进NLP群—>加入NLP交流群
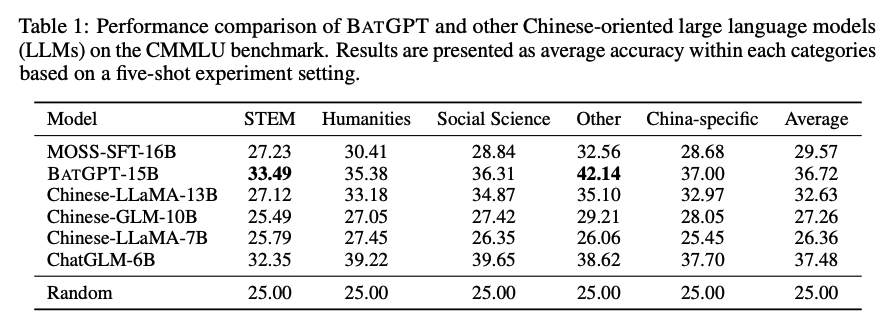
本论文介绍了一种名为BATGPT的大规模语言模型,由武汉大学和上海交通大学联合开发和训练。

该模型采用双向自回归架构,通过创新的参数扩展方法和强化学习方法来提高模型的对齐性能,从而更有效地捕捉自然语言的复杂依赖关系。

BATGPT在语言生成、对话系统和问答等任务中表现出色,是一种高效且多用途的语言模型。
BATGPT 的双向自回归架构如何帮助其捕获自然语言的复杂依赖关系?
BATGPT的双向自回归架构可以同时考虑输入序列的前后文信息,从而更好地捕捉自然语言的复杂依赖关系。
传统的自回归模型只能考虑输入序列的前面部分,而BATGPT的双向自回归架构可以同时考虑前面和后面的信息,从而更好地理解整个输入序列的语义。
这种架构可以有效地解决传统模型中存在的“有限记忆”和“幻觉”问题,提高模型的生成质量和对齐性能。
BATGPT在训练方面提出的参数扩展方法是什么,它是如何提高模型有效性的?
BATGPT在训练方面提出了一种参数扩展方法,即在较小的模型上进行预训练,然后将预训练的参数扩展到更大的模型中。
这种方法可以有效地利用较小模型的预训练参数,从而加速更大模型的训练过程,并提高模型的有效性。
此外,BATGPT还采用了强化学习方法,从AI和人类反馈中学习,以进一步提高模型的对齐性能。这些方法的结合可以显著提高BATGPT的生成质量和对齐性能,使其成为一种高效且多用途的语言模型。
BATGPT 是否可以用于语言生成、对话系统和问答之外的应用程序?
BATGPT表现稳健,能够处理不同类型的提示,因此它具有广泛的能力,并适用于广泛的应用程序。
虽然文中没有明确提到BATGPT是否可以用于语言生成、对话系统和问答之外的应用程序,但是它的广泛能力表明它可以用于其他类型的应用程序。
论文:
BATGPT: A Bidirectional Autoregessive Talker from Generative Pre-trained Transformer
地址:
https://arxiv.org/pdf/2307.00360.pdf

进NLP群—>加入NLP交流群