1 Stable Diffusion介绍
Stable Diffusion 是由CompVis、Stability AI和LAION共同开发的一个文本转图像模型,它通过LAION-5B子集大量的 512x512 图文模型进行训练,我们只要简单的输入一段文本,Stable Diffusion 就可以迅速将其转换为图像,同样我们也可以置入图片或视频,配合文本对其进行处理。

Stable Diffusion的发布是AI图像生成发展过程中的一个里程碑,相当于给大众提供了一个可用的高性能模型,不仅生成的图像质量非常高,运行速度快,并且有资源和内存的要求也较低。
Stable Diffusion Demo:demo

2 运行环境构建
2.1 conda环境安装
conda环境准备详见:annoconda
2.2 运行环境准备
git clone https://github.com/CompVis/stable-diffusion.git
cd stable-diffusion
conda env create -f environment.yaml
conda activate ldm
pip install diffusers==0.12.12.3 模型下载
(1)下载模型文件“sd-v1-4.ckpt”
模型地址:模型

完成后执行如下命令
mkdir -p models/ldm/stable-diffusion-v1/
mv sd-v1-4.ckpt model.ckpt
mv model.ckpt models/ldm/stable-diffusion-v1/
(2)下载checkpoint_liberty_with_aug.pth模型
模型地址:模型
下载完成后,模型放到cache文件夹下
mv checkpoint_liberty_with_aug.pth ~/.cache/torch/hub/checkpoints/(3)下载clip-vit-large-patch14模型
模型地址:模型
需要下载的模型文件如下:

创建模型的存储目录
mkdir -p openai/clip-vit-large-patch14下载完成后,把下载的文件移动到上面的目录下。
(4)下载safety_checker模型
模型地址:模型
需要下载模型文件如下:

创建模型文件的存储目录
mkdir -p CompVis/stable-diffusion-safety-checker下载完成后,把下载的文件移动到上面的目录下
将(3)中的preprocessor_config.json移动当前模型目录下:
mv openai/clip-vit-large-patch14/preprocessor_config.json CompVis/stable-diffusion-safety-checker/3 运行效果展示
3.1 运行文生图
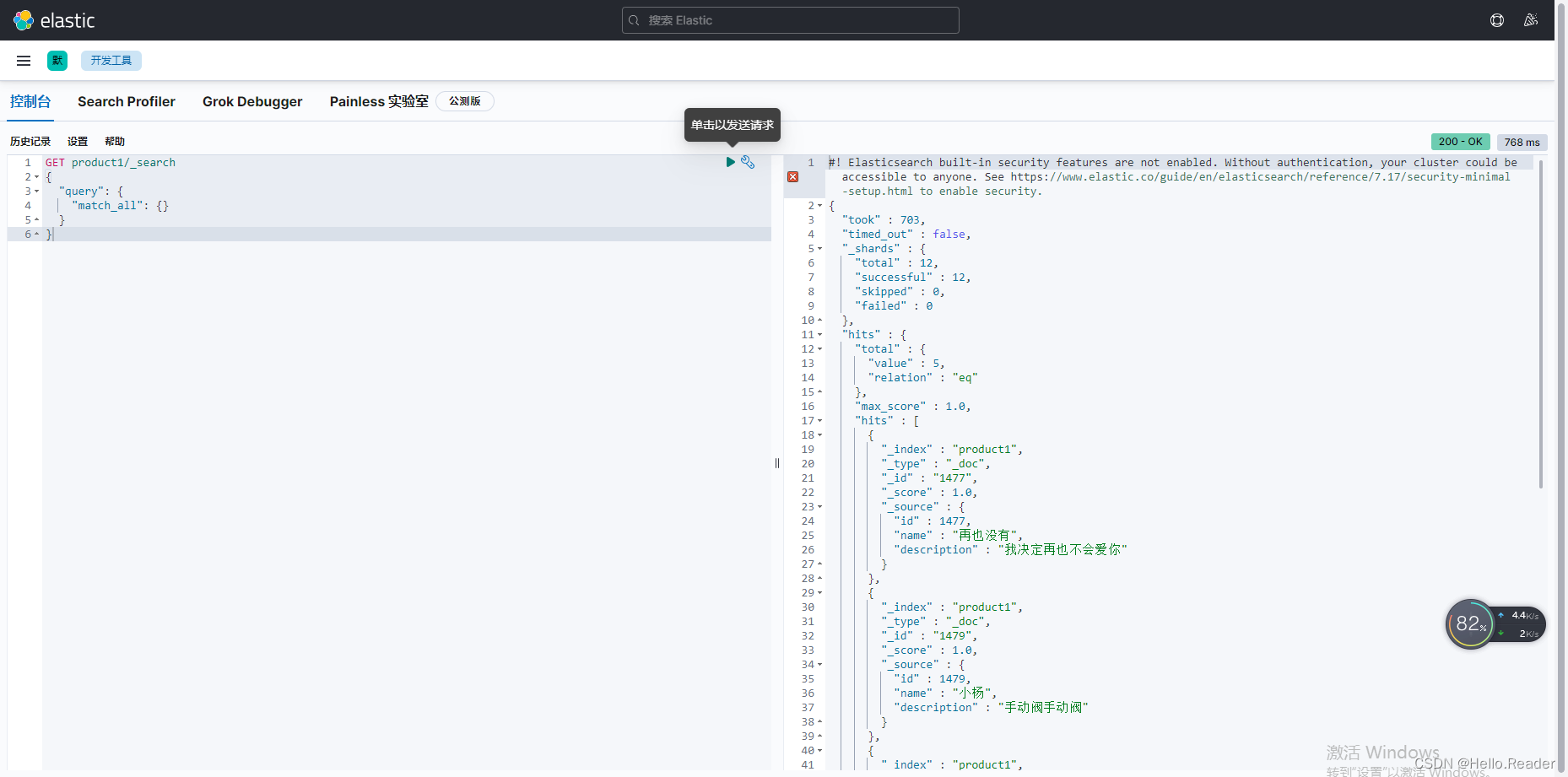
python scripts/txt2img.py --prompt "a photograph of an astronaut riding a horse" --plms 运行效果展示

txt2img.py参数
usage: txt2img.py [-h] [--prompt [PROMPT]] [--outdir [OUTDIR]] [--skip_grid] [--skip_save] [--ddim_steps DDIM_STEPS] [--plms] [--laion400m] [--fixed_code] [--ddim_eta DDIM_ETA]
[--n_iter N_ITER] [--H H] [--W W] [--C C] [--f F] [--n_samples N_SAMPLES] [--n_rows N_ROWS] [--scale SCALE] [--from-file FROM_FILE] [--config CONFIG] [--ckpt CKPT]
[--seed SEED] [--precision {full,autocast}]
optional arguments:
-h, --help show this help message and exit
--prompt [PROMPT] the prompt to render
--outdir [OUTDIR] dir to write results to
--skip_grid do not save a grid, only individual samples. Helpful when evaluating lots of samples
--skip_save do not save individual samples. For speed measurements.
--ddim_steps DDIM_STEPS
number of ddim sampling steps
--plms use plms sampling
--laion400m uses the LAION400M model
--fixed_code if enabled, uses the same starting code across samples
--ddim_eta DDIM_ETA ddim eta (eta=0.0 corresponds to deterministic sampling
--n_iter N_ITER sample this often
--H H image height, in pixel space
--W W image width, in pixel space
--C C latent channels
--f F downsampling factor
--n_samples N_SAMPLES
how many samples to produce for each given prompt. A.k.a. batch size
--n_rows N_ROWS rows in the grid (default: n_samples)
--scale SCALE unconditional guidance scale: eps = eps(x, empty) + scale * (eps(x, cond) - eps(x, empty))
--from-file FROM_FILE
if specified, load prompts from this file
--config CONFIG path to config which constructs model
--ckpt CKPT path to checkpoint of model
--seed SEED the seed (for reproducible sampling)
--precision {full,autocast}
evaluate at this precision3.2 运行图片转换
执行命令如下:
python scripts/img2img.py --prompt "A fantasy landscape, trending on artstation" --init-img assets/stable-samples/img2img/mountains-1.png --strength 0.8
4 问题解决
4.1 SAFE_WEIGHTS_NAME问题解决
运行txt2img,出现如下错误:
(ldm) [root@localhost stable-diffusion]# python scripts/txt2img.py --prompt "a photograph of an astronaut riding a horse" --plms
Traceback (most recent call last):
File "scripts/txt2img.py", line 22, in <module>
from diffusers.pipelines.stable_diffusion.safety_checker import StableDiffusionSafetyChecker
File "/root/anaconda3/envs/ldm/lib/python3.8/site-packages/diffusers/__init__.py", line 29, in <module>
from .pipelines import OnnxRuntimeModel
File "/root/anaconda3/envs/ldm/lib/python3.8/site-packages/diffusers/pipelines/__init__.py", line 19, in <module>
from .dance_diffusion import DanceDiffusionPipeline
File "/root/anaconda3/envs/ldm/lib/python3.8/site-packages/diffusers/pipelines/dance_diffusion/__init__.py", line 1, in <module>
from .pipeline_dance_diffusion import DanceDiffusionPipeline
File "/root/anaconda3/envs/ldm/lib/python3.8/site-packages/diffusers/pipelines/dance_diffusion/pipeline_dance_diffusion.py", line 21, in <module>
from ..pipeline_utils import AudioPipelineOutput, DiffusionPipeline
File "/root/anaconda3/envs/ldm/lib/python3.8/site-packages/diffusers/pipelines/pipeline_utils.py", line 67, in <module>
from transformers.utils import SAFE_WEIGHTS_NAME as TRANSFORMERS_SAFE_WEIGHTS_NAME
ImportError: cannot import name 'SAFE_WEIGHTS_NAME' from 'transformers.utils' (/root/anaconda3/envs/ldm/lib/python3.8/site-packages/transformers/utils/__init__.py)通过变更组件diffusers版本解决,命令如下:
pip install diffusers==0.12.14.2 不能连接到huggingface.co的解决办法
python scripts/txt2img.py --prompt "a photograph of an astronaut riding a horse" --plms
Traceback (most recent call last):
File "/root/anaconda3/envs/ldm/lib/python3.8/site-packages/transformers/feature_extraction_utils.py", line 403, in get_feature_extractor_dict
resolved_feature_extractor_file = cached_path(
File "/root/anaconda3/envs/ldm/lib/python3.8/site-packages/transformers/utils/hub.py", line 282, in cached_path
output_path = get_from_cache(
File "/root/anaconda3/envs/ldm/lib/python3.8/site-packages/transformers/utils/hub.py", line 545, in get_from_cache
raise ValueError(
ValueError: Connection error, and we cannot find the requested files in the cached path. Please try again or make sure your Internet connection is on.
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "scripts/txt2img.py", line 28, in <module>
safety_feature_extractor = AutoFeatureExtractor.from_pretrained(safety_model_id)
File "/root/anaconda3/envs/ldm/lib/python3.8/site-packages/transformers/models/auto/feature_extraction_auto.py", line 270, in from_pretrained
config_dict, _ = FeatureExtractionMixin.get_feature_extractor_dict(pretrained_model_name_or_path, **kwargs)
File "/root/anaconda3/envs/ldm/lib/python3.8/site-packages/transformers/feature_extraction_utils.py", line 436, in get_feature_extractor_dict
raise EnvironmentError(
OSError: We couldn't connect to 'https://huggingface.co' to load this model, couldn't find it in the cached files and it looks like CompVis/stable-diffusion-safety-checker is not the path to a directory containing a preprocessor_config.json file.
Checkout your internet connection or see how to run the library in offline mode at 'https://huggingface.co/docs/transformers/installation#offline-mode'.解决方法:
将模型下载到本地,过程详见2.3描述