本文主要是对苏剑林老师之前的博客中,对相似度相关的内容稍作整理。
Sentence-bert
是利用bert对两个句子判断相似度。
左图是训练期间的相似度计算方法,右图是推来过程中的相似度计算方法。
训练过程中使用时dense-linear方法,推理过程中使用的cosine方法。

注意到 一点,在u和v两个句子上,训练的时候,采用的是(u,v,|u-v|),其中,|u-v|可能与两个句子之间的相似值关联程度较大。
InferSent
有监督条件下的相似度判断模型。
- 比较在各种监督任务上训练的句子嵌入,并表明从在自然语言推理 (NLI) 任务上训练的模型生成的句子嵌入在迁移准确性方面达到了最佳结果。(论文在一些其他NLP任务中做了训练,比较了在其他任务中训练后的模型的词向量生成能力,最后,发现还是在NLI(natural language inference)任务中,效果比较好。)
- 研究了句子编码架构对表征可迁移性的影响,并比较了卷积、递归甚至更简单的单词组合方案,发现bi-directional LSTM architecture with max pooling, trained on the Stanford Natural Language Inference (SNLI) dataset上时,模型的表现效果最佳。

训练结构如下:

simBert
simbert=UniLM+Bert
采用的有监督的训练方式,整个任务建模为分类任务,相似的语句应该归为一类,不相似的语句归为一类。
在同一个batch中,把[CLS] SENT_a [SEP] SENT_b [SEP]和[CLS] SENT_b [SEP] SENT_a [SEP]都加入训练,做一个相似句的生成任务,这是Seq2Seq部分。
另一方面,把整个batch内的[CLS]向量都拿出来,得到一个句向量矩阵V∈Rb×dV∈Rb×d(bb是batch_size,dd是hidden_size),然后对dd维度做l2l2归一化,得到V~V~,然后两两做内积,得到b×bb×b的相似度矩阵V~V~⊤V~V~⊤,接着乘以一个scale(我们取了30),并mask掉对角线部分,最后每一行进行softmax,作为一个分类任务训练,每个样本的目标标签是它的相似句(至于自身已经被mask掉)。说白了,就是把batch内所有的非相似样本都当作负样本,借助softmax来增加相似样本的相似度,降低其余样本的相似度。
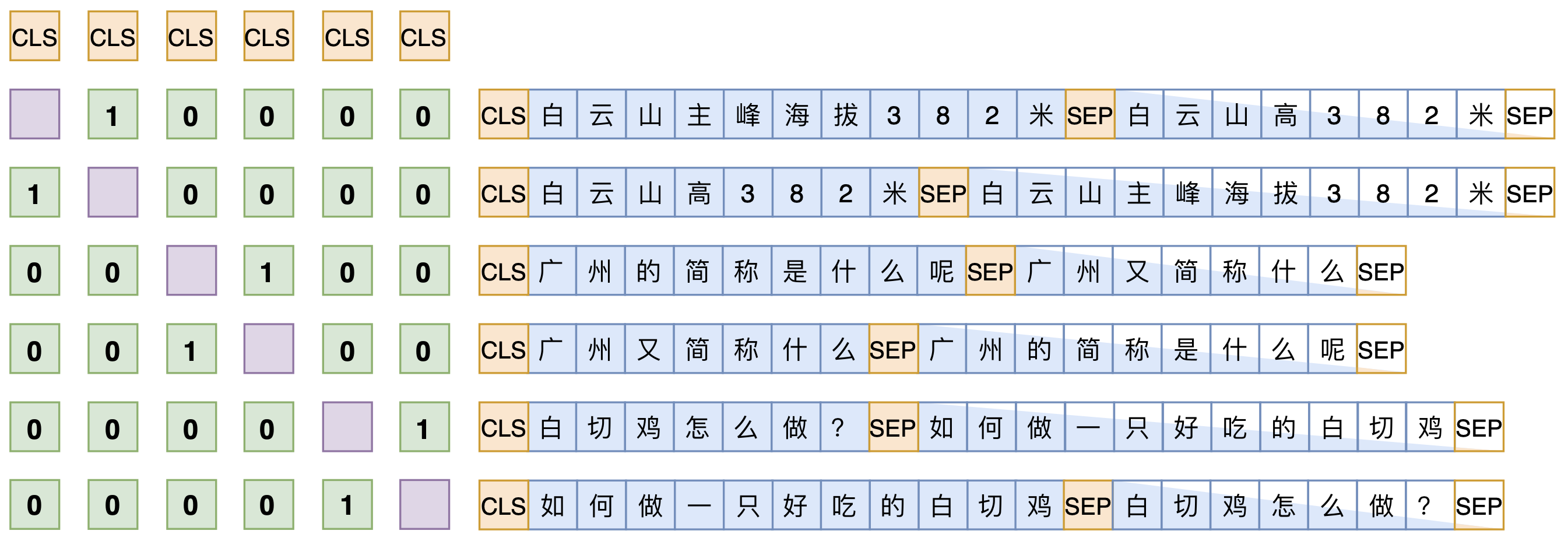
文本相似度数据
文本相似度比较中,数据一般是以句子对形式出现,如何学习句子对的表示?
原文链接:https://spaces.ac.cn/archives/8860
交互式(Interaction-based)和特征式(Representation-based)两种实现方案,其中交互式是指将两个文本拼接在一起当成单文本进行分类,而特征式则是指两个句子分别由编码器编码为句向量后再做简单的融合处理(算cos值或者接一个浅层网络)



![[附源码]Python计算机毕业设计Django在线影院系统](https://img-blog.csdnimg.cn/96950f8b6b57476cbfb3b57398eee355.png)
![[附源码]计算机毕业设计JAVA中小学微课学习系统](https://img-blog.csdnimg.cn/c08e2fb567794d0b82fffb3eebdc2247.png)