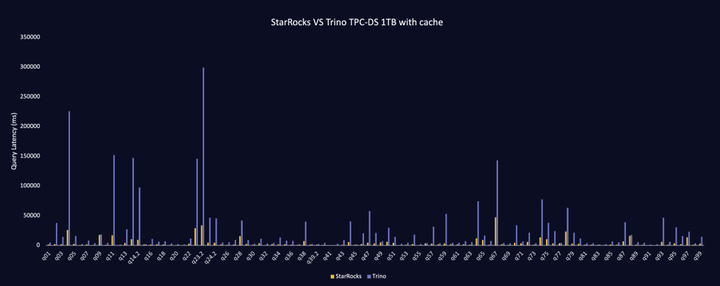
01 StarRocks 的极致查询性能
-
MPP 分布式执行
-
Pipeline 并行执行框架
-
向量化执行引擎
-
CBO 优化器
-
Global Runtime Filter
-
Metadata Cache
-
Local Data Cache
-
Materialized View
关于 StarRocks 的极致性能已经有很多资料介绍了,这里就不多加展开。大家可以通过文末文章链接了解更多细节。
02 利用StarRocks的 "House" 能力进一步提升性能
StarRocks 不仅仅是一个查询引擎,同时也拥有一个强大的存储引擎,如果你希望进一步提升查询性能或者查询并发能力,你可以将数据导入到 StarRocks 中,StarRocks 的本地存储拥有丰富的索引能力、实时更新能力和多表 colocate join 能力。
数据导入 StarRocks 中有两种方式:手动导入数据和 MV 自动导入数据。
StarRocks 支持对数据湖上的表创建物化视图,并且支持自动数据同步和自动查询改写。
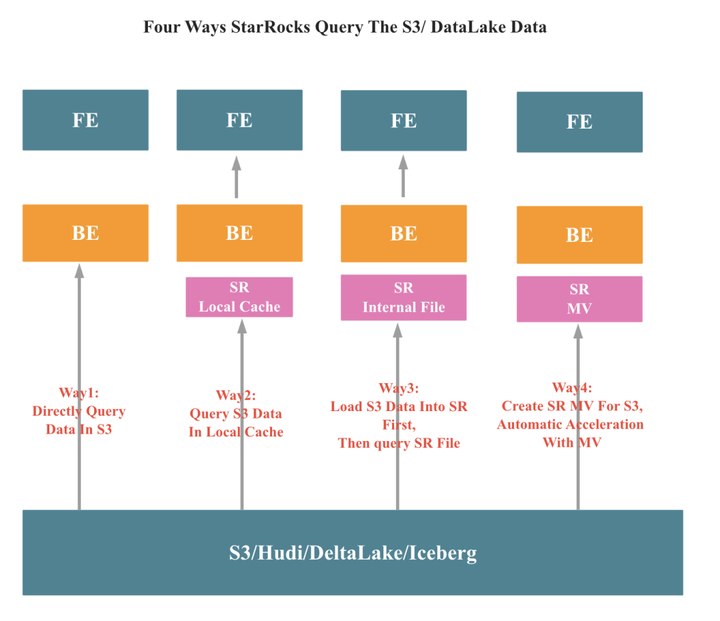
03 StarRocks 支持冷热分离+自动查询改写
大多数情况下,我们希望最近一周或者一个月的热数据拥有更好的查询性能,在 StarRocks 中,MV (物化视图)可以方便且高效地实现这一目标:
如上图所示,StarRocks 的 MV 可以只保存最近一个月的数据,当你查询 Data Lake 上的数据时,StarRocks 会帮你自动改写,最新的数据从 StarRocks 查询,而历史数据则从 Data Lake 查询,然后自动进行 Union 操作,将两部分数据合并返回给你。
04 StarRocks 支持实时更新
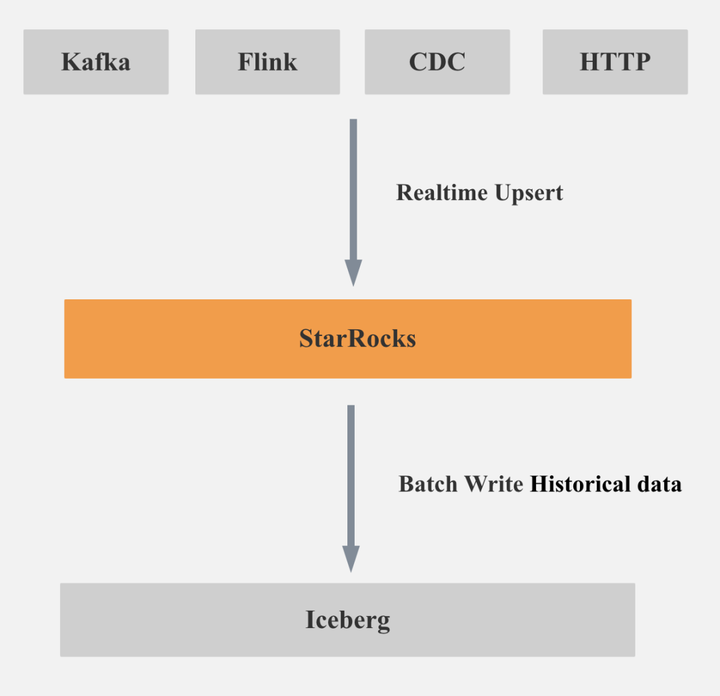
因为 StarRocks 同时支持实时高效更新和写出到 Iceberg,所以我们可以基于 StarRocks 构建实时更新的 Lakehouse。当你同时需要实时更新、极致查询性能和开放的 Table Format,StarRocks 便是你的唯一选择。
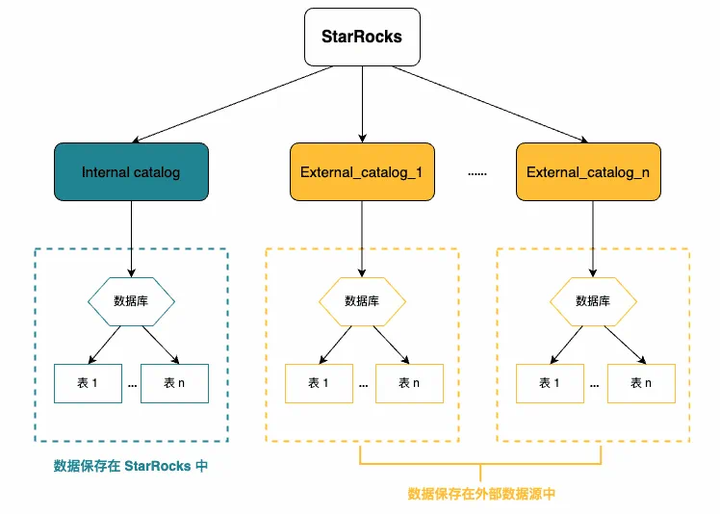
05 简单易用的 Catalog 元数据管理
StarRocks 提供了一键同步外部数据库中的所有表元数据的功能,并且可以快速同步各种 Data Lake 数据源。
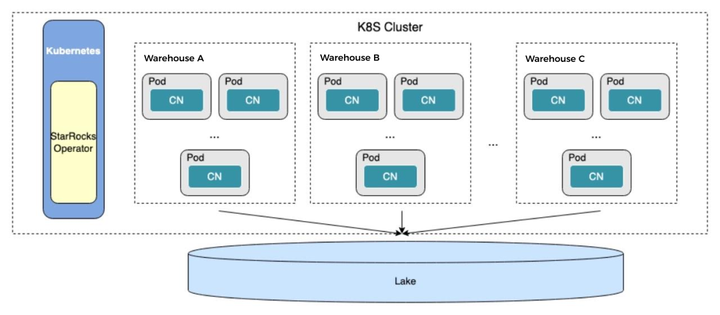
06 可弹性伸缩
StarRocks 用于数据湖分析的计算节点是无状态的,可以结合 K8s 进行快速弹性伸缩。
在前面的内容中,我们总结了 StarRocks 数据湖的卓越能力。而在未来,我们的承诺依然是让数据处理变得更简单(统一)、更快速有效(极速)。我们期待进一步利用 Delta UniForm 的能力,使用户能够更轻松地在各种开放数据格式上进行亚秒级分析。这种生态上的融合能够将亚秒级分析的功能范围扩展到更广泛的用户群体,使数据分析比以往任何时候都更加容易!
想要再深入了解更多关于 StarRocks 湖仓分析的特性吗?欢迎利用以下资源:
当打造一款极速湖分析产品时,我们在想些什么
StarRocks 3.0 极速统一的湖仓新范式
技术内幕 | StarRocks 支持 Apache Hudi 原理解析
StarRocks 湖仓融合的四种范式
💬 加入 StarRocks 的 Lakehouse 用户小组,开启你与 StarRocks 的极速湖仓分析之旅! 点击链接填写完问卷后即可获得入群方式:https://tl-tx.dustess.com/0kGIuI4VTZ