应单位要求需要参加某个考试,但考试需要从手机端登陆学习,1000多道题需要挨个刷一遍太过于麻烦,萌生了把题目和答案全部扒下来的想法,再用python做数据的清洗和梳理,最后整合出来所有的考试题库信息。
- 首先打开浏览器分析数据包,找到批量查询到的题目数据,在Response可以看到返回的数据,从中找一下关键题目,然后直接拷贝出来就行,这个请求包含所有数据,就不用再挨个模拟请求了。
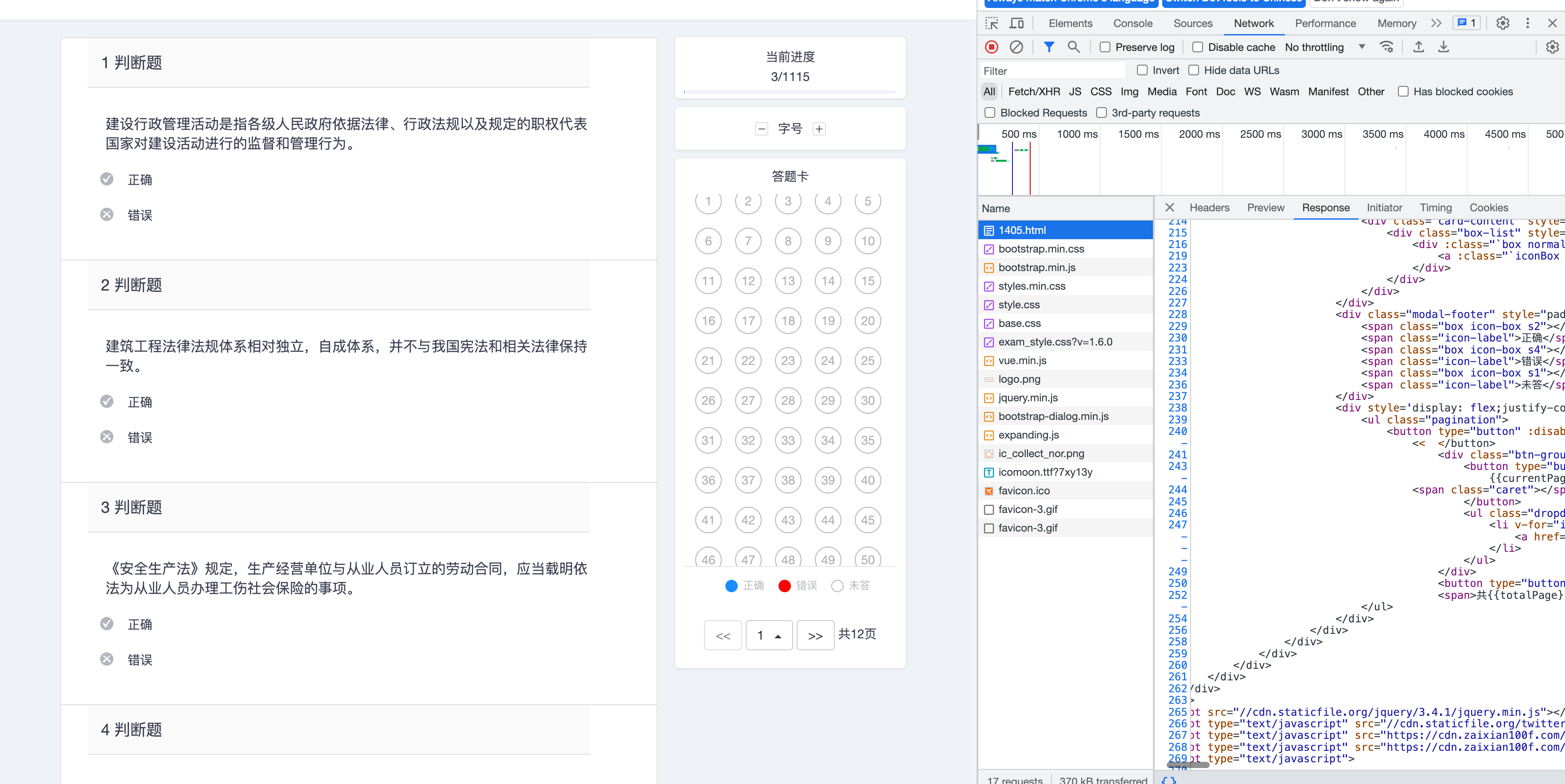
- 抓取到的数据太过于多,包含了各种html的信息,可以把题目的数据单独拷贝出来
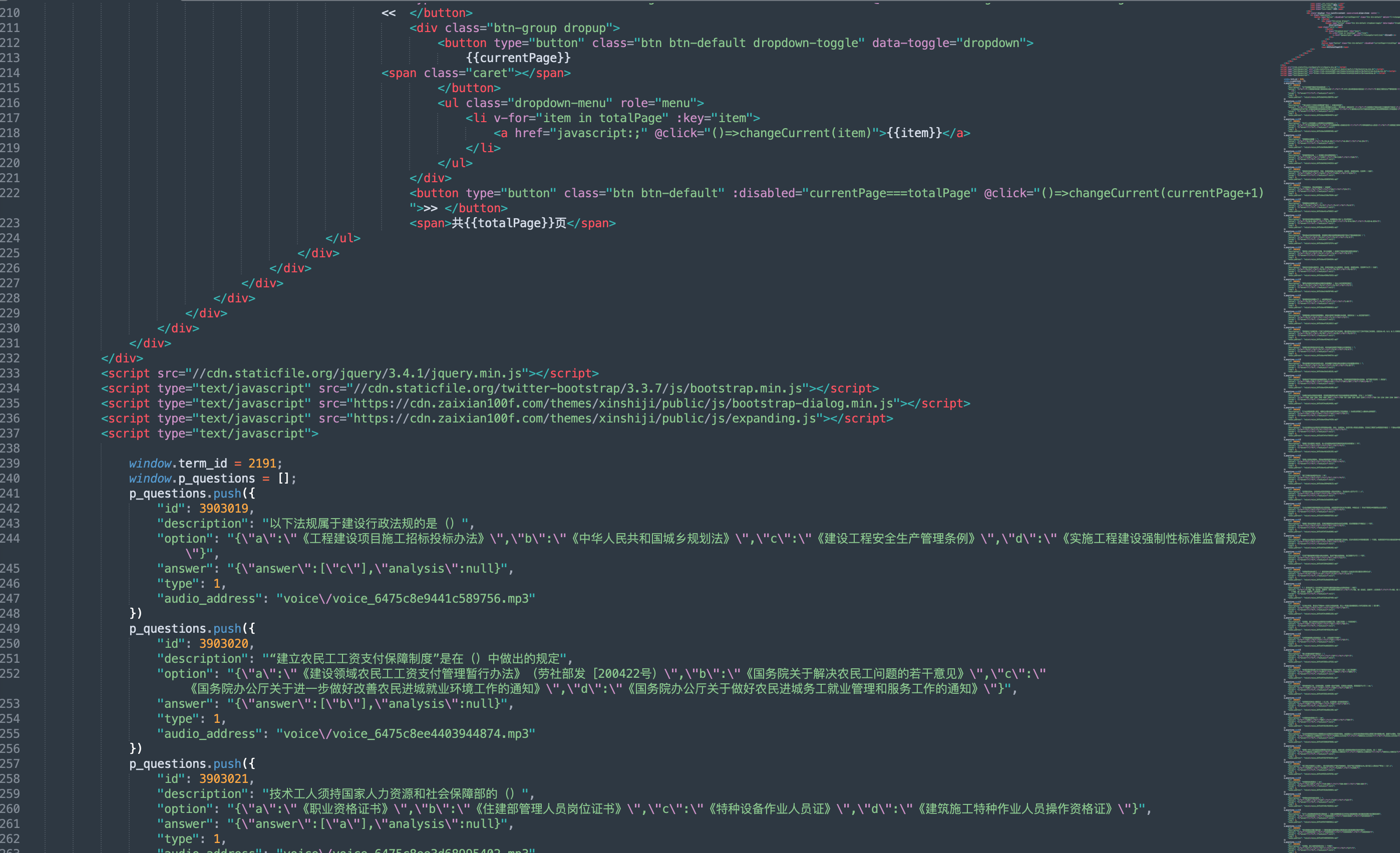
- 找到json数据的规律,让python批量解析json会容易很多,这里可以使用文本编辑器批量替换的功能,将"p_questions.push("替换成{, 再将"})"替换成"," ,这样就有了json的基本key-value结构,最后加上[]以列表形式呈现,这样就完成了数据的基本清洗。
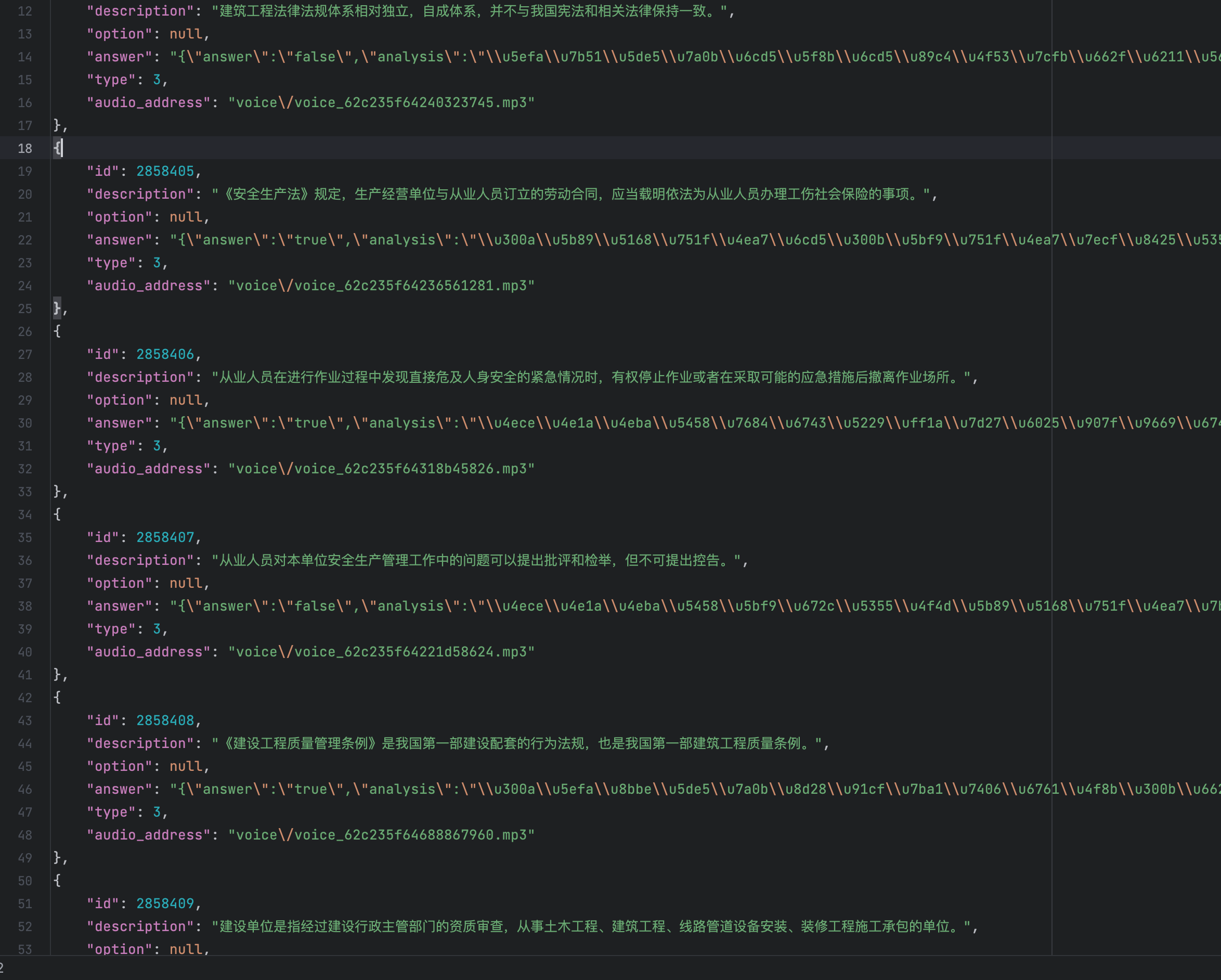
- 下面可以加载json文件,以json的形式处理数据列表,逐个分析每一项的每一个字段。这里可以加入一些异常捕获逻辑,防止某个错误阻断整体流程。
import json
# 读取文件中的JSON数据
def read_json_file(file_name):
with open(file_name, 'r') as f:
data = json.load(f)
return data
if __name__ == "__main__":
data = read_json_file('data/ti.json')
num = 1
for line in data:
print(str(num) + '. ' + line['description'])
num += 1
answer = json.loads(line['answer'])
if int(line['type']) == 3:
if str(answer['answer']) == 'false':
print('答案:错')
else:
print('答案:对')
elif int(line['type']) == 1 or int(line['type']) == 2:
option = json.loads(line['option'])
o_str = ''
for o in option:
o_str = o_str + o + ': ' + option[o] + '\n'
print('选项:\n' + o_str)
print('答案:' + str(answer['answer']))
if answer['analysis'] is not None:
print('解析:' + answer['analysis'])
最终将生成的数据导入word中,形成可以看的文档。