一篇文章带你吃透Go语言的Atomic和Channel–实战方法

Atomic 要保证原子操作,一定要使用这几种方法
我们在学习 Mutex、RWMutex 等并发原语的实现时,你可以看到,最底层是通过 atomic 包中的一些原子操作来实现的
你可能会说,这些并发原语已经可以应对大多数的并发场景了,为啥还要学习原子操作呢?其实,这是因为,在很多场景中,使用并发原语实现起来比较复杂,而原子操作可以帮助我们更轻松地实现底层的优化。
之所以叫原子操作,是因为一个原子在执行的时候,其它线程不会看到执行一半的操作结果。在其它线程看来,原子操作要么执行完了,要么还没有执行,就像一个最小的粒子 - 原子一样,不可分割。
原子操作的基础知识
CPU 提供了基础的原子操作,不过,不同架构的系统的原子操作是不一样的。
对于单处理器单核系统来说,如果一个操作是由一个 CPU 指令来实现的,那么它就是原子操作,比如它的 XCHG 和 INC 等指令。如果操作是基于多条指令来实现的,那么,执行的
过程中可能会被中断,并执行上下文切换,这样的话,原子性的保证就被打破了,因为这个时候,操作可能只执行了一半
在多处理器多核系统中,原子操作的实现就比较复杂了。
由于 cache 的存在,单个核上的单个指令进行原子操作的时候,你要确保其它处理器或者核不访问此原子操作的地址,或者是确保其它处理器或者核总是访问原子操作之后的最新
的值。x86 架构中提供了指令前缀 LOCK,LOCK 保证了指令(比如 LOCK CMPXCHG op1、op2)不会受其它处理器或 CPU 核的影响,有些指令(比如 XCHG)本身就提供
Lock 的机制。不同的 CPU 架构提供的原子操作指令的方式也是不同的,比如对于多核的 MIPS 和 ARM,提供了 LL/SC(Load Link/Store Conditional)指令,可以帮助实现原子
操作(ARMLL/SC 指令 LDREX 和 STREX)。
因为不同的 CPU 架构甚至不同的版本提供的原子操作的指令是不同的,所以,要用一种编程语言实现支持不同架构的原子操作是相当有难度的。不过,还好这些都不需要你操心,
因为 Go 提供了一个通用的原子操作的 API,将更底层的不同的架构下的实现封装成 atomic 包
关于 atomic,还有一个地方你一定要记住,atomic 操作的对象是一个地址,你需要把可寻址的变量的地址作为参数传递给方法,而不是把变量的值传递给方法。
基本方法
- Add 方法就是给第一个参数地址中的值增加一个
delta值 可以是负值 - CAS 这个方法会比较当前
addr地址里的值是不是old,如果不等于old,就返回false;如果等于old,就把此地址的值替换成new值,返回true。这就相当于“判断相等才替换”。 - Swap 直接交换值
- Load 方法会取出
addr地址中的值 - Store 方法会把一个值存入到指定的
addr地址中,即使在多处理器、多核、有CPU cache的情况下,这个操作也能保证Store是一个原子操作。 - Value 类型 它可以原子地存取对象类型,但也只能存取,不能
CAS和Swap,常常用在配置变更等场景中。
type Config struct {
NodeName string
Addr string
Count int32
}
func loadNewConfig() Config {
return Config{NodeName: "北京", Addr: "10.77.95.27", Count: rand.Int31()}
}
func main() {
var config atomic.Value
config.Store(loadNewConfig())
var cond = sync.NewCond(&sync.Mutex{}) // 设置新的config
go func() {
for {
time.Sleep(time.Duration(5+rand.Int63n(5)) * time.Second)
config.Store(loadNewConfig())
cond.Broadcast() // 通知等待着配置已变更
}
}()
go func() {
for {
cond.L.Lock()
cond.Wait() // 等待变更信号
c := config.Load().(Config) // 读取新的配置
fmt.Printf("new config: %+v\n", c)
cond.L.Unlock()
}
}()
select {}
}
第三方库的扩展
- uber go/atomic,它定义和封装了几种与常见类型相对应的原子操作类型,这些类型提供了原子操作的方法。这些类型包括 Bool、Duration、Error、Float64、Int32、Int64、String、Uint32、Uint64 等。
atomic 原子操作的应用场景
举个例子:假设你想在程序中使用一个标志(flag,比如一个 bool 类型的变量),来标识一个定时任务是否已经启动执行了,你会怎么做呢?
我们先来看看加锁的方法。如果使用 Mutex 和 RWMutex,在读取和设置这个标志的时候加锁,是可以做到互斥的、保证同一时刻只有一个定时任务在执行的,所以使用 Mutex 或者 RWMutex 是一种解决方案。
其实,这个场景中的问题不涉及到对资源复杂的竞争逻辑,只是会并发地读写这个标志,这类场景就适合使用 atomic 的原子操作。具体怎么做呢?
你可以使用一个 uint32 类型的变量,如果这个变量的值是 0,就标识没有任务在执行,如果它的值是 1,就标识已经有任务在完成了。你看,是不是很简单呢?
再来看一个例子。假设你在开发应用程序的时候,需要从配置服务器中读取一个节点的配置信息。而且,在这个节点的配置发生变更的时候,你需要重新从配置服务器中拉取一份
新的配置并更新。你的程序中可能有多个 goroutine 都依赖这份配置,涉及到对这个配置对象的并发读写,你可以使用读写锁实现对配置对象的保护。在大部分情况下,你也可以
利用 atomic 实现配置对象的更新和加载。
使用 atomic 实现 Lock-Free queue
// lock-free的queue
type LKQueue struct {
head unsafe.Pointer
tail unsafe.Pointer
}
// 通过链表实现,这个数据结构代表链表中的节点
type node struct {
value interface{}
next unsafe.Pointer
}
func NewLKQueue() *LKQueue {
n := unsafe.Pointer(&node{})
return &LKQueue{head: n, tail: n}
} // 入队
func (q *LKQueue) Enqueue(v interface{}) {
n := &node{value: v}
for {
tail := load(&q.tail)
next := load(&tail.next)
if tail == load(&q.tail) { // 尾还是尾
if next == nil { // 还没有新数据入队
if cas(&tail.next, next, n) { //增加到队尾
cas(&q.tail, tail, n) //入队成功,移动尾巴指针
return
}
} else { // 已有新数据加到队列后面,需要移动尾指针
cas(&q.tail, tail, next)
}
}
}
}
// 出队,没有元素则返回nil
func (q *LKQueue) Dequeue() interface{} {
for {
head := load(&q.head)
tail := load(&q.tail)
next := load(&head.next)
if head == load(&q.head) { // head还是那个head
if head == tail { // head和tail一样
if next == nil { // 说明是空队列
return nil
} // 只是尾指针还没有调整,尝试调整它指向下一个
cas(&q.tail, tail, next)
} else { // 读取出队的数据
v := next.value // 既然要出队了,头指针移动到下一个
if cas(&q.head, head, next) {
return v // Dequeue is done. return
}
}
}
}
}
// 将unsafe.Pointer原子加载转换成node
func load(p *unsafe.Pointer) (n *node) { return (*node)(atomic.LoadPointer(p)) }
// 封装CAS,避免直接将*node转换成unsafe.Pointer
func cas(p *unsafe.Pointer, old, new *node) (ok bool) {
return atomic.CompareAndSwapPointer(p, unsafe.Pointer(old), unsafe.Pointer(new))
}
Channel:另辟蹊径,解决并发问题
应用场景
- 数据交流:当作并发的
buffer或者queue,解决生产者 - 消费者问题。多个goroutine可以并发当作生产者(Producer)和消费者(Consumer)。 - 数据传递:一个
goroutine将数据交给另一个goroutine,相当于把数据的拥有权 (引用) 托付出去。 - 信号通知:一个
goroutine可以将信号 (closing、closed、data ready 等) 传递给另一个或者另一组goroutine。 - 任务编排:可以让一组
goroutine按照一定的顺序并发或者串行的执行,这就是编排的功能。 - 锁:利用
Channel也可以实现互斥锁的机制。
基本了解
通过 make,我们可以初始化一个 chan,未初始化的 chan 的零值是 nil。你可以设置它的容量,比如下面的 chan 的容量是 9527,我们把这样的 chan 叫做 buffered chan;如果
没有设置,它的容量是 0,我们把这样的 chan 叫做 unbuffered chan。
如果 chan 中还有数据,那么,从这个 chan 接收数据的时候就不会阻塞,如果 chan 还未满(“满”指达到其容量),给它发送数据也不会阻塞,否则就会阻塞。unbuffered chan 只有读写都准备好之后才不会阻塞,
这也是很多使用 unbuffered chan 时的常见 Bug。
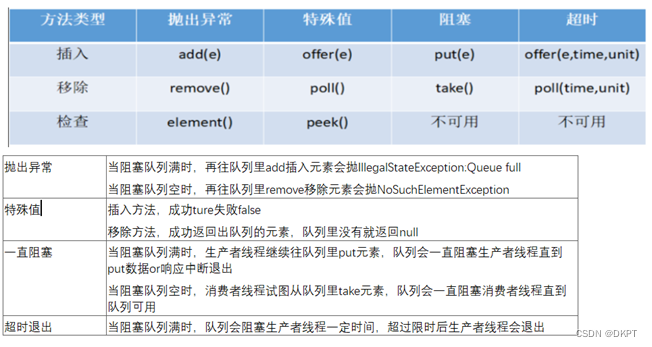
chan接收是有两个值的,第一个是通道中的值,第二个表示是否正常接收到那些值,如果第二个值为false,chan已经被被close而且chan中没有缓存的数据了- 发送和接收 都可用于
select的case语句 chan还可以用作于for-range中,可以使用取出的值,也可以什么都不作 用于清空数据
使用 Channel 容易犯的错误
close为nil的chan;send已经close的chan;close已经close的chan。
什么时候选择使用 Channel
- 共享资源的并发访问使用传统并发原语;
- 复杂的任务编排和消息传递使用
Channel; - 消息通知机制使用
Channel,除非只想signal一个goroutine,才使用Cond; - 简单等待所有任务的完成用
WaitGroup,也有Channel的推崇者用Channel,都可以; - 需要和
Select语句结合,使用Channel; - 需要和超时配合时,使用
Channel和Context。
Channel:透过代码看典型的应用模式
使用反射操作 Channel
select 语句可以处理 chan 的 send 和 recv,可是,如果要处理 100 个 chan 呢?一万个 chan 呢?
通过 reflect.Select 函数,你可以将一组运行时的 case clause 传入,当作参数执行。Go 的 select 是伪随机的,它可以在执行的 case 中随机选择一个 case,并把选择的这个 case
的索引(chosen)返回,如果没有可用的 case 返回,会返回一个 bool 类型的返回值,这个返回值用来表示是否有 case 成功被选择。如果是 recv case,还会返回接收的元素。
func main() {
var ch1 = make(chan int, 10)
var ch2 = make(chan int, 10) // 创建SelectCase
var cases = createCases(ch1, ch2) // 执行10次select
for i := 0; i < 10; i++ {
chosen, recv, ok := reflect.Select(cases)
if recv.IsValid() { // recv case
fmt.Println("recv:", cases[chosen].Dir, recv, ok)
} else { // send case
fmt.Println("send:", cases[chosen].Dir, ok)
}
}
}
func createCases(chs ...chan int) []reflect.SelectCase {
var cases []reflect.SelectCase // 创建recv case
for _, ch := range chs {
cases = append(cases, reflect.SelectCase{Dir: reflect.SelectRecv, Chan: reflect.ValueOf(ch)})
} // 创建send case
for i, ch := range chs {
v := reflect.ValueOf(i)
cases = append(cases, reflect.SelectCase{Dir: reflect.SelectSend, Chan: reflect.ValueOf(ch), Send: v})
}
return cases
}
典型的应用场景
消息交流
从 chan 的内部实现看,它是以一个循环队列的方式存放数据,所以,它有时候也会被当成线程安全的队列和 buffer 使用。一个 goroutine 可以安全地往 Channel 中塞数据,另
外一个 goroutine 可以安全地从 Channel 中读取数据,goroutine 就可以安全地实现信息交流了。
第一个例子是 worker 池的例子。他们将用户的请求放在一个 chan Job 中,这个 chan Job 就相当于一个待处理任务队列。除此之外,还有一个 chan chan Job
队列,用来存放可以处理任务的 worker 的缓存队列。 dispatcher 会把待处理任务队列中的任务放到一个可用的缓存队列中,worker 会一直处理它的缓存队列。通过使用 Channel,实现了一个 worker 池的任务处理中心,并且解耦
了前端 HTTP 请求处理和后端任务处理的逻辑。
数据传递
有 4 个 goroutine,编号为 1、2、3、4。每秒钟会有一个 goroutine 打印出它自己的编号,要求你编写程序,让输出的编号总是按照 1、2、3、4、1、2、3、4……这个顺序打印出来。
type Token struct{}
func newWorker(id int, ch chan Token, nextCh chan Token) {
for {
token := <-ch // 取得令牌
fmt.Println((id + 1)) // id从1开始
time.Sleep(time.Second)
nextCh <- token
}
}
func main() {
chs := []chan Token{make(chan Token), make(chan Token), make(chan Token), make(chan Token)} // 创建4个worker
for i := 0; i < 4; i++ {
go newWorker(i, chs[i], chs[(i+1)%4])
}
//首先把令牌交给第一个worker
chs[0] <- struct{}{}
select {}
}
这类场景有一个特点,就是当前持有数据的 goroutine 都有一个信箱,信箱使用 chan 实现,goroutine 只需要关注自己的信箱中的数据,处理完毕后,就把结果发送到下一家的信箱中。
信号通知
chan 类型有这样一个特点:chan 如果为空,那么,receiver 接收数据的时候就会阻塞等待,直到 chan 被关闭或者有新的数据到来。利用这个机制,我们可以实现 wait/notify 的设计模式。
除了正常的业务处理时的 wait/notify,我们经常碰到的一个场景,就是程序关闭的时候,我们需要在退出之前做一些清理(doCleanup 方法)的动作。这个时候,我们经常要使用 chan。
比如,使用 chan 实现程序的 graceful shutdown,在退出之前执行一些连接关闭、文件 close、缓存落盘等一些动作。
func main() {
go func() {
...... // 执行业务处理
}() // 处理CTRL+C等中断信号
termChan := make(chan os.Signal)
signal.Notify(termChan, syscall.SIGINT, syscall.SIGTERM) <- termChan // 执行退出之前的清理动作
doCleanup()
fmt.Println("优雅退出")
}
有时候,doCleanup 可能是一个很耗时的操作,比如十几分钟才能完成,如果程序退出需要等待这么长时间,用户是不能接受的,所以,在实践中,我们需要设置一个最长的等待
时间。只要超过了这个时间,程序就不再等待,可以直接退出。所以,退出的时候分为两个阶段:
- closing,代表程序退出,但是清理工作还没做;
- closed,代表清理工作已经做完。
func main() {
var closing = make(chan struct{})
var closed = make(chan struct{})
go func() { // 模拟业务处理
for {
select {
case <-closing:
return
default: // ....... 业务计算
time.Sleep(100 * time.Millisecond)
}
}
}() // 处理CTRL+C等中断信号
termChan := make(chan os.Signal)
signal.Notify(termChan, syscall.SIGINT, syscall.SIGTERM) <- termChan
close(closing) // 执行退出之前的清理动作
go doCleanup(closed)
select {
case <-closed:
case <-time.After(time.Second):
fmt.Println("清理超时,不等了")
}
fmt.Println("优雅退出")
}
func doCleanup(closed chan struct{}) { time.Sleep((time.Minute))
close(closed)
锁
使用 chan 也可以实现互斥锁。
要想使用 chan 实现互斥锁,至少有两种方式。一种方式是先初始化一个 capacity 等于 1 的 Channel,然后再放入一个元素。这个元素就代表锁,谁取得了这个元素,就相当于获
取了这把锁。另一种方式是,先初始化一个 capacity 等于 1 的 Channel,它的“空槽”代表锁,谁能成功地把元素发送到这个 Channel,谁就获取了这把锁。
这是使用 Channel 实现锁的两种不同实现方式,我重点介绍下第一种。理解了这种实现方式,第二种方式也就很容易掌握了,我就不多说了。
// 使用chan实现互斥锁
type Mutex struct {
ch chan struct{}
}
// 使用锁需要初始化
func NewMutex() *Mutex {
mu := &Mutex{make(chan struct{}, 1)}
mu.ch <- struct{}{}
return mu
}
// 请求锁,直到获取到
func (m *Mutex) Lock() {
<-m.ch
}
// 解锁
func (m *Mutex) Unlock() {
select {
case m.ch <- struct{}{}:
default:
panic("unlock of unlocked mutex")
}
} // 尝试获取锁
func (m *Mutex) TryLock() bool {
select {
case <-m.ch:
return true
default:
}
return false
} // 加入一个超时的设置
func (m *Mutex) LockTimeout(timeout time.Duration) bool {
timer := time.NewTimer(timeout)
select {
case <-m.ch:
timer.Stop()
return true
case <-timer.C:
}
return false
}
// 锁是否已被持有
func (m *Mutex) IsLocked() bool {
return len(m.ch) == 0
}
func main() {
m := NewMutex()
ok := m.TryLock()
fmt.Printf("locked v %v\n", ok)
ok = m.TryLock()
fmt.Printf("locked %v\n", ok)
}
你可以用 buffer 等于 1 的 chan 实现互斥锁,在初始化这个锁的时候往 Channel 中先塞入一个元素,谁把这个元素取走,谁就获取了这把锁,把元素放回去,就是释放了锁。元
素在放回到 chan 之前,不会有 goroutine 能从 chan 中取出元素的,这就保证了互斥性。
在这段代码中,还有一点需要我们注意下:利用 select+chan 的方式,很容易实现 TryLock、Timeout 的功能。具体来说就是,在 select 语句中,我们可以使用 default 实
现 TryLock,使用一个 Timer 来实现 Timeout 的功能。
任务编排
我们学习了 WaitGroup,我们可以利用它实现等待模式:启动一组 goroutine 执行任务,然后等待这些任务都完成。其实,我们也可以使用 chan 实现
WaitGroup 的功能。我来重点介绍下多个 chan 的编排方式,总共 5 种,分别是 Or-Done 模式、扇入模式、扇出模式、Stream 和 Map-Reduce
Or-Done 模式
我们会使用“信号通知”实现某个任务执行完成后的通知机制,在实现时,我们为这个任务定义一个类型为 chan struct{} 类型的 done 变量,等任务结束后,我们就可以 close 这
个变量,然后,其它 receiver 就会收到这个通知。这是有一个任务的情况,如果有多个任务,只要有任意一个任务执行完,我们就想获得这个信号,这就是 Or-Done 模式。
func or(channels ...<-chan interface{}) <-chan interface{} { // 特殊情况,只有零个或者1个chan
switch len(channels) {
case 0:
return nil
case 1:
return channels[0]
}
orDone := make(chan interface{})
go func() {
defer close(orDone)
switch len(channels) {
case 2: // 2个也是一种特殊情况
select {
case <-channels[0]:
case <-channels[1]:
}
default: //超过两个,二分法递归处理
m := len(channels) / 2
select {
case <-or(channels[:m]...):
case <-or(channels[m:]...):
}
}
}()
return orDone
}
func sig(after time.Duration) <-chan interface{} {
c := make(chan interface{})
go func() {
defer close(c)
time.Sleep(after)
}()
return c
}
func main() {
start := time.Now()
<-or(sig(10*time.Second), sig(20*time.Second), sig(30*time.Second), sig(40*time.Second), sig(50*time.Second), sig(01*time.Minute))
fmt.Printf("done after %v", time.Since(start))
}
这里的实现使用了一个巧妙的方式,当 chan 的数量大于 2 时,使用递归的方式等待信号。
扇入模式
扇入借鉴了数字电路的概念,它定义了单个逻辑门能够接受的数字信号输入最大量的术语。一个逻辑门可以有多个输入,一个输出。
在软件工程中,模块的扇入是指有多少个上级模块调用它。而对于我们这里的 Channel 扇入模式来说,就是指有多个源 Channel 输入、一个目的 Channel 输出的情况。扇入比就
是源 Channel 数量比 1。 每个源 Channel 的元素都会发送给目标 Channel,相当于目标 Channel 的 receiver 只需要监听目标 Channel,就可以接收所有发送给源 Channel 的数据。
func fanInReflect(chans ...<-chan interface{}) <-chan interface{} {
out := make(chan interface{})
go func() {
defer close(out) // 构造SelectCase slice
var cases []reflect.SelectCase
for _, c := range chans {
cases = append(cases, reflect.SelectCase{Dir: reflect.SelectRecv, Chan: reflect.ValueOf(c)})
} // 循环,从cases中选择一个可用的
for len(cases) > 0 {
i, v, ok := reflect.Select(cases)
if !ok { // 此channel已经close
cases = append(cases[:i], cases[i+1:]...)
continue
}
out <- v.Interface()
}
}()
return out
}
扇出模式
有扇入模式,就有扇出模式,扇出模式是和扇入模式相反的。
扇出模式只有一个输入源 Channel,有多个目标 Channel,扇出比就是 1 比目标 Channel 数的值,经常用在设计模式中的观察者模式中(观察者设计模式定义了对象间的一种一
对多的组合关系。这样一来,一个对象的状态发生变化时,所有依赖于它的对象都会得到通知并自动刷新)。在观察者模式中,数据变动后,多个观察者都会收到这个变更信号。
下面是一个扇出模式的实现。从源 Channel 取出一个数据后,依次发送给目标 Channel。
在发送给目标 Channel 的时候,可以同步发送,也可以异步发送:
func fanOut(ch <-chan interface{}, out []chan interface{}, async bool) {
go func() {
defer func() { //退出时关闭所有的输出chan
for i := 0; i < len(out); i++ {
close(out[i])
}
}()
for v := range ch { // 从输入chan中读取数据
v := v
for i := 0; i < len(out); i++ {
i := i
if async { //异步
go func() {
out[i] <- v // 放入到输出chan中,异步方式
}()
} else {
out[i] <- v // 放入到输出chan中,同步方式
}
}
}
}()
}
Stream
这里我来介绍一种把 Channel 当作流式管道使用的方式,也就是把 Channel 看作流 (Stream),提供跳过几个元素,或者是只取其中的几个元素等方法
func asStream(done <-chan struct{}, values ...interface{}) <-chan interface{} {
s := make(chan interface{}) //创建一个unbuffered的channel
go func() { // 启动一个goroutine,往s中塞数据
defer close(s) // 退出时关闭chan
for _, v := range values { // 遍历数组
select {
case <-done:
return
case s <- v: // 将数组元素塞入到chan中
}
}
}()
return s
}
流创建好以后,该咋处理呢?下面我再给你介绍下实现流的方法。
- takeN:只取流中的前 n 个数据;
- takeFn:筛选流中的数据,只保留满足条件的数据;
- takeWhile:只取前面满足条件的数据,一旦不满足条件,就不再取;
- skipN:跳过流中前几个数据;
- skipFn:跳过满足条件的数据;
- skipWhile:跳过前面满足条件的数据,一旦不满足条件,当前这个元素和以后的元素都
会输出给Channel的receiver。
func takeN(done <-chan struct{}, valueStream <-chan interface{}, num int) <-chan interface{} {
takeStream := make(chan interface{}) // 创建输出流
go func() {
defer close(takeStream)
for i := 0; i < num; i++ { // 只读取前num个元素
select {
case <-done:
return
case takeStream <- <-valueStream: //从输入流中读取元素
}
}
}()
return takeStream
}
Map-Reduce
单机单进程的 map-reduce 方法。map-reduce 分为两个步骤,第一步是映射(map),处理队列中的数据,第二步是规约 (reduce),把列表中的每一个元素按照一定的处理方式处理成结果,放入到结果队列中。
就像做汉堡一样,map 就是单独处理每一种食材,reduce 就是从每一份食材中取一部分,做成一个汉堡。
func mapChan(in <-chan interface{}, fn func(interface{}) interface{}) <-chan interface{} {
out := make(chan interface{}) //创建一个输出chan
if in == nil { // 异常检查
close(out)
return out
}
go func() { // 启动一个goroutine,实现map的主要逻辑
defer close(out)
for v := range in { // 从输入chan读取数据,执行业务操作,也就是map操作
out <- fn(v)
}
}()
return out
}
func reduce(in <-chan interface{}, fn func(r, v interface{}) interface{}) interface{} {
if in == nil { // 异常检查
return nil
}
out := <-in // 先读取第一个元素
for v := range in { // 实现reduce的主要逻辑
out = fn(out, v)
}
return out
}
// 生成一个数据流
func asStream(done <-chan struct{}) <-chan interface{} {
s := make(chan interface{})
values := []int{1, 2, 3, 4, 5}
go func() {
defer close(s)
for _, v := range values { // 从数组生成
select {
case <-done:
return
case s <- v:
}
}
}()
return s
}
func main() {
in := asStream(nil) // map操作: 乘以10
mapFn := func(v interface{}) interface{} { return v.(int) * 10 } // reduce操作: 对map的结果进行累加
reduceFn := func(r, v interface{}) interface{} { return r.(int) + v.(int) }
sum := reduce(mapChan(in, mapFn), reduceFn) //返回累加结果
fmt.Println(sum)
}