目录
目的
用户电影推荐矩阵主要思路如下
1 UserId 和 MovieID 做笛卡尔积,产生(uid,mid)的元组
2 通过模型预测(uid,mid)的元组。
3 将预测结果通过预测分值进行排序。
4 返回分值最大的 K 个电影,作为当前用户的推荐。
5 排序根据余弦相似度进行排序;
6 用均方根误差RMSE进行模型评估和参数调整 ;
由于电影的特征是稳定不变的,所以离线训练电影相似矩阵,节约实时计算时间。
完整代码
offlineRecommender.scala
ALSTrainer.scala
目的
训练出用户电影推荐矩阵,电影相似度矩阵。
用户电影推荐矩阵主要思路如下
1 UserId 和 MovieID 做笛卡尔积,产生(uid,mid)的元组
val userMovies = userRDD.cartesian(movieRDD)2 通过模型预测(uid,mid)的元组。
3 将预测结果通过预测分值进行排序。
4 返回分值最大的 K 个电影,作为当前用户的推荐。
核心代码
val preRatings = model.predict(userMovies)
val userRecs = preRatings
.filter(_.rating > 0)
.map(rating => (rating.user, (rating.product, rating.rating)))
.groupByKey()
.map {
case (uid, recs) => UserResc(uid, recs.toList
.sortWith(_._2 > _._2)
.take(USER_MAX_RECOMMENDATION)
.map(
x => Recommendation(x._1, x._2)
)
)
}
.toDF()5 排序根据余弦相似度进行排序;
6 用均方根误差RMSE进行模型评估和参数调整 ;
均方根误差RMSE公式
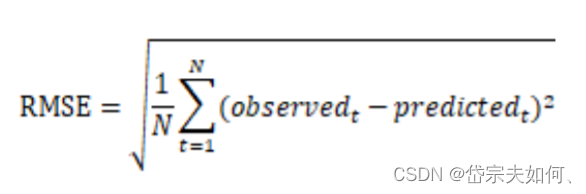
核心代码
def adjustALSParam(trainRDD: RDD[Rating], testRDD: RDD[Rating]): Unit = {
val result = for (rank <- Array(50, 100, 200, 300); lambda <- Array(0.01, 0.1, 1 ))
yield {
val model = ALS.train(trainRDD, rank, 5, lambda)
val rmse = getRMSE(model, testRDD)
(rank, lambda, rmse)
}
println(result.minBy(_._3)由于电影的特征是稳定不变的,所以离线训练电影相似矩阵,节约实时计算时间。
核心代码
val movieFeatures = model.productFeatures.map{
case (mid, feature) => (mid, new DoubleMatrix(feature))
}
val movieRecs = movieFeatures.cartesian(movieFeatures)
.filter{
case (a,b ) => a._1 != b._1
}
.map{
case(a, b) => {
val simScore = this.consinSim(a._2, b._2)
( a._1, (b._1, simScore) )
}
}
.filter(_._2._2 > 0.6)
.groupByKey()
.map{
case (mid, item) => MoiveResc(mid, item
.toList
.sortWith(_._2 > _._2)
.map(x => Recommendation(x._1, x._2)))
}
.toDF()完整代码
offlineRecommender.scala
package com.qh.offline
import org.apache.spark.SparkConf
import org.apache.spark.mllib.recommendation.{ALS, Rating}
import org.apache.spark.sql.SparkSession
import org.jblas.DoubleMatrix
//跟sparkMl 里面区分
case class MovieRating(uid: Int, mid: Int, score: Double, timestamp: Int)
case class MongoConfig(uri: String, db: String)
//基准推荐对象
case class Recommendation(mid: Int, score: Double)
//基于预测评分的用户推荐列表
case class UserResc(uid: Int, recs: Seq[Recommendation]) //类别, top10基准推荐对象
//基于LFM电影特征向量的电影相似度列表
case class MoiveResc(mid: Int, recs: Seq[Recommendation])
/**
* 基于隐语义模型的协同过滤 推荐
*
* 用户电影推荐矩阵
* 通过ALS训练出来的Model计算所有当前用户电影的推荐矩阵
* 1. UserID和MovieId做笛卡尔积
* 2. 通过模型预测uid,mid的元组
* 3. 将预测结果通过预测分值进行排序
* 4. 返回分值最大的K个电影,作为推荐
* 生成的数据结构 存到UserRecs表中
*
* 电影相似度矩阵
* 模型评估和参数选取
*
*/
object offline {
val MONGODB_RATING_COLLECTION = "Rating"
val USER_RECS = "UserRecs"
val MOVIE_RECS = "MovieRecs"
val USER_MAX_RECOMMENDATION = 20
def main(args: Array[String]): Unit = {
val config = Map(
"spark.cores" -> "local[*]",
"mongo.uri" -> "mongodb://hadoop100:27017/recommender",
"mongo.db" -> "recommender"
)
val sparkConf = new SparkConf().setMaster(config("spark.cores")).setAppName("offline")
val spark = SparkSession.builder().config(sparkConf).getOrCreate()
import spark.implicits._
implicit val mongoConfig = MongoConfig(config("mongo.uri"), config("mongo.db"))
//加载数据
val ratingRDD = spark.read
.option("uri", mongoConfig.uri)
.option("collection", MONGODB_RATING_COLLECTION)
.format("com.mongodb.spark.sql")
.load()
.as[MovieRating]
.rdd
.map(rating => (rating.uid, rating.mid, rating.score)) //去掉时间戳
.cache() //缓存,诗酒花在内存中
//预处理
val userRDD = ratingRDD.map(_._1).distinct()
val movieRDD = ratingRDD.map(_._2).distinct()
//训练LFM
val trainData = ratingRDD.map(x => Rating(x._1, x._2, x._3))
val (rank, iterations, lambda) = (200, 5, 0.1)
val model = ALS.train(trainData, rank, iterations, lambda)
//基于用户和电影的隐特征,计算预测评分,得到用户的推荐列表
// 笛卡尔积空矩阵
val userMovies = userRDD.cartesian(movieRDD)
//预测
val preRatings = model.predict(userMovies)
val userRecs = preRatings
.filter(_.rating > 0)
.map(rating => (rating.user, (rating.product, rating.rating)))
.groupByKey()
.map {
case (uid, recs) => UserResc(uid, recs.toList
.sortWith(_._2 > _._2)
.take(USER_MAX_RECOMMENDATION)
.map(
x => Recommendation(x._1, x._2)
)
)
}
.toDF()
userRecs.write
.option("uri", mongoConfig.uri)
.option("collection", USER_RECS)
.mode("overwrite")
.format("com.mongodb.spark.sql")
.save()
//基于电影隐特征,计算相似度矩阵,得到电影的相似度列表
val movieFeatures = model.productFeatures.map{
case (mid, feature) => (mid, new DoubleMatrix(feature))
}
//电影与电影 笛卡尔积
val movieRecs = movieFeatures.cartesian(movieFeatures)
.filter{
case (a,b ) => a._1 != b._1
}
.map{
case(a, b) => {
val simScore = this.consinSim(a._2, b._2)
( a._1, (b._1, simScore) )
}
}
.filter(_._2._2 > 0.6) //过滤出相似度
.groupByKey()
.map{
case (mid, item) => MoiveResc(mid, item
.toList
.sortWith(_._2 > _._2)
.map(x => Recommendation(x._1, x._2)))
}
.toDF()
movieRecs.write
.option("uri", mongoConfig.uri)
.option("collection", MOVIE_RECS)
.mode("overwrite")
.format("com.mongodb.spark.sql")
.save()
spark.stop()
}
/*
求解余弦相似度
*/
def consinSim(matrixA: DoubleMatrix, matrixB: DoubleMatrix):Double = {
// .dot 点乘 .norm2 L2范数,就是模长
matrixA.dot(matrixB) / (matrixA.norm2() * matrixB.norm2())
}
}ALSTrainer.scala
package com.qh.offline
import breeze.numerics.sqrt
import com.qh.offline.offline.MONGODB_RATING_COLLECTION
import org.apache.spark.mllib.recommendation.{ALS, MatrixFactorizationModel, Rating}
import org.apache.spark.SparkConf
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.SparkSession
/**
* 调参
* 通过ALS寻找lMF参数,打印到控制台输出
*/
object ALSTrainer {
def main(args: Array[String]): Unit = {
val config = Map(
"spark.cores" -> "local[*]",
"mongo.uri" -> "mongodb://hadoop100:27017/recommender",
"mongo.db" -> "recommender"
)
val sparkConf = new SparkConf().setMaster(config("spark.cores")).setAppName("offline")
val spark = SparkSession.builder().config(sparkConf).getOrCreate()
import spark.implicits._
implicit val mongoConfig = MongoConfig(config("mongo.uri"), config("mongo.db"))
val ratingRDD = spark.read
.option("uri", mongoConfig.uri)
.option("collection", MONGODB_RATING_COLLECTION)
.format("com.mongodb.spark.sql")
.load()
.as[MovieRating]
.rdd
.map(rating => Rating(rating.uid, rating.mid, rating.score)) //去掉时间戳
.cache()
// 随机切分数据集=>训练集 测试集
val splits = ratingRDD.randomSplit(Array(0.8, 0.2))
val trainRDD = splits(0)
val testRDD = splits(1)
// 模型参数选择
adjustALSParam(trainRDD, testRDD)
spark.close()
}
def adjustALSParam(trainRDD: RDD[Rating], testRDD: RDD[Rating]): Unit = {
val result = for (rank <- Array(50, 100, 200, 300); lambda <- Array(0.01, 0.1, 1 ))
yield {
val model = ALS.train(trainRDD, rank, 5, lambda)
val rmse = getRMSE(model, testRDD)
(rank, lambda, rmse)
}
println(result.minBy(_._3))
}
def getRMSE(model: MatrixFactorizationModel, data: RDD[Rating]): Double = {
// 计算预测评分
val userProducts = data.map(item => (item.user, item.product))
val predictRating = model.predict(userProducts)
//uid 和 mid 交集 做被减数
val observed = data.map(item => ((item.user, item.product), item.rating)) //实际观测值和预测值
val predict = predictRating.map(item => ((item.user, item.product), item.rating))
sqrt(
observed.join(predict).map {
case ((uid, mid), (actual, pre)) => //内连接没有数据冗余,不需要groupby
val err = actual - pre
err * err
}.mean()
)
}
}