HarmonyOS对象关系映射(Object Relational Mapping,ORM)数据库是一款基于SQLite的数据库框架,屏蔽了底层SQLite数据库的SQL操作,针对实体和关系提供了增删改查等一系列的面向对象接口。应用开发者不必再去编写复杂的SQL语句, 以操作对象的形式来操作数据库,提升效率的同时也能聚焦于业务开发。
基本概念
- 对象关系映射数据库的三个主要组件:
- 数据库:被开发者用@Database注解,且继承了OrmDatabase的类,对应关系型数据库。
- 实体对象:被开发者用@Entity注解,且继承了OrmObject的类,对应关系型数据库中的表。
- 对象数据操作接口:包括数据库操作的入口OrmContext类和谓词接口(OrmPredicate)等。
- 谓词
数据库中用来代表数据实体的性质、特征或者数据实体之间关系的词项,主要用来定义数据库的操作条件。对象关系映射数据库将SQLite数据库中的谓词封装成了接口方法供开发者调用。开发者通过对象数据操作接口,可以访问到应用持久化的关系型数据。
- 对象关系映射数据库
通过将实例对象映射到关系上,实现操作实例对象的语法,来操作关系型数据库。它是在SQLite数据库的基础上提供的一个抽象层。
- SQLite数据库
一款轻型的数据库,是遵守ACID的关系型数据库管理系统。
运作机制
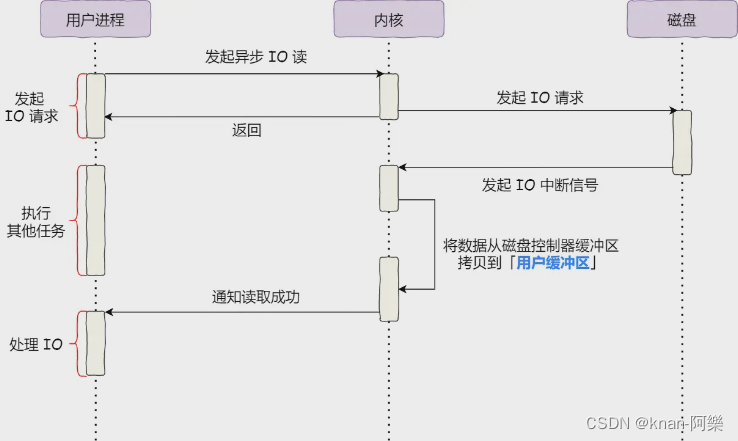
对象关系映射数据库操作是基于关系型数据库操作接口完成的,实际是在关系型数据库操作的基础上又实现了对象关系映射等特性。因此对象关系映射数据库跟关系型数据库一样,都使用SQLite作为持久化引擎,底层使用的是同一套数据库连接池和数据库连接机制。
使用对象关系映射数据库的开发者需要先配置实体模型与关系映射文件。应用数据管理框架提供的类生成工具会解析这些文件,生成数据库帮助类,这样应用数据管理框架就能在运行时,根据开发者的配置创建好数据库,并在存储过程中自动完成对象关系映射。开发者再通过对象数据操作接口,如OrmContext接口和谓词接口等操作持久化数据库。
对象数据操作接口提供一组基于对象映射的数据操作接口,实现了基于SQL的关系模型数据到对象的映射,让用户不需要再和复杂的 SQL语句打交道,只需简单地操作实体对象的属性和方法。对象数据操作接口支持对象的增删改查操作,同时支持事务操作等。
图1 对象关系映射数据库运作机制

默认配置
- 如果不指定数据库的日志模式,那么系统默认日志方式是WAL(Write Ahead Log)模式。
- 如果不指定数据库的落盘模式,那么系统默认落盘方式是FULL模式。
- HarmonyOS数据库使用的共享内存默认大小是2MB。
约束与限制
- 当应用使用对象关系映射数据库接口时,应用包和类的命名需要遵循典型的Java风格(小写包名,大驼峰类名)。
- HarmonyOS对象关系映射数据库是建立在HarmonyOS关系型数据库的基础之上。
- 此外当开发者建立实体对象类时,对象属性的类型可以在下表的类型中选择。不支持使用自定义类型。
| 类型名称 | 描述 | 初始值 |
|---|---|---|
| Integer | 封装整型 | null |
| int | 整型 | 0 |
| Long | 封装长整型 | null |
| long | 长整型 | 0L |
| Double | 封装双精度浮点型 | null |
| double | 双精度浮点型 | 0 |
| Float | 封装单精度浮点型 | null |
| float | 单精度浮点型 | 0 |
| Short | 封装短整型 | null |
| short | 短整型 | 0 |
| String | 字符串型 | null |
| Boolean | 封装布尔型 | null |
| boolean | 布尔型 | 0 |
| Byte | 封装字节型 | null |
| byte | 字节型 | 0 |
| Character | 封装字符型 | null |
| char | 字符型 | ' ' |
| Date | 日期类 | null |
| Time | 时间类 | null |
| Timestamp | 时间戳类 | null |
| Calendar | 日历类 | null |
| Blob | 二进制大对象 | null |
| Clob | 字符大对象 | null |
对象关系映射数据库开发
场景介绍
对象关系映射数据库适用于开发者使用的数据可以分解为一个或多个对象,且需要对数据进行增删改查等操作,但是不希望编写过于复杂的SQL语句的场景。
该对象关系映射数据库的实现是基于关系型数据库,除了数据库版本升降级等场景外,操作对象关系映射数据库一般不需要编写SQL语句,但是仍然要求使用者对于关系型数据库的基本概念有一定的了解。
开发能力介绍
对象关系映射数据库目前可以支持数据库和表的创建,对象数据的增删改查、对象数据变化回调、数据库升降级和备份等功能。
说明
对象关系映射数据库提供的接口在ohos.data.orm包中,使用该包中的接口时,要求配置文件config.json的“app > bundleName”字段的值,不能包含大写字母。
数据库和表的创建
- 创建数据库。开发者需要定义一个表示数据库的类,继承OrmDatabase,再通过@Database注解内的entities属性指定哪些数据模型类属于这个数据库。
属性:
- version:数据库版本号。
- entities:数据库内包含的表。
- 创建数据表。开发者可通过创建一个继承了OrmObject并用@Entity注解的类,获取数据库实体对象,也就是表的对象。
属性:
- tableName:表名。
- primaryKeys:主键名,一个表里只能有一个主键,一个主键可以由多个字段组成。
- foreignKeys:外键列表。
- indices:索引列表。
表1 注解对照表 接口名称
描述
@Database
被@Database注解且继承了OrmDatabase的类对应数据库类。
@Entity
被@Entity注解且继承了OrmObject的类对应数据表类。
@Column
被@Column注解的变量对应数据表的字段。
@PrimaryKey
被@PrimaryKey注解的变量对应数据表的主键。
@ForeignKey
被@ForeignKey注解的变量对应数据表的外键。
@Index
被@Index注解的内容对应数据表索引的属性。
打开数据库和数据库加密
- 打开数据库。开发者通过getOrmContext打开数据库。
表2 打开数据库API 类名
接口名
描述
DatabaseHelper
DatabaseHelper(Context context)
DatabaseHelper是数据库操作的辅助类,当数据库创建成功后,数据库文件将存储在由上下文指定的目录里。
- 获取上下文参考方法:context入参类型为ohos.app.Context,注意不要使用slice.getContext()来获取context,请直接传入slice,否则会出现找不到类的报错。
- 查看详细路径信息:ohos.app.Context#getDatabaseDir()。
DatabaseHelper
public <T extends OrmDatabase> OrmContext getOrmContext(String alias, String name, Class<T> ormDatabase, OrmMigration... migrations)
打开数据库,alias数据库别名,name数据库名称,ormDatabase数据库对应类,migrations数据库升级类。
DatabaseHelper
public <T extends OrmDatabase> OrmContext getOrmContext(OrmConfig ormConfig, Class<T> ormDatabase, OrmMigration... migrations)
打开数据库,ormConfig数据库配置,ormDatabase数据库对应类,migrations数据库升级类。
DatabaseHelper
public OrmContext getOrmContext(String alias)
根据别名打开数据库。
- 数据库加密。对象关系映射数据库提供数据库加密的能力,创建加密数据库时传入指定密钥,后续打开加密数据库时,需要传入正确密钥。
表3 数据库传入密钥API 类名
接口名
描述
OrmConfig.Builder
public OrmConfig.Builder setEncryptKey(byte[] encryptKey)
为数据库配置类设置数据库加密密钥,创建或打开数据库时传入包含数据库加密密钥的配置类,即可创建或打开加密数据库。
对象数据的增删改查
通过对象数据操作接口,开发者可以对对象数据进行增删改查操作。
| 类名 | 接口名 | 描述 |
|---|---|---|
| OrmContext | <T extends OrmObject> boolean insert(T object) | 添加方法。 |
| OrmContext | <T extends OrmObject> boolean update(T object) | 更新方法。 |
| OrmContext | <T extends OrmObject> List<T> query(OrmPredicates predicates) | 查询方法。 |
| OrmContext | <T extends OrmObject> boolean delete(T object) | 删除方法。 |
| OrmContext | <T extends OrmObject> OrmPredicates where(Class<T> clz) | 设置谓词方法。 |
事务提交和回滚
对象关系型数据库提供事务机制,来保证用户操作的原子性。对单条数据进行数据库操作时,无需开启事务;插入大量数据时,开启事务可以保证数据的准确性。如果中途操作出现失败,会自动执行回滚操作。
| 类名 | 接口名 | 描述 |
|---|---|---|
| OrmContext | void beginTransaction() | 开启事务。 |
| OrmContext | void commit() | 事务提交。 |
| OrmContext | void rollback() | 事务回滚。 |
| OrmContext | boolean isInTransaction() | 是否正在执行事务操作。 |
数据变化观察者设置
通过使用对象数据操作接口,开发者可以在某些数据上设置观察者,接收数据变化的通知。
| 类名 | 接口名 | 描述 |
|---|---|---|
| OrmContext | void registerStoreObserver(String alias, OrmObjectObserver observer) | 注册数据库变化回调。 |
| OrmContext | void registerContextObserver(OrmContext watchedContext, OrmObjectObserver observer) | 注册上下文变化回调。 |
| OrmContext | void registerEntityObserver(String entityName, OrmObjectObserver observer) | 注册数据库实体变化回调。 |
| OrmContext | void registerObjectObserver(OrmObject ormObject, OrmObjectObserver observer) | 注册对象变化回调。 |
数据库的升降级
通过调用数据库升降级接口,开发者可以将数据库切换到不同的版本。
| 类名 | 接口名 | 描述 |
|---|---|---|
| OrmMigration | public OrmMigration(int beginVersion, int endVersion) | 数据库升降级开始版本和结束版本。 |
| OrmMigration | public abstract void onMigrate( RdbStore store) | 数据库版本升降级方法。 |
| OrmMigration | public int getBeginVersion() | 获取开始版本。 |
| OrmMigration | public int getEndVersion() | 获取结束版本。 |
数据库的备份恢复
开发者可以将当前数据库的数据进行备份,在必要的时候进行数据恢复。
| 类名 | 接口名称 | 描述 |
|---|---|---|
| OrmContext | boolean backup(String destPath) | 数据库备份方法。 |
| OrmContext | boolean restore(String srcPath) | 数据库恢复备份方法。 |
开发步骤
配置“build.gradle”文件。
- 如果使用注解处理器的模块为“com.huawei.ohos.hap”模块,则需要在模块的“build.gradle”文件的ohos节点中添加以下配置:
compileOptions{
annotationEnabled true
} - 如果使用注解处理器的模块为“com.huawei.ohos.library”模块,则需要在模块的“build.gradle”文件的“dependencies”节点中配置注解处理器。
- 查看“orm_annotations_java.jar”、“orm_annotations_processor_java.jar” 、“javapoet_java.jar”这3个jar包在HUAWEI SDK中的Sdk/java/x.x.x.xx/build-tools/lib/目录,并将目录的这三个jar包导进来。
dependencies {
compile files("orm_annotations_java.jar的路径", "orm_annotations_processor_java.jar的路径", "javapoet_java.jar的路径")
annotationProcessor files("orm_annotations_java.jar的路径", "orm_annotations_processor_java.jar的路径", "javapoet_java.jar的路径")
}- 如果使用注解处理器的模块为“java-library”模块,则需要在模块的“build.gradle”文件的dependencies节点中配置注解处理器,并导入“ohos.jar”。
dependencies {
compile files("ohos.jar的路径","orm_annotations_java.jar的路径","orm_annotations_processor_java.jar的路径","javapoet_java.jar的路径")
annotationProcessor files("orm_annotations_java.jar的路径","orm_annotations_processor_java.jar的路径","javapoet_java.jar的路径")
}构造数据库,即创建数据库类并配置对应的属性。
例如,定义了一个数据库类BookStore.java,数据库包含了“User”,"Book","AllDataType"三个表,版本号为“1”。数据库类的getVersion方法和getHelper方法不需要实现,直接将数据库类设为虚类即可。
@Database(entities = {User.class, Book.class, AllDataType.class}, version = 1)
public abstract class BookStore extends OrmDatabase {
}构造数据表,即创建数据库实体类并配置对应的属性(如对应表的主键,外键等)。数据表必须与其所在的数据库在同一个模块中。
例如,定义了一个实体类User.java,对应数据库内的表名为“user”;indices 为“firstName”和“lastName”两个字段建立了复合索引“name_index”,并且索引值是唯一的;“ignoredColumns”表示该字段不需要添加到“user”表的属性中。
@Entity(tableName = "user", ignoredColumns = {"ignoredColumn1", "ignoredColumn2"},
indices = {@Index(value = {"firstName", "lastName"}, name = "name_index", unique = true)})
public class User extends OrmObject {
// 此处将userId设为了自增的主键。注意只有在数据类型为包装类型时,自增主键才能生效。
@PrimaryKey(autoGenerate = true)
private Integer userId;
private String firstName;
private String lastName;
private int age;
private double balance;
private int ignoredColumn1;
private int ignoredColumn2;
// 需添加各字段的getter和setter方法。
}说明
示例中的getter & setter 的方法名为小驼峰格式,除了手写方法,IDE中包含自动生成getter和setter方法的Generate插件。
- 当变量名的格式类似“firstName”时,getter和setter方法名应为“getFirstName”和“setFirstName”。
- 当变量名的格式类似“mAge”,即第一个字母小写,第二个字母大写的格式时,getter和setter方法名应为“getmAge”和“setmAge”。
- 当变量名格式类似“x”,即只有一个字母时,getter和setter方法名应为“getX”和“setX”。
变量为boolean类型时,上述规则仍然成立,即“isFirstName”,“ismAge”,“isX”。
使用对象数据操作接口OrmContext创建数据库。
例如,通过对象数据操作接口OrmContext,创建一个别名为“BookStore”,数据库文件名为“BookStore.db”的数据库。如果数据库已经存在,执行以下代码不会重复创建。通过context.getDatabaseDir()可以获取创建的数据库文件所在的目录。
// context入参类型为ohos.app.Context,注意不要使用slice.getContext()来获取context,请直接传入slice,否则会出现找不到类的报错。
DatabaseHelper helper = new DatabaseHelper(this);
OrmContext context = helper.getOrmContext("BookStore", "BookStore.db", BookStore.class); (可选)数据库升降级。如果开发者有多个版本的数据库,通过设置数据库版本迁移类可以实现数据库版本升降级。
数据库版本升降级的调用示例如下。其中BookStoreUpgrade类也是一个继承了OrmDatabase的数据库类,与BookStore类的区别在于配置的版本号不同。
OrmContext context = helper.getOrmContext("BookStore",
"BookStore.db",
BookStoreUpgrade.class,
new TestOrmMigration32(),
new TestOrmMigration23(),
new TestOrmMigration12(),
new TestOrmMigration21());TestOrmMigration12的实现示例如下:
private static class TestOrmMigration12 extends OrmMigration {
// 此处用于配置数据库版本迁移的开始版本和结束版本,super(startVersion, endVersion)即数据库版本号从1升到2。
public TestOrmMigration12() {super(1, 2); }
@Override
public void onMigrate(RdbStore store) {
store.executeSql("ALTER TABLE `Book` ADD COLUMN `addColumn12` INTEGER");
}
}说明
数据库版本迁移类的开始版本和结束版本必须是连续的。
- 如果BookStore.db的版本号为“1”,BookStoreUpgrade.class的版本号为“2”时,TestOrmMigration12类的onMigrate方法会被自动回调。
- 如果BookStore.db的版本号为“1”,BookStoreUpgrade.class版本号为“3”时,TestOrmMigration12类和TestOrmMigration23类的onMigrate方法会依次被回调。
使用对象数据操作接口OrmContext对数据库进行增删改查、注册观察者、备份数据库等。
- 更新或删除数据,分为两种情况:
- 通过直接传入OrmObject对象的接口来更新数据,需要先从表中查到需要更新的User对象列表,然后修改对象的值,再调用更新接口持久化到数据库中。删除数据与更新数据的方法类似,只是不需要更新对象的值。
例如,更新“user”表中age为“29”的行,需要先查找“user”表中对应数据,得到一个User的列表。然后选择列表中需要更新的User对象(如第0个对象),设置需要更新的值,并调用update接口传入被更新的User对象。最后调用flush接口持久化到数据库中。
- 通过直接传入OrmObject对象的接口来更新数据,需要先从表中查到需要更新的User对象列表,然后修改对象的值,再调用更新接口持久化到数据库中。删除数据与更新数据的方法类似,只是不需要更新对象的值。
// 更新数据
OrmPredicates predicates = context.where(User.class);
predicates.equalTo("age", 29);
List<User> users = context.query(predicates);
User user = users.get(0);
user.setFirstName("Li");
context.update(user);
context.flush();
// 删除数据
OrmPredicates predicates = context.where(User.class);
predicates.equalTo("age", 29);
List<User> users = context.query(predicates);
User user = users.get(0);
context.delete(user);
context.flush();- 通过传入谓词的接口来更新和删除数据,方法与OrmObject对象的接口类似,只是无需flush就可以持久化到数据库中。
ValuesBucket valuesBucket = new ValuesBucket();
valuesBucket.putInteger("age", 31);
valuesBucket.putString("firstName", "ZhangU");
valuesBucket.putString("lastName", "SanU");
valuesBucket.putDouble("balance", 300.51);
OrmPredicates update = context.where(User.class).equalTo("userId", 1);
context.update(update, valuesBucket);- 查询数据。在数据库的“user”表中查询lastName为“San”的User对象列表,示例如下:
OrmPredicates query = context.where(User.class).equalTo("lastName", "San");
List<User> users = context.query(query);- 注册观察者。
// 定义一个观察者类。
private class CustomedOrmObjectObserver implements OrmObjectObserver {
@Override
public void onChange(OrmContext changeContext, AllChangeToTarget subAllChange) {
// 用户可以在此处定义观察者行为
}
}
// 调用registerEntityObserver方法注册一个观察者observer。
CustomedOrmObjectObserver observer = new CustomedOrmObjectObserver();
context.registerEntityObserver("user", observer);
// 当以下方法被调用,并flush成功时,观察者observer的onChange方法会被触发。其中,方法的入参必须为User类的对象。
public <T extends OrmObject> boolean insert(T object)
public <T extends OrmObject> boolean update(T object)
public <T extends OrmObject> boolean delete(T object)- 备份数据库。其中原数据库名为“OrmTest.db”,备份数据库名为“OrmBackup.db”。
OrmContext context = helper.getObjectContext("OrmTest", "OrmTest.db", BookStore.class);
context.backup("OrmBackup.db");
context.close();删除数据库,例如删除OrmTest.db。
helper.deleteRdbStore("OrmTest.db");