编者按:掩码图像建模(Masked Image Modeling, MIM)的提出,为计算机视觉模型训练引入无监督学习做出了重要贡献。得益于 MIM 的预训练算法,计算机视觉领域在近年来持续输出着优质的研究成果。然而整个业界对 MIM 机制的研究仍存在不足。
秉持着不断扩展前沿技术边界的探索精神,微软亚洲研究院的研究员们在理解 MIM 作用机制,以及基于这些机制提升现有 MIM 算法的领域,取得了一系列的创新成果,并获得了 CVPR 2023 的认可。这些成果包含:基于 MIM 预训练方法的扩展法则研究、分析 MIM 的具体性质以及有效性背后的原因、通过蒸馏技术将 MIM 模型的优势拓展到小模型中。
让我们一起了解 MIM 助推计算机视觉研究进入加速道的新发现吧!
预训练-微调(Pre-training and Fine-tuning)是过去十年计算机视觉中最重要的学习范式之一,其基本想法是在海量数据的任务中,对神经网络进行训练,然后再将预训练过的模型在下游数据量较少的任务中进行微调。这种方式能够将上游大数据任务中学到的信息迁移至下游数据量较少的任务上,缓解数据量不足的问题,并显著提升模型的性能。
预训练-微调范式的成功,源于计算机视觉领域十年来预训练算法的停滞。自2012年 AlexNet 提出以来,计算机视觉中的预训练算法在很大程度上被等价于以 ImageNet 数据集为代表的图像分类任务。尽管图像分类的数据标注成本已然较低,但后续的数据清洗、质量控制等步骤仍对扩展图像分类数据产生了挑战,而数据不足的困难也限制了计算机视觉模型的进一步扩大。因此,如何使用无监督学习方法进行视觉模型的预训练逐渐成为了计算机视觉任务中的核心问题。

图1:预训练-微调范式
2021年6月,微软亚洲研究院提出的 BEiT 方法,通过引入自然语言处理(NLP)中的掩码语言建模(Masked Language Modeling, MLM)算法,成功地证明了计算机视觉中无监督预训练可以达到与有监督预训练相同甚至更好的效果。2021年11月,微软亚洲研究院提出的 SimMIM 与 Meta 提出的 MAE 进一步简化了 BEiT,并提升了算法性能。自此,掩码图像建模(Masked Image Modeling, MIM)的研究范式正式开启。
虽然基于 MIM 的预训练算法的成果在计算机视觉领域内百花齐放,但对 MIM 机制的探索仍然十分匮乏。今天我们将介绍微软亚洲研究院视觉计算组在理解 MIM 作用机制,以及基于这些机制扩展并提升现有 MIM 算法的系列工作。
探索 MIM 的扩展法则与数据可扩展性
扩展法则(scaling law)的概念最初由 OpenAI 发表于2020年的“Scaling Laws for Neural Language Models”,文中提出:测试集上的 Loss 会随着计算(compute)、数据规模(dataset size)与模型参数量(parameters)的增加而呈现可以预测的下降模式。该发现对于如何优化自然语言模型的设计与训练,具有里程碑式的指导意义。

图2:自然语言处理中的扩展法则:测试集 Loss 随着计算,数据规模以及模型参数的增加呈现可以预测的下降模式
在入选 CVPR 2023 的“On Data Scaling in Masked Image Modeling”(论文链接:https://arxiv.org/abs/2206.04664)一文中,微软亚洲研究院的研究员们也探索了基于 MIM 预训练方法的扩展法则。尽管在计算与模型大小这两个维度中,MIM 预训练算法也呈现了较好的扩展性质,但是在数据维度上,MIM 算法则呈现了与在 NLP 中截然不同的特性:测试集的 Loss 随着数据集大小达到一定规模后不再降低,呈饱和状。这引发了一个关键问题——作为一个无监督预训练算法,MIM 是否能从更多的数据中受益?换言之,MIM 是否具有数据可扩展性?
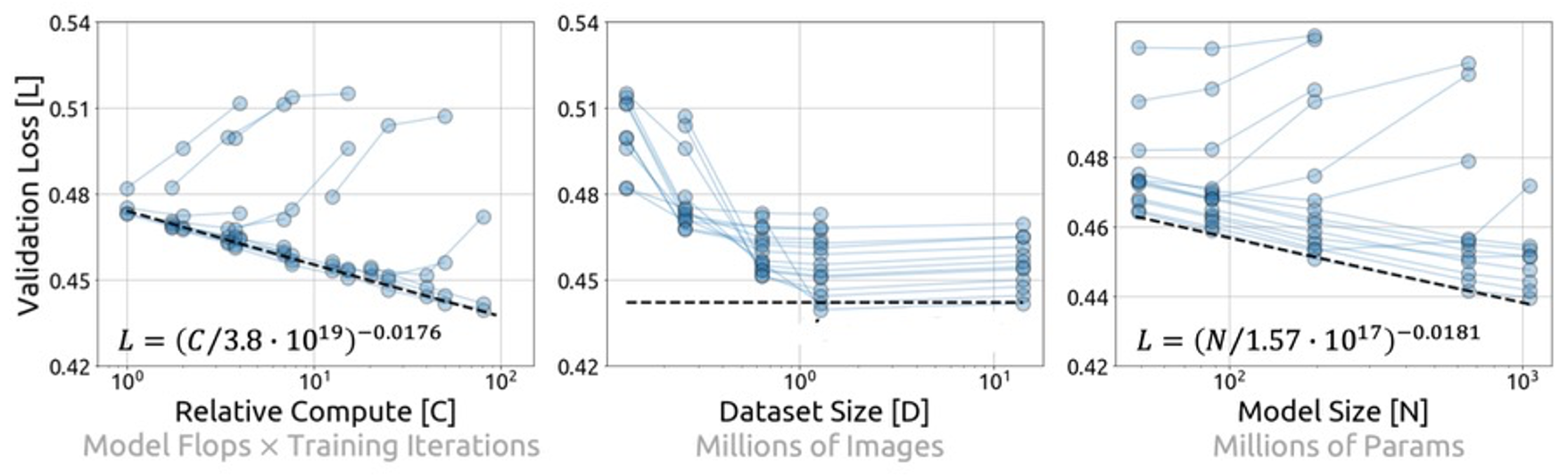
图3:MIM 中的扩展法则:测试集 Loss 仅随着计算与模型参数的增加呈现可预测的下降模式,而在数据集大小维度上,呈现了饱和的现象
为了回答该问题,研究员们分析了模型大小、数据规模以及训练长度的影响,发现 MIM 具有数据可扩展性,但需要满足两个关键的条件:1)需要更大的模型;2)需要配以更长的训练轮数。进一步的观察表明,该现象是由过拟合(over-fitting)导致的。
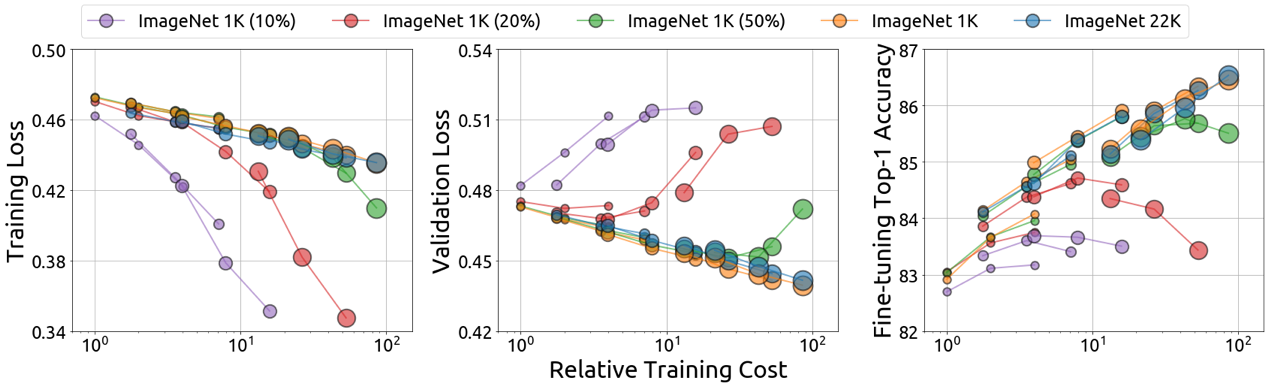
图4:MIM 中的过拟合现象
如图4所示,对一些较大的模型,使用小数据与长训练轮数会使得训练 Loss 异常下降,测试 Loss 与下游任务中的微调性能受损。同时,过拟合状态时,模型更倾向于呈现记忆图像的性质;非过拟合状态时,更倾向呈现推理的性质。基于这些发现,研究员们认为对于 MIM 而言,测试集 Loss 比训练 Loss 更适合作为下游任务迁移能力的代理指标。

图5:展示了过拟合模型与非过拟合模型对图片补全的可视化结果。过拟合模型在训练集上会记忆原图,而在测试集上则无法正确的推理内容。非过拟合模型则在训练集与测试集图像上都表现出较好的推理能力。
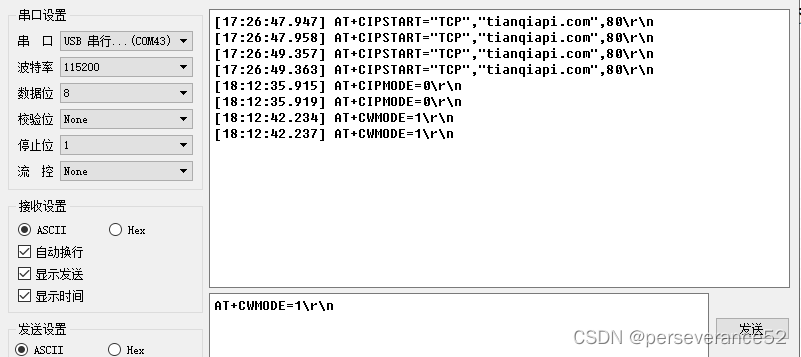
更深入地理解 MIM 及其有效性
MIM 展示了其在预训练-微调范式下的广泛有效性。传统视角通常认为模型的有效性取决于其提取的特征质量。然而,进一步实验发现,在固定网络权重的设定时,MIM 的性能远逊色于其他预训练算法。这说明 MIM 的有效性源自其他因素。

表1:在固定网络权重(frozen setting)与微调全网络权重(full fine-tuning setting)下,比较不同预训练算法的性能
于是,在微软亚洲研究院入选 CVPR 2023 的另一篇论文“Revealing the Dark Secrets of Masked Image Modeling”中(论文链接:https://arxiv.org/abs/2205.13543),研究员们对 MIM 的性质以及有效性背后的原因进行了更细致的研究与分析,取得了如下发现:
1) 有监督预训练以及基于对比学习的预训练方法的深层网络仅建模长程信息,相比之下,MIM 能够对局部信息与长程信息同时建模,如图6所示。
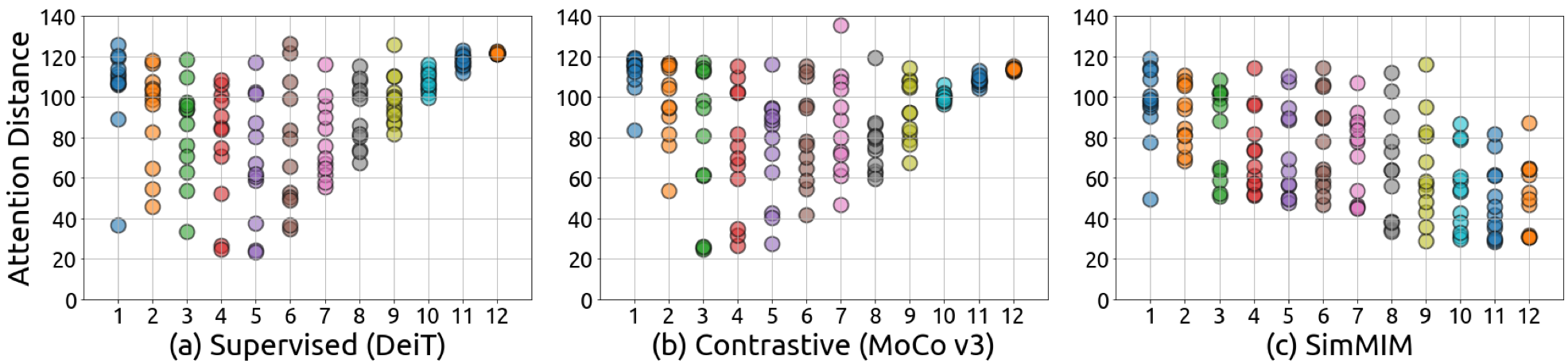
图6:不同模型中的注意力距离(attention distance)。有监督预训练与对比学习预训练算法在网络的深层只关注长程信息,而 MIM 方法同时关注长程信息与局部信息。
2) MIM 中不同注意力头(attention head)关注的信息具有多样,如图7所示,在有监督预训练与对比学习预训练算法中,网络的较深层注意力模块里,不同注意力头关注的信息是趋同的,而在 MIM 中,不同注意力头关注的信息更多样,这在一定程度上避免了模型塌陷(model collapse)的问题。
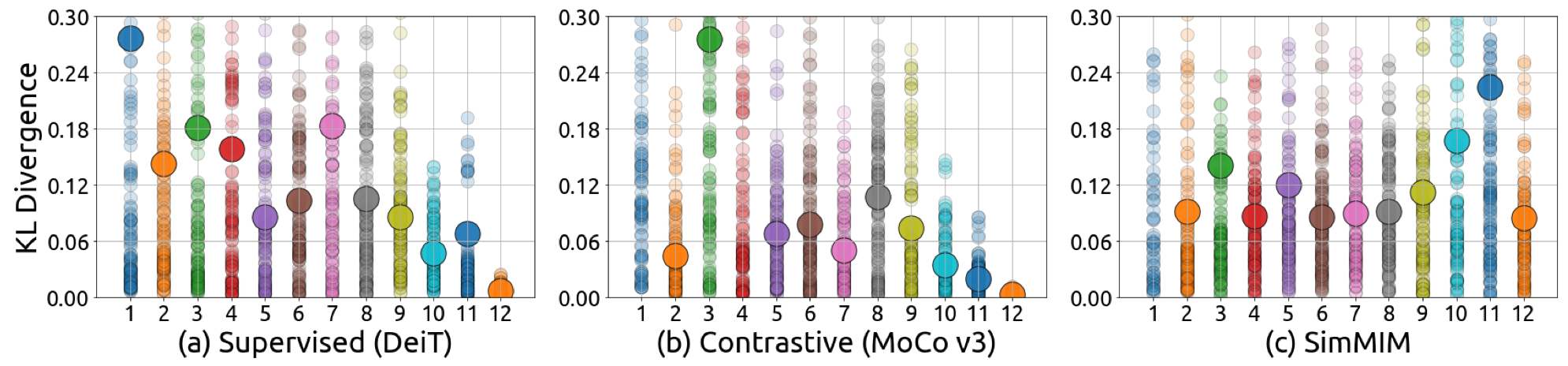
图7:不同模型中注意力头对应的注意力地图(attention map)的多样性分析
3) MIM 对语义信息的刻画较少,但是对几何信息的刻画较多。因此,研究员们对比了监督学习与 MIM 在语义分类任务中和几何任务中的性能表现。结果显示 MIM 在语义分类任务中的性能表现较差,但是在几何任务中的性能表现较好,如表2所示。同时,研究员们还考察了在混合任务(如物体检测)中,MIM 与有监督预训练在分类与定位两个子任务上的性能变化情况(如图8所示)。结果也显示 MIM 在分类任务上的收敛速度比有监督预训练差,但是在定位任务上收敛性更好。

表2:(左)语义分类任务的性能比较;(右)几何任务的性能比较

图8:物体检测任务中的分类损失与定位损失
扩展 MIM 在小模型上的有效性
在关于 MIM 的早期论文中,科研人员普遍发现 MIM 方法对大模型更加友好,直接在小模型中使用的有效性欠佳。如表3所示,在 ViT-T 等较小的模型中使用 MIM 预训练算法,其性能甚至落后于随机初始化的模型。如何将 MIM 应用于小模型,是领域中一个重要的开放性问题。在另外一篇入选 CVPR 2023 的工作“TinyMIM: An Empirical Study of Distilling MIM Pre-trained Models”中(论文链接:https://arxiv.org/abs/2301.01296),微软亚洲研究院的研究员们通过蒸馏(distillation)技术,成功将 MIM 模型的优势拓展到了小模型中。
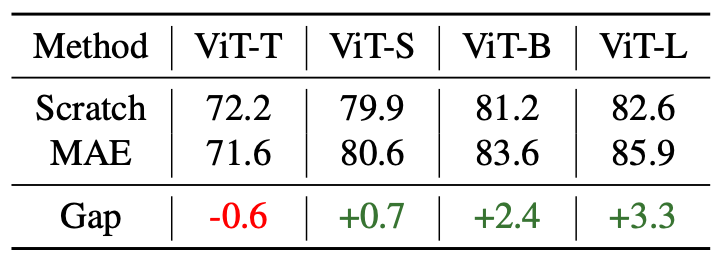
表3:不同大小模型下,使用 MIM 预训练与随机初始化模型的性能比较
TinyMIM 中,研究员们系统性地研究了如何使用经过 MIM 预训练的模型蒸馏至小模型中。其研究对象包括输入形式,蒸馏对象,以及蒸馏方法三个方面。通过广泛的实验,研究人员发现:
1) 直接蒸馏元素间的关系(relation)是 MIM 中最有效的蒸馏方式,其性能可以比蒸馏 CLS Token 在 ViT-T 上好4.2 Top-1 Acc,在 ViT-B 上好1.6 Top-1 Acc.

表4:不同蒸馏对象对结果的影响
2) 在蒸馏时引入 MIM 任务会损害性能。如表5所示,使用掩码图像作为输入,以及在蒸馏时引入图像重构任务,都会损害模型的蒸馏效果。
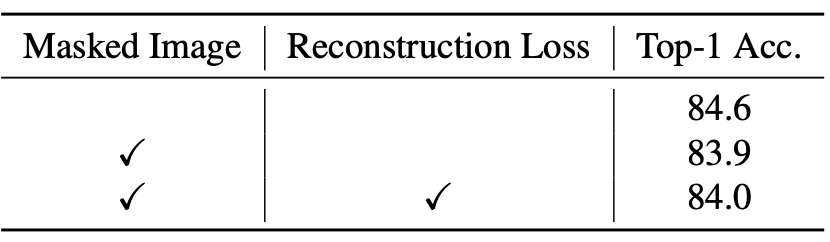
表5:蒸馏时引入 MIM 任务对性能的影响。
3) 序列化蒸馏可以进一步降低难度,提升性能。序列化蒸馏指的是使用小模型蒸馏大模型的过程中,引入中等规模模型进行蒸馏,即先蒸馏出一个中等大小的模型,再利用该模型去蒸馏小模型。这样的蒸馏方式可以获得更好的性能,如表6所示。

表6:序列化蒸馏对结果的影响
结合上述发现,TinyMIM 在一系列中小型模型中均取得了显著的性能提升,相较于其他直接训练的小模型,如 MobileViT 等,也取得了更好的下游任务迁移能力,如图9所示。
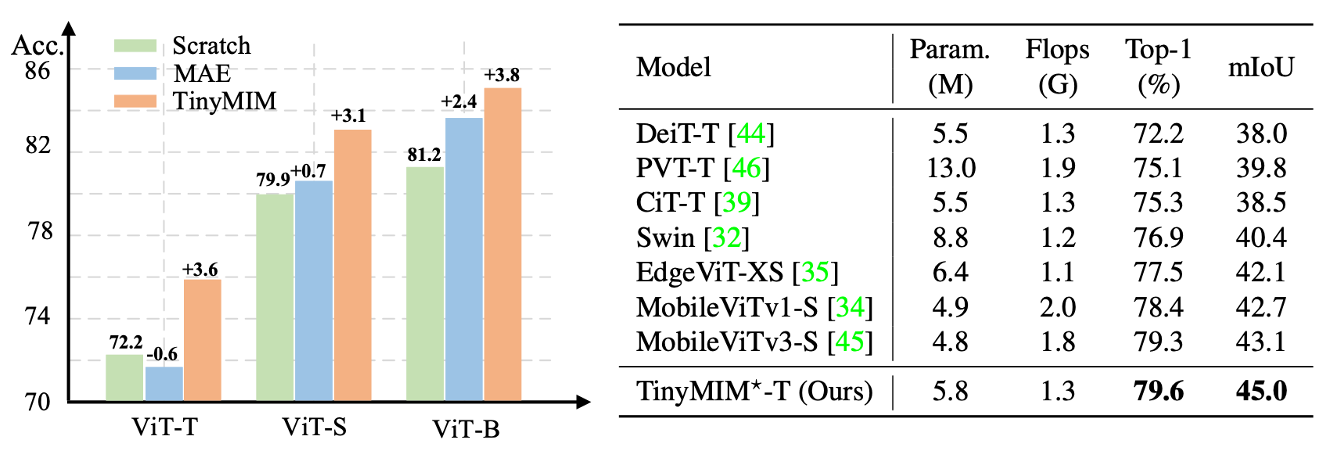
图9:TinyMIM 相较于 MAE 与其他小模型设计方法均取得了显著的性能优势
展望未来
随着计算机视觉中预训练范式从有监督学习逐渐演变至自监督学习,科研人员对视觉智能的认识与理解也在不断改变与深化。现阶段,基于掩码图像建模(MIM)的图像预训练算法已经展现出无监督预训练强大的潜力,但是否存在更适合视觉信号的预训练方法仍然是领域内最重要的开放问题之一。此外,在视觉与语言大一统的发展趋势之下,如何有效利用掩码信号建模等预训练算法高效连接语言与视觉信号的问题也仍需探索。微软亚洲研究院的研究员们希望随着对掩码图像建模预训练算法理解与认识的深化,研究并提出更高效的预训练算法,促进视觉智能迈入下一个发展新阶段。